

django学习(三)
1.单表操作和测试环境的准备
我们先对单表查询做一个总结和回顾,并进行进一步的学习和交流。我们在我们的应用的models.py文件下面书写user类。如下所示,然后用数据库迁移,在mysql数据库中生成表。然后进行数据库表的单表查询的操作。
# models.py文件
class User(models.Model):
username = models.CharField(max_length=32, verbose_name='用户名')
password = models.CharField(max_length=32, verbose_name='密码')
age = models.IntegerField(verbose_name='年龄')
info = models.CharField(max_length=256, verbose_name='用户描述')
salary = models.DecimalField(max_digits=8, decimal_places=2, verbose_name='用户的薪水')
register_time = models.DateField(default='2020-8-28',verbose_name='注册时间')
'''
这里补充一个知识点:DateField和DateTimeField有两个重要的参数
这两个参数分别是:
auto_now:每次操作数据的时候,该字段会自动将当前时间更新
auto_now_add:在创建数据的时候会自动将当前创建时间记录下来,之后只要不修改,那么时间一直不变。
'''
def __str__(self):
return '%s' % self.username
我们之前学了单表操作的知识,在这里我们巩固一下,并且进行更深入一步的学习。我们之前测试我们的models文件是否正常,数据库迁移是否正确,我们都是采用的是前后端交互的技术实现测试的。但是我们知道django的orm语句是比较多的,我们每次对于数据库的操作,orm语句的操作都需要前后端来测试的话,那么这个是十分的麻烦。在这里我们在学习单表操作的同时,也引进了关于测试环境准备的知识点,那么以后我们写好的.py文件的代码,我们可以放到我们的测试环境中,即test.py文件中进行测试。脚本代码无论是写在自己应用下的test.py中,还是自己单独开设.py文件都可以。
测试环境的准备:去manager.py中copy这个文件的前面四行代码,然后自己写两行。测试文件是通用的一个功能,不一定是在应用下的test.py文件,自己也可以新建测试的.py文件,例如mytest.py文件。
在这个代码块下面就可以测试django里面的单个py文件了。所有的代码都要写在测试环境的下面,因为测试环境还没有准备好,我们必须放在测试环境的下面,等待测试环境准备好之后,我们才可以开始测试。所有的代码必须等待环境准备好之后才可以开始书写。
# 测试环境的搭建
import os
def main():
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'model_mysite.settings')
import django
django.setup()
if __name__ == '__main__':
main()
现在我们在我们的测试环境下来测试、使用、学习和扩展我们的单表查询。
# 这个导入包的操作必须放在测试环境之后,即django.setup()之后,不然会出现报错。
from app01 import models
# 单表操作--增
# 用create()方法增加
models.User.objects.create(username='zhouqian', password='123456', age=22, info='可甜、可怜、可爱、可傻', salary=12500,register_time='2020-6-26')
# 用类的方式增加,save()方法
user_obj = models.User(username='AndreasZhou', password='456789', age=22, info='可骚、可变态、博多、仓老师', salary=22500,register_time='2020-6-28')
user_obj.save()
# 单表操作--删
models.User.objects.filter(id=1).delete()
# 查询出某一个数据,然后将这个数据删除,直接调用deldete()方法
# 单表操作--改
# 批量的更新操作。这个其实是所谓的批量的更新的操作,但是因为我们平常用的id值唯一的主键,所以我们这里更新的其实也是一个数据
models.User.objects.filter(id=2).update(username='ZhouQian')
# 单独的更新操作
user_obj = models.User.objects.filter(id=3).first()
user_obj.username = 'ANDREASZHOU'
user_obj.save()
# 单表操作--查
res = models.User.objects.filter(id=2) # <QuerySet [<User: User object (2)>]> 类似于列表套对象的形式 <QuerySet [<User: ZhouQian>]>
print(res)
user_obj = models.User.objects.filter(id=2).first()
print(user_obj) # User object (2) ZhouQian
res = models.User.objects.all()
print(res) # <QuerySet [<User: User object (2)>, <User: User object (3)>]> <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>]>
'''
在这里我们需要补充一个知识点就是pk的使用,pk会自动查找到当前表的主键字段,指代的就是当前表的主键字段,用了pk之后,你就不需要指代当前表的主键字段到底叫什么了。uid,pid,sid...。所以我们在平时的使用的时候,我们用pk用的比较的频繁。所以我们后面按照主键查找,我们就按照pk来使用就好了。
'''
2.必知必会13条(重点)
1)all():查询所有
res = models.User.objects.all() # 得到的是一个查询集queryset,类似于列表里面套数据对象
