Kubernetes之十九---Kubernetes网络插件体系及flannel基础
1、背景
自Docker 技术诞生以来,采用容器技术用于开发、测试甚至是生产环境的企业或组织 与日俱增。 然而,将容器技术应用于生产环境时如何确定合适的网络方案依然是亟待解决的 最大问题,这也曾是主机虚拟化时代的著名难题之一,它不仅涉及了网络中各组件的互连互 通,还需要将容器与不相关的其他容器进行有效隔离以确保其安全性。 本章将主要讲述容器 网络模型的进化、 Kubernetes 的网络模型、常用网络插件以及网络策略等相关的话题。
2、Kubernetes 网络模型及CNI插件
Docker 的传统网络模型在应用至日趋复杂的实际业务场景时必将导致复杂性的几何级 数上升,由此,Kubernetes 设计了一种网络模型,它要求所有容器都能够通过一个扁平的网 络平面直接进行通信(在同一 IP 网络中),无论它们是否运行于集群中的同一节点。 不过, 在 Kubernetes 集群中, IP 地址分配是以 Pod 对象为单位,而非容器, 同一Pod 内的所有容 器共享同一网络名称空间。
2.1 Docker容器的网络模型
Docker 容器网络的原始模型主要有三种: Bridge(桥接)、Host(主机)及 Container(容器)。
- Bridge 模型借助于虚拟网桥设备为容器建立网络连接
- Host 模型则设定容器直接共享使用 节点主机的网络名称空间
- Container 模型则是指多个容器共享同一个网络名称空间,从 而彼此之间能够以本地通信的方式建立连接。
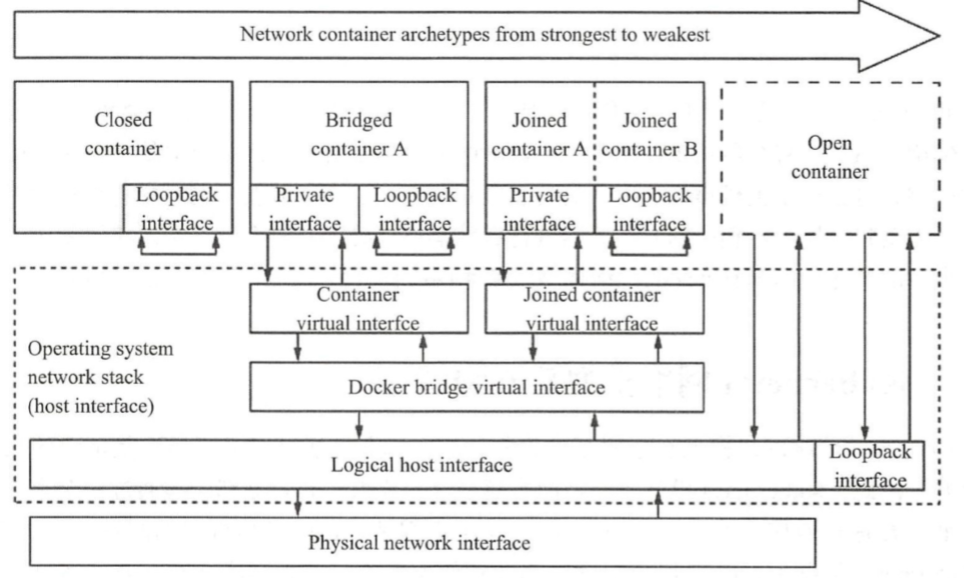
Docker 守护进程首次启动时-,它会在当前节点上创建一个名为 dockerO 的桥设备,并默认配置其使用 172.17.0.0/16 网络,该网络是 Bridge 模型的一种实现, 也是创建 Docker 容 器时默认使用的网络模型。 如图所示, 创建 Docker 容器时,默认有四种网络可供选择 使用 ,从而表现出了四种不同类型的容器,具体如下。
- Closed container (封闭式容器): 此类容器使用“ None ”网络,它们没有对外通信的 网络接 口,而是仅具有 IO 接口,通常仅用于不需要网络的后端作业处理场景。
- Bridged container (桥接式容器):此类容器使用“ Bridge,,模型的网络,对于每个网 络接口,容器引擎都会为每个容器创建一对(两个)虚拟以太网设备,一个配置为容 器的接口设备,另一个则在节点主机上接人指定的虚拟网桥设备(默认为 docker0 )。
- Open container (开放式容器): 此类容器使用“ Host,,模型的网络,它们共享使用 Docker 主机的网络及其接口 。
- Joined container(联盟式容器):此类容器共享使用某个已存在的容器的网络名称空间, 即共享并使用指定的容器的网络及其接口 。
2.2 Kubernetes 网络模型
Kubernetes 的网络模型主要可用于解决四类通信需求:同一Pod 内容器间的通信(Contamer to Container)、 Pod 间的通信( Pod to Pod)、 Service 到 Pod 间的通信( Service to Pod)以及 集群外部与 Service 之间的通信(external to Service) 。
Pod容器之间的通信方式:
- Containers-Containers:lo
- Pod-Pod
- Pod-External Clients
2.2.1 容器间通信
Pod 对象内的各容器共享同一网络名称空间,它通常由构建 Pod 对象的基础架构容器所提供,例如,由 pause 镜像启动的容器。 所有运行于同一个 Pod 内的容器与同一主机上的多 个进程类似,彼此之间可通过 lo 接口完成交互,如图所示, Pod P 内的 Container! 和 Container2 之间的通信即为容器间通信。
2.2.2 Pod间通信
各Pod 对象需要运行于同一个平面网络中,每个 Pod 对象拥有一个集群全局唯一的地 址并可直接用于与其他 Pod 进行通信,图中的 Pod P 和 Pod Q 之间的通信。 此网络 也称为 Pod 网络。 另外,运行 Pod 的各节点也会通过桥接设备等持有此平面网络中的一个 IP 地址,如图 l 1-3 中的 cbr0 接口,这就意味着 Node 到 Pod 间的通信也可在此网络上直接 进行。 因此, Pod 间的通信或 Pod 到 Node 间的通信比较类似于同一 IP 网络中主机间进行的通信。

此类通信模型中的通信需求也是 Kubernetes 的各网络插件需要着力解决的问题,它们 的实现方式有叠加网络模型和路由网络模型等,流行的解决方案有十数种之多,例如前面使 用到的flannel。
2.2.3 Service与Pod间的通信
Service 资源的专用网络也称为集群网络( Cluster Network),需要在启动 kube-apiserver 时经由“ --service-cluster叩-range”选项进行指定,如 10.96.0.0/12,而每个 Service 对象在 此网络中均拥一个称为 Cluster-IP 的固定地址。 管理员或用户对 Service 对象的创建或更改 操作由 API Server 存储完成后触发各节点上的 kube-proxy,并根据代理模式的不同将其定义 为相应节点上的 iptables 规则或 ipvs 规则,借此完成从 Service 的 Cluster-IP与 Pod-IP 之间的报文转发,如图所示。

2.2.4 集群外部到 Pod 对象之间的通信
