3-高级特性
🌽 高级特性
掌握了Python的数据类型、语句和函数,基本上就可以编写出很多有用的程序了。
比如构造一个1, 3, 5, 7, ..., 99的列表,可以通过循环实现:
L = []
n = 1
while n <= 99:
L.append(n)
n = n + 2
取list的前一半的元素,也可以通过循环实现。
但是在Python中,代码不是越多越好,而是越少越好。代码不是越复杂越好,而是越简单越好。
基于这一思想,我们来介绍Python中非常有用的高级特性,1行代码能实现的功能,决不写5行代码。请始终牢记,代码越少,开发效率越高。
1. 切片 Slice
① list 切片
取一个list或tuple的部分元素是非常常见的操作。比如,一个list如下:
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
取前3个元素,应该怎么做?
笨办法:
print([L[0], L[1], L[2]]) # ['Michael', 'Sarah', 'Tracy']
取前N个元素,也就是索引为0-(N-1)的元素,可以用循环:
r = []
n = 3
for i in range(n):
r.append(L[i])
print(r) # ['Michael', 'Sarah', 'Tracy']
对这种经常取指定索引范围的操作,用循环十分繁琐,因此,Python提供了切片 Slice 操作符,能大大简化这种操作。
对应上面的问题,取前3个元素,用一行代码就可以完成切片:
print(L[0:3])
# ['Michael', 'Sarah', 'Tracy']
👍 L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
L[:3] # ['Michael', 'Sarah', 'Tracy']
也可以从索引1开始,取出2个元素出来:
L[1:3] # ['Sarah', 'Tracy']
类似的,既然Python支持L[-1]取倒数第一个元素,那么它同样支持倒数切片,试试:
L[-2:] # ['Bob', 'Jack']
L[-2:-1] # ['Bob']
记住倒数第一个元素的索引是-1。
⭐ 切片格式:[开头:结束:步长]
-
开头:当步长 >0 时,开头不写默认 0,即从第一位开始切片
当步长 < 0时,开头不写默认 -1 ,即从最后一位开始倒着切片
-
结束:当步长 > 0 时,结束不写默认为列表长度加一,即切片到最后一位结束
当步长 < 0 时,结束不写默认为负的列表长度减一,即倒着切片到第一位结束
-
步长:默认为1,> 0 是从左往右走,< 0 是从右往左走
💬 切片操作十分有用。我们先创建一个0-99的数列:
L = list(range(100)) # [0, 1, 2, 3, ..., 99]
可以通过切片轻松取出某一段数列。比如前10个数:
L[:10] # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
后10个数:
L[-10:] # [90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
前11-20个数:
L[10:20] # [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
前10个数,每两个取一个:
L[:10:2] # [0, 2, 4, 6, 8]
所有数,每5个取一个:
L[::5] # [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95]
甚至什么都不写,只写[:]就可以原样复制一个list:
L[:] # [0, 1, 2, 3, ..., 99]
② tuple 切片
tuple 也是一种 list,唯一区别是 tuple 不可变。因此,tuple 也可以用切片操作,只是操作的结果仍是 tuple:
(0, 1, 2, 3, 4, 5)[:3] # (0, 1, 2)
③ str 切片
字符串'xxx'也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:
'ABCDEFG'[:3] # 'ABC'
'ABCDEFG'[::2] # 'ACEG'
在很多编程语言中,针对字符串提供了很多各种截取函数(例如,substring),其实目的就是对字符串切片。Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
实例:
利用切片操作,实现一个trim()函数,去除字符串首尾的空格
def trim(s):
while(s[:1] == ' '):
s = s[1:]
while(s[-1:] == ' '):
s = s[:-1]
return s
s = ' abcde '
print(trim(s)) # 'abcde'
2. 迭代 / 可迭代对象 Iterable
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
在Python中,迭代是通过for ... in来完成的,而很多语言比如C语言,迭代list是通过下标完成的,比如Java代码:
for (i=0; i<list.length; i++) {
n = list[i];
}
可以看出,Python的for循环抽象程度要高于 C 的for循环,因为Python的for循环不仅可以用在list或tuple上,还可以作用在其他可迭代对象上。
list这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:
d = {'a': 1, 'b': 2, 'c': 3}
for key in d:
print(key)
因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不一样。
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
由于字符串也是可迭代对象,因此,也可以作用于for循环:
for ch in 'ABC':
print(ch)
