MySQL之三:索引及执行计划
一.扩展
https://www.yiibai.com/mysql/stored-function.html
-
定义
子查询允许把一个查询嵌套在另一个查询当中。
子查询,又叫内部查询,相对于内部查询,包含内部查询的就称为外部查询。
子查询可以包含普通select可以包括的任何子句,比如:distinct、 group by、order by、limit、join和union等;但是对应的外部查询必须是以下语句之一:select、insert、update、delete、set或 者do。
子查询的位置:
select 中、from 后、where 中.group by 和order by 中无实用意义
分类:
可以使用的操作符:= > < >= <= <> ANY IN SOME ALL EXISTS 一个子查询会返回一个标量(就一个值)、一个行、一个列或一个表,这些子查询称之为标量、行、列和表子查询。 如果子查询返回一个标量值(就一个值),那么外部查询就可以使用:=、>、<、>=、<=和<>符号进行比较判断;如果子查询返回的不是一个标量值,而外部查询使用了比较符和子查询的结果进行了比较,那么就会抛出异常。
1.1标量子查询
定义
子查询返回的是单一值的标量,如一个数字或一个字符串,也是子查询中最简单的返回形式。 可以使用 = > < >= <= <> 这些操作符对子查询的标量结果进行比较,通常子查询的位置在比较式的右侧
例子:
SELECT * FROM article WHERE uid = (SELECT uid FROM user WHERE status=1 ORDER BY uid DESC LIMIT 1) SELECT * FROM t1 WHERE column1 = (SELECT MAX(column2) FROM t2) SELECT * FROM article AS t WHERE 2 = (SELECT COUNT(*) FROM article WHERE article.uid = t.uid)
1.2 列子查询
定义
指子查询返回的结果集是 N 行一列,该结果通常来自对表的某个字段查询返回。 可以使用 = > < >= <= <> 这些操作符对子查询的标量结果进行比较,通常子查询的位置在比较式的右侧 ;可以使用 IN、ANY、SOME 和 ALL 操作符,不能直接使用 = > < >= <= <> 这些比较标量结果的操作符。
SELECT * FROM article WHERE uid IN(SELECT uid FROM user WHERE status=1) SELECT s1 FROM table1 WHERE s1 > ANY (SELECT s2 FROM table2) SELECT s1 FROM table1 WHERE s1 > ALL (SELECT s2 FROM table2)
注意
NOT IN 是 <> ALL 的别名,二者相同。 如果 table2 为空表,则 ALL 后的结果为 TRUE; 如果子查询返回如 (0,NULL,1) 这种尽管 s1 比返回结果都大,但有空行的结果,则 ALL 后的结果为 UNKNOWN 。 对于 table2 空表的情况,下面的语句均返回 NULL:
SELECT s1 FROM table1 WHERE s1 > (SELECT s2 FROM table2) SELECT s1 FROM table1 WHERE s1 > ALL (SELECT MAX(s1) FROM table2)
1.3 行子查询
定义:
指子查询返回的结果集是一行 N 列,该子查询的结果通常是对表的某行数据进行查询而返回的结果集。
例子:
SELECT * FROM table1 WHERE (1,2) = (SELECT column1, column2 FROM table2) 注:(1,2) 等同于 row(1,2) SELECT * FROM article WHERE (title,content,uid) = (SELECT title,content,uid FROM blog WHERE bid=2)
1.4 表子查询
指子查询返回的结果集是 N 行 N 列的一个表数据。
例子:
SELECT * FROM article WHERE (title,content,uid) IN (SELECT title,content,uid FROM blog)
不能优化的子查询
http://www.cnblogs.com/loveyouyou616/archive/2012/12/21/2827655.html
1.mysql不支持子查询合并和聚合函数子查询优化,mariadb对聚合函数子查询进行物化优化;
2.mysql不支持from子句子查询优化,mariadb对from子句子查询进行子查询上拉优化;
3.mysql和mariadb对子查询展开提供有限的支持,如对主键的操作才能进行上拉子查询优化;
4.mysql不支持exists子查询优化,mariadb对exists关联子查询进行半连接优化,对exists非关联子查询没有进一步进行优化;
5.mysql和mariadb不支持not exists子查询优化;
