


图像处理--图像特效
图像特效基础
(1)灰度处理
在讲解图像特效之前,我们先get一下做灰度图像的四种方法。
方法一:通过设置imread的第二个参数,来实现图片的灰度处理。
方法二:cv库提供了一个函数cvtColor,来实现图片的灰度处理。
方法三:Gray = (B+G+R)/3 根据BGR的均值作为计算。
方法四:Gray = R*0.299 + G*0.587 + B*0.114 根据线性规则来做运算。心理学计算公式。也是概率分布的。
方法五:灰度图像处理的算法的优化。gray = (B*1+G*2+R*1)/4
我们先来讲解一下方法一:
# 方法一:通过设置imread的第二个参数,来实现图片的灰度处理
import cv2
img0 = cv2.imread('image0.JPG',0)
img1 = cv2.imread('image0.JPG',1)
print(img0.shape)
print(img1.shape)
cv2.imshow('image0',img0)
cv2.imshow('image1',img1)
cv2.waitKey(0)
# (547, 730) 灰度图片显示的是图片的宽高信息,没有深度.深度默认是1。
# (547, 730, 3) 彩色图片显示的是图片的高度宽度信息,还有深度信息。这里的深度是3
|  |
|
接下来我们讲解一下方法2:
# 方法2 cvtColor
import cv2
img = cv2.imread('image0.JPG',1)
dst = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 颜色空间转换 1 data 2 BGR gray 转换为灰度
cv2.imshow('image',dst)
cv2.waitKey(0)
|  |
|
接下来我们讲解一下方法三:
# 方法3 灰度图像的BGR和彩色图像的BGR有什么区别呢?
# 彩色图像的BGR是不一样的,而灰度图像的BRG是一样的:B=G=R gray
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
# print(img.shape)
print(img[100][100])
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# print(height,width)
dst = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
# 读取原来图像的BGR
(B,G,R) = img[i][j]
# 三个点的均值计算
B = G = R = int((int(B)+int(G)+int(R))/3)
dst[i][j]= np.uint8((B,G,R))
# 这个方法也是可以的
# gray = (int(B)+int(G)+int(R))/3
# dst[i][j] = np.uint8(gray)
cv2.imshow('dst',dst)
cv2.waitKey(0)
|  |
|
接下来我们来讲解一下方法四:
# 方法4 心理学计算公式。也是概率分布的。 gray = R*0.299 + G*0.587 + B*0.114
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
# print(img.shape)
print(img[100][100])
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# print(height,width)
dst1 = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
# 读取原来图像的BGR
(B,G,R) = img[i][j]
B = int(B)
G = int(G)
R = int(R)
gray = R*0.299 + G*0.587 + B*0.114
dst[i][j] = np.uint8(gray)
cv2.imshow('dst1',dst1)
cv2.waitKey(0)
|  |
|
最后我们讲解一下方法五:
在这里我们学习一下算法的优化,我们可以更好更快的计算出图像的灰度值。在这里我们要先明白两个知识点。
- 定点数的效率要比浮点数的效率高一些 。 定点-》浮点
- 加减的运算效率要比乘除的运算效率高一些。移位的运算也要比乘除高一些。 + - —》 */ 《— >>移位
# 方法5 算法优化,更快更好的计算图像的灰度值。
# 1 灰度知识点,是本小结中最重要的知识点。 2 很多图像的基础 3 算法的实时性。
# 定点的算法效率比浮点数的高一些 定点-》浮点。
# + - -》 */ 《- >>移位。
# 我们的方法四是利用到线性的概率分布的问题:gray = R*0.299 + G*0.587 + B*0.114。
# 那么这里我们使用到的是浮点型的小数,那么我们想要使用整数来提高效率。gray = (B*1+G*2+R*1)/4。
# 因为整数的计算是比小数的计算的计算效率还要快。
# 当然不一定是乘以1,2这样子。我们也可以乘以100,1000,10000。根据具体的问题决定,尽量减少误差。
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
# print(img.shape)
print(img[100][100])
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# print(height,width)
dst2 = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
# 读取原来图像的BGR
(B,G,R) = img[i][j]
B = int(B)
G = int(G)
R = int(R)
# 在这里我们使用定点的整数,来实现优化,使得我们得出来的结果快,但是多多少少都是有误差的。
gray = (B*1+G*2+R*1)/4
# 下面的这种更加的优化
# gray = (B+(G<<1)+R)>>2 # 使用了左移和右移
dst2[i][j] = np.uint8(gray)
cv2.imshow('dst2',dst2)
cv2.waitKey(0)
|  |
|
(2)颜色反转(底板效果)
底板效果有点像胶卷相机洗出来的效果
1.彩色图片的颜色反转
彩色图片的每一个像素值的颜色是有BGR三个颜色值组成的,那么我们在实现颜色反转(底板效果)的时候,我们需要用255减去每一个颜色值。即
我们针对每一种颜色进行处理:例如对于B,------255-B=newB
BGR 255-B = newB 255-G = newG 255-R = newR
dst[i,j] = (255-b,255-g,255-r)
实现彩色图片的颜色反转的代码如下所示:
# 彩色图片的图片的反转,产生底板效果
# 我们针对每一种颜色进行处理:例如对于B,------255-B=newB
# BGR 255-B = newB 255-G = newG 255-R = newR
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
deepth = imgInfo[2]
dst = np.zeros([height,width,3],np.uint8) # 这里面的3表示一个像素的颜色是有三个颜色值组成的
for i in range(0,height):
for j in range(0,width):
(B,G,R) = img[i,j]
newB = 255-B
newG = 255-G
newR = 255-R
dst[i,j] = np.uint8((newB,newG,newR))
cv2.imshow('dst',dst)
cv2.waitKey(0)
| |
|
2.灰色图片的颜色反转
灰度图像的值是0-255,那么我们要实现颜色反转(底板效果),那么我们就要使得每一个像素都用255-灰度图片的值。
dst[i,j] = 255-grayPixel
代码的实现如下所示:
# 灰度图片的图片的反转
# 灰度图片的值是0-255, 然后用255-当前的值
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
deepth = imgInfo[2]
