4-函数式编程
🥫 函数式编程 Functional Programming
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
1. 高阶函数 Higher-order function
① 什么是高阶函数
我们以实际代码为例子,一步一步深入概念。
Ⅰ变量可以指向函数
以Python内置的求绝对值的函数abs()为例,调用该函数用以下代码:
abs(-10) # 10
但是,如果只写abs呢?
abs # <built-in function abs>
可见,abs(-10)是函数调用,而abs是函数本身。
要获得函数调用结果,我们可以把结果赋值给变量:
x = abs(-10)
x # 10
但是,如果把函数本身赋值给变量呢?
f = abs
f # <built-in function abs>
结论:函数本身也可以赋值给变量,即:变量可以指向函数。
如果一个变量指向了一个函数,那么,可否通过该变量来调用这个函数?用代码验证一下:
f = abs
f(-10) # 10
成功!说明变量f现在已经指向了abs函数本身。直接调用abs()函数和调用变量f()完全相同。
Ⅱ 函数名也是变量
函数名其实就是指向函数的变量!对于abs()这个函数,完全可以把函数名abs看成变量,它指向一个可以计算绝对值的函数!
如果把abs指向其他对象,会有什么情况发生?
abs = 10
abs(-10)
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not callable
把abs指向10后,就无法通过abs(-10)调用该函数了!因为abs这个变量已经不指向求绝对值函数而是指向一个整数10!
当然实际代码绝对不能这么写,这里是为了说明函数名也是变量。
Ⅲ 传入函数
🔴 一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数。
一个最简单的高阶函数:
def add(x, y, f):
return f(x) + f(y)
当我们调用add(-5, 6, abs)时,参数x,y和f分别接收-5,6和abs:
print(add(-5, 6, abs)) # 11
# f(x) + f(y) ==> abs(-5) + abs(6) ==> 11
② map / reduce
Python内建了map()和reduce()函数。
Ⅰ map
map()函数接收两个参数,一个是函数,一个是Iterable可迭代对象,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
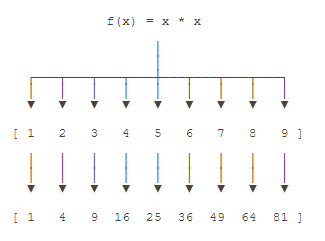
def f(x):
return x*x
r = map(f,[1,2,3,4,5,6,7,8,9])
print(r) # <map object at 0x000002399194EE48>
print(list(r)) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
你可能会想,不需要map()函数,写一个循环,也可以计算出结果:
L = []
for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(n))
print(L)
的确可以,但是,从上面的循环代码,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list”吗?
所以,map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的 f(x)=$x^2$,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
print(list(map(str,[1,2,3,4,5])))
Ⅱ reduce
再看reduce的用法。reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
from functools import reduce
def add(x,y):
return x + y
r = reduce(add,[1,2,3,4,5])
print(r) # 15
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 2, 3, 4, 5]变换成整数12345,reduce就可以派上用场:
from functools import reduce
def f(x,y):
return x * 10 + y
r = reduce(f,[1,2,3,4,5])
print(r) # 12345
这个例子本身没多大用处,但是,如果考虑到字符串str也是一个序列,对上面的例子稍加改动,配合map(),我们就可以写出把str转换为int的函数:
from functools import reduce
def fn(x,y):
return x * 10 + y
def char2num(s): # 传入一个字符串
# 字典:字符到数字的映射
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
return DIGITS[s] # 返回数字
# map 将传入的函数依次作用到字符串的每个元素
r = reduce(fn, map(char2num, '13579'))
print(r) # 13579
🚩 整理成一个str2int的函数就是:
from functools import reduce
# 字典:字符到数字的映射
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x,y):
return x * 10 + y
def char2num(s): # 传入一个字符串
return DIGITS[s] # 返回数字
return reduce(fn, map(char2num, s)) # map 将传入的函数依次作用到字符串的每个元素
print(str2int('12345')) # 12345
Ⅲ map / reduce 练习题
-
利用
map()函数,把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字。输入:['adam', 'LISA', 'barT'],输出:['Adam', 'Lisa', 'Bart']:def normalize(name): return name[0].upper() + name[1:].lower() L1 = ['adam', 'LISA', 'barT'] L2 = list(map(normalize, L1)) print(L2) # ['Adam', 'Lisa', 'Bart'] -