将集群外部的流量引入到 Pod 对象的方 式有受限于 Pod 所在的工作节点范围的节点 端口( nodePort)和主机网络( hostNetwork) 两种,以及工作于集群级别的 NodePort 或 LoadBalancer 类型的 Service 对象。 不过, 即便是四层代理的模式也要经由两级转发才能到达目标pod资源:请求流量首先到达外部负载均衡器,由其调度至某个工作节点之 上,而后再由工作节点的 netfilter ( kube“proxy)组件上的规则( iptables 或 ipvs)调度至某 个目标 Pod 对象。
2.3 Pod 网络的实现方式
每个 Pod 对象内的基础架构容器均使用一个独立的网络名称空间,并共享给同一Pod 内的其他容器使用。 每个名称空间均有其专用的独立网络协议战及其相关的网络接口设备。 一个网络接口仅能属于一个网络名称空间,于是,运行多个 Pod 必然要求使用多个网络名 称空间,也就需要用到多个网络接口设备。 不过 一个易于实现的方案是使用软件实现的伪 网络接口及模拟线缆将其连接至物理接口 。 伪网络接口的实现方案常见的有虚拟网桥、多路复用及硬件交换三种。
-
-
多路复用 : 多路复用可以由一个中间网络设备组成,它暴露了多个虚拟接口,可使 用数据包转发规则来控制每个数据包转到的目标接口 。 MACVLAN 为每个虚拟接口 配置一个 MAC 地址并基于此地址完成二层报文收发,而 IPVLAN 是基于 IP 地址的 并使用单个 MAC,从而使其更适合 VM。
-
大多数情况下,用户希望创建跨越多个 L2 或口的逻辑网络子网,这就要借助于叠加 封装协议来实现(最常见的是 VXLAN,它将叠加流量封装到 UDP 数据包中)。 不过,由 于控制平面缺乏标准化, VXLAN 可能会引人更高的开销,并且来自不同供应商的多个VXLAN 网络通常无法互操作。 而 Kubernetes 还将大量使用 iptables 和 NAT 来拦截进入逻 辑/ 虚拟地址的流量并将其路由到适当的物理目的地。

无论上述哪种方式应用于容器环境中,其实现过程都需要大量的操作步骤。 不过,目前Kubernetes 支持使用CNI插件来编排网络,以实现 Pod 及集群网络管理功能的自动 化。 每次 Pod 被初始化或删除时 kubelet 都会调用默认的 CNI 插件创建一个虚拟设备接 口附加到相关的底层网络,为其设置 IP 地址、路由信息并将其映射到 Pod 对象的网络名称 空间。
配置Pod的网络时,kubelet 首先在默认的/etc/cni/net.d目录中查找CNI JSON配置 文件,接着基于 type 属性到/o[t/cni/bin中查找相关的插件二进制文件,如下面示例中的 “ portmap ” 。 随后,由 CNI 插件调用 IPAM 插件( IP 地址管理)来设置每个接口的 IP 地址, 如 host-local 或 dhcp 等:
2.4 CNI 插件及其常见的实现
Kubemetes 设计了网络模型,但将其实现交给了网络插件。 于是,各种解决方案不断涌 现。 为了规范及兼容各种解决方案, CoreOS 和 Google 联合制定了 CNI ( Contain巳r Network Interface)标准,旨在定义容器网络模型规范。 它连接了两个组件: 容器管理系统和网络插 件。 它们之间通过 JSON 格式的文件进行通信,以实现容器的网络功能。 具体的工作均由插 件来实现,包括创建容器 netns、关联网络接口到对应的 netns 以及为网络接口分配 IP 等。 CNI 的基本思想是:容器运行时环境在创建容器时,先创建好网络名称空间( netns), 然后调用CNI 插件为这个netns 配置网络,而后再启动容器内的进程。
CNI 本身只是规范,付诸生产还需要有特定的实现。 目前, CNI 提供的插件分为三类: main、 meta 和 ipam。 main一类的插件主要在于实现某种特定的网络功能,例如 loopback、 bridge、 macvlan 和 ipvlan 等; meta 一类的插件自身并不提供任何网络实现,而是用于调用 其他插件,例如调用 flannel; ipam 仅用于分配 IP 地址,而不提供网络实现。
CNI 具有很强的扩展性和灵活性,例如,如果用户对某个插件具有额外的需求,则 可以通过输入中的 args 和环境变量 CNI_ARGS 进行传递,然后在插件中实现自定义的功 能,这大大增加了它的扩展性。另外,CNI 插件将 main 和 ipam 分开,赋予了用户自由组 合它们的机制,甚至一个 CNI 插件也可以直接调用另外一个 CNI 插件。 CNI 目前已经是 Kubernetes 当前推荐的网络方案。 常见的 CNI 网络插件包含如下这些主流的项目 。
- Flannel :一个为 Kubernetes 提供叠加网络的网络插件,它基于 Linux TUN/TAP ,使 用 UDP 封装 IP 报文来创建叠加网络,并借助 etcd 维护网络的分配情况。
- Calico : 一个基于 BGP 的三层网络插件 并且也支持网络策略来实现网络的访问控 制;它在每台机器上运行一个 vRouter,利用 Linux 内核来转发网络数据包, 并借助 iptables 实现防火墙等功能。
- Canal : 由 Flannel 和 Calico 联合发布的一个统一网络捅件,提供 CNI 网络插件,并支持网络策略。
3、基于CNI网络模型实现
3.1 创建副本pod
1、创建多个副本pod,用来实验效果
[root@master bin]# kubectl create deployment myapp --image=ikubernetes/myapp:v1 # 创建一个myapp的pod deployment.apps/myapp created [root@master bin]# kubectl scale deployment myapp --replicas=3 # 将myapp的pod分为三个副本 deployment.apps/myapp scaled