# grayPixel = img[100,100]
# print(grayPixel)
# 将彩色图片转换为灰度图片
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = np.zeros([height,width,3],np.uint8)
for i in range(0,height):
for j in range(0,width):
grayPixel = gray[i,j]
# print(grayPixel)
dst[i,j] = 255 - grayPixel
cv2.imshow('dst',dst)
cv2.waitKey(0)
|  |
|
(3)马赛克效果
我们先通过下面的一张图来体验一下马赛克。(马赛克分为矩形马赛克和圆形马赛克,我们这里使用的是矩形的马赛克)。
|  |
|
代码的实现如下所示:
# 用相同的颜色值,去替代所有需要打上马赛克地方的颜色值。
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
heihth = imgInfo[0]
width = imgInfo[1]
for m in range(100,300):
for n in range(100,200):
# pixel ->10*10,对每一个10*10的区域进行处理,先定义了一个10*10的小方块
if m%10 == 0 and n%10 == 0:
for i in range(0,10):
for j in range(0,10):
(b,g,r) = img[m,n] # 这个保证的是每一个10*10的都用同一个颜色值
img[i+m,j+n] = (b,g,r) # 使得10*10的区域都是用一个颜色的值,实现马赛克的效果。
cv2.imshow('dst',img)
cv2.waitKey(0)
|  |
|
全屏马赛克,代码实现如下:
# 用相同的颜色值,去替代所有需要打上马赛克地方的颜色值。
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
heigth = imgInfo[0]
width = imgInfo[1]
for m in range(0,heigth-10):
for n in range(0,width-10):
# pixel ->10*10
if m%10 == 0 and n%10 == 0:
for i in range(0,10):
for j in range(0,10):
(b,g,r) = img[m,n] # 这个保证的是每一个10*10的都用同一个颜色值
img[i+m,j+n] = (b,g,r)
cv2.imshow('dst',img)
cv2.waitKey(0)
| 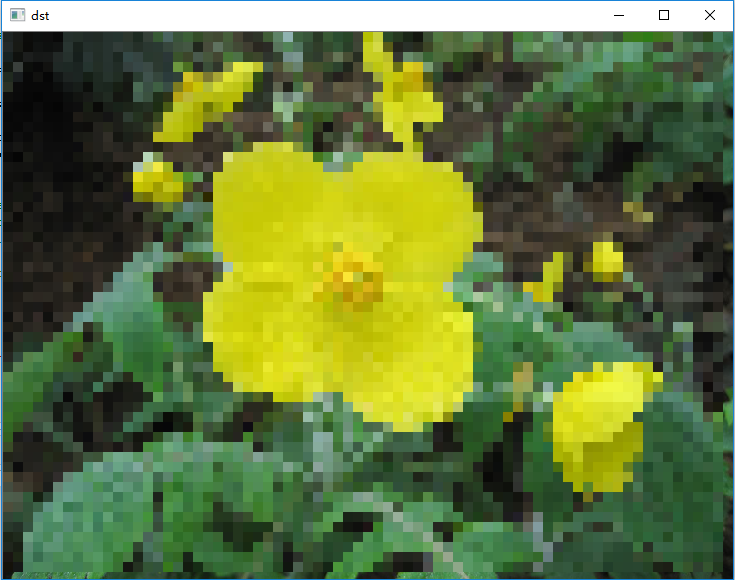 |
|
(4)毛玻璃效果
我们先通过下面的一张图来体验一下毛玻璃效果。
|  |
|
代码的实现如下所示:
# 对于每一个区域中的像素的颜色值,我们用随机的一个颜色的值。去替代所在区域的像素的颜色值。
import cv2
import numpy as np
import random
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height,width,3),np.uint8)
mm = 8 # 定义一个范围
# 减去mm是防止当前的矩阵越界
for m in range(0,height-mm):
for n in range(0,width-mm):
index = int(random.random()*mm)# 0-8
(b,g,r) = img[m+index,n+index]
dst[m,n] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
| |
|
(5)图片融合
我们先通过下面的一张图来体验一下图片的融合效果。
|  |
|
代码的实现如下所示:
# 实现的是将两个图片的像素颜色的融合 dst = src1*a + src2*(1-a),如果a=0.3,那么1-a=0.7
# 按照某一个系数的比例来实现图片的融合。
import cv2