Python提供的
sum()函数可以接受一个list并求和,请编写一个prod()函数,可以接受一个list并利用reduce()求积:from functools import reduce def prod(L): def chen(x,y): return x*y return reduce(chen,L) print('3 * 5 * 7 * 9 =', prod([3, 5, 7, 9])) if prod([3, 5, 7, 9]) == 945: print('测试成功!') else: print('测试失败!') -
👊 利用
map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456:from functools import reduce DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9} def str2float(s): s = s.split('.') # 以小数点为分割符,将字符串分为两部分 s[0] s[1] def char2num(x): # 字符转数字 return DIGITS[x] def f1(x,y): # 处理小数点之前的数 return x * 10 + y def f2(x,y): # 处理小数点之后的数 return x / 10 + y s0 = reduce(f1,map(char2num,s[0])) # 整数部分 s1 = reduce(f2,list(map(char2num,s[1]))[::-1]) / 10 return s0 + s1 print('str2float(\'123.456\') =', str2float('123.456')) if abs(str2float('123.456') - 123.456) < 0.00001: print('测试成功!') else: print('测试失败!')
③ filter 过滤器
Ⅰ filter
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
🚩 filter()的作用是从一个序列中筛出符合条件的元素。由于filter()使用了惰性计算,所以只有在取filter()结果的时候,才会真正筛选并每次返回下一个筛出的元素。
例如,在一个 list 中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
print(list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))) # [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
print(list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))) # ['A', 'B', 'C']
strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list
💬 再比如:利用filter()筛选出回文数(从左向右读和从右向左读都是一样的数 ,例如12321,909):
def is_palindrome(n):
s = str(n)
return s == s[::-1]
output = filter(is_palindrome, range(1, 1000))
print('1~1000 的回文数:', list(output))

Ⅱ filter 求素数
首先,列出从2开始的所有自然数,构造一个序列:
2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
取序列的第一个数2,它一定是素数,然后用2把序列的2的倍数筛掉:
3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
取新序列的第一个数3,它一定是素数,然后用3把序列的3的倍数筛掉:
5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
取新序列的第一个数5,然后用5把序列的5的倍数筛掉:
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...
不断筛下去,就可以得到所有的素数。
# 构造一个从3开始的奇数序列.注意这是一个生成器,并且是一个无限序列。
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
# 定义一个筛选函数
def _not_divisible(n):
def f(x):
return x % n > 0
# 定义一个生成器,不断返回下一个素数
# 这个生成器先返回第一个素数2,然后,利用filter()不断产生筛选后的新的序列。
def primes():
yield 2 # 2是素数
it = _odd_iter() #创建一个<generator object _odd_iter>,代表奇数序列
while True:
n = next(it) #返回奇数序列的一个数
yield n # 这个数是素数,所以返回。
# 用filter()来筛选, it生成器中的数字
it = filter(_not_divisible(n),it)
# 由于primes()也是一个无限序列,所以调用时需要设置一个退出循环的条件
for n in primes():
if n < 20:
print(n)
else:
break
由本例可知,generator其实就是算法,它不会一次性产生全部数据,而是根据调用的次数,逐步向内存写入数据。
本例把一个生成器对象作为参数传入了filter()函数,其实就是对这个生成器的代码进行更新,即改进算法。
④ sorted 排序
排序也是在程序中经常用到的算法。无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。如果是数字,我们可以直接比较,但如果是字符串或者两个dict呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。
Python内置的sorted()函数就可以对 list 进行排序:
print(sorted([36, 5, -12, 9, -21])) # [-21, -12, 5, 9, 36]
