3-Python语法基础+数据结构+函数+文件
🍭 第 3 章 Python 语法基础 + 数据结构 + 函数 + 文件
🚨 因为这本书是专注于 Python 数据处理的,对于一些 Python 的数据结构和库的特性难免不足。因此,本章和第 3 章的 Python 知识只够你能学习本书后面的内容。
😀 就作为对于前段时间跟随廖雪峰老师的 Python 笔记学习的一个总结回顾吧
3.1 Python 语法基础
1. 语言的语义
Python 的语言设计强调的是可读性、简洁和清晰。有些人称 Python 为“可执行的伪代码”。
2. 使用缩进,而不是括号
Python使用空白字符(tab和空格)来组织代码,而不是像其它语言,比如R、C++、JAVA和Perl那样使用括号。看一个排序算法的for循环:
for x in array:
if x < pivot:
less.append(x)
else:
greater.append(x)
冒号标志着缩进代码块的开始,冒号之后的所有代码的缩进量必须相同,直到代码块结束。不管是否喜欢这种形式,使用空白符是Python程序员开发的一部分,在我看来,这可以让python的代码可读性大大优于其它语言。
Notes:我强烈建议你使用四个空格作为默认的缩进,可以使用tab代替四个空格。许多文本编辑器的设置是使用制表位替代空格。某些人使用tabs或不同数目的空格数,常见的是使用两个空格。大多数情况下,四个空格是大多数人采用的方法,因此建议你也这样做。
你应该已经看到,Python的语句不需要用分号结尾。但是,分号却可以用来给同在一行的语句切分:
a = 5; b = 6; c = 7
Python不建议将多条语句放到一行,这会降低代码的可读性。
3. 万物皆对象
Python语言的一个重要特性就是它的对象模型的一致性。每个数字、字符串、数据结构、函数、类、模块等等,都是在Python解释器的自有“盒子”内,它被认为是Python对象。每个对象都有类型(例如,字符串或函数)和内部数据。在实际中,这可以让语言非常灵活,因为函数也可以被当做对象使用。
4. 注释
任何前面带有井号 # 的文本都会被 Python 解释器忽略。这通常被用来添加注释。有时,你会想排除一段代码,但并不删除。简便的方法就是将其注释掉:
results = []
for line in file_handle:
# keep the empty lines for now
# if len(line) == 0:
# continue
results.append(line.replace('foo', 'bar'))
也可以在执行过的代码后面添加注释。一些人习惯在代码之前添加注释,前者这种方法有时也是有用的:
print("Reached this line") # Simple status report
5. 函数和对象方法调用
你可以用圆括号调用函数,传递零个或几个参数,或者将返回值给一个变量:
result = f(x, y, z)
几乎Python中的每个对象都有附加的函数,称作方法,可以用来访问对象的内容。可以用下面的语句调用:
obj.some_method(x, y, z)
函数可以使用位置和关键词参数:
result = f(a, b, c, d=5, e='foo')
后面会有更多介绍。
6. 变量和参数传递
当在Python 中创建变量(或名字),你就在等号右边创建了一个对这个变量的引用。考虑一个整数列表:
In [8]: a = [1, 2, 3]
假设将 a 赋值给一个新变量 b:
In [9]: b = a
在有些方法中,这个赋值会将数据[1, 2, 3] 也复制。在Python中,a 和 b 实际上是同一个对象,即原有列表[1, 2, 3](见图2-7)。你可以在 a 中添加一个元素,然后检查 b:
In [10]: a.append(4)
In [11]: b
Out[11]: [1, 2, 3, 4]
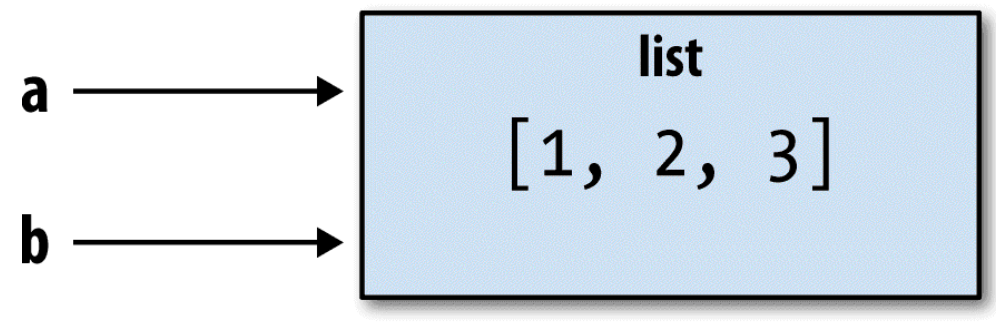
理解Python的引用的含义,数据是何时、如何、为何复制的,是非常重要的。尤其是当你用 Python 处理大的数据集时。
🚩 Notes:赋值也被称作绑定,我们是把一个名字绑定给一个对象。变量名有时可能被称为绑定变量。
当你将对象作为参数传递给函数时,新的局域变量创建了对原始对象的引用,而不是复制。如果在函数里绑定一个新对象到一个变量,这个变动不会反映到上一层。因此可以改变可变参数的内容。假设有以下函数:
def append_element(some_list, element):
some_list.append(element)
然后有:
In [27]: data = [1, 2, 3]
In [28]: append_element(data, 4)
In [29]: data
Out[29]: [1, 2, 3, 4]
7. 动态引用,强类型
与许多编译语言(如JAVA和C++)对比,Python中的对象引用不包含附属的类型。下面的代码是没有问题的:
In [12]: a = 5
In [13]: type(a)
Out[13]: int
In [14]: a = 'foo'
In [15]: type(a)
Out[15]: str
变量是在特殊命名空间中的对象的名字,类型信息保存在对象自身中。一些人可能会说Python不是“类型化语言”。这是不正确的,看下面的例子:
In [16]: '5' + 5
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-f9dbf5f0b234> in <module>()
----> 1 '5' + 5
TypeError: must be str, not int
在某些语言中,例如Visual Basic,字符串‘5’可能被默许转换(或投射)为整数,因此会产生10。但在其它语言中,例如JavaScript,整数5会被投射成字符串,结果是联结字符串‘55’。在这个方面,Python被认为是强类型化语言,意味着每个对象都有明确的类型(或类),默许转换只会发生在特定的情况下,例如:
In [17]: a = 4.5
In [18]: b = 2
# String formatting, to be visited later
In [19]: print('a is {0}, b is {1}'.format(type(a), type(b)))
a is <class 'float'>, b is <class 'int'>
In [20]: a / b
Out[20]: 2.25
知道对象的类型很重要,最好能让函数可以处理多种类型的输入。你可以用isinstance函数检查对象是某个类型的实例:
In [21]: a = 5
In [22]: isinstance(a, int)
Out[22]: True
isinstance可以用类型元组,检查对象的类型是否在元组中:
In [23]: a = 5; b = 4.5
In [24]: isinstance(a, (int, float))
Out[24]: True
In [25]: isinstance(b, (int, float))
Out[25]: True
8. 属性和方法
Python 的对象通常都有属性(其它存储在对象内部的Python对象)和方法(对象的附属函数可以访问对象的内部数据)。可以用obj.attribute_name访问属性和方法:
In [1]: a = 'foo'
In [2]: a.<Press Tab>
a.capitalize a.format a.isupper a.rindex a.strip
a.center a.index a.join a.rjust a.swapcase
a.count a.isalnum a.ljust a.rpartition a.title
a.decode a.isalpha a.lower a.rsplit a.translate
a.encode a.isdigit a.lstrip a.rstrip a.upper
a.endswith a.islower a.partition a.split a.zfill
a.expandtabs a.isspace a.replace a.splitlines
a.find a.istitle a.rfind a.startswith
也可以用getattr函数,通过名字访问属性和方法:
In [27]: getattr(a, 'split')
Out[27]: <function str.split>
在其它语言中,访问对象的名字通常称作“反射”。本书不会大量使用getattr函数和相关的hasattr和setattr函数,使用这些函数可以高效编写原生的、可重复使用的代码。
9. 鸭子类型
经常地,你可能不关心对象的类型,只关心对象是否有某些方法或用途。这通常被称为“鸭子类型”,来自“走起来像鸭子、叫起来像鸭子,那么它就是鸭子”的说法。例如,你可以通过验证一个对象是否遵循迭代协议,判断它是可迭代的。对于许多对象,这意味着它有一个__iter__魔术方法,其它更好的判断方法是使用iter函数:
def isiterable(obj):
try:
iter(obj)
return True
except TypeError: # not iterable
return False
这个函数会返回字符串以及大多数Python集合类型为True:
In [29]: isiterable('a string')
Out[29]: True
In [30]: isiterable([1, 2, 3])
Out[30]: True
In [31]: isiterable(5)
Out[31]: False
我总是用这个功能编写可以接受多种输入类型的函数。常见的例子是编写一个函数可以接受任意类型的序列(list、tuple、ndarray)或是迭代器。你可先检验对象是否是列表(或是 NumPy 数组),如果不是的话,将其转变成列表:
if not isinstance(x, list) and isiterable(x):