6.mysql和mariadb对in子查询,对满足半连接语义的查询进行半连接优化,再基于代价评估进行优化,两者对半连接的代价评估选择方式有差异;
7.mysql不支持not in子查询优化,mariadb对非关联not in子查询使用物化优化,对关联not in子查询不做优化;
8.mysql和mariadb对>all非关联子查询使用max函数,<all非关联子查询使用min函数,对=all和非关联子查询使用exists优化;
9.对>some和>any非关联子查询使用min函数,对<some和<any非关联子查询使用max函数,=any 和=some子查询使用半连接进行优化,对>some和>any关联子查询以及<some和<any关联子查询只有exists 优化。
2.内置函数
2.1 数学函数
abs(x) pi() mod(x,y) sqrt(x) ceil(x)或者ceiling(x) rand(),rand(N):返回0-1间的浮点数,使用不同的seed N可以获得不同的随机数 round(x, D):四舍五入保留D位小数,D默认为0, 可以为负数, 如round(19, -1)返回20 truncate(x, D):截断至保留D位小数,D可以为负数, 如trancate(19,-1)返回10 sign(x): 返回x的符号,正负零分别返回1, -1, 0 pow(x,y)或者power(x,y) exp(x):e^x log(x):自然对数 log10(x):以10为底的对数 radians(x):角度换弧度 degrees(x):弧度换角度 sin(x)和asin(x): cos(x)和acos(x): tan(x)和atan(x): cot(x):
2.2 字符串函数
char_length(str):返回str所包含的字符数,一个多字节字符算一个字符
length(str): 返回字符串的字节长度,如utf8中,一个汉字3字节,数字和字母算一个字节
concat(s1, s1, ...): 返回连接参数产生的字符串
concat_ws(x, s1, s2, ...): 使用连接符x连接其他参数产生的字符串
INSERT(str,pos,len,newstr):返回str,其起始于pos,长度为len的子串被newstr取代。
1. 若pos不在str范围内,则返回原字符串str
2. 若str中从pos开始的子串不足len,则将从pos开始的剩余字符用newstr取代
3. 计算pos时从1开始,若pos=3,则从第3个字符开始替换
lower(str)或者lcase(str):
upper(str)或者ucase(str):
left(s,n):返回字符串s最左边n个字符
right(s,n): 返回字符串最右边n个字符
lpad(s1, len, s2): 用s2在s1左边填充至长度为len, 若s1的长度大于len,则截断字符串s1至长度len返回
rpad(s1, len, s2):
ltrim(s):删除s左侧空格字符
rtrim(s):
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)或TRIM([remstr FROM] str):从str中删除remstr, remstr默认为空白字符
REPEAT(str,count):返回str重复count次得到的新字符串
REPLACE(str,from_str,to_str): 将str中的from_str全部替换成to_str
SPACE(N):返回长度为N的空白字符串
STRCMP(str1,str2):若str1和str2相同,返回0, 若str1小于str2, 返回-1, 否则返回1.
SUBSTRING(str,pos), SUBSTRING(str FROM pos), SUBSTRING(str,pos,len), SUBSTRING(str FROM pos FOR len),MID(str,pos,len): 获取特定位置,特定长度的子字符串
LOCATE(substr,str), LOCATE(substr,str,pos),INSTR(str,substr),POSITION(substr IN str): 返回字符串中特定子串的位置,注意这里INSTR与其他函数的参数位置是相反的
REVERSE(str)
ELT(N,str1,str2,str3,...):返回参数strN, 若N大于str参数个数,则返回NULL
FIELD(str,str1,str2,str3,...): 返回str在后面的str列表中第一次出现的位置,若找不到str或者str为NULL, 则返回0
FIND_IN_SET(str,strlist):strlist是由','分隔的字符串,若str不在strlist或者strlist为空字符串,则返回0;若任意一个参数为NULL则返回NULL
MAKE_SET(bits,str1,str2,...): 由bits的作为位图来选取strN参数,选中的参数用','连接后返回
2.3日期和时间函数