print(res) # <QuerySet [<User: User object (2)>, <User: User object (3)>]> <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>]>
2)filter():带有过滤条件的查询
res = models.User.objects.filter(id=2) # <QuerySet [<User: User object (2)>]> 类似于列表套对象的形式 <QuerySet [<User: ZhouQian>]>
print(res)# 获取的也是queryset,类似于列表套数据对象
user_obj = models.User.objects.filter(id=2).first()
print(user_obj) # User object (2) ZhouQian 打印出来的直接是一个对象。因为这里显示zhouqian表示的是调用了类中的__str__方法了。
3)get():直接拿数据对象,但是条件不存在那么会直接报错,不推荐使用。
user_obj = models.User.objects.get(id=2)
print(user_obj) # 得到的是User object(2) ZhouQian
user_obj = models.User.objects.get(id=4) # app01.models.DoesNotExist: User matching query does not exist. 查询不存在,所以这里报错,其实我们的get方法是不推荐使用的,完全被filter方法给替代了。
print(user_obj)
'''
get方法返回的直接就是当前的数据对象,但是该方法不推荐使用,一旦数据不存在该方法会直接报错。
而filter则不会报错,所以我们还是用filter
'''
4)first():拿到queryset里面的第一个元素,即第一个数据对象(queryset是列表套数据对象)
res = models.User.objects.filter(id=2) # <QuerySet [<User: User object (2)>]> 类似于列表套对象的形式 <QuerySet [<User: ZhouQian>]>
print(res)
user_obj = models.User.objects.filter(id=2).first()
print(user_obj) # User object (2) ZhouQian
5)last():拿到queryset里面的最后一个元素,即最后一个数据对象(queryset是列表套数据对象)
res = models.User.objects.filter(id=2) # <QuerySet [<User: User object (2)>]> 类似于列表套对象的形式 <QuerySet [<User: ZhouQian>]>
print(res)
user_obj = models.User.objects.filter(id=2).last()
print(user_obj) # User object (2) ZhouQian
user_obj = models.User.objects.all().last()
print(user_obj) # ANDREASZHOU
6)values():可以指定的获取的数据字段 select name,age from ..... 类似于列表套字典
res = models.User.objects.values('name','age')
# 类似于sql语句中的select name,age from User;
print(res)
# 打印出来的结果是一个queryset,这里的queryset我们可以看做是列表套字典的形式,返回结果我们是需要记忆的。记住这是一个返回结果queryset,列表里面套字典的形式,字典的关键字是name和age。
# select username,password from User;
res = models.User.objects.values('username','password')
print(res)
7)values_list():可以指定的获取的数据字段 select name,age from ..... 类似于列表套元组
res = models.User.objects.values('name','age')
print(res)
# 打印出来的结果是一个queryset,这里的queryset我们可以看做是列表套元组的形式,返回结果我们是需要记忆的。记住返回的是一个queryset,里面是列表套元组的形式。
# select username,password from User;
res = models.User.objects.values('username','password')
print(res)
print(res.query)
# 在这里我们补充一个知识点
'''
查看内部封装的sql语句
上述查看sql语句的方式,只能用于QuerySet对象
只有queryset对象才能够点击query查看内部的sql语句
'''
8)distinct():去重
res = models.User.objects.values('username','age').distinct()
print(res)
select distinct username,age from User;
"""
去重一定要是一模一样的数据,如果带有主键那么肯定不一样,你在往后的查询中一定不要忽略主键
"""
9)order_by():排序
res = models.User.objects.order_by('age') # 默认是升序
print(res)
res = models.User.objects.order_by('-age') # 现在是降序
print(age)
res = models.User.objects.all().order_by('age') # 升序
print(res)
10)reverse():反转,先排序,才可以反转,是建立在排序的基础上的
res = models.User.objects.all()
res1 = models.User.objects.order_by('age').reverse()
print(res,res1)
11)count():统计数量
res = models.User.objects.count()
print(res)
12)exclude():除了什么之外,排除在外。