x = list(x)
10. 引入自定义模块
在 Python 中,模块就是一个有.py扩展名、包含 Python 代码的文件。假设有以下模块:
# some_module.py
PI = 3.14159
def f(x):
return x + 2
def g(a, b):
return a + b
如果想从同目录下的另一个文件访问some_module.py中定义的变量和函数,可以:
import some_module
result = some_module.f(5)
pi = some_module.PI
或者:
from some_module import f, g, PI
result = g(5, PI)
🚩 使用as关键词,你可以给引入起不同的变量名:
import some_module as sm
from some_module import PI as pi, g as gf
r1 = sm.f(pi)
r2 = gf(6, pi)
11. 二元运算符和比较运算符
大多数二元数学运算和比较都不难想到:
In [32]: 5 - 7
Out[32]: -2
In [33]: 12 + 21.5
Out[33]: 33.5
In [34]: 5 <= 2
Out[34]: False
下表列出了所有的二元运算符:
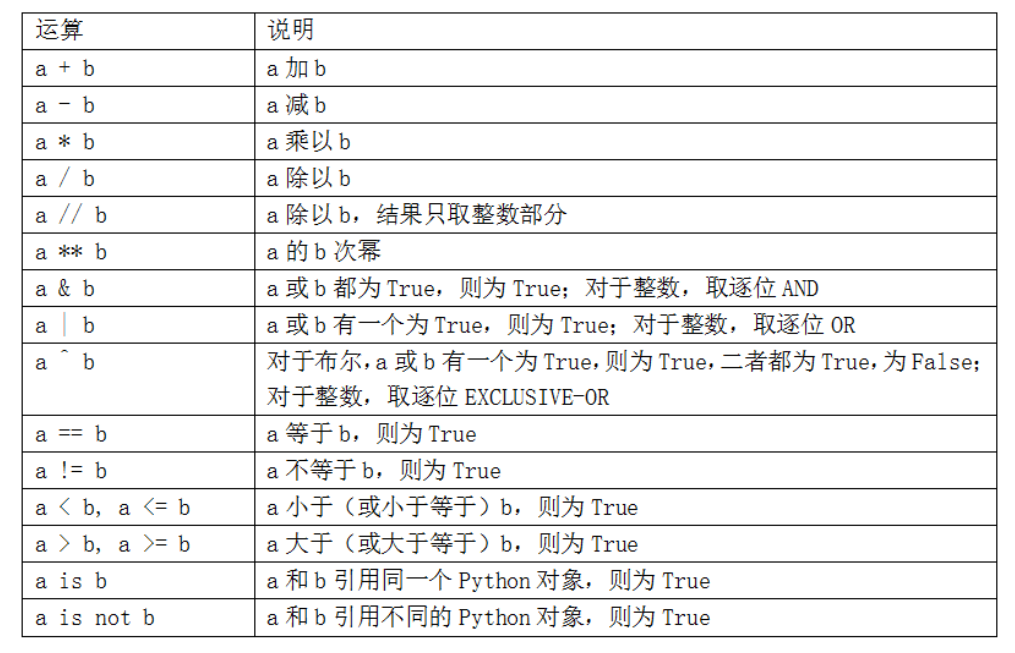
要判断两个引用是否指向同一个对象,可以使用is方法。is not可以判断两个对象是不同的:
In [35]: a = [1, 2, 3]
In [36]: b = a
In [37]: c = list(a)
In [38]: a is b
Out[38]: True
In [39]: a is not c
Out[39]: True
因为 🚩 list总是创建一个新的Python列表(即复制),我们可以断定c是不同于a的。使用is比较与==运算符不同,如下:
In [40]: a == c
Out[40]: True
is和is not常用来判断一个变量是否为None,因为只有一个None的实例:
In [41]: a = None
In [42]: a is None
Out[42]: True
12. 可变与不可变对象
Python 中的大多数对象,比如列表、字典、NumPy 数组,和用户定义的类型(类),都是可变的。意味着这些对象或包含的值可以被修改:
In [43]: a_list = ['foo', 2, [4, 5]]
In [44]: a_list[2] = (3, 4)
In [45]: a_list
Out[45]: ['foo', 2, (3, 4)]
其它的,例如字符串和元组,是不可变的:
In [46]: a_tuple = (3, 5, (4, 5))
In [47]: a_tuple[1] = 'four'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-47-b7966a9ae0f1> in <module>()
----> 1 a_tuple[1] = 'four'
TypeError: 'tuple' object does not support item assignment
记住,可以修改一个对象并不意味就要修改它。这被称为副作用。例如,当写一个函数,任何副作用都要在文档或注释中写明。如果可能的话,我推荐避免副作用,采用不可变的方式,即使要用到可变对象。
13. 标量类型
Python 的标准库中有一些内建的类型,用于处理数值数据、字符串、布尔值,和日期时间。这些单值类型被称为标量类型,本书中称其为标量。下表列出了主要的标量。日期和时间处理会另外讨论,因为它们是标准库的datetime模块提供的。
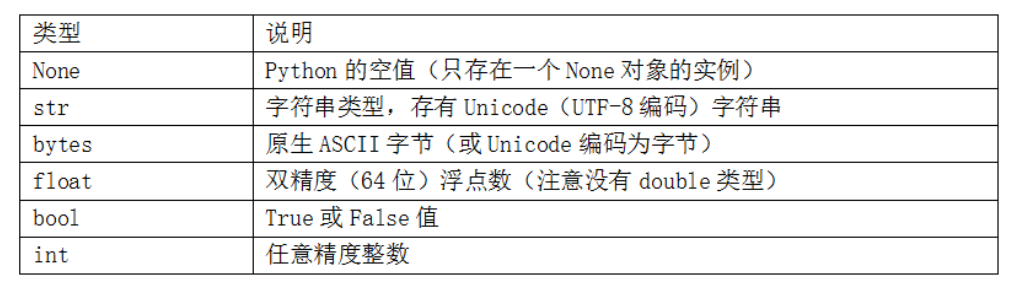
14. 数值类型
Python 的主要数值类型是int和float。👍 int可以存储任意大的数:
In [48]: ival = 17239871
In [49]: ival ** 6
Out[49]: 26254519291092456596965462913230729701102721
浮点数使用Python的float类型。每个数都是双精度(64位)的值。也可以用科学计数法表示:
In [50]: fval = 7.243
In [51]: fval2 = 6.78e-5
不能得到整数的除法会得到浮点数:
In [52]: 3 / 2
Out[52]: 1.5
要获得 C-风格 的整除(去掉小数部分),可以使用底除运算符//:
In [53]: 3 // 2
Out[53]: 1
15. 字符串
许多人是因为Python强大而灵活的字符串处理而使用Python的。你可以用单引号或双引号来写字符串:
a = 'one way of writing a string'
b = "another way"
对于有换行符的字符串,可以使用三引号,'''或"""都行:
c = """
i love you
"""
print(c) # '\ni love you\n'
字符串c实际包含 3 行文本,""" 后面和 you 后面的换行符。可以用count方法计算c中的新的行:
In [55]: c.count('\n')
Out[55]: 2
⭐ Python 的字符串是不可变的,不能修改字符串:
In [56]: a = 'this is a string'
In [57]: a[10] = 'f'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-57-5ca625d1e504> in <module>()
----> 1 a[10] = 'f'
TypeError: 'str' object does not support item assignment
In [58]: b = a.replace('string', 'longer string')
In [59]: b
Out[59]: 'this is a longer string'
经过以上的操作,变量a并没有被修改:
In [60]: a
Out[60]: 'this is a string'
许多 Python 对象使用str函数可以被转化为字符串:
In [61]: a = 5.6
In [62]: s = str(a)
In [63]: type(s)
str
字符串是一个序列的 Unicode 字符,因此可以像其它序列,比如列表和元组一样处理:
In [64]: s = 'python'
In [65]: list(s)
Out[65]: ['p', 'y', 't', 'h', 'o', 'n']
In [66]: s[:3]
Out[66]: 'pyt'
语法s[:3]被称作切片,适用于许多Python序列。后面会更详细的介绍,本书中用到很多切片。
反斜杠是转义字符,意思是它备用来表示特殊字符,比如换行符 \n 或 Unicode 字符。要写一个包含反斜杠的字符串,需要进行转义:
In [67]: s = '12\\34'
In [68]: print(s)
12\34
如果字符串中包含许多反斜杠,但没有特殊字符,这样做就很麻烦。🚩 可以在字符串前面加一个 r,表明字符就是它自身:
In [69]: s = r'this\has\no\special\characters'
In [70]: s
Out[70]: 'this\\has\\no\\special\\characters'
print(s) # this\has\no\special\characters
r 表示 raw。
将两个字符串合并,会产生一个新的字符串:
In [71]: a = 'this is the first half '
In [72]: b = 'and this is the second half'
In [73]: a + b
Out[73]: 'this is the first half and this is the second half'
⭐ 字符串的模板化或格式化,是另一个重要的主题。Python 3 拓展了此类的方法,这里只介绍一些。字符串对象有format方法,可以替换格式化的参数为字符串,产生一个新的字符串:
In [74]: template = '{0:.2f} {1:s} are worth US${2:d}'
在这个字符串中,
{0:.2f}表示格式化第一个参数为带有两位小数的浮点数。{1:s}表示格式化第二个参数为字符串。{2:d}表示格式化第三个参数为一个整数。
要替换参数为这些格式化的参数,我们传递format方法一个序列:
In [75]: template.format(4.5560, 'Argentine Pesos', 1)
Out[75]: '4.56 Argentine Pesos are worth US$1'
字符串格式化是一个很深的主题,有多种方法和大量的选项,可以控制字符串中的值是如何格式化的。推荐参阅Python官方文档。
这里概括介绍字符串处理,第 8 章的数据分析会详细介绍。
16. 字节和 Unicode
在 Python 3 及以上版本中,Unicode 是一级的字符串类型,这样可以更一致的处理 ASCII 和 Non-ASCII 文本。在老的 Python 版本中,字符串都是字节,不使用 Unicode 编码。假如知道字符编码,可以将其转化为Unicode。看一个例子:
In [76]: val = "español"
In [77]: val
Out[77]: 'español'
可以用encode将这个Unicode字符串编码为UTF-8:
In [78]: val_utf8 = val.encode('utf-8')
In [79]: val_utf8
Out[79]: b'espa\xc3\xb1ol'
In [80]: type(val_utf8)
Out[80]: bytes
如果你知道一个字节对象的Unicode编码,用decode方法可以解码:
In [81]: val_utf8.decode('utf-8')