CURDATE(), CURRENT_DATE, CURRENT_DATE():用于获取当前日期,格式为'YYYY-MM-DD'; 若+0则返回YYYYMMDD UTC_DATE, UTC_DATE():返回当前世界标准时间 CURTIME([fsp]), CURRENT_TIME, CURRENT_TIME([fsp]): 用于获取当前时间, 格式为'HH:MM:SS' 若+0则返回 HHMMSS UTC_TIME, UTC_TIME([fsp]) CURRENT_TIMESTAMP, CURRENT_TIMESTAMP([fsp]), LOCALTIME, LOCALTIME([fsp]), SYSDATE([fsp]), NOW([fsp]): 用于获取当前的时间日期,格式为'YYYY-MM-DD HH:MM:SS',若+0则返回YYYYMMDDHHMMSS UTC_TIMESTAMP, UTC_TIMESTAMP([fsp]) UNIX_TIMESTAMP(), UNIX_TIMESTAMP(date):返回一个unix时间戳('1970-01-01 00:00:00' UTC至今或者date的秒数),这实际上是从字符串到整数的一个转化过程 FROM_UNIXTIME(unix_timestamp), FROM_UNIXTIME(unix_timestamp,format):从时间戳返回'YYYY-MM-DD HH:MM:SS' 或者YYYYMMDDHHMMSS,加入format后根据所需的format显示。 MONTH(date) MONTHNAME(date) DAYNAME(date) DAY(date),DAYOFMONTH(date):1-31或者0 DAYOFWEEK(date):1-7==>星期天-星期六 DAYOFYEAR(date): 1-365(366) WEEK(date[,mode]):判断是一年的第几周,如果1-1所在周在新的一年多于4天,则将其定为第一周;否则将其定为上一年的最后一周。mode是用来人为定义一周从星期几开始。 WEEKOFYEAR(date):类似week(date,3),从周一开始计算一周。 QUARTER(date):返回1-4 HOUR(time):返回时间中的小时数,可以大于24 MINUTE(time): SECOND(time): EXTRACT(unit FROM date):提取日期时间中的要素 TIME_TO_SEC(time) SEC_TO_TIME(seconds) TO_DAYS(date): 从第0年开始的天数 TO_SECNDS(expr):从第0年开始的秒数 ADDDATE(date,INTERVAL expr unit), ADDDATE(expr,days),DATE_ADD(date,INTERVAL expr unit) DATE_SUB(date,INTERVAL expr unit), DATE_SUB(date,INTERVAL expr unit) ADDTIME(expr1,expr2) SUBTIME(expr1,expr2) DATE_FORMAT(date,format): DATEDIFF(expr1,expr2):返回相差的天数 TIMEDIFF(expr1,expr2):返回相隔的时间
注意:时间日期的加减也可以直接用+/-来进行
date + INTERVAL expr unit date - INTERVAL expr unit 如: SELECT '2008-12-31 23:59:59' + INTERVAL 1 SECOND;##'2009-01-01 00:00:00' SELECT INTERVAL 1 DAY + '2008-12-31';##'2009-01-01' SELECT '2005-01-01' - INTERVAL 1 SECOND;##'2004-12-31 23:59:59'
2.4条件判断函数
IF(expr1,expr2,expr3):如果expr1不为0或者NULL,则返回expr2的值,否则返回expr3的值 IFNULL(expr1,expr2):如果expr1不为NULL,返回expr1,否则返回expr2 NULLIF(expr1,expr2): 如果expr1=expr2则返回NULL, 否则返回expr2 CASE value WHEN [compare_value] THEN result [WHEN [compare_value] THEN result ...] [ELSE result] END 当compare_value=value时返回result CASE WHEN [condition] THEN result [WHEN [condition] THEN result ...] [ELSE result] END 当condition为TRUE时返回result SELECT CASE 1 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END;##'one' SELECT CASE WHEN 1>0 THEN 'true' ELSE 'false' END;##'true' SELECT CASE BINARY 'B' WHEN 'a' THEN 1 WHEN 'b' THEN 2 END;##NULL
2.5系统信息函数