res = models.User.objects.exclude(name='jason')
print(res)
13)exists():判断是否存在,返回的是布尔值,基本用不到因为数据本身就自带布尔值。
res=models.User.objects.filter(pk=10).exists()
print(res)
3.神器的双下划线查询
1.我们要你帮我查出年龄大于35岁的数据
# 我们写的sql语句是:
select * from user where age >35
res = models.User.objects.filter(age__gt=35)
print(res) # <QuerySet [<User: az>]> 返回的是一个字典,列表里面套数据对象
2.我们要你帮我查出年龄小于35岁的数据
select * from user where age < 35
res = models.User.objects.filter(age__lt=35)
print(res) # <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>]> 返回的是一个字典,列表里面套数据对象。
3.我们要你帮我查出年龄大于等于35岁的数据
select * from user where age >=35;
res = models.User.objects.filter(age__gte=35)----->这里的g是greater,t是than,e是equal
print(res) # <QuerySet [<User: ak>, <User: az>]>。返回的是一个queryset,类似于列表里面套数据对象。
4.我们要你帮我查出年龄小于等于35岁的数据
select * from user where age <=35;
res = models.User.objects.filter(age__lte=35)
print(res) # <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>, <User: ak>]>返回的是一个queryset,类似于列表里面套数据对象。
5.我们要你帮我查出年龄是18或者35或者38
select * from user where age in (18,35,38);
res = models.User.objects.filter(age__in=(18, 35, 38))
print(res) # <QuerySet [<User: ak>, <User: az>]>
6.我们要你帮我查出年龄在18到48岁之间的,首位都要
res = models.User.objects.filter(age__range=[18, 48])
print(res) # <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>, <User: ak>, <User: az>]>返回的是一个queryset,类似于列表里面套数据对象。
7.我们要你帮我查出名字里面含有n的数据,模糊查询,区分大小写
# 默认是区分大小写的
res = models.User.objects.filter(username__contains='n')
print(res) # <QuerySet [<User: ZhouQian>]> 返回的是一个queryset,类似于列表里面套数据对象。
8.我们要你帮我查出名字里面含有n的数据,模糊查询,忽略大小写
# 忽略大小写
res = models.User.objects.filter(username__icontains='n')
print(res) # <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>]> 返回的是一个queryset,类似于列表里面套数据对象。
9.我们要你帮我查出名字以Z为开头
res = models.User.objects.filter(username__startswith='Z')
print(res) # <QuerySet [<User: ZhouQian>]> 返回的是一个queryset,类似于列表里面套数据对象。
10.我们要你帮我查出名字以U为结尾
res = models.User.objects.filter(username__endswith='U')
print(res) # <QuerySet [<User: ANDREASZHOU>]> 返回的是一个queryset,类似于列表里面套数据对象。
11.我们要你帮我查出注册时间的月
res = models.User.objects.filter(register_time__month=8)
print(res) # <QuerySet [<User: ak>, <User: az>]>
12.我们要你帮我查出注册时间的年
res = models.User.objects.filter(register_time__year=2020)
print(res) # <QuerySet [<User: ZhouQian>, <User: ANDREASZHOU>, <User: ak>, <User: az>]>
4.多表查询
我们在做多表查询的之前需要做一些准备工作,下面就是我们准备工作要写的模型类,将写好的模型类迁移到数据库中,这样我们就可以开始做我们的多表的查询。模型类的代码如下所示。
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name='书名')
price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name='价格')
publish_date = models.DateField(auto_now_add=True, verbose_name='出版时间')
publish = models.ForeignKey(to='Publish', verbose_name='书和出版社多对一',on_delete=models.CASCADE)
author = models.ManyToManyField(to='Author', verbose_name='书和作者多对多')
class Publish(models.Model):
name = models.CharField(max_length=32, verbose_name='出版社名称')
addr = models.CharField(max_length=32, verbose_name='出版社地址')