2、查看副本详细信息
[root@master ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-5c6976696c-2md48 1/1 Running 0 4m33s 10.244.1.120 node1 <none> <none> myapp-5c6976696c-l2hbl 1/1 Running 0 67s 10.244.2.118 node2 <none> <none> myapp-5c6976696c-n2k97 1/1 Running 0 57s 10.244.1.121 node1 <none> <none>
3、此时上面可以通信是在cni0这个网络桥上,以下是各个网络之前通讯的网络模式接口:cni0、docker0、eth0、flannel.1
[root@node2 ~]# ifconfig # 查看对应的cni0信息
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.1 netmask 255.255.255.0 broadcast 10.244.2.255
inet6 fe80::d0cb:f7ff:feac:2285 prefixlen 64 scopeid 0x20<link>
ether d2:cb:f7:ac:22:85 txqueuelen 1000 (Ethernet)
RX packets 37017 bytes 6844157 (6.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 40564 bytes 4730267 (4.5 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:1e:a1:3e:9e txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.7.103 netmask 255.255.255.0 broadcast 192.168.7.255
inet6 fe80::20c:29ff:fe62:fd2a prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:62:fd:2a txqueuelen 1000 (Ethernet)
RX packets 82626 bytes 46977592 (44.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 77948 bytes 7494426 (7.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::7ce1:4dff:fef3:3395 prefixlen 64 scopeid 0x20<link>
ether 7e:e1:4d:f3:33:95 txqueuelen 0 (Ethernet)
RX packets 1625 bytes 136500 (133.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1625 bytes 136500 (133.3 KiB)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
3.2 测试cni0通信效果
1、在master节点上与node节点上进行互通
[root@master ~]# kubectl exec -it myapp-5c6976696c-2md48 -- /bin/sh / # ping 10.244.2.118 PING 10.244.2.118 (10.244.2.118): 56 data bytes 64 bytes from 10.244.2.118: seq=0 ttl=62 time=1.421 ms 64 bytes from 10.244.2.118: seq=1 ttl=62 time=0.755 ms ^C --- 10.244.2.118 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.755/1.088/1.421 ms
2、在node1节点上查看此时的tcpdump信息,此时可以看到两个pod之间是可以通过icmp协议通信
[root@node1 ~]# tcpdump -i cni0 -nn icmp tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on cni0, link-type EN10MB (Ethernet), capture size 262144 bytes 17:38:27.505778 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 0, length 64 17:38:27.506494 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 0, length 64 17:38:28.506758 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 1, length 64 17:38:28.509794 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 1, length 64 17:38:29.508176 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 2, length 64 17:38:29.508651 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 2, length 64 17:38:30.509067 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 3, length 64 17:38:30.509436 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 3, length 64