VERSION():返回mysql服务器的版本,是utf8编码的字符串 CONNECTION_ID():显示连接号(连接的线程号) DATABASE(),SCHEMA():显示当前使用的数据库 SESSION_USER(), SYSTEM_USER(), USER(), CURRENT_USER, CURRENT_USER():返回当前的用户名@主机,utf8编码字符串 CHARSET(str) COLLATION(str) LAST_INSERT_ID():自动返回最后一个insert或者update查询, 为auto_increment列设置的第一个发生的值
2.6加密和压缩函数
PASSWORD(str):这个函数的输出与变量old_password有关。old_password 在mysql5.6中默认为0。 不同取值的效果如下表

old_password=1时, password(str)的效果与old_password(str)相同,由于其不够安全已经弃用(5.6.5以后)。
old_password=2时,在生成哈希密码时会随机加盐。
MD5(str):计算MD5 128位校验和,返回32位16进制数构成的字符串,当str为NULL时返回NULL。可以用作哈希密码
SHA1(str), SHA(str):计算160位校验和,返回40位16进制数构成的字符串,当str为NULL时返回NULL。
SHA2(str, hash_length):计算SHA-2系列的哈希方法(SHA-224, SHA-256, SHA-384, and SHA-512). 第一个参数为待校验字符串,第二个参数为结果的位数(224, 256, 384, 512)
ENCRYPT(str[,salt]): 用unix crypt()来加密str. salt至少要有两位字符,否则会返回NULL。若未指定salt参数,则会随机添加salt。
ECODE(crypt_str,pass_str):解密crypt_str, pass_str用作密码
ENCODE(str,pass_str):用pass_str作为密码加密str
DES_ENCRYPT(str[,{key_num|key_str}]):用Triple-DES算法编码str, 这个函数只有在mysql配置成支持ssl时才可用。
DES_DECRYPT(crypt_str[,key_str])
AES_ENCRYPT(str,key_str[,init_vector])
AES_DECRYPT(crypt_str,key_str[,init_vector])
COMPRESS(string_to_compress):返回二进制码
UNCOMPRESS(string_to_uncompress)
2.7 聚合函数
若在没使用group by时使用聚合函数,相当于把所有的行都归于一组来进行处理。除非特殊说明,一般聚合函数会忽略掉NULL. AVG([DISTINCT] expr): 返回expr的平均值,distinct选项用于忽略重复值 COUNT([DISTINCT] expr):返回select中expr的非0值个数,返回值为bigint类型 group_concat:连接组内的非空值,若无非空值,则返回NULL
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
MAX([DISTINCT] expr)
MIN([DISTINCT] expr)
SUM([DISTINCT] expr)
VAR_POP(expr)
VARIANCE(expr):同VAR_POP(expr),但是这是标准sql的一个扩展函数
VAR_SAMP(expr)
STD(expr): 这是标准sql的一个扩展函数
STDDEV(expr):这个函数是为了跟oracle兼容而设置的
STDDEV_POP(expr):这个是sql标准函数
STDDEV_SAMP(expr):样本标准差
2.8格式或类型转化函数
FORMAT(X,D[,locale]):将数字X转化成'#,###,###.##'格式,D为保留的小数位数 CONV(N,from_base,to_base):改变数字N的进制,返回值为该进制下的数字构成的字符串 INET_ATON(expr):ip字符串转数字 INET_NTOA(expr):数字转ip字符串 CAST(expr AS type):转换数据类型 CONVERT(expr,type), CONVERT(expr USING transcoding_name): type可以为BINARY[(N)],CHAR[(N)],DATE,DATETIME, DECIMAL[(M[,D])],DECIMAL[(M[,D])],TIME,UNSIGNED [INTEGER]等等。transcoding_name如utf8等等 3.存储过程
存储过程是存储在数据库目录中的一段声明性SQL语句。
自身的存储过程称为递归存储过程。大多数数据库管理系统支持递归存储过程。 但是,MySQL不支持它。
MySQL是最受欢迎的开源RDBMS,被社区和企业广泛使用。 然而,在它发布的第一个十年期间,它不支持存储过程,
MySQL存储过程的优点
通常存储过程有助于提高应用程序的性能。当创建,存储过程被编译之后,就存储在数据库中。 但是,MySQL实现的存储过程略有不同。 MySQL存储过程按需编译。 在编译存储过程之后,MySQL将其放入缓存中。 MySQL为每个连接维护自己的存储过程高速缓存。 如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询。