Out[81]: 'español'
虽然 UTF-8 编码已经变成主流,但因为历史的原因,你仍然可能碰到其它编码的数据:
In [82]: val.encode('latin1')
Out[82]: b'espa\xf1ol'
In [83]: val.encode('utf-16')
Out[83]: b'\xff\xfee\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
In [84]: val.encode('utf-16le')
Out[84]: b'e\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
工作中碰到的文件很多都是字节对象,盲目地将所有数据编码为Unicode是不可取的。
虽然用的不多,你可以在字节文本的前面加上一个b:
In [85]: bytes_val = b'this is bytes'
In [86]: bytes_val
Out[86]: b'this is bytes'
In [87]: decoded = bytes_val.decode('utf8')
In [88]: decoded # this is str (Unicode) now
Out[88]: 'this is bytes'
17. 布尔值
Python 中的布尔值有两个,True 和 False。比较和其它条件表达式可以用 True 和 False 判断。布尔值可以与 and 和 or 结合使用:
In [89]: True and True
Out[89]: True
In [90]: False or True
Out[90]: True
18. 类型转换
⭐ str、bool、int 和 float 也是函数,可以用来转换类型:
In [91]: s = '3.14159'
In [92]: fval = float(s)
In [93]: type(fval)
Out[93]: float
In [94]: int(fval)
Out[94]: 3
In [95]: bool(fval)
Out[95]: True
In [96]: bool(0)
Out[96]: False
19. None
None 是 Python 的空值类型。如果一个函数没有明确的返回值,就会默认返回 None:
In [97]: a = None
In [98]: a is None
Out[98]: True
In [99]: b = 5
In [100]: b is not None
Out[100]: True
🚩 None 也常常作为函数的默认参数:
def add_and_maybe_multiply(a, b, c=None):
result = a + b
if c is not None:
result = result * c
return result
另外,None 不仅是一个保留字,还是唯一的 NoneType 的实例:
In [101]: type(None)
Out[101]: NoneType
20. 日期和时间
Python内建的datetime模块提供了datetime、date和time类型。datetime类型结合了date和time,是最常使用的:
In [102]: from datetime import datetime, date, time
In [103]: dt = datetime(2011, 10, 29, 20, 30, 21)
In [104]: dt.day
Out[104]: 29
In [105]: dt.minute
Out[105]: 30
根据datetime实例,你可以用date和time提取出各自的对象:
In [106]: dt.date()
Out[106]: datetime.date(2011, 10, 29)
In [107]: dt.time()
Out[107]: datetime.time(20, 30, 21)
strftime方法可以将 datetime 格式化为字符串:
In [108]: dt.strftime('%m/%d/%Y %H:%M')
Out[108]: '10/29/2011 20:30'
strptime可以将字符串转换成datetime对象:
In [109]: datetime.strptime('20091031', '%Y%m%d')
Out[109]: datetime.datetime(2009, 10, 31, 0, 0)
👇 下表列出了所有的格式化命令:
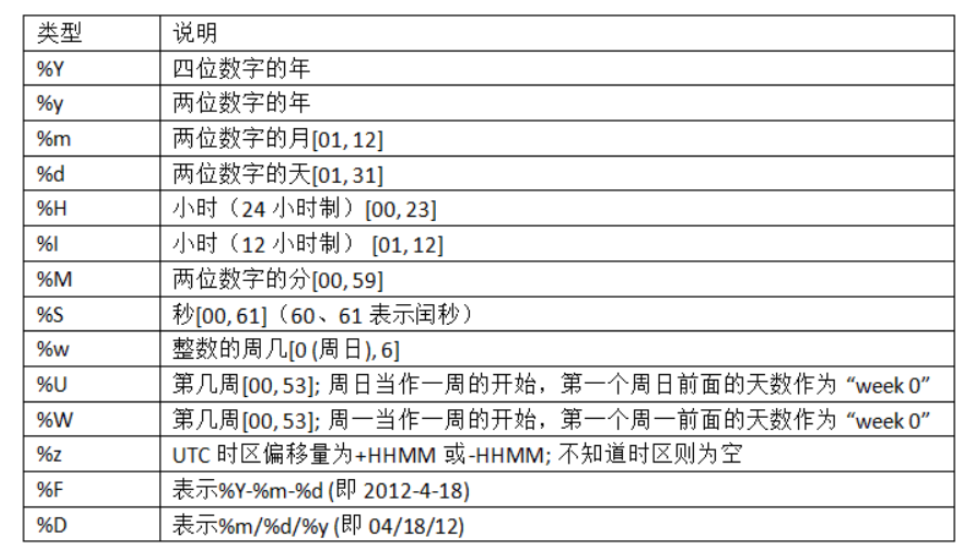
当你聚类或对时间序列进行分组,替换 datetimes 的 time 字段有时会很有用。例如,用 0 替换分和秒:
In [110]: dt.replace(minute=0, second=0)
Out[110]: datetime.datetime(2011, 10, 29, 20, 0)
因为datetime.datetime是不可变类型,上面的方法会产生新的对象。
两个 datetime 对象的差会产生一个datetime.timedelta类型:
In [111]: dt2 = datetime(2011, 11, 15, 22, 30)
In [112]: delta = dt2 - dt
In [113]: delta
Out[113]: datetime.timedelta(17, 7179)
In [114]: type(delta)
Out[114]: datetime.timedelta
结果timedelta(17, 7179)指明了timedelta将17天、7179秒的编码方式。
将timedelta添加到datetime,会产生一个新的偏移datetime:
In [115]: dt
Out[115]: datetime.datetime(2011, 10, 29, 20, 30, 21)
In [116]: dt + delta
Out[116]: datetime.datetime(2011, 11, 15, 22, 30)
21. 控制流
Python 有若干内建的关键字进行条件逻辑、循环和其它控制流操作。
① if、elif 和 else
if 是最广为人知的控制流语句。它检查一个条件,如果为 True,就执行后面的语句:
if x < 0:
print('It's negative')
if后面可以跟一个或多个elif(即 else if),所有条件都是 False 时,还可以添加一个else:
if x < 0:
print('It's negative')
elif x == 0:
print('Equal to zero')
elif 0 < x < 5:
print('Positive but smaller than 5')
else:
print('Positive and larger than or equal to 5')
如果某个条件为True,后面的elif就不会被执行。当使用 and 和 or 时,复合条件语句是从左到右执行(🚩 短路特性):
In [117]: a = 5; b = 7
In [118]: c = 8; d = 4
In [119]: if a < b or c > d:
.....: print('Made it')
Made it
在这个例子中,c > d不会被执行,因为第一个比较是 True:
也可以把比较式串在一起:
In [120]: 4 > 3 > 2 > 1
Out[120]: True
② for循环
for 循环是在一个集合(列表或元组)中进行迭代,或者就是一个迭代器。for循环的标准语法是:
for value in collection:
# do something with value
你可以用 continue 使 for 循环提前,跳过剩下的部分。看下面这个例子,将一个列表中的整数相加,跳过 None:
sequence = [1, 2, None, 4, None, 5]
total = 0
for value in sequence:
if value is None:
continue
total += value
可以用break跳出for循环。下面的代码将各元素相加,直到遇到5:
sequence = [1, 2, 0, 4, 6, 5, 2, 1]
total_until_5 = 0
for value in sequence:
if value == 5:
break
total_until_5 += value
break 只中断 for 循环的最内层,其余的 for 循环仍会运行:
In [121]: for i in range(4):
.....: for j in range(4):
.....: if j > i:
.....: break
.....: print((i, j))
.....:
(0, 0)
(1, 0)
(1, 1)
(2, 0)
(2, 1)
(2, 2)
(3, 0)
(3, 1)
(3, 2)
(3, 3)
如果集合或迭代器中的元素序列(元组或列表),可以用 for 循环将其方便地拆分成变量:
for a, b, c in iterator:
# do something
③ While循环
while 循环指定了条件和代码,当条件为 False 或用 break 退出循环,代码才会退出:
x = 256
total = 0
while x > 0:
if total > 500:
break
total += x
x = x // 2
22. pass
pass 是 Python 中的非操作语句。代码块不需要任何动作时可以使用(作为未执行代码的占位符);因为 Python 需要使用空白字符划定代码块,所以需要 pass:
if x < 0:
print('negative!')
elif x == 0:
# TODO: put something smart here
pass
else:
print('positive!')