import numpy as np
img0 = cv2.imread('image0.JPG',1)
img1 = cv2.imread('image1.JPG',1)
imgInfo = img0.shape
height = imgInfo[0]
width = imgInfo[1]
# ROI
# 将宽和高变成原来的一半
roiH = int(height/2)
roiW = int(width/2)
img0ROI = img0[0:roiH,0:roiW]
img1ROI = img1[0:roiH,0:roiW]
dst = np.zeros((roiH,roiW,3),np.uint8)
dst = cv2.addWeighted(img0ROI, 0.5, img1ROI, 0.5,3) # add src1*a + src2*(1-a)
cv2.imshow('dst',dst)
cv2.waitKey(0)
|  |
|
(6)边缘检测
我们先通过下面的一张图来体验一下图片的边缘检测的效果。
|  |
|
# 方法一:通过调用opencv的api的形式
import cv2
import numpy as np
# import tensorflow as tf
import random
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
# canny 1 转换为灰度图片gray 2 高斯滤波-去掉噪声干扰 3 调用canny方法实现边缘检测
gray = cv2.cvtColor(img,cv2.COLOR_BGR2BGRA)
imgG = cv2.GaussianBlur(gray,(3,3),0)
dst = cv2.Canny(img,50,50)
cv2.imshow('dst',dst)
|  |
|
import cv2
import numpy as np
import random
import math
img = cv2.imread('image0.JPG',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
cv2.imshow('src',img)
# sobel 1 算子模版 2 图片卷积 3 阈值判决
# [1 2 1 [ 1 0 -1
# 0 0 0 2 0 -2
# -1 -2 -1 ] 1 0 -1 ]
# [1 2 3 4] [a b c d] a*1+b*2+c*3+d*4 = dst
# sqrt(a*a+b*b) = f>th
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = np.zeros((height,width,1),np.uint8)
for i in range(0,height-2):
for j in range(0,width-2):
# 求出x方向的梯度
gy = gray[i,j]*1+gray[i,j+1]*2+gray[i,j+2]*1-gray[i+2,j]*1-gray[i+2,j+1]*2-gray[i+2,j+2]*1
# 求出y方向的梯度
gx = gray[i,j]+gray[i+1,j]*2+gray[i+2,j]-gray[i,j+2]-gray[i+1,j+2]*2-gray[i+2,j+2]
# 求出梯度
grad = math.sqrt(gx*gx+gy*gy)
# 阈值判决
if grad>50:
dst[i,j] = 255
else:
dst[i,j] = 0
cv2.imshow('dst',dst)
cv2.waitKey(0)
|  |
|
(7)浮雕效果
代码的实现的结果为:
import cv2
import numpy as np
img = cv2.imread('image0.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# newP = gray0-gray1+150
dst = np.zeros((height,width,1),np.uint8)