存储过程有助于减少应用程序和数据库服务器之间的流量,因为应用程序不必发送多个冗长的SQL语句,而只能发送存储过程的名称和参数。
存储的程序对任何应用程序都是可重用的和透明的。 存储过程将数据库接口暴露给所有应用程序,以便开发人员不必开发存储过程中已支持的功能。
存储的程序是安全的。 数据库管理员可以向访问数据库中存储过程的应用程序授予适当的权限,而不向基础数据库表提供任何权限。
除了这些优点之外,存储过程有其自身的缺点,在数据库中使用它们之前,您应该注意这些缺点。
MySQL存储过程的缺点
如果使用大量存储过程,那么使用这些存储过程的每个连接的内存使用量将会大大增加。 此外,如果您在存储过程中过度使用大量逻辑操作,则CPU使用率也会增加,因为数据库服务器的设计不当于逻辑运算。
存储过程的构造使得开发具有复杂业务逻辑的存储过程变得更加困难。
很难调试存储过程。只有少数数据库管理系统允许您调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。
开发和维护存储过程并不容易。开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能会导致应用程序开发和维护阶段的问题。
MySQL存储过程有自己的优点和缺点。开发应用程序时,您应该决定是否应该或不应该根据业务需求使用存储过程。
函数
MySQL聚合函数
MySQL字符串函数
MySQL控制流函数
MySQL日期和时间函数
MySQL比较函数
其他MySQL函数
触发器
SQL触发器是存储在数据库目录中的一组SQL语句。每当与表相关联的事件发生时,即会执行或触发SQL触发器,例如插入,更新或删除。
SQL触发器是一种特殊类型的
了解SQL触发器的优缺点非常重要,以便您可以适当地使用它。在以下部分中,我们将讨论使用SQL触发器的优缺点。
SQL触发器的优点
-
SQL触发器提供了检查数据完整性的替代方法。
-
SQL触发器可以捕获数据库层中业务逻辑中的错误。
-
SQL触发器提供了
-
SQL触发器对于审核表中数据的更改非常有用。
SQL触发器的缺点
-
SQL触发器只能提供扩展验证,并且无法替换所有验证。一些简单的验证必须在应用层完成。 例如,您可以使用JavaScript或服务器端使用服务器端脚本语言(如
-
从客户端应用程序调用和执行SQL触发器不可见,因此很难弄清数据库层中发生的情况。
-
SQL触发器可能会增加数据库服务器的开销。
MySQL触发器简介
在MySQL中,触发器是一组SQL语句,当对相关联的表上的数据进行更改时,会自动调用该语句。 触发器可以被定义为在
-
BEFORE INSERT- 在数据插入表之前被激活触发器。 -
AFTER INSERT- 在将数据插入表之后激活触发器。 -
BEFORE UPDATE- 在表中的数据更新之前激活触发器。 -
AFTER UPDATE- 在表中的数据更新之后激活触发器。 -
BEFORE DELETE- 在从表中删除数据之前激活触发器。 -
AFTER DELETE- 从表中删除数据之后激活触发器。
但是,从MySQL 5.7.2+版本开始,可以
当使用不使用INSERT,DELETE或UPDATE语句更改表中数据的语句时,不会调用与表关联的触发器。 例如,
有些语句使用了后台的INSERT语句,如
必须要为与表相关联的每个触发器使用唯一的名称。可以为不同的表定义相同的触发器名称,这是一个很好的做法。
应该使用以下命名约定命名触发器:
(BEFORE | AFTER)_tableName_(INSERT| UPDATE | DELETE)
SQL
例如,before_order_update是更新orders表中的行数据之前调用的触发器。
以下命名约定与上述一样。
tablename_(BEFORE | AFTER)_(INSERT| UPDATE | DELETE)
SQL
例如,order_before_update与上述before_order_update触发器相同。
MySQL触发存储
MySQL在数据目录中存储触发器,例如:/data/yiibaidb/,并使用名为tablename.TRG和triggername.TRN的文件:
-
tablename.TRG文件将触发器映射到相应的表。 -
triggername.TRN文件包含触发器定义。
可以通过将触发器文件复制到备份文件夹来备份MySQL触发器。也可以
MySQL触发限制
MySQL触发器覆盖标准SQL中定义的所有功能。 但是,在应用程序中使用它们之前,您应该知道一些限制。
MySQL触发器不能:
-
使用在
SHOW,LOAD DATA,LOAD TABLE, -
使用隐式或明确提交或回滚的语句,如
COMMIT,ROLLBACK,START TRANSACTION, -
使用
-
使用动态SQL语句。
MySQL触发语法
为了创建一个新的触发器,可以使用CREATE TRIGGER语句。 下面说明了CREATE TRIGGER语句的语法:
CREATE TRIGGER trigger_name trigger_time trigger_event
ON table_name
FOR EACH ROW
BEGIN
...
