


Mybatis缓存
1.一级缓存
1>. 什么是一级缓存? 为什么使用一级缓存?
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,
而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,
当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
如下图所示,MyBatis会在一次会话的表示----一个SqlSession对象中创建一个本地缓存(local cache),对于每一次查询,
都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;
否则,从数据库读取数据,将查询结果存入缓存并返回给用户

对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存
2>. MyBatis中的一级缓存是怎样组织的?(即SqlSession中的缓存是怎样组织的?)
由于MyBatis使用SqlSession对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在SqlSession中控制的。
SqlSession只是一个MyBatis对外的接口,SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。
当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,
MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。
SqlSession、Executor、Cache之间的关系如下列类图所示:
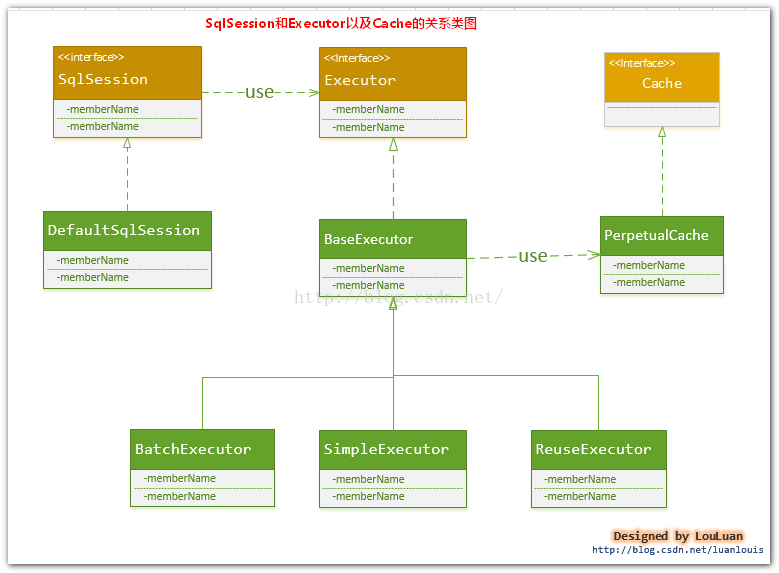
如上述的类图所示,Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,
则对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
综上,SqlSession对象、Executor对象、Cache对象之间的关系如下图所示:
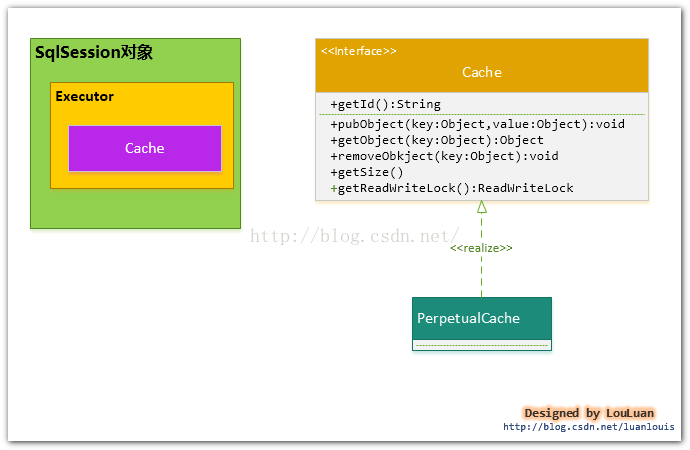
PerpetualCache实现原理其实很简单,其内部就是通过一个简单的HashMap<k,v>
来实现的,没有其他的任何限制。如下是PerpetualCache的实现代码:
package org.apache.ibatis.cache.impl; import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks.ReentrantReadWriteLock; import org.apache.ibatis.cache.Cache; import org.apache.ibatis.cache.CacheException; public class PerpetualCache implements Cache { private String id; <strong>private Map<Object, Object> cache = new HashMap<Object, Object>();</strong> private ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); public PerpetualCache(String id) { this.id = id; } public String getId() { return id; } public int getSize() { return cache.size(); } public void putObject(Object key, Object value) { cache.put(key, value); } public Object getObject(Object key) { return cache.get(key); } public Object removeObject(Object key) { return cache.remove(key); } public void clear() { cache.clear(); } public ReadWriteLock getReadWriteLock() { return readWriteLock; } public boolean equals(Object o) { if (getId() == null) throw new CacheException("Cache instances require an ID."); if (this == o) return true; if (!(o instanceof Cache)) return false; Cache otherCache = (Cache) o; return getId().equals(otherCache.getId()); } public int hashCode() { if (getId() == null) throw new CacheException("Cache instances require an ID."); return getId().hashCode(); } }
3>.一级缓存的生命周期有多长?