email = models.EmailField(verbose_name='联系邮箱')
# EmailField其实和varchar(254)是一样的。
# 该字段类型不是给models看的,而是给我们后面会学到的校验性组件看的。
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name='作者姓名')
age = models.IntegerField(verbose_name='作者年龄')
author_detail = models.OneToOneField(to='AuthorDetail', verbose_name='作者和作者详情一对一',on_delete=models.CASCADE)
class AuthorDetail(models.Model):
phone = models.CharField(max_length=32, verbose_name='手机号')
# 电话号码我们用BigIntegerField或者使用直接使用CharField,而不能用IntegerField。
addr = models.CharField(max_length=32, verbose_name='作者地址')
5.外键的增删改
我们前面已经建立了表之间的关系,那么我们现在可以使用orm框架实现外键的增删改查,因为查是最难的知识点,所以我们将查和增删改分开讲解,我们先讲解增删改,后面再讲解查。
1)一对一、一对多外键的增删改
# 一对一、一对多外键的增
# 增:
models.Book.objects.create(title='白蛇传', price=255, publish_id=3) # 1.直接写id的形式增加
publish_obj = models.Publish.objects.filter(pk=2).first() # 2.用对象的形式增加
models.Book.objects.create(title='武当派',price=388,publish=publish_obj)
# 一对一、一对多外键的删
# 删:我们设置为级联更新,级联删除
models.Publish.objects.filter(pk=1).delete()
# 一对一、一对多外键的改
# 改:
models.Book.objects.filter(pk=7).update(publish_id=3) # 1.直接写id的形式更新
publish_obj = models.Publish.objects.filter(pk=1).first() # 2.用对象的形式更新
models.Book.objects.filter(pk=7).update(publish=publish_obj)
2)多对多外键增删改清空
接下来我们学习多对多外键的增删改,我们依次用下面的代码来写:
# 多对多外键的增
# 直接写id的形式增加
book_obj = models.Book.objects.filter(pk=7).first()
print(book_obj.author) # app01.Author.None 就类似于你已经进入了第三张表的关系了
book_obj.author.add(1) # 书籍id为1的书籍绑定一个主键为1的作者
book_obj = models.Book.objects.filter(pk=8).first()
print(book_obj.author) # app01.Author.None 就类似于你已经进入了第三张表的关系了
book_obj.author.add(1, 2, 3, 4)
# 用对象的形式增加
author_obj = models.Author.objects.filter(pk=2).first()
author_obj1 = models.Author.objects.filter(pk=3).first()
author_obj2 = models.Author.objects.filter(pk=4).first()
book_obj = models.Book.objects.filter(pk=4).first()
book_obj1 = models.Book.objects.filter(pk=5).first()
print(book_obj.author) # app01.Author.None 就类似于你已经进入了第三张表的关系了
book_obj.author.add(author_obj, author_obj1, author_obj2)
book_obj1.author.add(author_obj)
'''
add()给第三张关系表添加数据,括号内既可以传数字也可以传对象,并且支持一个或者多个。
'''
# 多对多外键的删
# 直接写id的形式删除
book_obj = models.Book.objects.filter(pk=5).first()
print(book_obj.author) # app01.Author.None 类似于进入了第三张表
book_obj.author.remove(2)
# 用对象的形式删除
author_obj = models.Author.objects.filter(pk=2).first()
author_obj1 = models.Author.objects.filter(pk=3).first()
book_obj = models.Book.objects.filter(pk=4).first()
book_obj.author.remove(author_obj,author_obj1)
'''
remove():括号内既可以传数字也可以传对象,并且数字和对象可以有一个或者是多个。
'''
# 多对多外键的改----记住这里的set方法只可以传入一个可迭代的对象,不然会报错。可迭代对象的列表和元组都是可以的。
# 直接写id的形式修改
book_obj = models.Book.objects.filter(pk=4).first()
book_obj.author.set([2]) # 这个括号内必须是一个可迭代对象,列表和元组都是可以的
book_obj.author.set((3,))
book_obj.author.set([2])
# 用对象的形式修改
book_obj = models.Book.objects.filter(pk=7).first()
author_obj = models.Author.objects.filter(pk=3).first()
author_obj1 = models.Author.objects.filter(pk=4).first()