4、flannel 网络插件
各 Docker 主机在 docker0桥上默认使用同一个子网,不同节点的容器很可能会得到相 同的地址,于是跨节点的容器问通信会面临地址冲突的问题。 另外,即使人为地设定多个 节点上的 docker0桥使用不同的子网,其报文也会因为在网络中缺乏路由信息而无法准确送 达。 事实上,各种CNI 插件都至少要解决这两类问题。
对于第一个问题, flannel 的解决办法是,预留使用一个网络,如 I0.244.0.0/16,而后 自动为每个节点的 Docker 容器引擎分配一个子网,如 10.244.1.0/24 和 10.244.20/24 ,并将其分配信息保存于etcd 持久存储。对于第二个问题, flannel 有着多种不同的处理方法,每 一种处理方法也可以称为一种网络模型,或者称为flannel使用的后端。
- VxLAN : Linux 内核自 3.7.0 版本起支持 VxLAN, flannel 的此种后端意味着使用内 核中的 VxLAN 模块封装报文,这也是 flannel 较为推荐使用的方式。

- host-gw :即 Host GateWay,它通过在节点上创建到达目标容器地址的路由直接完成 报文转发,因此这种方式要求各节点本身必须在同一个二层网络中,故该方式不太 适用于较大的网络规模(大二层网络除外)。host-gw 有着较好的转发性能,且易于设定,推荐对报文转发性能要求较高的场景使用。
- UDP :使用普通 UDP 报文封装完成隧道转发,其性能较前两种方式要低很多,仅应 该在不支持前两种方式的环境中使用。
flannel 初创之后的一段时期内,不少环境中的 Linux 发行版的内核尚且不支持 VxLAN,而 host-gw 模式有着略高的网络技术门槛,故此大多数部署场景只好使用 UDP 模 式, flannel 因而不幸地落下性能不好的声名 。 不过,目前 flannel 的部署默认后端已经是叠 加网络模型 VxLAN。 另外,除了这三种后端之外, flannel 还实验性地支持 AliVPC、 AWS VPC、 Alloc 和 GCE 几种后端。
4.1 flannel配置参数
为了跟踪各子网分配信息等, flannel 使用 etcd 来存储虚拟 IP 和主机 IP 之间的映射,各个节点上运行的 flanneld 守护进程负责监视 etcd 中的信息并完成报文路由 。 默认情况下,flannel的配置信息保存于etcd 的键名/coreos .com/network/config 之下,可以使用 etcd 服务 的客户端工具来设定或修改其可用的相关配置。 config 的值是一个 JSON 格式的字典数据结 构,它可以使用的键包含以下几个。
- Network: flannel 于全局使用的 CIDR 格式的 IPv4 网络,字符串格式, 此为必选键, 余下的均为可选。
- SubnetLen :将 Network 属性指定的 IPv4 网络基于指定位的掩码切割为供各节点使 用的子网,此网络的掩码小于 24 时(如 16 ),其切割子网时使用的掩码默认为 24 位。
- SubnetMin :可用作分配给节点使用的起始子网,默认为切分完成后的第一个子网; 字符串格式。
- SubnetMax: 可用作分配给节点使用的最大子网,默认为切分完成后最大的一个子网; 字符串格式。
- Backend : flannel 要使用的后端类型,以及后端的相关配置,字典格式; VxLAN、 host-gw 和 UDP 后端各有其相关的参数。
以上配置信息可直接由 flannel 保存于 etcd 存储中,也可交由 Kubernetes 进行存储。 具 体使用的方式取决于管理员或部署程序的默认配置。 另外, flannel 默认使用 VxLAN 后端, 但 VxLAN direct routing 和 host-gw 却有着更好的性能表现。
4.2 VxLAN 后端和 direct routing
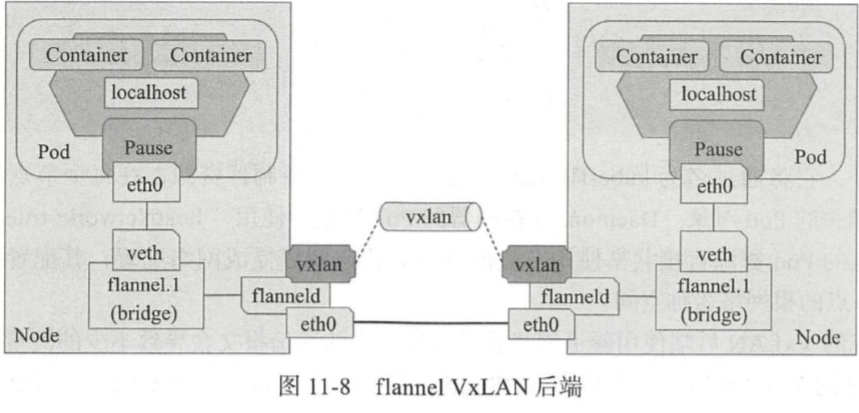
VxLAN 全称 Virtual extensible Local Area Network (虚拟可扩展局域网),是 VLAN 扩展方案草案,采用的是 MAC in UDP 封装方式是 NVo3 ( Network Virtualization over Layer3 )中的一种网络虚拟化技术 ,如下图所示。 具体实现方式为 :将虚拟网络的数据 帧添加到 VxLAN 首部后,封装在物理网络的 UDP 报文中,然后以传统网络的通信方式传 送该 UDP 报文,待其到达目的主机后,去掉物理网络报文的头部信息以及 VxLAN 首部, 然后将报文交付给目的终端如图 l 1-9 所示的拓扑结构中,跨节点的 Pod 间通信即为如此。不过,整个过程中通信双方对物理网络无所感知。

5、在flannel进行网络通信
5.1 进行flannel网络通信
1、在master节点上与node节点上进行ping,此时的flannel网络模式将cni0的网络模式进行封装了