23. range
🚩 range 函数返回一个迭代器,它产生一个均匀分布的整数序列:
In [122]: range(10)
Out[122]: range(0, 10)
In [123]: list(range(10))
Out[123]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
⭐ range 的三个参数是(起点,终点,步伐):
In [124]: list(range(0, 20, 2))
Out[124]: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
In [125]: list(range(5, 0, -1))
Out[125]: [5, 4, 3, 2, 1]
可以看到,range 产生的整数不包括 终点(左闭右开)。range 的常见用法是用序号迭代序列:
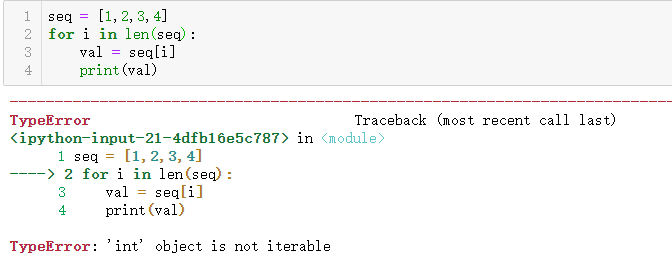
seq = [1, 2, 3, 4]
for i in range(len(seq)):
val = seq[i]
🚨 如果直接用
len(seq)进行迭代会报错:int 类型不是一个迭代器
可以使用 list 来存储 range 在其他数据结构中生成的所有整数,默认的迭代器形式通常是你想要的。下面的代码对 0 到 99999 中 3 或 5 的倍数求和:
sum = 0
for i in range(100000):
# % is the modulo operator
if i % 3 == 0 or i % 5 == 0:
sum += i
虽然 range 可以产生任意大的数,但任意时刻耗用的内存却很小。
24. 三元表达式
Python 中的三元表达式可以将 if-else 语句放到一行里。语法如下:
value = true-expr if condition else false-expr
true-expr或false-expr可以是任何Python代码。它和下面的代码效果相同:
if condition:
value = true-expr
else:
value = false-expr
下面是一个更具体的例子:
In [126]: x = 5
In [127]: 'Non-negative' if x >= 0 else 'Negative'
Out[127]: 'Non-negative'
和 if-else 一样,只有一个表达式会被执行。因此,三元表达式中的 if 和 else 可以包含大量的计算,但只有True的分支会被执行。
虽然使用三元表达式可以压缩代码,但会降低代码可读性。
3.2 数据结构和序列
1. 元组 tuple
① 概述
元组是一个固定长度,不可改变的 Python 序列对象。创建元组的最简单方式,是用逗号分隔一列值:
In [1]: tup = 4, 5, 6
In [2]: tup
Out[2]: (4, 5, 6)
当用复杂的表达式定义元组,最好将值放到圆括号内,如下所示:
In [3]: nested_tup = (4, 5, 6), (7, 8)
In [4]: nested_tup
Out[4]: ((4, 5, 6), (7, 8))
用tuple可以将任意序列或迭代器转换成元组:
In [5]: tuple([4, 0, 2])
Out[5]: (4, 0, 2)
In [6]: tup = tuple('string')
In [7]: tup
Out[7]: ('s', 't', 'r', 'i', 'n', 'g')
可以用方括号访问元组中的元素。和 C、C++、JAVA 等语言一样,序列是从 0 开始的:
In [8]: tup[0]
Out[8]: 's'
元组中存储的对象可能是可变对象。🚩 一旦创建了元组,元组中的对象就不能修改了:
In [9]: tup = tuple(['foo', [1, 2], True])
In [10]: tup[2] = False
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-10-c7308343b841> in <module>()
----> 1 tup[2] = False
TypeError: 'tuple' object does not support item assignment
如果元组中的某个对象是可变的,比如列表,⭐ 可以在原位进行修改:
In [11]: tup[1].append(3)
In [12]: tup
Out[12]: ('foo', [1, 2, 3], True)
可以用加号运算符将元组串联起来:
In [13]: (4, None, 'foo') + (6, 0) + ('bar',)
Out[13]: (4, None, 'foo', 6, 0, 'bar')
元组乘以一个整数,像列表一样,会将几个元组的复制串联起来:
In [14]: ('foo', 'bar') * 4
Out[14]: ('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar')
对象本身并没有被复制,只是引用了它。
② 拆分元组
如果你想将元组赋值给类似元组的变量,Python 会试图拆分等号右边的值:
In [15]: tup = (4, 5, 6)
In [16]: a, b, c = tup
In [17]: b
Out[17]: 5
即使含有元组的元组也会被拆分:
In [18]: tup = 4, 5, (6, 7)
In [19]: a, b, (c, d) = tup
In [20]: d
Out[20]: 7
使用这个功能,你可以很容易地替换变量的名字,其它语言可能是这样:
tmp = a
a = b
b = tmp
但是在Python中,替换可以这样做:
In [21]: a, b = 1, 2
In [22]: a
Out[22]: 1
In [23]: b
Out[23]: 2
In [24]: b, a = a, b
In [25]: a
Out[25]: 2
In [26]: b
Out[26]: 1
变量拆分常用来迭代元组或列表序列:
In [27]: seq = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
In [28]: for a, b, c in seq:
....: print('a={0}, b={1}, c={2}'.format(a, b, c))
a=1, b=2, c=3
a=4, b=5, c=6
a=7, b=8, c=9
另一个常见用法是从函数返回多个值。后面会详解。
Python 新增了更多高级的元组拆分功能,允许从元组的开头“摘取”几个元素。它使用了特殊的语法*rest,这也用在函数签名中以抓取任意长度列表的位置参数:
In [29]: values = 1, 2, 3, 4, 5
In [30]: a, b, *rest = values
In [31]: a, b
Out[31]: (1, 2)
In [32]: rest
Out[32]: [3, 4, 5]
rest的部分是想要舍弃的部分,rest 的名字不重要。作为惯用写法,许多Python程序员会将不需要的变量使用下划线:
In [33]: a, b, *_ = values
③ 元组的方法
因为元组的大小和内容不能修改,它的实例方法都很轻量。其中一个很有用的就是count(也适用于列表),它可以统计某个值的出现频率:
In [34]: a = (1, 2, 2, 2, 3, 4, 2)
In [35]: a.count(2)
Out[35]: 4
2. 列表 list
① 概述
与元组对比,列表的长度可变、内容可以被修改。你可以用方括号定义,或用list函数:
In [36]: a_list = [2, 3, 7, None]
In [37]: tup = ('foo', 'bar', 'baz')
In [38]: b_list = list(tup)
In [39]: b_list
Out[39]: ['foo', 'bar', 'baz']
In [40]: b_list[1] = 'peekaboo'
In [41]: b_list
Out[41]: ['foo', 'peekaboo', 'baz']
列表和元组的语义接近,在许多函数中可以交叉使用。
list函数常用来在数据处理中实体化迭代器或生成器:
In [42]: gen = range(10)
In [43]: gen
Out[43]: range(0, 10)
In [44]: list(gen)
Out[44]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
② 添加和删除元素
可以用append在列表末尾添加元素:
In [45]: b_list.append('dwarf')
In [46]: b_list
Out[46]: ['foo', 'peekaboo', 'baz', 'dwarf']
insert可以在特定的位置插入元素:
In [47]: b_list.insert(1, 'red')
In [48]: b_list
Out[48]: ['foo', 'red', 'peekaboo', 'baz', 'dwarf']
插入的序号必须在0和列表长度之间。
🚨 与
append相比,insert耗费的计算量大,因为对后续元素的引用必须在内部迁移,以便为新元素提供空间。如果要在序列的头部和尾部插入元素,你可能需要使用collections.deque,一个双尾部队列。
insert 的逆运算是 pop,它移除并返回指定位置的元素:
In [49]: b_list.pop(2)
Out[49]: 'peekaboo'
In [50]: b_list
Out[50]: ['foo', 'red', 'baz', 'dwarf']
可以用remove去除某个值,remove会先寻找第一个值并除去:
In [51]: b_list.append('foo')
In [52]: b_list
Out[52]: ['foo', 'red', 'baz', 'dwarf', 'foo']
In [53]: b_list.remove('foo')
In [54]: b_list
Out[54]: ['red', 'baz', 'dwarf', 'foo']
如果不考虑性能,使用append和remove,可以把 Python 的列表当做完美的“多重集”数据结构。
用in可以检查列表是否包含某个值:
In [55]: 'dwarf' in b_list
Out[55]: True
否定in可以再加一个not:
In [56]: 'dwarf' not in b_list
Out[56]: False
在列表中检查是否存在某个值远比字典和集合速度慢,因为Python是线性搜索列表中的值,但在字典和集合中,在同样的时间内还可以检查其它项(基于哈希表)。
③ 串联和组合列表
与元组类似,可以用加号将两个列表串联起来:
In [57]: [4, None, 'foo'] + [7, 8, (2, 3)]
Out[57]: [4, None, 'foo', 7, 8, (2, 3)]
如果已经定义了一个列表,用extend方法可以追加多个元素:
In [58]: x = [4, None, 'foo']
In [59]: x.extend([7, 8, (2, 3)])
In [60]: x
Out[60]: [4, None, 'foo', 7, 8, (2, 3)]
🚩 通过加法将列表串联的计算量较大,因为要新建一个列表,并且要复制对象。用extend追加元素,尤其是到一个大列表中,更为可取。因此:
everything = []
for chunk in list_of_lists:
everything.extend(chunk)
要比串联方法快:
everything = []
for chunk in list_of_lists:
everything = everything + chunk
④ 排序 sort
你可以用sort函数将一个列表原地排序(不创建新的对象):
In [61]: a = [7, 2, 5, 1, 3]
In [62]: a.sort()
In [63]: a
Out[63]: [1, 2, 3, 5, 7]
sort有一些选项,有时会很好用。其中之一是二级排序 key,可以用这个 key 进行排序。例如,我们可以按长度对字符串进行排序:
In [64]: b = ['saw', 'small', 'He', 'foxes', 'six']
In [65]: b.sort(key=len)
In [66]: b
Out[66]: ['He', 'saw', 'six', 'small', 'foxes']
稍后,我们会学习sorted函数,它可以产生一个排好序的序列副本。
⑤ 二分搜索和维护已排序的列表
bisect模块支持二分查找,和向已排序的列表插入值。bisect.bisect可以找到元素应该插入的位置后仍保证序列有序,bisect.insort1是向 bisect 查找到的位置插入值:
In [67]: import bisect
In [68]: c = [1, 2, 2, 2, 3, 4, 7]