book_obj.author.set([author_obj, author_obj1]) # 这里面必须是一个可迭代对象,列表和元组都是可以的。
'''
set():set的括号内必须是一个可迭代的对象,可迭代对象里面既可以是数字也可以是对象,并且数字和对象可以有一个或者是多个。
'''
# 多对多的清空---清空的clear()方法中不需要传入任何的参数和对象。我们只要点这个方法就可以。
# 清空:在第三张关系表中清空某个书籍与作者的绑定关系
book_obj = models.Book.objects.filter(pk=7).first()
book_obj.author.clear()
'''
clear():括号内不需要加任何的参数
'''
6.正反向的概念
在我们讲解多表查询的时候,我们在这里先学一个概念,这个概念就是关于正反向的概念,如果我们弄清楚了这个概念以后,我们的下面的学下就会表的更加的轻松。
外键字段在我手上,那么我查你就是正向。外键字段如果不在我手上,那么我查你就是反向。
-
book 》》》外键字段在书哪儿(正向)》》》publish
-
publish》》》外键字段在书哪儿(反向)》》》book
一对一,多对多正反向的判断也是如此
7.多表查询--基于对象的跨表查询(子查询)
正向查询按字段,如果我们发现结果是有多个的时候我们是字段加上all(),如果发现结果只有一个的时候,我们是字段即可。
反向查询按表名小写,如果发现结果有多个的时候我们是表名小写加__set,并且还要加上all()。如果是单个的时候我们是直接表名小写,也不用加__set和all()
1)正向查询
1.查询书籍主键为1的出版社名称
书籍查出出版社 正向
book_obj = models.Book.objects.filter(pk=1).first()
res = book_obj.publish
print(res) # 打印出来的是出版社对象
print(res.name) # 北京出版社
print(res.addr) # 北京
这个res是一个Publish对象,我们打印调用了`__str__`方法,显示出是对象:北京出版社。
2.查询书籍主键为2的作者
书籍查作者是正向查询
book_obj = models.Book.objects.fliter(pk=2).first()
res = book_obj.author
print(res) # 打印出来是app01.Author.None
res = book_obj.author.all() # 打印出很多个作者对象
3.查询作者jason的电话号码
作者到作者的详情,所以是正向。所以我们这里这样写:
author_obj = models.Author.objects.filter(name='jason').first()
res=author_obj.author_detail
print(res) 得到的结果是一个AuthorDetail对象。
print(res.phone)
print(res.addr)
上面我们得到了一个特点是:利用orm跨表查询是比较的简单。在书写orm语句的时候跟写sql语句是一样的,不要企图一次性将orm语句写完,如果比较复杂,就写一点看一点,分段写
正向的时候什么时候需要加.all()呢?当你的结果可能有多个的时候就需要加.all(),如果是一个则直接拿到数据对象。
2)反向查询
4.查询出版社是北京出版社出版的书籍
出版社查书 反向
publish_obj = models.Publish.objects.filter(name='北京出版社').first()
res = publish_obj.book_set
print(res) # app01.Book.None
res = publish_obj.book_set.all()
print(res) 返回的是queryset,我们可以理解为列表里面套对象
5.查询作者是jason写过的书
Author 到 book 是反向查询
author_obj = models.Author.objects.filter(name='jason').first()
res = author_obj.book_set app01.Book.None
res = author_obj.book_set.all()
6.查询手机号是110的作者姓名
authoudetail 到 author 是反向查询 AuthorDetail-->Book是反向的查询
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
res = author_detail_obj.author
print(res.name)
基于对象反向查询的时候的规律
当你的查询结果可以有多个的时候,我们就必须表名小写加上_set.all()
当你的查询结果只有一个的时候,我们就必须是表名小写,不需要加_set.all()
8.多表查询--基于双下划线的跨表查询(联表查询)
例子1.查询书籍主键为1的出版社名称(一行代码搞定)
select Publish.name from (select * from Book,Publish where publish_id = Publish.id ) as Book_Publish where Book.id =1;
1.查询jason的手机号和作者姓名
正向
res=models.Author.objects.filter(name='json').values('author_detail__phone',‘name’)
print(res) # query_set:类似于列表里面套字典
反向
res = model.AuthorDetail.objects.filter(author__name='jason') 拿作者姓名jason的作者详情
res = model.AuthorDetail.objects.filter(author__name='jason').values('phone','author__name')
print(res)
2.查询书籍主键为1的出版社名称和书的名字
正向
# 书籍查出版社是正向
res = models.Book.objects.filter(pk=1).values('publish__name','title')
print(res)
反向
res = models.Publish.objects.filter(book__id=1).values('name','book__title')
print(res)
3.查询书籍主键为1的作者姓名
正向