所以,当我们使用for循环时,只要作用于一个可迭代对象,for循环就可以正常运行,而我们不太关心该对象究竟是list还是其他数据类型。
那么,如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:
from collections import Iterable
isinstance('abc', Iterable) # str是否可迭代
# True
isinstance([1,2,3], Iterable) # list是否可迭代
# True
isinstance(123, Iterable) # 整数是否可迭代
# False
如果要对list实现类似Java那样的下标循环怎么办?Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
list = ['A','B',234]
for i, value in enumerate(list):
print(i, value)

上面的for循环里,同时引用了两个变量,在Python里是很常见的,比如下面的代码:
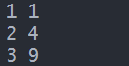
for x, y in [(1,1),[2,4],[3,9]]:
print(x,y)
💬 迭代器实例:
使用迭代查找一个list中最小和最大值,并返回一个tuple:
def findMinAndMax(L):
if len(L) == 0:
return (None,None)
min = max = L[0]
for x in L:
if x < min:
min = x
if x > max:
max = x
return (min, max)
print(findMinAndMax([1,3,5,2])) # (1, 5)
3. 列表生成式 List Comprehensions
① 列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
举个例子,要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11)):
list(range(1, 11))
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
但如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?方法一是循环:
L = []
for x in range(1, 11):
L.append(x * x)
print(L)
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的 list:
print([x*x for x in range(1,11)])
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
🚩 写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来,即根据f or 循环遍历的结果计算 x * x
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
print([x * x for x in range(1, 11) if x % 2 == 0])
# [4, 16, 36, 64, 100]
还可以使用两层循环,可以生成全排列:
print([m + n for m in 'ABC' for n in 'XYZ'])
# ['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
三层和三层以上的循环就很少用到了。
运用列表生成式,可以写出非常简洁的代码。例如,列出当前目录下的所有文件和目录名,可以通过一行代码实现:
import os
print([d for d in os.listdir('.')])
# ['.vscode', 'BookCRUD_Demo', 'BookStore02', 'ClassSolutions', 'CodeScanner', 'JavaWeb两个案例', 'MyQRCode', 'ORCodeTest', 'Program-Cpp', 'Program-Ds', 'Program-Java', 'Program-Vue', 'Program_Python', 'Python', 'ScanCode-master', 'Spring-Programs', 'springboottest', 'studentManage', 'TestInfo', 'tiantian', 'vuetest2', '数据库']
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
d = {'x': 'A', 'y': 'B', 'z': 'C' }
print([k + '=' + v for k,v in d.items()]) # 字符串和输出之间用 + 连接
# ['x=A', 'y=B', 'z=C']
最后把一个list中所有的字符串变成小写:
L = ['Hello', 'World', 'IBM', 'Apple']
print([s.lower() for s in L])
# ['hello', 'world', 'ibm', 'apple']
② 列表生成式中的 if else
使用列表生成式的时候,有些童鞋经常搞不清楚if...else的用法。
例如,以下代码正常输出偶数:
[x for x in range(1, 11) if x % 2 == 0]
# [2, 4, 6, 8, 10]
但是,我们不能在最后的if加上else:
>>> [x for x in range(1, 11) if x % 2 == 0 else 0]
File "<stdin>", line 1
[x for x in range(1, 11) if x % 2 == 0 else 0]
^
SyntaxError: invalid syntax
这是因为跟在for后面的if是一个筛选条件,不能带else,否则如何筛选?