a.MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,
Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
b.如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
c.如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
d.SqlSession中执行了任何一个update操作(update()、delete()、insert()),都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
4>. SqlSession 一级缓存的工作流程:
1.对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果;
2. 判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;
3. 如果命中,则直接将缓存结果返回;
4. 如果没命中:
4.1 去数据库中查询数据,得到查询结果;
4.2 将key和查询到的结果分别作为key,value对存储到Cache中;
4.3. 将查询结果返回;
5. 结束。
5>.Cache中Map的key值:CacheKey
MyBatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
1. 传入的statementId
传入的statementId,对于MyBatis而言,你要使用它,必须需要一个statementId,它代表着你将执行什么样的Sql;
2. 查询时要求的结果集中的结果范围(结果的范围通过rowBounds.offset和rowBounds.limit表示);
3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql())
4. 传递给java.sql.Statement要设置的参数值
综上所述,CacheKey由以下条件决定:statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值
原文: http://www.xuebuyuan.com/2231229.html
2.二级缓存
1>.MyBatis的缓存机制整体设计以及二级缓存的工作模式
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
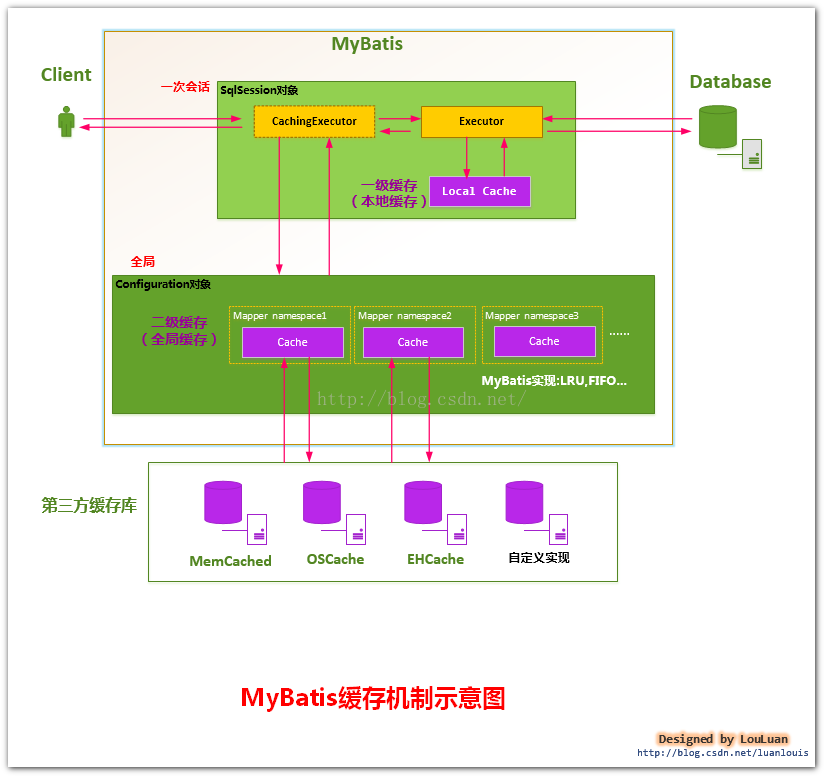
如上图所示,当开一个会话时,一个 SqlSession 对象会使用一个 Executor 对象来完成会话操作,
MyBatis 的二级缓存机制的关键就是对这个 Executor 对象做文章。如果用户配置了" cacheEnabled=true ",
那么 MyBatis 在为 SqlSession 对象创建 Executor 对象时,会对 Executor 对象加上一个装饰者: CachingExecutor ,
这时 SqlSession 使用 CachingExecutor 对象来完成操作请求。
CachingExecutor 对于查询请求,会先判断该查询请求在 Application 级别的二级缓存中是否有缓存结果,
如果有查询结果,则直接返回缓存结果;
如果缓存中没有,再交给真正的 Executor 对象来完成查询操作,
之后 CachingExecutor 会将真正 Executor 返回的查询结果放置到缓存中,然后再返回给用户。

CachingExecutor是Executor的装饰者,以增强Executor的功能,使其具有缓存查询的功能,这里用到了设计模式中的装饰者模式。
MyBatis二级缓存的划分
MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,
它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下:
a.为每一个Mapper分配一个Cache缓存对象(使用<cache>节点配置);
b.多个Mapper共用一个Cache缓存对象(使用<cache-ref>节点配置);
使用二级缓存,必须要具备的条件
MyBatis对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。
虽然在Mapper中配置了<cache>,并且为此Mapper分配了Cache对象,
这并不表示我们使用Mapper中定义的查询语句查到的结果都会放置到Cache对象之中,
我们必须指定Mapper中的某条选择语句是否支持缓存,即在<select>节点中配置useCache="true" ,
Mapper才会对此Select的查询支持缓存特性,
<cache eviction="FIFO" <!--回收策略为先进先出--> flushInterval="60000" <!--自动刷新时间60s--> size="512" <!--最多缓存512个引用对象--> readOnly="true"/> <!--只读-->
二级缓存作用域为 Mapper(Namespace);(整个项目期间application)
configuration.MappedStatement.Cache;项目启动时会初始化;
Mybatis框架在初始化阶段会对XML配置文件进行读取,将其中的sql语句节点对象化为一个个MappedStatement对象,
即一个<select />、<update />或者<insert />标签;
总之,要想使某条Select查询支持二级缓存,你需要保证:
1.MyBatis支持二级缓存的总开关:全局配置变量参数cacheEnabled=true
2.该select语句所在的Mapper,配置了<cache> 或<cached-ref>节点,并且有效
3.该select语句的参数useCache=true
一级缓存和二级缓存的使用顺序 :
二级缓存———> 一级缓存——> 数据库
二级缓存实现的选择
MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;
另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,
然后将Cache实现类配置在<cache type="">节点的type属性上即可;
除此之外,MyBatis还支持跟第三方内存缓存库如Memecached的集成,总之,使用MyBatis的二级缓存有三个选择:
1.MyBatis自身提供的缓存实现;
2.用户自定义的Cache接口实现;
3.跟第三方内存缓存库的集成;
MyBatis自身提供的二级缓存的实现
MyBatis自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的Cache接口装饰者,可以满足各种对缓存操作和更新的策略。
MyBatis定义了大量的Cache的装饰器来增强Cache缓存的功能,如下类图所示。
对于每个Cache而言,都有一个容量限制,MyBatis各供了各种策略来对Cache缓存的容量进行控制,以及对Cache中的数据进行刷新和置换。
MyBatis主要提供了以下几个刷新和置换策略:
LRU:(Least Recently Used),最近最少使用算法,即如果缓存中容量已经满了,会将缓存中最近做少被使用的缓存记录清除掉,然后添加新的记录;
FIFO:(First in first out),先进先出算法,如果缓存中的容量已经满了,那么会将最先进入缓存中的数据清除掉;
Scheduled:指定时间间隔清空算法,该算法会以指定的某一个时间间隔将Cache缓存中的数据清空;

三、Cache使用时的注意事项/避免使用二级缓存
注意事项
1. 只能在【只有单表操作】的表上使用缓存
不只是要保证这个表在整个系统中只有单表操作,而且和该表有关的全部操作必须全部在一个namespace下。
2. 在可以保证查询远远大于insert,update,delete操作的情况下使用缓存
这一点不需要多说,所有人都应该清楚。记住,这一点需要保证在1的前提下才可以!