res = models.Book.objects.filter(pk=1).values('author__name')
print(res) # queryset 类似于列表里面套字典
反向
res= models.Author.objects.filter(book__pk=1).values('name')
print(res) # queryset 类似于列表里面套字典
4.查询书籍主键是1的作者的手机号
Book Author AuthorDetail
res = models.Book.objects.filter(pk=1).values('author__author_detail__phone')
print(res)
你只要掌握了正反向的概念以及双下划线的查询,那么你就可以无限制的跨表查询,联表查询。
9.聚合查询
在这里我们先学习一个东西,我们必须明白一个理论的知识。这个理论知识就是:只要是跟数据库相关的模块基本上都在django.db.models里面,如果上述没有那么应该在django.db里面。聚合函数涉及的一般是如下:max,min,sum,count,avg,在django中,我们应该使用aggregate()。
from app01 import models
from django.db.models import Max,Min,Count,Sum,Avg
# 1.计算所有书的平均价格
res = models.Book.objects.aggregate(Avg('price'))
print(res)
# 2.上诉的方法统一使用
res=models.Book.objects.aggregate(Max('price'),Min('price'),Sum('price'),Count('pk'),Avg('price'))
print(res) # 返回的是字典
{'price__max': Decimal('388.00'), 'price__min': Decimal('255.00'), 'pk__count': 5, 'price__avg': Decimal('334.800000'), 'price__sum': Decimal('1674.00')}
10.分组查询
分组在mysql中是group by,在我们的django是用annotate作为分组的使用。一般分组和聚合是在一起使用的。两者相辅相成,也就是我们平时所说的分组聚合。
MySQL分组查询有哪些特点呢?分组时候默认只能获取到分组的依据,组内其他字段无法直接获取了。因为MySQL默认是严格模式,ONLY_FULL_GROUP_BY
我们看下面的几个题目来深刻的体会和理解分组查询的意义和内涵。
# 1.统计每一本书的作者的个数
# models后面点什么我们就按照什么来分组,models.Book.objects.values('price').annotate()按照书的价格分组
# res = models.Book.objects.annotate(author_number=Count('author__id')).values('title', 'author_number')
# print(res)<QuerySet [<Book: Book object (3)>, <Book: Book object (4)>, <Book: Book object (5)>, <Book: Book object (7)>, <Book: Book object (8)>]>
# print(res)
# < QuerySet[{'title': '小斌张嘎', 'author_number': 0}, {'title': '白蛇传', 'author_number': 1}, {'title': '武当派',
# 'author_number': 0}, {
# 'title': '聊斋', 'author_number': 2}, {'title': '斗破苍穹', 'author_number': 4}] >
# 2.统计每一个出版社卖的最便宜的书的价格
# res = models.Publish.objects.annotate(book_price=Min('book__price')).values('name', 'book_price')
# print(res)
# < QuerySet[{'name': '上海出版社', 'book_price': Decimal('388.00')}, {'name': '杭州出版社', 'book_price': Decimal('255.00')}, {
# 'name': '北京出版社', 'book_price': Decimal('255.00')}, {'name': '嘉兴出版社', 'book_price': None}] >
# 3.统计不止是一个作者的图书
# res = models.Book.objects.annotate(author_num=Count('author__pk')).filter(author_num__gt=1).values('title', 'author_num')
# print(res) # <QuerySet [{'title': '聊斋', 'author_num': 2}, {'title': '斗破苍穹', 'author_num': 4}]>
# 4.查询每个作者出的书的总价格
# res = models.Author.objects.annotate(book_sum=Sum('book__price')).values('name', 'book_sum')
# print(res)
# < QuerySet[{'name': 'AndreasZhou', 'book_sum': Decimal('643.00')}, {'name': '周周', 'book_sum': Decimal('643.00')}, {
# 'name': '憨憨', 'book_sum': Decimal('643.00')}, {'name': '周乾', 'book_sum': Decimal('388.00')}] >
在这里我们补充一个知识点,这个知识点就是:只要你的orm语句得出来的结果还是一个QuerySet对象,那么它就可以继续无限制的点QuerySet对象封装的方法。
还有一个知识点就是,如果我想要按照指定的字段分组该如何处理呢?
models.Book.objects.values('price').annotate(),后续我们在写项目的时候会使用到这个知识点。
11.F查询
我们现在来讲解一下什么是F查询,F查询的用途是什么呢?