此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
print(sorted([36, 5, -12, 9, -21], key=abs)) # [5, 9, -12, -21, 36]
💬 我们再看一个字符串排序的例子:
print(sorted(['bob', 'about', 'Zoo', 'Credit'])) # ['Credit', 'Zoo', 'about', 'bob']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
print(sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)) # ['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
print(sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)) # ['Zoo', 'Credit', 'bob', 'about']
从上述例子可以看出,高阶函数的抽象能力是非常强大的,而且,核心代码可以保持得非常简洁。
💬 sorted 代码实例:
假设我们用一组tuple表示学生名字和成绩:
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
请用sorted()对上述列表分别按名字 / 成绩 进行排序:
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_name(t):
return t[0]
def by_score(t):
return t[1]
L1 = sorted(L, key=by_name)
print(L1)
L2 = sorted(L, key=by_score)
print(L2)
🚩 解析:sorted 将 key 函数作用在序列的每一个元素,然后对函数 by_name / by_score 的返回值进行排序,再返回排好后的序列
所以 t 就是当前传入到 key 函数的那个元素,t[0] 就是第一个子元素,也就是姓名;t[1] 就是第二个子元素,也就是分数
2. 返回函数
① 函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
我们来实现一个可变参数的求和。通常情况下,求和的函数是这样定义的:
def calc_sum(*args):
ax = 0
for n in args:
ax = ax + n
return ax
但是,如果不需要立刻求和,而是在后面的代码中,根据需要再计算怎么办?可以不返回求和的结果,而是返回求和的函数:
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
f = lazy_sum(1, 3, 5, 7, 9)
print(f) # <function lazy_sum.<locals>.sum at 0x101c6ed90>
调用函数f时,才真正计算求和的结果:
print(f()) # 25
🚩 在这个例子中,我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
请再注意一点,当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
f1 = lazy_sum(1, 3, 5, 7, 9)
f2 = lazy_sum(1, 3, 5, 7, 9)
print(f1==f2) # False
f1()和f2()的调用结果互不影响。
② 闭包
如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数。
🔴 闭包: 在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
#闭包函数的实例
# lazy_sum是外部函数 args 是外函数的临时变量
def lazy_sum(*args):
def sum():
# ax 是内函数
ax = 0
#在内函数中 用到了外函数的临时变量
for n in args:
ax = ax + n
return ax
# 外函数的返回值是内函数的引用
return sum
注意到返回的函数在其定义内部引用了局部变量args,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用,所以,闭包用起来简单,实现起来可不容易。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了lazy_sum()才执行。我们来看一个例子:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
在上面的例子中,每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了。
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是:
print(f1()) # 9
print(f2()) # 9
print(f3()) # 9
全部都是9!原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
🚨 返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
再看看结果:
f1, f2, f3 = count()
print(f1()) # 1
print(f2()) # 4
print(f3()) # 9
缺点是代码较长,可利用 lambda 函数缩短代码。
💬 闭包代码示例:
利用闭包返回一个计数器函数,每次调用它返回递增整数:
def createCounter():
L=[0]
def counter():
L[0]=L[0]+1
return L[0]
return counter
counterA = createCounter()
print(counterA(), counterA(), counterA(), counterA(), counterA()) # 1 2 3 4 5
counterB = createCounter()
if [counterB(), counterB(), counterB(), counterB()] == [1, 2, 3, 4]:
print('测试通过!')
else:
print('测试失败!')
