


python基础--自定义模块、import、from......import......
自定义模块、import、from......import......
1)模块的定义和分类
1.模块是什么?
我们知道一个函数封装了一个功能,软件可能是有多个函数组成的。我们说一个函数就是一个功能,那么把一些常用的函数放在一个py文件中,那么这个文件就称之为模块。模块就是一些列常用功能的集合体。
什么是模块:本质就是.py文件,封装语句的最小单位。
2.为什么要使用模块
- 从文件级别组织程序,更方便管理 随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用
- 拿来主义,提升开发效率 同样的原理,我们也可以下载别人写好的模块然后导入到自己的项目中使用,这种拿来主义,可以极大地提升我们的开发效率,避免重复造轮子。
ps:人们常说的脚本是什么?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
所以,脚本就是一个python文件,比如你之前写的购物车,模拟博客园登录系统的文件等等。
3.模块的分类
Python语言中,模块分为三类。
第一类:内置模块,也叫做标准库。此类模块就是python解释器给你提供的,比如我们之前见过的time模块,os模块。标准库的模块非常多(200多个,每个模块又有很多功能),我们这几天就讲常用的十几种,后面课程中还会陆续的讲到。
第二类:第三方模块,第三方库。一些python大神写的非常好用的模块,必须通过pip install 指令安装的模块,比如BeautfulSoup, Django,等等。大概有6000多个。
第三类:自定义模块。我们自己在项目中定义的一些模块。
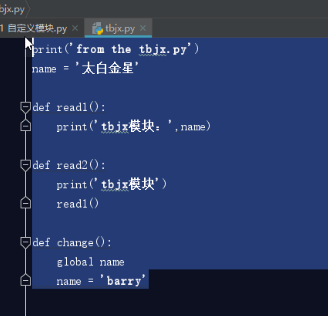
我们先定义一个模块,定义一个模块其实很简单就是写一个文件,里面写一些代码(变量,函数)即可。此文件的名字为tbjx.py,文件内容如下:
print('from the tbjx.py')
name = '太白金星'
def read1():
print('tbjx模块:',name)
def read2():
print('tbjx模块')
read1()
def change():
global name
name = 'barry'
2)自定义模块
自定义模块:定义一个模块其实很简单就是写一个文件,里面写一些代码(变量,函数)即可。此文件的名字为tbjx.py,文件内容如下:
模块中出现的变量,for循环,if结构,函数定义。。。。称为模块的成员。
自定义模块:实际上就是定义.py文件,其中可以包含:变量定义,可执行语句,for循环,函数定义等等,他们
统称模块的成员
模块的运行方式:
1.脚本方式:python xxx.py(直接用解释器执行) 或者在pycharm软件run运行(右键运行)
2.模块方式:被其它的模块导入。为导入它的模块提供资源(变量,函数定义,类定义等)。
# b.py文件
# 可执行语句
a = 1
print(a)
for x in range(10):
print(x)
# 函数的定义
def f():
print('hello world')
f()
自定义模块被其他模块导入时,其中的可执行语句会立即执行。
但是函数的定义和类的定义等是不会立即执行的。
但是我们在实际的开发的过程中,不是我们import模块就执行了。
而是在实际开发的时候用到什么就执行什么。
所以在模块中,我们一般不会写可执行语句,而是写变量的定义,函数定义和类定义等不会立即执行的语句。
我们在实际的时候,不能直接可执行语句,只有变量、函数、类定义等等。被其它的模块导入。为导入它的模块提供资源(变量,函数定义,类定义等)。
# test_import.py文件
import b
# 输出的结果为:
'''
1
0
1
2
3
4
5
6
7
8
9
hello world
'''
# import bb # ModuleNotFoundError: No module named 'bb'
我们再看一下下面这个例子,我们没有写可执行语句,而是变量、函数、类等的定义,不会再import时,就直接执行。
# b.py文件
# 可执行语句
a = 1
# 函数的定义
def f():
print('hello world')
import b
print(b.a)
b.f()
print(b.f())
'''
输出的结果为:
1
hello world
hello world
None
'''
python中提供一种可以判断自定义模块是属于开发阶段还是使用阶段。'name'
系统导入模块的路径
1.内存中:如果之前成功导入过某个模块,直接使用已经存在的模块
2.内置路径中:安全路径下:Lib
PYTHONPATH:import是寻找模块的路径
3.sys.path:是一个路径的列表
如果三个都找不到,就报错。
动态修改sys.path
os.path.dirname():获取到某一个文件的父路径。
通常获取当前脚本(模块)的相对位置,可以获取到每一个文件。