F查询:能够帮助你直接获取到列表中某个字段对应的数据
1.查询卖出数大于库存数的书籍
from django.db.models import F
res = models.Book.objects.filter(maichu__gt=F('库存'))
print(res)
# <QuerySet [<Book: Book object (3)>, <Book: Book object (7)>]>
2.将所有书籍的价格提升50块
# 2.将所有书籍的价格提升50块
from django.db.models import F
res = models.Book.objects.all().values('title', 'price')
print(res)
res = models.Book.objects.update(price=F('price') + 50)
print(res)
models.Book.objects.update(price=F('price')+50)
F('price'):表示获取的是原来的价格
3.将所有书的名称后面加上爆款两个字(了解)
'''
在操作字符串类型的数据的时候,F不能够直接做到字符串的拼接。
'''
from django.db.models.functions import concat
from django.db.models import Value
models.Book.objects.update(title=concat((F('title'),Value('爆款')))
12.Q查询
在学习Q查询之前,我们先来说明一个问题,filter默认只是支持使用的是与(and)关系。但是往往这样一种关系是不能满足于我们平时的使用。所以我们需要更多的逻辑关系,使得我们更加的操作方便,因此我们在这里引入了一种查询方式,这个查询方式叫做Q查询。
1.查询卖出数大于100或者价格小于600的书籍
`res = models.Book.objects.filter(maichu__gt=100,price__lt=600)`
`print(res)`
'''
filter括号内多个参数是and关系,是我们想要的是或,非等关系,那我们怎么办呢?
'''
from django.db.models import Q
`res = models.Book.objects.filter(Q(maichu__gt=100,price__lt=600))` Q包裹,逗号分隔,还是and关系
`res = models.Book.objects.filter(Q(maichu__gt=100|price__lt=600))` Q包裹,|分隔,or关系
`res = models.Book.objects.filter(~Q(maichu__gt=100,price__lt=600))` Q包裹,~分隔,not关系
`print(res)`
2.Q的高阶用法 能够将查询条件左边也变成字符串的形式,而不再是变量名的形式。使用Q我们可以实现一个简单的搜索功能。
q = Q()
q.connector='or'
q.children.append(('maichu__gt',100))
q.children.append(('price__lt',600))
res=models.Book.objects.filter(q) # filter括号内也支持直接放q对象,默认还是and关系
print(res)
13.django中如何开启事务
事务:我们知道事务有四个特性,这四个特性分别是:
原子性:不可分割的最小单位。
一致性:跟原子性是相辅相成的。
隔离性:事务之间是互相不干扰。
持久性:事务一旦确认是永久有效的。
事务的回滚:rollback
事务的确认:commit
from django.db import transaction
try:
with transaction.atomic():
# sql1
# sql2
# ...
# 在with代码块内书写的所有orm操作都是同一个事务
except Exception as e:
print(e)
print('执行其他操作')
14.orm中常用字段以及参数
# 常用字段
AutoField()
IntegerField()
CharField()
DecimalField()
EmailField()
DateField()
DateTimeField()
TimeField()
OneToOneField()
ManyToManyField()
ForeignField()
# 常用参数
null
unique
verbose_name
default
auto_now
auto_now_add
to
to_field
on_delete
max_length
choices
# 了解字段
SmallIntegerField()
PositiveSmallIntegerField()
PositiveIntegerField()
PositiveIntegerField()
BooleanField()
# 了解参数
related_name
through
through_fields
db_table
参考:https://www.cnblogs.com/liuqingzheng/articles/9627915.html
15.choices参数(数据库字段设计常见)
'''
用户表
姓名
学历
工作经验
是否生子
是否结婚
客户来源
...
针对某个可以列举完全的可能性字段,我们该如何存储?
