

如何迁移Alwayson AG
Windows cluster要求同一个cluster中的所有windows版本都是相同的,这样就出现一个问题,当我们要将对windows进行升级时,(例如从windows 2008 R2升级到windows 2012)不得不搭建一套新的windows cluster。你可以选择使用新的硬件搭建,或者将现有windows cluster中的节点一台一台的evict掉,重装/升级系统后加入到新的windows cluster中。具体的cluster升级方案我就不在这里讨论。马上进入主题:
SQL Server AlwaysOn Availability Group (后文简称为AG) 的一个要求是:所有的replica都要求隶属于同一个windows cluster。
 所以当我们对windows cluster进行升级时,无法在新的windows cluster和现有的windows cluster之间建立AG。那么在迁移过程中会有一段时间内AG无法对外提供服务。
所以当我们对windows cluster进行升级时,无法在新的windows cluster和现有的windows cluster之间建立AG。那么在迁移过程中会有一段时间内AG无法对外提供服务。
从数据库的角度上说,我们需要做下面的事情
- 接下来停止应用并删除cluster1中的Listener,确保没有外界来接使用SQL SERVER.
- Backup database
- Backup tail log
- 将备份文件copy到新的服务器
- Restore 到各个服务器
- 然后重新建立AG
- 创建Listener
- 重启应用
我们需要将数据库备份并还原到新的primary replica和secondary replica。 相应的downtime时间就是1+2+3+4+5+6+7+8想要的时间。 或许你想到了在新旧cluster之间创建一个mirroring,但遗憾的是,创建了AG的数据库是不再允许创建mirroring的.
那应当如何进行迁移呢?从SQL Server 2012 SP1 开始,允许在两套不同的windows cluster之间创建AG。下面用一个例子说明一下
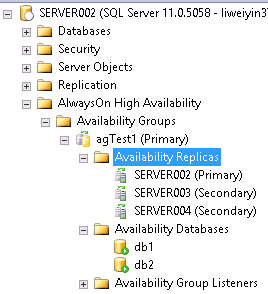
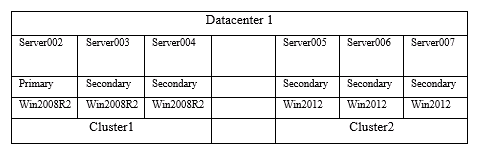
有一个三个节点的windows cluster, windows版本为Windows 2008 R2
Domain:liweiyin3.lab
Cluster name: cluster1
Server002
Server003
Server004
Listener name: Listener1
三个节点上装有SQL Server 2012 SP1的standalone实例。均为默认实例。
之间建立了AG.拓扑图如下:

现在创建一套两个节点的windows 2012的windows cluster
Domain:liweiyin3.lab
Cluster name: cluster2
Server005
Server006
|
Datacenter 1 |
|
|
Server005 |
Server006 |
|
Win 2012 |
Win2012 |
|
Cluster2 |
|
两个cluster中间创建AG:
- 对cluster1上的AG数据库进行备份,包含full database backup和log backup
- 将第一步得到的文件在cluster2的节点上进行还原,指定为with norecovery.
-
接下来在cluster2的三个数据库上执行下面的语句
ALTER SERVER CONFIGURATION SET HADR CLUSTER CONTEXT='cluster1.liweiyin3.lab'
这条语句执行完毕后,这台数据库的cluster context就会切换为cluster1了。这个结果可以从下面的DMV中检查到
select cluster_name from sys.dm_hadr_cluster

4.接下就可以在cluster1和cluster2之间建立AG。我们可以使用UI或者T-SQL语句。需要注意的是,请将cluster2中的至少一个SQL Server的同步模式设置为Synchronous commit,以保证迁移是没有数据损失的。

这样,我们就建立了一套既包含win 2008R2,也包含win 2012的AG环境了。并且也可以正常地向外界提供服务,整个过程不需要downtime.

但需要注意的是,这种情况下是不允许在两个cluster之间进行failover的。相应的提示信息如下
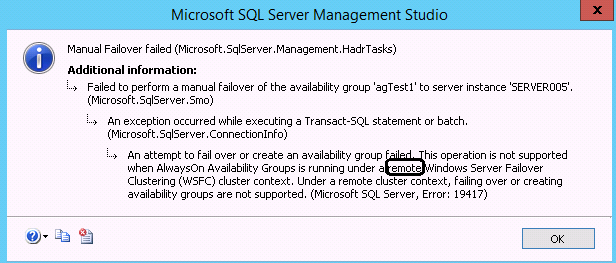 An attempt to fail over or create an availability group failed. This operation is not supported when AlwaysOn Availability Groups is running under a remote Windows Server Failover Clustering (WSFC) cluster context. Under a remote cluster context, failing over or creating availability groups are not supported.
An attempt to fail over or create an availability group failed. This operation is not supported when AlwaysOn Availability Groups is running under a remote Windows Server Failover Clustering (WSFC) cluster context. Under a remote cluster context, failing over or creating availability groups are not supported.
5.接下来停止应用并删除cluster1中的Listener,确保没有外界来接使用SQL SERVE
6.在Cluster1将AG进行offline操作
ALTER AVAILABILITY GROUP agName offline
7.将cluster2中所有sql server的CLUSTER CONTEXT切换回来
ALTER SERVER CONFIGURATION SET HADR CLUSTER CONTEXT=local
8.在cluster2中重新创建AG
9.在cluster2中创建新的listener
10.重启应用
这样所涉及的downtime就是5+6+7+8+9+10
和之前的解决方案相比,省去了backup,文件copy和restore的时间。其余的操作都是句操作,很大程度地减少了downtime。
更多信息
===
迁移之前,Cluster2中的sql server不允许创建任何AG。
迁移之前需要授予cluster2中的sql server启动账号访问cluster1注册表的权限
在第六步“在Cluster1中将AG进行offline操作”之前在各个AG 数据库中执行checkpoint,以前少cluster2中数据库的recovery时间。
对于multiply subnet场景,则需要在各自的子网内创建新的cluster,然后搭建AG。
Change the HADR Cluster Context of Server Instance (SQL Server) http://msdn.microsoft.com/en-us/library/jj573601.aspx
-----------------------3/1/2017----------------
Distributed Availability Groups is a better choice :)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号