# 查看sys.path内容
# import sys
# print(sys.path)
# 添加b.py所在的路径到sys.path中
# import sys
# sys.path.append(r'D:\Program Files (x86)\DjangoProjects\basic\day15\bbb')
# import bb
# print(bb.a) # 输出的结果为:get it
# # 使用相对位置找到bbb文件夹中的bb
# print(__file__) # 获取当前文件的绝对路径;D:/Program Files (x86)/DjangoProjects/basic/day15/test_imoirt.py
# # 使用os模块获取一个路径的父路径
# import os
# print(os.path.dirname(__file__)) # 获取当前文件的父路径 D:/Program Files (x86)/DjangoProjects/basic/day15
# print(os.path.dirname(__file__)+r'/bbb') # D:/Program Files (x86)/DjangoProjects/basic/day15/bbb
import sys
import os
sys.path.append(os.path.dirname(__file__)+'/bbb')
a = 1
def main():
print(a)
for x in range(3):
print(x)
f()
# __name__属性的使用。
if __name__ == '__main__':
main()
'''
输出的结果为:
1
0
1
2
hello world
'''
'''
__name__属性的使用:
在脚本方式运行的时候:__name__是固定的字符串:__main__
在模块导入运行的时候,__name__就是被导入模块的名字,没有文件的后缀名.py。
在模块方式导入时,__name__就是本模块的名字。
通过__name__属性,我们就可以决定可执行文件中的语句该不该被执行。
'''
'''
自定义模块
'''
# age = 10
#
#
# def f1():
# print('hello')
#
#
# # 测试函数,在开发阶段,对本模块中的功能进行测试。
# # 这个测试函数一般我们是写成main函数的形式。
# def main():
# print(age)
# f1()
#
#
# # 可以快速生成。
# if __name__ == '__main__':
# main()
'''
对于一个新的py文件或者是一个新的模块时,我们一上来要写下面两个东西.
然后根据自己的需求,去写这个模块对应的别的东西。例如变量的定义,函数的定义等等
'''
def main():
pass
if __name__ == '__main__':
main()
Python中引用模块是按照一定的规则以及顺序去寻找的,这个查询顺序为:先从内存中已经加载的模块进行寻找找不到再从内置模块中寻找,内置模块如果也没有,最后去sys.path中路径包含的模块中寻找。它只会按照这个顺序从这些指定的地方去寻找,如果最终都没有找到,那么就会报错。
内存中已经加载的模块->内置模块->sys.path路径中包含的模块
模块的查找顺序
- 在第一次导入某个模块时(比如tbjx),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用(ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看)
- 如果没有,解释器则会查找同名的内置模块
- 如果还没有找到就从sys.path给出的目录列表中依次寻找tbjx.py文件。
需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错
#在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。
> > > import sys
> > > sys.path.append('/a/b/c/d')
> > > sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索
> > > 注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理,
#首先制作归档文件:zip module.zip foo.py bar.py
import sys
sys.path.append('module.zip')
import foo,bar
#也可以使用zip中目录结构的具体位置
sys.path.append('module.zip/lib/python')
#windows下的路径不加r开头,会语法错误
sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a')
#至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。
#需要强调的一点是:只能从.zip文件中导入.py,.pyc等文件。使用C编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降。
接下来我们就开始讲解python常用的内置模块,由于Python常用的模块非常多,我们不可能将所有的模块都讲完, 所以只针对于工作中经常用到模块进行讲解。剩下的模块可以在课余时间自学。
3)import使用
1.import使用
import 翻译过来是一个导入的意思。
这里一定要给同学强调那个文件执行文件,和哪个文件是被执行模块。
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句),如下 import tbjx #只在第一次导入时才执行tbjx.py内代码,此处的显式效果是只打印一次'from the tbjx.py',当然其他的顶级代码也都被执行了,只不过没有显示效果.