# 查找在保证有序的情况下 2 应该插入的位置
In [69]: bisect.bisect(c, 2)
Out[69]: 4
In [70]: bisect.bisect(c, 5)
Out[70]: 6
In [71]: bisect.insort(c, 5) # 在bisect 查找的位置 6 上插入元素 5
In [72]: c
Out[72]: [1, 2, 2, 2, 3, 4, 5, 7]
🚨
bisect模块不会检查列表是否已排好序,进行检查的话会耗费大量计算。因此,对未排序的列表使用bisect不会产生错误,但结果不一定正确。
⑥ 切片
用切片可以选取大多数序列类型的一部分,切片的基本形式是在方括号中使用start:stop:(左闭右开)
In [73]: seq = [7, 2, 3, 7, 5, 6, 0, 1]
In [74]: seq[1:5]
Out[74]: [2, 3, 7, 5]
切片也可以被序列赋值:
In [75]: seq[3:4] = [6, 3]
In [76]: seq
Out[76]: [7, 2, 3, 6, 3, 5, 6, 0, 1]
切片的起始元素是包括的,不包含结束元素。因此,结果中包含的元素个数是stop - start。
start或stop都可以被省略,省略之后,分别默认序列的开头和结尾:
In [77]: seq[:5]
Out[77]: [7, 2, 3, 6, 3]
In [78]: seq[3:]
Out[78]: [6, 3, 5, 6, 0, 1]
负数表明从后向前切片:
In [79]: seq[-4:]
Out[79]: [5, 6, 0, 1]
In [80]: seq[-6:-2]
Out[80]: [6, 3, 5, 6]
需要一段时间来熟悉使用切片,尤其是当你之前学的是R或MATLAB。下图展示了正整数和负整数的切片。在图中,指数标示在边缘以表明切片是在哪里开始哪里结束的。
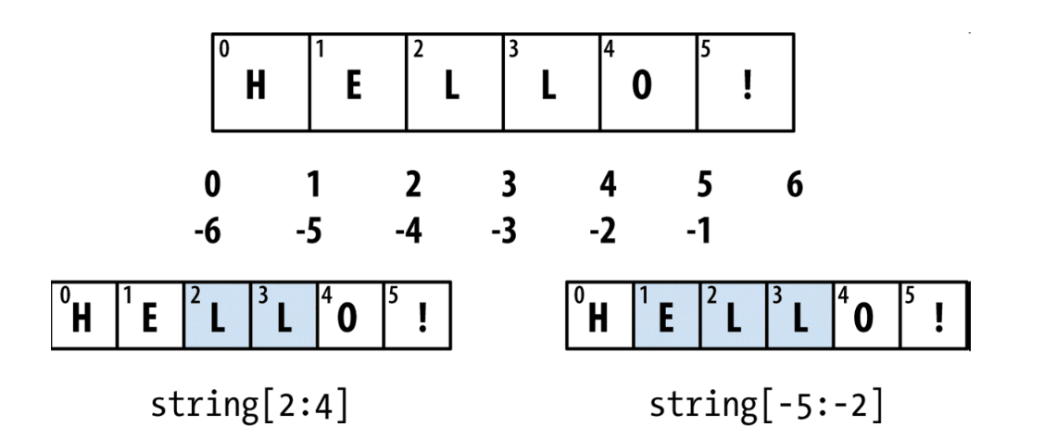
在第二个冒号后面使用step,可以隔 step 个取一个元素:
In [81]: seq[::2]
Out[81]: [7, 3, 3, 6, 1]
一个聪明的方法是使用-1,它可以将列表或元组颠倒过来:
In [82]: seq[::-1]
Out[82]: [1, 0, 6, 5, 3, 6, 3, 2, 7]
3. 序列函数
Python 有一些有用的序列函数。
① enumerate 函数
迭代一个序列时,你可能想跟踪当前项的序号。手动的方法可能是下面这样:
i = 0
for value in collection:
# do something with value
i += 1
因为这么做很常见,Python内建了一个enumerate函数,可以返回(i, value)元组序列:
for i, value in enumerate(collection):
# do something with value
当你索引数据时,使用enumerate的一个好方法是计算序列(唯一的)dict映射到位置的值:
In [83]: some_list = ['foo', 'bar', 'baz']
In [84]: mapping = {}
In [85]: for i, v in enumerate(some_list):
....: mapping[i] = v
In [86]: mapping
Out[86]: {0: 'foo', 1: 'bar', 2: 'baz'}
② sorted 函数
sorted函数可以从任意序列的元素返回一个新的排好序的列表:
In [87]: sorted([7, 1, 2, 6, 0, 3, 2])
Out[87]: [0, 1, 2, 2, 3, 6, 7]
In [88]: sorted('horse race')
Out[88]: [' ', 'a', 'c', 'e', 'e', 'h', 'o', 'r', 'r', 's']
sorted函数可以接受和sort相同的参数。
③ zip 函数
zip可以将多个列表、元组或其它序列成对组合成一个元组列表:
In [89]: seq1 = ['foo', 'bar', 'baz']
In [90]: seq2 = ['one', 'two', 'three']
In [91]: zipped = zip(seq1, seq2)
In [92]: list(zipped)
Out[92]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
zip可以处理任意多的序列,元素的个数取决于最短的序列:
In [93]: seq3 = [False, True]
In [94]: list(zip(seq1, seq2, seq3))
Out[94]: [('foo', 'one', False), ('bar', 'two', True)]
zip的常见用法之一是同时迭代多个序列,可能结合enumerate使用:
In [95]: for i, (a, b) in enumerate(zip(seq1, seq2)):
....: print('{0}: {1}, {2}'.format(i, a, b))
....:
0: foo, one
1: bar, two
2: baz, three
给出一个“被压缩的”序列,zip可以被用来解压序列。也可以当作把行的列表转换为列的列表。这个方法看起来有点神奇:
In [96]: pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'),
....: ('Schilling', 'Curt')]
In [97]: first_names, last_names = zip(*pitchers)
In [98]: first_names
Out[98]: ('Nolan', 'Roger', 'Schilling')
In [99]: last_names
Out[99]: ('Ryan', 'Clemens', 'Curt')
④ reversed 函数
reversed可以从后向前迭代一个序列:
In [100]: list(reversed(range(10)))
Out[100]: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
要记住reversed是一个生成器(后面详细介绍),只有实体化(即列表或 for 循环)之后才能创建翻转的序列。
4. 字典 dict
① 概述
字典可能是 Python 最为重要的数据结构。它更为常见的名字是哈希映射或关联数组。它是键值对的大小可变集合,键和值都是 Python 对象。创建字典的方法之一是使用尖括号,用冒号分隔键和值:
In [101]: empty_dict = {}
In [102]: d1 = {'a' : 'some value', 'b' : [1, 2, 3, 4]}
In [103]: d1
Out[103]: {'a': 'some value', 'b': [1, 2, 3, 4]}
你可以像访问列表或元组中的元素一样,访问、插入或设定字典中的元素:
In [104]: d1[7] = 'an integer'
In [105]: d1
Out[105]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'}
In [106]: d1['b']
Out[106]: [1, 2, 3, 4]
你可以用检查列表和元组是否包含某个值的方法,检查字典中是否包含某个键:
In [107]: 'b' in d1
Out[107]: True
可以用del关键字或pop方法(返回值的同时删除键)删除值:
In [108]: d1[5] = 'some value'
In [109]: d1
Out[109]:
{'a': 'some value',
'b': [1, 2, 3, 4],
7: 'an integer',
5: 'some value'}
In [110]: d1['dummy'] = 'another value'
In [111]: d1
Out[111]:
{'a': 'some value',
'b': [1, 2, 3, 4],
7: 'an integer',
5: 'some value',
'dummy': 'another value'}
In [112]: del d1[5]
In [113]: d1
Out[113]:
{'a': 'some value',
'b': [1, 2, 3, 4],
7: 'an integer',
'dummy': 'another value'}
In [114]: ret = d1.pop('dummy')
In [115]: ret
Out[115]: 'another value'
In [116]: d1
Out[116]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'}
keys和values是字典的键和值的迭代器方法。虽然键值对没有顺序,这两个方法可以用相同的顺序输出键和值:
In [117]: list(d1.keys())
Out[117]: ['a', 'b', 7]
In [118]: list(d1.values())
Out[118]: ['some value', [1, 2, 3, 4], 'an integer']
用update方法可以将一个字典与另一个融合:
In [119]: d1.update({'b' : 'foo', 'c' : 12})
In [120]: d1
Out[120]: {'a': 'some value', 'b': 'foo', 7: 'an integer', 'c': 12}
🚩 update方法是原地改变字典,因此任何传递给update的键的旧的值都会被舍弃。
② 用序列创建字典
常常,你可能想将两个序列配对组合成字典。下面是一种写法:
mapping = {}
for key, value in zip(key_list, value_list):
mapping[key] = value
因为字典本质上是2元元组的集合,dict可以接受2元元组的列表:
In [121]: mapping = dict(zip(range(5), reversed(range(5))))
In [122]: mapping
Out[122]: {0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
后面会谈到dict comprehensions,另一种构建字典的优雅方式。
③ 默认值
下面的逻辑很常见:
if key in some_dict:
value = some_dict[key]
else:
value = default_value
因此,dict 的方法 get 和 pop 可以取默认值进行返回,上面的 if-else 语句可以简写成下面:
value = some_dict.get(key, default_value)
get 默认会返回 None,如果不存在键,pop会抛出一个例外。关于设定值,常见的情况是在字典的值是属于其它集合,如列表。💬 例如,你可以通过首字母,将一个列表中的单词分类:
In [123]: words = ['apple', 'bat', 'bar', 'atom', 'book']
In [124]: by_letter = {}
In [125]: for word in words:
.....: letter = word[0]
.....: if letter not in by_letter:
.....: by_letter[letter] = [word]
.....: else:
.....: by_letter[letter].append(word)
.....:
In [126]: by_letter
Out[126]: {'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']}
setdefault方法就正是干这个的。前面的 for 循环可以改写为:
for word in words:
letter = word[0]
by_letter.setdefault(letter, []).append(word)
🚩 collections模块有一个很有用的类,defaultdict,它可以进一步简化上面。传递类型或函数以生成每个位置的默认值:
from collections import defaultdict
by_letter = defaultdict(list)
for word in words:
by_letter[word[0]].append(word)
④ 有效的键类型
⭐ 字典的值可以是任意Python对象,而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的)。这被称为 🔴 “可哈希性”。可以用hash函数检测一个对象是否是可哈希的(可被用作字典的键):
In [127]: hash('string')