3. 匿名函数 / Lamda 函数
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
r = list(map(lambda x: x*x, [1,2,3]))
print(r)
匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
f = lambda x: x*x
print(f) # <function <lambda> at 0x0000024FA912C268>
print(f(5)) # 25
同样,也可以把匿名函数作为返回值返回,比如:
def build(x, y):
return lambda: x * x + y * y
4. 装饰器 Decorator
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
def now():
print('2015-3-25')
f = now
print(f())
函数对象有一个__name__属性,可以拿到函数的名字:
print(now.__name__) # 'now'
print(f.__name__) # 'now'
现在,假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
💡 类似于 Spring 中的 AOP,Java 中的动态代理
本质上,decorator 就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的 decorator,可以定义如下:
def log(func):
def wrapper(*args, **kw):
print('call function %s' %func.__name__)
return func(*args, **kw) # 调用原始函数
return wrapper
@log
def now():
print('2015-3-25')
now()
把@log放到now()函数的定义处,相当于执行了语句:
now = log(now)
由于log()是一个 decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s function %s' %(text,func.__name__))
return func(*args, **kw) # 执行原函数
return wrapper
return decorator
@log('execute')
def now():
print('2015-3-25')
now()

和两层嵌套的decorator相比,3层嵌套的效果是这样的:
now = log('execute')(now)
我们来剖析上面的语句,首先执行log('execute'),返回的是decorator函数,再调用返回的函数,参数是now函数,返回值最终是wrapper函数。
以上两种decorator的定义都没有问题,但还差最后一步。因为我们讲了函数也是对象,它有__name__等属性,❓ 但你去看经过decorator装饰之后的函数,它们的__name__已经从原来的'now'变成了'wrapper':
print(now.__name__) # 'wrapper'
因为返回的那个wrapper()函数名字就是'wrapper',所以,需要把原始函数的__name__等属性复制到wrapper()函数中,否则,有些依赖函数签名的代码执行就会出错。
👍 不需要编写wrapper.__name__ = func.__name__这样的代码,Python内置的functools.wraps就是干这个事的,所以,一个完整的decorator的写法如下:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
或者针对带参数的decorator:
import functools
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('%s function %s' %(text,func.__name__))
return func(*args, **kw) # 执行原函数
return wrapper
return decorator
在定义wrapper()的前面加上@functools.wraps(func)即可。
💬 装饰器代码实例:
请设计一个decorator,它可作用于任何函数上,并打印该函数的执行时间
import functools,time
def metric(fn):
@functools.wraps(fn)
def wrapper(*args, **kw):
startTime = time.time() # 计算函数开始时间
fn(*args, **kw) # 执行原函数
endTime = time.time() # 计算函数结束时间
print('%s executed in %s ms' % (fn.__name__, endTime - startTime))
return fn(*args, **kw)
return wrapper
@metric
def fast(x, y):
time.sleep(0.0012)
return x + y;
@metric
def slow(x, y, z):
time.sleep(0.1234)
return x * y * z;
f = fast(11, 22)
s = slow(11, 22, 33)

5. 偏函数 Partial function
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
在介绍函数参数的时候,我们讲到,通过设定参数的默认值,可以降低函数调用的难度。而偏函数也可以做到这一点。举例如下:
int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换:
print(int('12345')) # 12345
但int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做N进制的转换:
print(int('12345', base=8)) # 5349
print(int('12345', 16)) # 74565
假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,于是,我们想到,可以定义一个int2()的函数,默认把base=2传进去:
def int2(x, base=2):
return int(x, base)
这样,我们转换二进制就非常方便了:
print(int2('1000000')) # 64
print(int2('1010101')) # 85
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
import functools
int2 = functools.partial(int, base=2)
print(int2('1000000')) # 64
🔵 所以,简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值:
print(int2('1000000', base=10)) # 1000000
最后,创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数,当传入:
int2 = functools.partial(int, base=2)
实际上固定了int()函数的关键字参数base,也就是:
int2('10010')
相当于:
kw = { 'base': 2 }
int('10010', **kw)
当传入:
max2 = functools.partial(max, 10)
实际上会把10作为*args的一部分自动加到左边,也就是:
max2(5, 6, 7)
相当于:
args = (10, 5, 6, 7)
max(*args)
结果为10。
🚩 总结:当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号