[root@master ~]# kubectl exec -it myapp-5c6976696c-2md48 -- /bin/sh / # ping 10.244.2.118 PING 10.244.2.118 (10.244.2.118): 56 data bytes 64 bytes from 10.244.2.118: seq=0 ttl=62 time=1.421 ms 64 bytes from 10.244.2.118: seq=1 ttl=62 time=0.755 ms ^C --- 10.244.2.118 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.755/1.088/1.421 ms
2、在node1节点上查看此时的tcpdump信息,此时可以看到两个pod之间也可以通过隧道icmp协议通信
[root@node1 ~]# tcpdump -i flannel.1 -nn icmp tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on cni0, link-type EN10MB (Ethernet), capture size 262144 bytes 17:38:27.505778 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 0, length 64 17:38:27.506494 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 0, length 64 17:38:28.506758 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 1, length 64 17:38:28.509794 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 1, length 64 17:38:29.508176 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 2, length 64 17:38:29.508651 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 2, length 64 17:38:30.509067 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 3840, seq 3, length 64 17:38:30.509436 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 3840, seq 3, length 64
5.2 将VxLAN改为DirectRouting网络模型
注意: 为了保证所有 Pod 均能得到正确的网络配置,建议在创建 Pod 资源之前事先配置好网络插件,甚至是事先了解并根据自身业务需求测试完成中意的目标网络插件,在 选型完成后再部署 Kub巳metes 集群,而尽量避免中途修改 , 否则有些 Pod 资源可能 会需要重建。
5.2.1 将VxLAN改为Direct Routing模式
1、在github上下载对应的flannel的yaml文件
[root@master ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
2、修改yaml文件内容,添加DirectRouting字段信息
[root@master ~]# vim kube-flannel.yml
............... # 前面内容省略
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan", # vxlan后面加上逗号
"DirectRouting": true # DirectRouting字段是布尔值形式,后面的true不需要加双引号
}
}
3、基于yaml文件创建新的flannel,并查看信息,此时的DirectRouting模型已经加载成功
[root@master ~]# kubectl apply -f kube-flannel.yml # 基于yaml文件创建新的flannel
podsecuritypolicy.policy/psp.flannel.unprivileged configured
clusterrole.rbac.authorization.k8s.io/flannel unchanged
clusterrolebinding.rbac.authorization.k8s.io/flannel unchanged
serviceaccount/flannel unchanged
configmap/kube-flannel-cfg configured
daemonset.apps/kube-flannel-ds-amd64 configured
daemonset.apps/kube-flannel-ds-arm64 configured
daemonset.apps/kube-flannel-ds-arm configured
daemonset.apps/kube-flannel-ds-ppc64le configured
daemonset.apps/kube-flannel-ds-s390x configured
[root@master ~]# kubectl get cm kube-flannel-cfg -n kube-system -o yaml # 查看此时的网络模型信息
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"DirectRouting": true # 此时的DirectRouting模型已经加载成功
}
}
4、查看此时的flannel重载是否生效,此时是已经生效了