Out[127]: 5023931463650008331
In [128]: hash((1, 2, (2, 3)))
Out[128]: 1097636502276347782
In [129]: hash((1, 2, [2, 3])) # fails because lists are mutable
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-129-800cd14ba8be> in <module>()
----> 1 hash((1, 2, [2, 3])) # fails because lists are mutable
TypeError: unhashable type: 'list'
要用列表当做键,一种方法是将列表转化为元组,只要内部元素可以被哈希,它也就可以被哈希:
In [130]: d = {}
In [131]: d[tuple([1, 2, 3])] = 5
In [132]: d
Out[132]: {(1, 2, 3): 5}
5. 集合 set
集合是无序的不可重复的元素的集合。你可以把它当做字典,但是只有键没有值。可以用两种方式创建集合:通过set函数或使用尖括号set语句:
In [133]: set([2, 2, 2, 1, 3, 3])
Out[133]: {1, 2, 3}
In [134]: {2, 2, 2, 1, 3, 3}
Out[134]: {1, 2, 3}
集合支持合并、交集、差分和对称差等数学集合运算。考虑两个示例集合:
In [135]: a = {1, 2, 3, 4, 5}
In [136]: b = {3, 4, 5, 6, 7, 8}
合并是取两个集合中不重复的元素。可以用union方法,或者|运算符:
In [137]: a.union(b)
Out[137]: {1, 2, 3, 4, 5, 6, 7, 8}
In [138]: a | b
Out[138]: {1, 2, 3, 4, 5, 6, 7, 8}
交集的元素包含在两个集合中。可以用intersection或&运算符:
In [139]: a.intersection(b)
Out[139]: {3, 4, 5}
In [140]: a & b
Out[140]: {3, 4, 5}
下表列出了常用的集合方法。
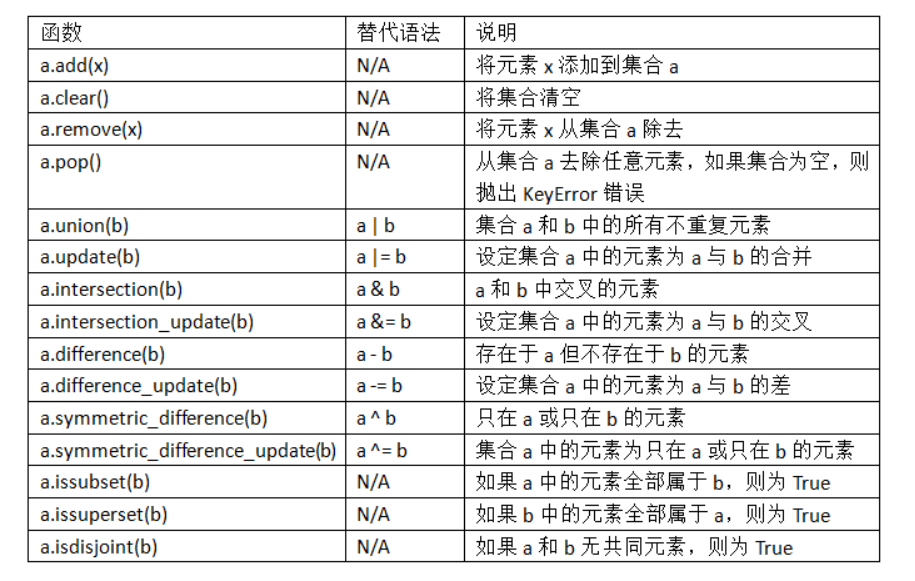
所有逻辑集合操作都有另外的原地实现方法,可以直接用结果替代集合的内容。对于大的集合,这么做效率更高:
In [141]: c = a.copy()
In [142]: c |= b
In [143]: c
Out[143]: {1, 2, 3, 4, 5, 6, 7, 8}
In [144]: d = a.copy()
In [145]: d &= b
In [146]: d
Out[146]: {3, 4, 5}
与字典类似,集合元素通常都是不可变的。要获得类似列表的元素,必须转换成元组:
In [147]: my_data = [1, 2, 3, 4]
In [148]: my_set = {tuple(my_data)}
In [149]: my_set
Out[149]: {(1, 2, 3, 4)}
你还可以检测一个集合是否是另一个集合的子集或父集:
In [150]: a_set = {1, 2, 3, 4, 5}
In [151]: {1, 2, 3}.issubset(a_set)
Out[151]: True
In [152]: a_set.issuperset({1, 2, 3})
Out[152]: True
集合的内容相同时,集合才对等:
In [153]: {1, 2, 3} == {3, 2, 1}
Out[153]: True
6. 列表、集合和字典推导式
① 列表推导式
列表推导式是 Python 最受喜爱的特性之一。它允许用户方便的从一个集合过滤元素,形成列表,在传递参数的过程中还可以修改元素。形式如下:
[expr for val in collection if condition]
它等同于下面的 for 循环;
result = []
for val in collection:
if condition:
result.append(expr)
filter 条件可以被忽略,只留下表达式就行。例如,给定一个字符串列表,我们可以过滤出长度在2及以下的字符串,并将其转换成大写:
In [154]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
In [155]: [x.upper() for x in strings if len(x) > 2]
Out[155]: ['BAT', 'CAR', 'DOVE', 'PYTHON']
② 字典推导式
字典的推导式如下所示:
dict_comp = {key-expr : value-expr for value in collection if condition}
💬 作为一个字典推导式的例子,我们可以创建一个字符串的查找映射表以确定它在列表中的位置:
In [159]: loc_mapping = {val : index for index, val in enumerate(strings)}
In [160]: loc_mapping
Out[160]: {'a': 0, 'as': 1, 'bat': 2, 'car': 3, 'dove': 4, 'python': 5}
③ 集合推导式
集合的推导式与列表很像,只不过用的是尖括号:
set_comp = {expr for value in collection if condition}
💬 假如我们只想要字符串的长度,用集合推导式的方法非常方便:
In [156]: unique_lengths = {len(x) for x in strings}
In [157]: unique_lengths
Out[157]: {1, 2, 3, 4, 6}
map函数可以进一步简化:
In [158]: set(map(len, strings))
Out[158]: {1, 2, 3, 4, 6}
7. 嵌套列表推导式
假设我们有一个包含列表的列表,包含了一些英文名和西班牙名:
In [161]: all_data = [['John', 'Emily', 'Michael', 'Mary', 'Steven'],
.....: ['Maria', 'Juan', 'Javier', 'Natalia', 'Pilar']]
你可能是从一些文件得到的这些名字,然后想按照语言进行分类。现在假设我们想用一个列表包含所有的名字,这些名字中包含两个或更多的 e。可以用 for 循环来做:
result = []
for names in all_data:
enough_es = [name for name in names if name.count('e') >= 2]
result.extend(enough_es)
可以用嵌套列表推导式的方法,将这些写在一起,如下所示:
In [162]: result = [name for names in all_data for name in names
.....: if name.count('e') >= 2]
In [163]: result
Out[163]: ['Steven']
嵌套列表推导式看起来有些复杂。列表推导式的for部分是根据嵌套的顺序,过滤条件还是放在最后。下面是另一个例子,我们将一个整数元组的列表扁平化成了一个整数列表:
In [164]: some_tuples = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
In [165]: flattened = [x for tup in some_tuples for x in tup]
In [166]: flattened
Out[166]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
记住,for表达式的顺序是与嵌套for循环的顺序一样(而不是列表推导式的顺序):
flattened = []
for tup in some_tuples:
for x in tup:
flattened.append(x)
你可以有任意多级别的嵌套,但是如果你有两三个以上的嵌套,你就应该考虑下代码可读性的问题了。分辨列表推导式的列表推导式中的语法也是很重要的:
In [167]: [[x for x in tup] for tup in some_tuples]
Out[167]: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
这段代码产生了一个列表的列表,而不是扁平化的只包含元素的列表。
3.3 函数
1. 概述
函数是Python中最主要也是最重要的代码组织和复用手段。作为最重要的原则,如果你要重复使用相同或非常类似的代码,就需要写一个函数。通过给函数起一个名字,还可以提高代码的可读性。
函数使用def关键字声明,用return关键字返回值:
def my_function(x, y, z=1.5):
if z > 1:
return z * (x + y)
else:
return z / (x + y)
同时拥有多条return语句也是可以的。如果到达函数末尾时没有遇到任何一条return语句,则返回None。
函数可以有一些位置参数(positional)和一些关键字参数(keyword)。关键字参数通常用于指定默认值或可选参数。在上面的函数中,x 和 y 是位置参数,而 z 则是关键字参数。也就是说,该函数可以下面这两种方式进行调用:
my_function(5, 6, z=0.7)
my_function(3.14, 7, 3.5)
my_function(10, 20)
函数参数的主要限制在于:⭐ 关键字参数必须位于位置参数(如果有的话)之后。你可以任何顺序指定关键字参数。也就是说,你不用死记硬背函数参数的顺序,只要记得它们的名字就可以了。
🚩 也可以用关键字传递位置参数。前面的例子,也可以写为:
my_function(x=5, y=6, z=7) my_function(y=6, x=5, z=7)这种写法可以提高可读性。
2. 命名空间、作用域和局部函数
函数可以访问两种不同作用域中的变量:全局(global)和局部(local)。Python 有一种更科学的用于描述变量作用域的名称,即命名空间(namespace)。任何在函数中赋值的变量默认都是被分配到局部命名空间(local namespace)中的。局部命名空间是在函数被调用时创建的,函数参数会立即填入该命名空间。在函数执行完毕之后,局部命名空间就会被销毁(会有一些例外的情况,具体请参见后面介绍闭包的那一节)。看看下面这个函数:
def func():
a = []
for i in range(5):
a.append(i)
调用 func() 之后,首先会创建出空列表 a,然后添加 5 个元素,最后 a 会在该函数退出的时候被销毁。假如我们像下面这样定义 a:
a = []
def func():
for i in range(5):
a.append(i)
🚨 虽然可以在函数中对全局变量进行赋值操作,但是那些变量必须用 global 关键字声明成全局的才行:
In [168]: a = None
In [169]: def bind_a_variable():
.....: global a
.....: a = []
.....: bind_a_variable()
.....:
In [170]: print(a)
[]
🚩 我常常建议人们不要频繁使用global关键字。因为全局变量一般是用于存放系统的某些状态的。如果你发现自己用了很多,那可能就说明得要来点儿面向对象编程了(即使用类)。
3. 返回多个值
在我第一次用Python编程时(之前已经习惯了Java和C++),最喜欢的一个功能是:函数可以返回多个值。下面是一个简单的例子:
def f():
a = 5
b = 6
c = 7
return a, b, c
a, b, c = f()
在数据分析和其他科学计算应用中,你会发现自己常常这么干。该函数其实只返回了一个对象,也就是一个元组,最后该元组会被拆包到各个结果变量中。在上面的例子中,我们还可以这样写:
return_value = f()
这里的 return_value 将会是一个含有3个返回值的三元元组。此外,还有一种非常具有吸引力的多值返回方式——返回字典:
def f():
a = 5
b = 6
c = 7
return {'a' : a, 'b' : b, 'c' : c}
取决于工作内容,第二种方法可能很有用。
4. 函数也是对象
由于 Python 函数都是对象,因此,在其他语言中较难表达的一些设计思想在 Python 中就要简单很多了。假设我们有下面这样一个字符串数组,希望对其进行一些数据清理工作并执行一堆转换:
In [171]: states = [' Alabama ', 'Georgia!', 'Georgia', 'georgia', 'FlOrIda',
.....: 'south carolina##', 'West virginia?']