如果把if写在for前面必须加else,否则报错:
>>> [x if x % 2 == 0 for x in range(1, 11)]
File "<stdin>", line 1
[x if x % 2 == 0 for x in range(1, 11)]
^
SyntaxError: invalid syntax
这是因为for前面的部分是一个表达式,它必须根据x计算出一个结果。因此,考察表达式:x if x % 2 == 0,它无法根据x计算出结果,因为缺少else,必须加上else:
[x if x % 2 == 0 else -x for x in range(1, 11)]
# [-1, 2, -3, 4, -5, 6, -7, 8, -9, 10]
上述for前面的表达式x if x % 2 == 0 else -x才能根据x计算出确定的结果。
⭐ 可见,在一个列表生成式中,for前面的if ... else是表达式,而for后面的if是过滤条件,不能带else。
💬 列表生成式代码示例:
如果list中既包含字符串,又包含整数,非字符串类型没有lower()方法,请修改列表生成式,通过添加if语句保证列表生成式能正确地执行:
L1 = ['Hello', 'World', 18, 'Apple', None]
# 保留所有数据并小写 ['hello', 'world', 18, 'apple', None]
print([s.lower() if isinstance(s,str) else s for s in L1])
# 只保留字符串并小写 ['hello', 'world', 'apple']
print([s.lower() for s in L1 if isinstance(s,str)])
4. 生成器 Generator
① Generator
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
L = [x * x for x in range(10)]
print(L) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
g = (x * x for x in range(10))
print(g) # <generator object <genexpr> at 0x1022ef630>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
print(next(g))
# 0
print(next(g))
# 1
print(next(g))
# 4
print(next(g))
# 9
print(next(g))
# 16
print(next(g))
# 25
print(next(g))
# 36
print(next(g))
# 49
print(next(g))
# 64
print(next(g))
# 81
print(next(g))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
我们讲过,generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
g = (x*x for x in range(10))
for n in g:
print(n)
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
② 带 yield 的 Generator Function
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
print(fib(6))
注意,赋值语句:
a, b = b, a + b
相当于:
t = (b, a + b) # t是一个tuple
a = t[0]
b = t[1]
但不必显式写出临时变量t就可以赋值。
上面的函数可以输出斐波那契数列的前N个数:
1
1
2
3
5
8
'done'
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
👉 也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
f = fib(6)
print(f) # <generator object fib at 0x104feaaa0>
⭐ 这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
举个简单的例子,定义一个generator,依次返回数字1,3,5:
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
调用该generator时,首先要生成一个generator对象,然后用next()函数不断获得下一个返回值:
o = odd()
print(next(o))
print(next(o))
print(next(o))
print(next(o))
输出结果:
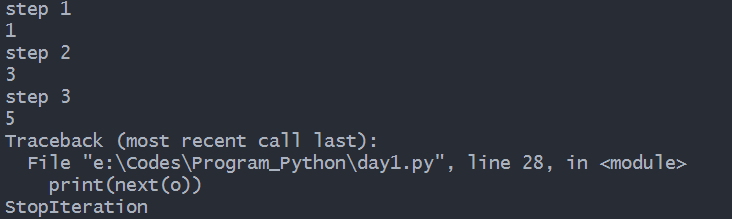
可以看到,odd不是普通函数,而是generator,在执行过程中,遇到yield就中断,下次又继续执行。执行3次yield后,已经没有yield可以执行了,所以,第4次调用next(o)就报错。
回到fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
for n in fib(6):
print(n)
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
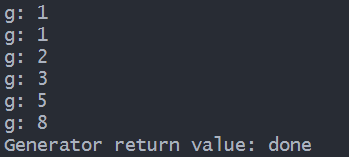
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
输出结果:
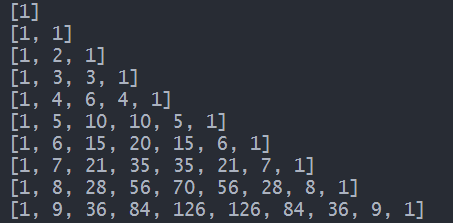
💬 生成器代码示例:
使用生成器打印杨辉三角:把每一行看做一个 list
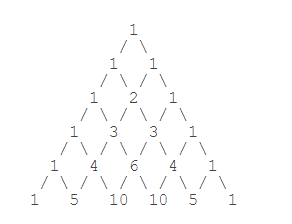
def triangles():
L = [1] # 定义一个 list
while True:
yield L # 打印该 list
L = [L[x] + L[x+1] for x in range(len(L) - 1)] # 计算下一行中间的值,除去首尾的1
L.insert(0,1) # 首位插入 1
L.append(1) # 末尾插入 1
if(len(L) > 10): # 仅输出 10 行
break
# 生成一个generator对象,然后通过for循环迭代输出每一行
tri = triangles()
for i in tri:
print(i)
5. 迭代器 Iterator
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
🔵 这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
from collections.abc import Iterable
isinstance([], Iterable) # True
isinstance({}, Iterable) # True
isinstance('abc', Iterable) # True
isinstance((x for x in range(10)), Iterable) # True
isinstance(100, Iterable) # False
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
🔴 可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
from collections.abc import Iterator
isinstance((x for x in range(10)), Iterator) # True
isinstance([], Iterator) # False
isinstance({}, Iterator) # False
isinstance('abc', Iterator) # False
🚨 生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
isinstance(iter([]), Iterator) # True
isinstance(iter('abc'), Iterator) # True
❓ 你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
🔷 Python的
for循环本质上就是通过不断调用next()函数实现的,例如:for x in [1, 2, 3, 4, 5]: pass实际上完全等价于:
# 首先获得 Iterator 迭代器对象: it = iter([1, 2, 3, 4, 5]) # 循环: while True: try: # 获得下一个值: x = next(it) except StopIteration: # 遇到StopIteration就退出循环 break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号