代码示例:
import tbjx
import tbjx
import tbjx
import tbjx
import tbjx
执行结果:只是打印一次:
from the tbjx.py
2.第一次导入模块执行三件事
-
创建一个以模块名命名的名称空间。
-
执行这个名称空间(即导入的模块)里面的代码。
-
通过此模块名. 的方式引用该模块里面的内容(变量,函数名,类名等)。 这个名字和变量名没什么区别,都是‘第一类的’,且使用tbjx.名字的方式可以访问tbjx.py文件中定义的名字,tbjx.名字与test.py中的名字来自两个完全不同的地方。
ps:重复导入会直接引用内存中已经加载好的结果
3. 被导入模块有独立的名称空间
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突。
示例:
当前是meet.py
import tbjx.py
name = 'alex'
print(name)
print(tbjx.name)
'''
from the tbjx.py
alex
太白金星
'''
def read1():
print(666)
tbjx.read1()
'''
from the tbjx.py
tbjx模块: 太白金星
'''
name = '日天'
tbjx.change()
print(name)
print(tbjx.name)
'''
from the tbjx.py
日天
barry
'''
4.为模块起别名
1. 好处可以将很长的模块名改成很短,方便使用.
import tbjx as t
t.read1()
from xxx import xxx as xxx
2. 有利于代码的扩展和优化。
#mysql.py
def sqlparse():
print('from mysql sqlparse')
#oracle.py
def sqlparse():
print('from oracle sqlparse')
#test.py
db_type=input('>>: ')
if db_type == 'mysql':
import mysql as db
elif db_type == 'oracle':
import oracle as db
db.sqlparse()
5.导入多个模块
我们以后再开发过程中,免不了会在一个文件中,导入多个模块,推荐写法是一个一个导入。
import os,sys,json # 这样写可以但是不推荐
推荐写法
import os
import sys
import json
多行导入:易于阅读 易于编辑 易于搜索 易于维护。
4)from......import......
1.from......import......使用
from ... import ... 的使用示例。
from tbjx import name, read1
print(name)
read1()
'''
执行结果:
from the tbjx.py
太白金星
tbjx模块: 太白金星
'''
2.from...import... 与import对比
唯一的区别就是:使用from...import...则是将spam中的名字直接导入到当前的名称空间中,所以在当前名称空间中,直接使用名字就可以了、无需加前缀:tbjx.
from...import...的方式有好处也有坏处
好处:使用起来方便了
坏处:容易与当前执行文件中的名字冲突
示例演示:
- 执行文件有与模块同名的变量或者函数名,会有覆盖效果。
name = 'oldboy'
from tbjx import name, read1, read2
print(name)
'''
执行结果:
太白金星
'''
----------------------------------------
from tbjx import name, read1, read2
name = 'oldboy'
print(name)
'''
执行结果:
oldboy
'''
----------------------------------------
def read1():
print(666)
from tbjx import name, read1, read2
read1()
'''
执行结果:
tbjx模块: 太白金星
'''
----------------------------------------
from tbjx import name, read1, read2
def read1():
print(666)
read1()
'''
执行结果:
tbjx模块: 666
'''
2. 当前位置直接使用read1和read2就好了,执行时,仍然以tbjx.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到tbjx.py中寻找全局变量 'alex'
#test.py
from tbjx import read1
name = 'alex'
read1()
'''
执行结果:
from the spam.py
spam->read1->name = '太白金星'
'''
#测试二:导入的函数read2,执行时需要调用read1(),仍然回到tbjx.py中找read1()
#test.py
from tbjx import read2
def read1():
print('==========')
read2()
'''
执行结果:
from the tbjx.py
tbjx->read2 calling read
tbjx->read1->tbjx 'barry'
'''
通过这种方式引用模块也可以对模块进行改名。
from tbjx import read1 as read
read()
3.一行导入多个
from tbjx import read1,read2,name
4.from......import*
from spam import * 把tbjx中所有的不是以下划线(_)开头的名字都导入到当前位置
大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
可以使用all来控制*(用来发布新版本),在tbjx.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
5.模块循环导入问题
模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码