for i in range(0,height):
# 注意这里的width需要减去1,不然会报错。
for j in range(0,width-1):
grayP0 = int(gray[i,j])
grayP1 = int(gray[i,j+1])
newP = grayP0-grayP1+150
if newP > 255:
newP = 255
if newP < 0:
newP = 0
dst[i,j] = newP
cv2.imshow('dst',dst)
cv2.waitKey(0)
| 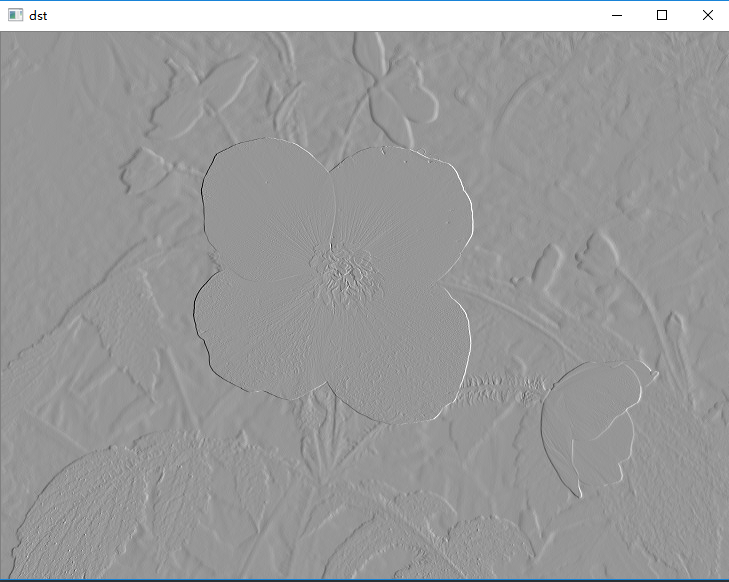 |
|
(8)颜色映射
代码的实现的结果为:
import cv2
import numpy as np
img = cv2.imread('image0.jpg',1)
cv2.imshow('src',img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#rgb -》RGB new “蓝色”
# b=b*1.5
# g = g*1.3
dst = np.zeros((height,width,3),np.uint8)
for i in range(0,height):
for j in range(0,width):
(b,g,r) = img[i,j]
b = b*1.5
g = g*1.3
if b>255:
b = 255
if g>255:
g = 255
dst[i,j]=(b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
|  |
|
(9)油画特效
代码的实现的结果为:
# 1 gray
# 2 7*7 10*10
# 3 0-255 256 4 64 0-63 64-127
# 3 10 0-63 99 64-127
# 4 count
# 5 dst = result
import cv2
import numpy as np
img = cv2.imread('image0.JPG',1)
cv2.imshow('src',img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dst = np.zeros((height,width,3),np.uint8)
for i in range(4,height-4):
for j in range(4,width-4):
# 这里是划分为8个段
array1 = np.zeros(8,np.uint8)
for m in range(-4,4):
for n in range(-4,4):
# 总共是256个,8个段,每一个段是32个。
p1 = int(gray[i+m,j+n]/32)
# p1到底投影在哪一个灰度等级中
array1[p1] = array1[p1]+1
# 获取到8个像素段中,哪一个是最大的,并且知道了最大的像素段的下标
currentMax = array1[0]
l = 0
for k in range(0,8):
if currentMax<array1[k]:
currentMax = array1[k]
l = k
# 简化 均值
for m in range(-4,4):
for n in range(-4,4):
if gray[i+m,j+n]>=(l*32) and gray[i+m,j+n]<=((l+1)*32):
(b,g,r) = img[i+m,j+n]
dst[i,j] = (b,g,r)
cv2.imshow('dst',dst)
cv2.waitKey(0)
| |
(10)线段绘制
import cv2
import numpy as np
newImageInfo = (500,500,3)
dst = np.zeros(newImageInfo,np.uint8)
# line
# 绘制线段 1 dst 2 begin 3 end 4 color
cv2.line(dst,(100,100),(400,400),(0,0,255))
# 5 line w
cv2.line(dst,(100,200),(400,200),(0,255,255),20)