只要某个字段的可能性是可以列举完全的,那么一般情况下都会采用choices参数
'''
class User(models.Model):
username = models.CharField(max_length=32,verbose_name='用户名')
age = models.IntegerField(verbose_name='年龄')
gender_choices = (
(1,'男'),
(2,'女'),
(3,'其他'),
)
gender = models.IntegerField(choices=gender_choices)
'''
改gender字段存的还是数字,但是如果存的数字在上面元组列举的范围之内,那么可以非常轻松的获取到数字对应的真正内容。
1.gender字段存的数字不在上述元组列举的范围内容
2.如果在的话,如何获取对应的中文信息
'''
from app01 import models
models.User.objects.create(username='zhouqian',age=18,gender=1)
models.User.objects.create(username='zhoukun',age=28,gender=2)
models.User.objects.create(username='AndreasZhou',age=20,gender=3)
models.User.objects.create(username='thanzhou',age=18,gender=4)
user_obj = models.User.objects.filter(pk=1).first()
print(user_obj.gender)
user_obj = models.User.objects.filter(pk=1).first()
# 只要是choices参数的字段,如果想要获取对应信息。固定写法:get_字段名_display()
print(user_obj.get_gender_display())
# 如果没有对应关系,那么字段是什么还是展示什么
user_obj = models.User.objects.filter(pk=4)..first()
print(user_obj.get_gender_display()) # 4
gender_choices=(
(1,'男'),
(2,'女'),
(3,'其他'),
)
gender = models.IntegerField(choices=gender_choices)
scores_choices = (
('A','优秀'),
('B','良好'),
('C','及格'),
('D','不及格'),
)
# 保证字段的类型跟列举出来的元组的第一个数据类型一致即可。
score = models.CharField(choices=scores_choices,null=True)
16.多对多三种创建方式
# 系统自带
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
class Author(models.Model):
name = models.CharField(max_length=32)
'''
优点:代码不需要你写,非常方便,还支持orm提供操作第三张关系表的方法,add(),remove(),clear(),set()
不足之处:第三张关系表的扩展性极差(没有第三张表,没有办法额外添加字段)
'''
# 纯手动
class Book(models.Model):
name = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book_id = models.ForeignKey(to='Book')
author_id = models.ForeignKey(to='Author')
'''
优点:第三张表完全取决于你自己进行额外的扩展
不足之处:需要你自己手写代码,写的代码比较多。不能够使用orm提供的简单的方法,不建议你用该方式。
'''
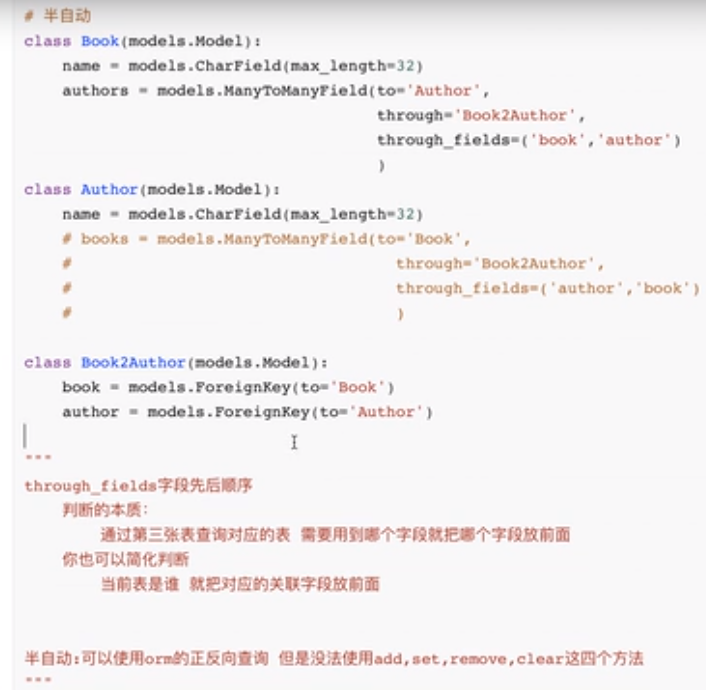
# 半自动
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',
through='Book2Author'
through_fields=('book','author')
)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Models):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
'''
半自动:可以使用orm的正反向查询,但是没发使用add,set,remove,clear这四个方法
'''
 |
|---|
总结:需要掌握全自动和半自动,为了扩展性更高,一般我们都会采用半自动(写代码给自己留一条后)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号