[root@master ~]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-5644d7b6d9-28wzt 1/1 Running 26 13d coredns-5644d7b6d9-dfwv4 1/1 Running 27 13d etcd-master 1/1 Running 26 13d kube-apiserver-master 1/1 Running 26 13d kube-controller-manager-master 1/1 Running 28 13d kube-flannel-ds-amd64-6hh59 1/1 Running 0 2m57s kube-flannel-ds-amd64-77rvg 1/1 Running 0 4m10s kube-flannel-ds-amd64-xgrtr 1/1 Running 0 3m34s kube-proxy-cqvj8 1/1 Running 25 12d kube-proxy-pntl4 1/1 Running 23 12d kube-proxy-tjdvz 1/1 Running 23 12d kube-scheduler-master 1/1 Running 28 13d
5.2.2 验证修改后效果
1、再未修改前的DirectRouting的路由模型时,属于flannel.1的隧道封装模型
[root@node1 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.7.2 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 192.168.7.101 255.255.255.0 UG 0 0 0 eth0 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 10.244.2.0 192.168.7.103 255.255.255.0 UG 0 0 0 flannel.1 # flannel.1封装效果 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.7.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
2、此时在node1节点上查看路由信息,就是以eth0的路由形式显示了,此时就不会再有隧道封装了
[root@node1 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.7.2 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 192.168.7.101 255.255.255.0 UG 0 0 0 eth0 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 10.244.2.0 192.168.7.103 255.255.255.0 UG 0 0 0 eth0 # 此时node1就以eth0进行显示 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.7.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
3、开始在master节点是ping node节点
[root@master ~]# kubectl exec -it myapp-5c6976696c-2md48 -- /bin/sh / # ping 10.244.2.118 PING 10.244.2.118 (10.244.2.118): 56 data bytes 64 bytes from 10.244.2.118: seq=0 ttl=62 time=1.421 ms 64 bytes from 10.244.2.118: seq=1 ttl=62 time=0.755 ms ^C --- 10.244.2.118 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.755/1.088/1.421 ms
4、此时在node1上查看对应的物理网卡eth0信息,物理网卡之间的网络也是互通的
[root@node1 ~]# tcpdump -i eth0 -nn icmp tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes 17:48:03.287790 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 4352, seq 0, length 64 17:48:03.288820 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 4352, seq 0, length 64 17:48:04.288559 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 4352, seq 1, length 64 17:48:04.289054 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 4352, seq 1, length 64 17:48:05.289795 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 4352, seq 2, length 64 17:48:05.290262 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 4352, seq 2, length 64 17:48:06.290673 IP 10.244.1.120 > 10.244.2.118: ICMP echo request, id 4352, seq 3, length 64 17:48:06.291437 IP 10.244.2.118 > 10.244.1.120: ICMP echo reply, id 4352, seq 3, length 64