避免使用二级缓存
1.缓存是以namespace为单位的,不同namespace下的操作互不影响。
2.insert,update,delete操作会清空所在namespace下的全部缓存。
3.通常使用MyBatis Generator生成的代码中,都是各个表独立的,每个表都有自己的namespace。
针对一个表的某些操作不在它独立的namespace下进行。
例如在UserMapper.xml中有大多数针对user表的操作。但是在一个XXXMapper.xml中,还有针对user单表的操作.
这会导致user在两个命名空间下的数据不一致。如果在UserMapper.xml中做了刷新缓存的操作,
在XXXMapper.xml中缓存仍然有效,如果有针对user的单表查询,使用缓存的结果可能会不正确。
更危险的情况是在XXXMapper.xml做了insert,update,delete操作时,会导致UserMapper.xml中的各种操作充满未知和风险。
有关这样单表的操作可能不常见。但是你也许想到了一种常见的情况。
多表操作一定不能使用缓存
首先不管多表操作写到那个namespace下,都会存在某个表不在这个namespace下的情况。
例如两个表:role和user_role,如果我想查询出某个用户的全部角色role,就一定会涉及到多表的操作。
<select id="selectUserRoles" resultType="UserRoleVO">
select * from user_role a,role b where a.roleid = b.roleid and a.userid = #{userid}
</select>
像上面这个查询,你会写到那个xml中呢??
不管是写到RoleMapper.xml还是UserRoleMapper.xml,或者是一个独立的XxxMapper.xml中。如果使用了二级缓存,都会导致上面这个查询结果可能不正确。
如果你正好修改了这个用户的角色,上面这个查询使用缓存的时候结果就是错的。
最后还是建议,放弃二级缓存,在业务层使用可控制的缓存代替更好。
参考:
http://www.th7.cn/Program/java/201411/321081.shtml
http://blog.csdn.net/isea533/article/details/44566257
部分源码: Reader reader = Resources.getResourceAsReader("mybatis.cfg.xml"); SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(reader); SqlSession session = ssf.openSession(); session.selectOne("selectUser", "3"); ****************************************************************** 1.SqlSessionFactoryBuilder类 build() ----------------------------------------------------------- public SqlSessionFactory build(Configuration config) { return new DefaultSqlSessionFactory(config); } 2.DefaultSqlSessionFactory类 openSession() ----------------------------------------------------------- private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { final Environment environment = configuration.getEnvironment(); final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); final Executor executor = configuration.newExecutor(tx, execType, autoCommit); return new DefaultSqlSession(configuration, executor); } catch (Exception e) { closeTransaction(tx); // may have fetched a connection so lets call close() throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } } 3.Configuration类 newExecutor() ----------------------------------------------------------- public Executor newExecutor(Transaction transaction, ExecutorType executorType, boolean autoCommit) { executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } if (cacheEnabled) {//装饰模式 executor = new CachingExecutor(executor, autoCommit); } executor = (Executor) interceptorChain.pluginAll(executor); return executor; } 4.SimpleExecutor类 extends BaseExecutor ----------------------------------------------------------- BaseExecutor类 protected PerpetualCache localCache; PerpetualCache类 private Map<Object, Object> cache = new HashMap<Object, Object>(); BaseExecutor类 query()方法 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;//先从一级缓存中查 if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);//一级缓存中没有命中,从db查 } 5.CachingExecutor类 query()方法 ----------------------------------------------------------- private Executor delegate;//装饰者模式,默认BaseExecutor.query() cache.getReadWriteLock().readLock().lock();//加锁 try { List<E> cachedList = (List<E>) cache.getObject(key);//先从二级缓存中查 if (cachedList != null) return cachedList; } finally { cache.getReadWriteLock().readLock().unlock();//去锁 } //二级缓存中没有命中,从delegate中查(默认BaseExecutor.query() 从一级缓存中查,一级缓存中没有就从db中查) List<E> list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);