不管是谁,只要处理过由用户提交的调查数据,就能明白这种乱七八糟的数据是怎么一回事。为了得到一组能用于分析工作的格式统一的字符串,需要做很多事情:去除空白符、删除各种标点符号、正确的大写格式等。做法之一是使用内建的字符串方法和正则表达式re模块:
import re
def clean_strings(strings):
result = []
for value in strings:
value = value.strip()
value = re.sub('[!#?]', '', value)
value = value.title()
result.append(value)
return result
🔸
str.title(): 将每个单词的第一个字符转为大写,如果单词包含数字或符号,则其后的第一个字母将转换为大写字母🔹
re.sub():sub 是 substitute 的所写,表示替换;re.sub 是个正则表达式方面的函数,用来实现通过正则表达式,实现比普通字符串的 replace 更加强大的替换功能。举个最简单的例子:如果输入字符串是:
inputStr = "hello 111 world 111"那么你可以通过
replacedStr = inputStr.replace("111", "222")去换成 "hello 222 world 222"
但是,如果输入字符串是:
inputStr = "hello 123 world 456"而你是想把 123 和 456,都换成 222,那么就没法直接通过字符串的 replace 达到这一目的了。
就需要借助于 re.sub,通过正则表达式,来实现这种相对复杂的字符串的替换:
replacedStr = re.sub("\d+", "222", inputStr)
结果如下所示:
In [173]: clean_strings(states)
Out[173]:
['Alabama',
'Georgia',
'Georgia',
'Georgia',
'Florida',
'South Carolina',
'West Virginia']
其实还有另外一种不错的办法:将需要在一组给定字符串上执行的所有运算做成一个列表:
def remove_punctuation(value):
return re.sub('[!#?]', '', value)
clean_ops = [str.strip, remove_punctuation, str.title]
def clean_strings(strings, ops):
result = []
for value in strings:
for function in ops:
value = function(value)
result.append(value)
return result
然后我们就有了:
In [175]: clean_strings(states, clean_ops)
Out[175]:
['Alabama',
'Georgia',
'Georgia',
'Georgia',
'Florida',
'South Carolina',
'West Virginia']
这种多函数模式使你能在很高的层次上轻松修改字符串的转换方式。此时的 clean_strings 也更具可复用性!
还可以将函数用作其他函数的参数,比如内置的 map 函数,它用于在一组数据上应用一个函数:
In [176]: for x in map(remove_punctuation, states):
.....: print(x)
Alabama
Georgia
Georgia
georgia
FlOrIda
south carolina
West virginia
5. 匿名(lambda)函数
Python 支持一种被称为匿名的、或 lambda 函数。它仅由单条语句组成,该语句的结果就是返回值。它是通过 lambda 关键字定义的,这个关键字没有别的含义,仅仅是说“我们正在声明的是一个匿名函数”。
def short_function(x):
return x * 2
equiv_anon = lambda x: x * 2
本书其余部分一般将其称为 lambda 函数。它们在数据分析工作中非常方便,因为你会发现很多数据转换函数都以函数作为参数的。直接传入lambda函数比编写完整函数声明要少输入很多字(也更清晰),甚至比将lambda函数赋值给一个变量还要少输入很多字。看看下面这个简单的例子:
def apply_to_list(some_list, f):
return [f(x) for x in some_list]
ints = [4, 0, 1, 5, 6]
apply_to_list(ints, lambda x: x * 2)
虽然你可以直接编写 [x *2 for x in ints],但是这里我们可以非常轻松地传入一个自定义运算给apply_to_list 函数。
再来看另外一个例子。假设有一组字符串,你想要根据各字符串不同字母的数量对其进行排序:
In [177]: strings = ['foo', 'card', 'bar', 'aaaa', 'abab']
这里,我们可以传入一个 lambda 函数到列表的 sort 方法:
In [178]: strings.sort(key=lambda x: len(set(list(x))))
In [179]: strings
Out[179]: ['aaaa', 'foo', 'abab', 'bar', 'card']
🚩 lambda 函数之所以会被称为匿名函数,与 def 声明的函数不同,原因之一就是这种函数对象本身是没有提供名称
__name __属性。
6. 柯里化:部分参数应用
柯里化(currying)是一个有趣的计算机科学术语,它指的是通过“部分参数应用”(partial argument application)从现有函数派生出新函数的技术。例如,假设我们有一个执行两数相加的简单函数:
def add_numbers(x, y):
return x + y
通过这个函数,我们可以派生出一个新的只有一个参数的函数 —— add_five,它用于对其参数加 5:
add_five = lambda y: add_numbers(5, y)
add_numbers 的第二个参数称为“柯里化的”(curried)。这里没什么特别花哨的东西,因为我们其实就只是定义了一个可以调用现有函数的新函数而已。内置的functools模块可以用partial函数将此过程简化:
from functools import partial
add_five = partial(add_numbers, 5) # 相当于默认第一个参数为 5
add_five(2) # 7
add_five(5,1) # TypeError: add_numbers() takes 2 positional arguments but 3 were given
7. 生成器
能以一种一致的方式对序列进行迭代(比如列表中的对象或文件中的行)是Python的一个重要特点。这是通过一种叫做迭代器协议(iterator protocol,它是一种使对象可迭代的通用方式)的方式实现的,一个原生的使对象可迭代的方法。比如说,对字典进行迭代可以得到其所有的键:
In [180]: some_dict = {'a': 1, 'b': 2, 'c': 3}
In [181]: for key in some_dict:
.....: print(key)
a
b
c
当你编写 for key in some_dict 时,Python 解释器首先会尝试从 some_dict 创建一个迭代器:
In [182]: dict_iterator = iter(some_dict)
In [183]: dict_iterator
Out[183]: <dict_keyiterator at 0x7fbbd5a9f908>
迭代器是一种特殊对象,它可以在诸如 for 循环之类的上下文中向 Python 解释器输送对象。大部分能接受列表之类的对象的方法也都可以接受任何可迭代对象。比如min、max、sum等内置方法以及list、tuple等类型构造器:
In [184]: list(dict_iterator)
Out[184]: ['a', 'b', 'c']
生成器(generator)是构造新的可迭代对象的一种简单方式。⭐ 一般的函数执行之后只会返回单个值,而生成器则是以延迟的方式返回一个值序列,即每返回一个值之后暂停,直到下一个值被请求时再继续。要创建一个生成器,只需将函数中的 return 替换为 yeild 即可:
def squares(n=10):
print('Generating squares from 1 to {0}'.format(n ** 2)) # ** 代表乘方
for i in range(1, n + 1):
yield i ** 2
调用该生成器时,没有任何代码会被立即执行:
In [186]: gen = squares()
In [187]: gen
Out[187]: <generator object squares at 0x7fbbd5ab4570>
直到你从该生成器中请求元素时,它才会开始执行其代码:
In [188]: for x in gen:
.....: print(x, end=' ')
Generating squares from 1 to 100
1 4 9 16 25 36 49 64 81 100
8. 生成器表达式
另一种更简洁的构造生成器的方法是使用 生成器表达式(generator expression)。这是一种类似于列表、字典、集合推导式的生成器。其创建方式为,把列表推导式两端的方括号改成圆括号:
In [189]: gen = (x ** 2 for x in range(100))
In [190]: gen
Out[190]: <generator object <genexpr> at 0x7fbbd5ab29e8>
它跟下面这个冗长得多的生成器是完全等价的:
def _make_gen():
for x in range(100):
yield x ** 2
gen = _make_gen()
生成器表达式也可以取代列表推导式,作为函数参数:
In [191]: sum(x ** 2 for x in range(100))
Out[191]: 328350
In [192]: dict((i, i **2) for i in range(5))
Out[192]: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
9. itertools 模块
标准库 itertools 模块中有一组用于许多常见数据算法的生成器。例如,groupby 可以接受任何序列和一个函数,它根据函数的返回值对序列中的连续元素进行分组。下面是一个例子:
In [193]: import itertools
In [194]: first_letter = lambda x: x[0]
In [195]: names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven']
In [196]: for letter, names in itertools.groupby(names, first_letter):
.....: print(letter, list(names)) # names is a generator
A ['Alan', 'Adam']
W ['Wes', 'Will']
A ['Albert']
S ['Steven']
下表列出了一些经常用到的 itertools 函数。建议参阅 Python 官方文档,进一步学习。

10. 错误和异常处理
优雅地处理Python的错误和异常是构建健壮程序的重要部分。在数据分析中,许多函数函数只用于部分输入。例如,Python 的 float 函数可以将字符串转换成浮点数,但输入有误时,有ValueError错误:
In [197]: float('1.2345')
Out[197]: 1.2345
In [198]: float('something')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-198-439904410854> in <module>()
----> 1 float('something')
ValueError: could not convert string to float: 'something'
假如想优雅地处理float的错误,让它返回输入值。我们可以写一个函数,在try/except中调用float:
def attempt_float(x):
try:
return float(x)