# 6 line type
cv2.line(dst,(100,300),(400,300),(0,255,0),20,cv2.LINE_AA)
cv2.line(dst,(200,150),(50,250),(25,100,255))
cv2.line(dst,(50,250),(400,380),(25,100,255))
cv2.line(dst,(400,380),(200,150),(25,100,255))
cv2.imshow('dst',dst)
cv2.waitKey(0)
| 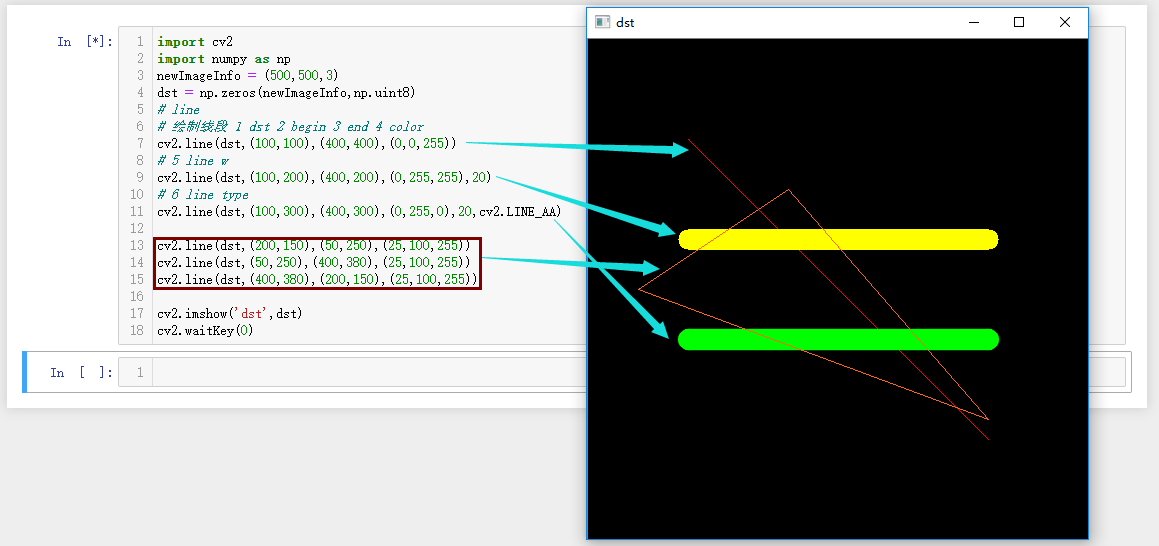 |
|
(11)矩形圆形任意多边形绘制
import cv2
import numpy as np
newImageInfo = (500,500,3)
dst = np.zeros(newImageInfo,np.uint8)
# 矩形的绘制
# 1 dst 2 左上角 3 右下角 4 color 5 fill -1 >0 line w 第五个参数如果是-1,表示的是fill填充。如果是一个大于0的值,表示的是线条的宽度。
cv2.rectangle(dst,(50,100),(200,300),(255,0,0),5)
# 圆形的绘制
# 1 dst 2 center 3 r 4 颜色color 5 宽度或者是否填充
cv2.circle(dst,(250,250),(50),(0,255,0),2)
# 椭圆形的绘制
# 1 dst 2 center 3 轴的长度(椭圆有两个轴,一个是长轴,一个是短轴,所以这里的150是长轴的值,100是短轴的值)
# 4 angle偏转角度 5 begin角度 6 end角度 7 颜色color 8 表示的是否填充,以及宽度
cv2.ellipse(dst,(256,256),(150,100),0,0,180,(255,255,0),-1)
# 定义任意多边形
points = np.array([[150,50],[140,140],[200,170],[250,250],[150,50]],np.int32)
print(points.shape)
# 实现了维度的转换
points = points.reshape((-1,1,2))
print(points.shape)
# 完成当前多边形的绘制
cv2.polylines(dst,[points],True,(0,255,255))
cv2.imshow('dst',dst)
cv2.waitKey(0)
|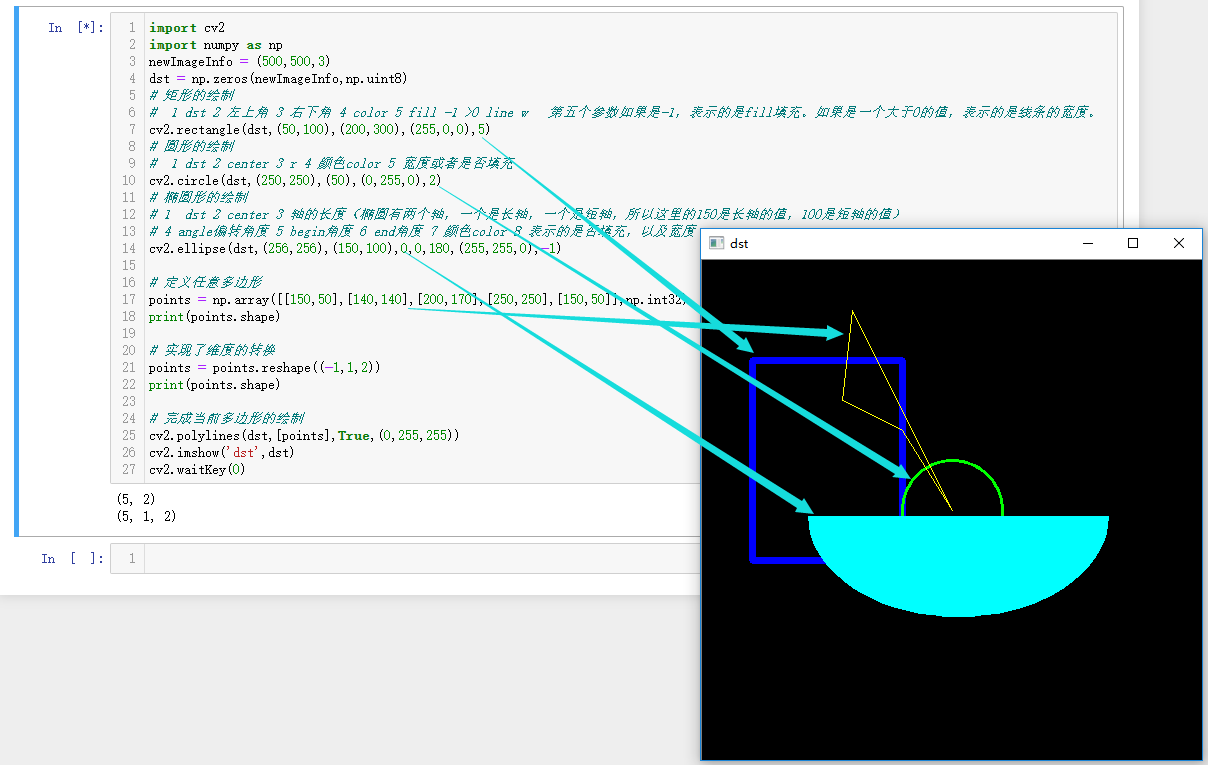 |
|
(12)文字图片绘制
1.图片上绘制文字
import cv2
import numpy as np
img = cv2.imread('image0.jpg',1)
font = cv2.FONT_HERSHEY_SIMPLEX
# 绘制一个矩形框
cv2.rectangle(img,(200,100),(500,400),(0,255,0),3)
# 1 dst 2 文字内容 3 坐标 4 font 5 字体大小 6 color 7 粗细 8 line type
cv2.putText(img,'this is flow',(100,300),font,1,(200,100,255),2,cv2.LINE_AA)
cv2.imshow('src',img)
cv2.waitKey(0)
|  |
|
2.图片上绘制图片
import cv2
img = cv2.imread('image0.jpg',1)
height = int(img.shape[0]*0.2)
width = int(img.shape[1]*0.2)
# 将图片的宽和高进行缩放,实现了将小的图片放到了大的图片上。
imgResize = cv2.resize(img,(width,height))
for i in range(0,height):
for j in range(0,width):
img[i+200,j+350] = imgResize[i,j]
cv2.imshow('src',img)
cv2.waitKey(0)
| |
|