在我们的项目中应该尽量避免出现循环/嵌套导入,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方在程序出现了循环/嵌套导入后的异常分析、解决方法如下(了解,以后尽量避免)
示范文件内容如下
#创建一个m1.py
print('正在导入m1')
from m2 import y
x='m1'
#创建一个m2.py
print('正在导入m2')
from m1 import x
y='m2'
#创建一个run.py
import m1
#测试一
执行run.py会抛出异常
正在导入m1
正在导入m2
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/aa.py", line 1, in <module>
import m1
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module>
from m1 import x
ImportError: cannot import name 'x'
#测试一结果分析
先执行run.py--->执行import m1,开始导入m1并运行其内部代码--->打印内容"正在导入m1"
--->执行from m2 import y 开始导入m2并运行其内部代码--->打印内容“正在导入m2”--->执行from m1 import x,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿x,然而x此时并没有存在于m1中,所以报错
#测试二:执行文件不等于导入文件,比如执行m1.py不等于导入了m1
直接执行m1.py抛出异常
正在导入m1
正在导入m2
正在导入m1
Traceback (most recent call last):
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m2.py", line 2, in <module>
from m1 import x
File "/Users/linhaifeng/PycharmProjects/pro01/1 aaaa练习目录/m1.py", line 2, in <module>
from m2 import y
ImportError: cannot import name 'y'
#测试二分析
执行m1.py,打印“正在导入m1”,执行from m2 import y ,导入m2进而执行m2.py内部代码--->打印"正在导入m2",执行from m1 import x,此时m1是第一次被导入,执行m1.py并不等于导入了m1,于是开始导入m1并执行其内部代码--->打印"正在导入m1",执行from m1 import y,由于m1已经被导入过了,所以无需继续导入而直接问m2要y,然而y此时并没有存在于m2中所以报错
# 解决方法:
方法一:导入语句放到最后
#m1.py
print('正在导入m1')
x='m1'
from m2 import y
#m2.py
print('正在导入m2')
y='m2'
from m1 import x
方法二:导入语句放到函数中
#m1.py
print('正在导入m1')
def f1():
from m2 import y
print(x,y)
x = 'm1'
# f1()
#m2.py
print('正在导入m2')
def f2():
from m1 import x
print(x,y)
y = 'm2'
#run.py
import m1
m1.f1()
5)import和from......import......总结
# 导入模块的多种方式:
# import xxx导入一个模块的所有成员
# import aaa,bbb,....一次性导入多个模块的成员,不推荐这种写法,分开写比较好。因人而异。import os,sys等
# from xxx import aaa.. 从某个模块中导入指定的成员。最大化利用。有用就导入,没有使用我们就不用去导入。
# from xxx import a,b,c 从某个模块中导入多个成员。
# from xxx import * 从某个模块汇总导入所有成员。
# import xxx 和 from xxx import *
# 第一种方式在使用其中成员时,必须使用模块名作为前提。不容易产生命名冲突
# 第二种方式在使用其中成员时,不用使用模块名作为前提,直接使用成员名即可。容易产生命名冲突,在后面定义的成员生效,把前面的覆盖了。
# 怎么解决名称冲突的问题
# 改用import xxx 这种方式导入
# 自己避免使用同名(alias的缩写)
# 使用别名解决冲突 from xxx import xxx as xxx
#
# 也可以给模块起别名 import my_module as m import xxx as xxx,为了方便简化书写。
# from xxx import * 控制成员被导入(__all__只是适合控制这一种导入成员的方式,其余方式都是不可以用的)
# 默认情况下,所有的成员都会被导入
# __all__是一个列表,用于表示本模块可被外界使用的成员。元素是成员名组成的字符串。
# __all__ = []
# __all__ = [
# 'age',
# 'age2'
# ]
# 相对导入:相对导入时导入的是同项目下的模块。
# 只有一种的导入的方式
# from xxx import xxx
# import os
# import sys
# # 把项目所在的父路径加到sys.path中,python的解释器中。os是操作系统相关的路径。
# sys.path.append(os.path.dirname(__file__))
# from xx.y import yy
# print(yy.age2)
# # 使用相对位置找到bbb文件夹中的bb
# print(__file__) # 当前文件的绝对路径;D:/Program Files (x86)/DjangoProjects/basic/day15/test_imoirt.py
# # 使用os模块获取一个路径的父路径
# import os
# print(os.path.dirname(__file__)) # 获取当前文件的父路径 D:/Program Files (x86)/DjangoProjects/basic/day15
# print(os.path.dirname(__file__)+r'/bbb') # D:/Program Files (x86)/DjangoProjects/basic/day15/bbb