except:
return x
当float(x)抛出异常时,才会执行except的部分:
In [200]: attempt_float('1.2345')
Out[200]: 1.2345
In [201]: attempt_float('something')
Out[201]: 'something'
你可能注意到float抛出的异常不仅是ValueError:
In [202]: float((1, 2))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-202-842079ebb635> in <module>()
----> 1 float((1, 2))
TypeError: float() argument must be a string or a number, not 'tuple'
你可能只想处理ValueError,TypeError错误(输入不是字符串或数值)可能是合理的bug。可以写一个异常类型:
def attempt_float(x):
try:
return float(x)
except ValueError:
return x
然后有:
In [204]: attempt_float((1, 2))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-204-9bdfd730cead> in <module>()
----> 1 attempt_float((1, 2))
<ipython-input-203-3e06b8379b6b> in attempt_float(x)
1 def attempt_float(x):
2 try:
----> 3 return float(x)
4 except ValueError:
5 return x
TypeError: float() argument must be a string or a number, not 'tuple'
可以用元组包含多个异常:
def attempt_float(x):
try:
return float(x)
except (TypeError, ValueError):
return x
某些情况下,你可能不想抑制异常,你想无论 try 部分的代码是否成功,都执行一段代码。可以使用finally:
f = open(path, 'w')
try:
write_to_file(f)
finally:
f.close()
这里,文件处理 f 总会被关闭。相似的,你可以用else让只在try部分成功的情况下,才执行代码:
f = open(path, 'w')
try:
write_to_file(f)
except:
print('Failed')
else:
print('Succeeded')
finally:
f.close()
3.4 文件和操作系统
① 基本文件操作
本书的代码示例大多使用诸如 pandas.read_csv 之类的高级工具将磁盘上的数据文件读入 Python 数据结构。但我们还是需要了解一些有关 Python 文件处理方面的基础知识。好在它本来就很简单,这也是 Python 在文本和文件处理方面的如此流行的原因之一。
为了打开一个文件以便读写,可以使用内置的open函数以及一个相对或绝对的文件路径:
In [207]: path = 'examples/segismundo.txt'
In [208]: f = open(path)
默认情况下,文件是以只读模式('r')打开的。然后,我们就可以像处理列表那样来处理这个文件句柄 f 了,比如对行进行迭代:
for line in f:
pass
从文件中取出的行都带有完整的行结束符(EOL),因此你常常会看到下面这样的代码(得到一组没有 EOL 的行):
In [209]: lines = [x.rstrip() for x in open(path)]
In [210]: lines
Out[210]:
['Sueña el rico en su riqueza,',
'que más cuidados le ofrece;',
'',
'sueña el pobre que padece',
'su miseria y su pobreza;',
'',
'sueña el que a medrar empieza,',
'sueña el que afana y pretende,',
'sueña el que agravia y ofende,',
'',
'y en el mundo, en conclusión,',
'todos sueñan lo que son,',
'aunque ninguno lo entiende.',
'']
🚩 如果使用 open 创建文件对象,一定要用 close 关闭它。关闭文件可以返回操作系统资源:
In [211]: f.close()
用 with 语句可以可以更容易地清理打开的文件:
In [212]: with open(path) as f:
.....: lines = [x.rstrip() for x in f]
这样可以在退出代码块时,自动关闭文件。
如果输入 f =open(path,'w'),就会有一个新文件被创建在 examples/segismundo.txt,并覆盖掉该位置原来的任何数据。另外有一个 x 文件模式,它可以创建可写的文件,但是如果文件路径存在,就无法创建。
👇 下表列出了所有的读/写模式:

对于可读文件,一些常用的方法是 read、seek 和 tell。read 会从文件返回字符。字符的内容是由文件的编码决定的(如UTF-8),如果是二进制模式打开的就是原始字节:
In [213]: f = open(path)
In [214]: f.read(10)
Out[214]: 'Sueña el r'
In [215]: f2 = open(path, 'rb') # 以二进制模式打开文件
In [216]: f2.read(10)
Out[216]: b'Sue\xc3\xb1a el '
read 模式会将文件句柄的位置提前,提前的数量是读取的字节数。tell 可以给出当前的位置:
In [217]: f.tell()
Out[217]: 11
In [218]: f2.tell()
Out[218]: 10
尽管我们从文件读取了10个字符,位置却是11,这是因为用默认的编码用了这么多字节才解码了这10个字符。你可以用 sys 模块检查默认的编码:
In [219]: import sys
In [220]: sys.getdefaultencoding()
Out[220]: 'utf-8'
seek 将文件位置更改为文件中的指定字节:
In [221]: f.seek(3)
Out[221]: 3
In [222]: f.read(1)
Out[222]: 'ñ'
最后,关闭文件:
In [223]: f.close()
In [224]: f2.close()
向文件写入,可以使用文件的 write 或 writelines 方法。例如,我们可以创建一个无空行版的prof_mod.py:
In [225]: with open('tmp.txt', 'w') as handle:
.....: handle.writelines(x for x in open(path) if len(x) > 1)
In [226]: with open('tmp.txt') as f:
.....: lines = f.readlines()
In [227]: lines
Out[227]:
['Sueña el rico en su riqueza,\n',
'que más cuidados le ofrece;\n',
'sueña el pobre que padece\n',
'su miseria y su pobreza;\n',
'sueña el que a medrar empieza,\n',
'sueña el que afana y pretende,\n',
'sueña el que agravia y ofende,\n',
'y en el mundo, en conclusión,\n',
'todos sueñan lo que son,\n',
'aunque ninguno lo entiende.\n']
👇 下表列出了一些最常用的文件方法:

② 文件的字节和 Unicode
Python 文件的默认操作是“文本模式”,也就是说,你需要处理Python的字符串(即Unicode)。它与“二进制模式”相对,文件模式加一个 b。我们来看上一节的文件(UTF-8编码、包含非ASCII字符):
In [230]: with open(path) as f:
.....: chars = f.read(10)
In [231]: chars
Out[231]: 'Sueña el r'
UTF-8 是长度可变的Unicode编码,所以当我从文件请求一定数量的字符时,Python 会从文件读取足够多(可能少至10或多至40字节)的字节进行解码。如果以“rb”模式打开文件,则读取确切的请求字节数:
In [232]: with open(path, 'rb') as f:
.....: data = f.read(10)
In [233]: data
Out[233]: b'Sue\xc3\xb1a el '
取决于文本的编码,你可以将字节解码为 str 对象,但只有当每个编码的Unicode字符都完全成形时才能这么做:
In [234]: data.decode('utf8')
Out[234]: 'Sueña el '
In [235]: data[:4].decode('utf8')
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-235-300e0af10bb7> in <module>()
----> 1 data[:4].decode('utf8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 3: unexpecte
d end of data
文本模式结合了open的编码选项,提供了一种更方便的方法将Unicode转换为另一种编码:
In [236]: sink_path = 'sink.txt'
In [237]: with open(path) as source:
.....: with open(sink_path, 'xt', encoding='iso-8859-1') as sink:
.....: sink.write(source.read())
In [238]: with open(sink_path, encoding='iso-8859-1') as f:
.....: print(f.read(10))
Sueña el r
🚨 注意,不要在二进制模式中使用 seek。如果文件位置位于定义Unicode字符的字节的中间位置,读取后面会产生错误:
In [240]: f = open(path)
In [241]: f.read(5)
Out[241]: 'Sueña'
In [242]: f.seek(4)
Out[242]: 4
In [243]: f.read(1)
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-243-7841103e33f5> in <module>()
----> 1 f.read(1)
/miniconda/envs/book-env/lib/python3.6/codecs.py in decode(self, input, final)
319 # decode input (taking the buffer into account)
320 data = self.buffer + input
--> 321 (result, consumed) = self._buffer_decode(data, self.errors, final
)
322 # keep undecoded input until the next call
323 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid s
tart byte
In [244]: f.close()
如果你经常要对非ASCII字符文本进行数据分析,通晓Python的Unicode功能是非常重要的。更多内容,参阅Python官方文档。
✅ End
我们已经学过了 Python 的基础、环境和语法,接下来学习 NumPy 和 Python 的面向数组计算 😊 。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号