5.3 flannel重载为Direct Routing未生效解决办法
1、查看此时的flannel的标签信息
[root@master ~]# kubectl get pods -n kube-system --show-labels NAME READY STATUS RESTARTS AGE LABELS coredns-5644d7b6d9-28wzt 1/1 Running 26 13d k8s-app=kube-dns,pod-template-hash=5644d7b6d9 coredns-5644d7b6d9-dfwv4 1/1 Running 27 13d k8s-app=kube-dns,pod-template-hash=5644d7b6d9 etcd-master 1/1 Running 26 13d component=etcd,tier=control-plane kube-apiserver-master 1/1 Running 26 13d component=kube-apiserver,tier=control-plane kube-controller-manager-master 1/1 Running 28 13d component=kube-controller-manager,tier=control-plane kube-flannel-ds-amd64-6hh59 1/1 Running 0 4m23s app=flannel,controller-revision-hash=7cf85bbbfc,pod-template-generation=2,tier=node kube-flannel-ds-amd64-77rvg 1/1 Running 0 5m36s app=flannel,controller-revision-hash=7cf85bbbfc,pod-template-generation=2,tier=node kube-flannel-ds-amd64-xgrtr 1/1 Running 0 5m app=flannel,controller-revision-hash=7cf85bbbfc,pod-template-generation=2,tier=node kube-proxy-cqvj8 1/1 Running 25 12d controller-revision-hash=56c95f6b7b,k8s-app=kube-proxy,pod-template-generation=1 kube-proxy-pntl4 1/1 Running 23 12d controller-revision-hash=56c95f6b7b,k8s-app=kube-proxy,pod-template-generation=1 kube-proxy-tjdvz 1/1 Running 23 12d controller-revision-hash=56c95f6b7b,k8s-app=kube-proxy,pod-template-generation=1 kube-scheduler-master 1/1 Running 28 13d component=kube-scheduler,tier=control-plane
2、删除对应的flannel标签信息,此时对应的flannel就会重新创建
[root@master ~]# kubectl delete pods -l app=flannel -n kube-system pod "kube-flannel-ds-amd64-6hh59" deleted pod "kube-flannel-ds-amd64-77rvg" deleted pod "kube-flannel-ds-amd64-xgrtr" deleted
3、此时查看新的flannel已经创建成功
[root@master ~]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-5644d7b6d9-28wzt 1/1 Running 26 13d coredns-5644d7b6d9-dfwv4 1/1 Running 27 13d etcd-master 1/1 Running 26 13d kube-apiserver-master 1/1 Running 26 13d kube-controller-manager-master 1/1 Running 28 13d kube-flannel-ds-amd64-d2crx 1/1 Running 0 4s # 查看新的flannel在4s之前创建成功 kube-flannel-ds-amd64-dbzbs 1/1 Running 0 3s # 查看新的flannel在3s之前创建成功 kube-flannel-ds-amd64-kfw8d 1/1 Running 0 8s # 查看新的flannel在8s之前创建成功 kube-proxy-cqvj8 1/1 Running 25 12d kube-proxy-pntl4 1/1 Running 23 12d kube-proxy-tjdvz 1/1 Running 23 12d kube-scheduler-master 1/1 Running 28 13d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号