END;
SQL
-
将触发器名称放在
CREATE TRIGGER语句之后。触发器名称应遵循命名约定[trigger time]_[table name]_[trigger event],例如before_employees_update。 -
触发激活时间可以在之前或之后。必须指定定义触发器的激活时间。如果要在更改之前处理操作,则使用
BEFORE关键字,如果在更改后需要处理操作,则使用AFTER关键字。 -
触发事件可以是
INSERT,UPDATE或DELETE。此事件导致触发器被调用。 触发器只能由一个事件调用。要定义由多个事件调用的触发器,必须定义多个触发器,每个事件一个触发器。 -
触发器必须与特定表关联。没有表触发器将不存在,所以必须在
ON关键字之后指定表名。 -
将SQL语句放在
BEGIN和END块之间。这是定义触发器逻辑的位置。
MySQL触发器示例
下面我们将在MySQL中创建触发器来记录employees表中行数据的更改情况。
mysql> DESC employees;
+----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+-------+
| employeeNumber | int(11) | NO | PRI | NULL | |
| lastName | varchar(50) | NO | | NULL | |
| firstName | varchar(50) | NO | | NULL | |
| extension | varchar(10) | NO | | NULL | |
| email | varchar(100) | NO | | NULL | |
| officeCode | varchar(10) | NO | MUL | NULL | |
| reportsTo | int(11) | YES | MUL | NULL | |
| jobTitle | varchar(50) | NO | | NULL | |
+----------------+--------------+------+-----+---------+-------+
8 rows in set
SQL
首先,创建一个名为employees audit的新表,用来保存employees表中数据的更改。 以下语句创建employee_audit表。
USE yiibaidb;
CREATE TABLE employees_audit (
id INT AUTO_INCREMENT PRIMARY KEY,
employeeNumber INT NOT NULL,
lastname VARCHAR(50) NOT NULL,
changedat DATETIME DEFAULT NULL,
action VARCHAR(50) DEFAULT NULL
);
SQL
接下来,创建一个BEFORE UPDATE触发器,该触发器在对employees表中的行记录更改之前被调用。
DELIMITER $$
CREATE TRIGGER before_employee_update
BEFORE UPDATE ON employees
FOR EACH ROW
BEGIN
INSERT INTO employees_audit
SET action = 'update',
employeeNumber = OLD.employeeNumber,
lastname = OLD.lastname,
changedat = NOW();
END$$
DELIMITER ;
SQL
在触发器的主体中,使用OLD关键字来访问受触发器影响的行的employeeNumber和lastname列。
请注意,在为
然后,要查看当前数据库中的所有触发器,请使用SHOW TRIGGERS语句,如下所示:
SHOW TRIGGERS;
SQL
执行上面查询语句,得到以下结果 -
mysql> SHOW TRIGGERS;
+------------------------+--------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+------------------------+-----------------------------------------------------------------------------------+----------------+----------------------+----------------------+--------------------+
| Trigger | Event | Table | Statement | Timing | Created | sql_mode | Definer | character_set_client | collation_connection | Database Collation |
+------------------------+--------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+------------------------+-----------------------------------------------------------------------------------+----------------+----------------------+----------------------+--------------------+
| before_employee_update | UPDATE | employees | BEGIN
INSERT INTO employees_audit
SET action = 'update',
employeeNumber = OLD.employeeNumber,
lastname = OLD.lastname,
changedat = NOW();
END | BEFORE | 2017-08-02 22:06:36.40 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@localhost | utf8 | utf8_general_ci | utf8_general_ci |
+------------------------+--------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+------------------------+-----------------------------------------------------------------------------------+----------------+----------------------+----------------------+--------------------+
1 row in set
SQL
之后,更新employees表以检查触发器是否被调用。
UPDATE employees
SET
lastName = 'Maxsu'
WHERE
employeeNumber = 1056;
SQL
最后,要检查触发器是否被UPDATE语句调用,可以使用以下查询来查询employees_audit表:
SELECT * FROM employees_audit;
SQL
以下是查询的输出:
mysql> SELECT * FROM employees_audit;
+----+----------------+----------+---------------------+--------+
| id | employeeNumber | lastname | changedat | action |
+----+----------------+----------+---------------------+--------+
| 1 | 1056 | Hill | 2017-08-02 22:15:51 | update |
+----+----------------+----------+---------------------+--------+
1 row in set
MySQL将按照创建的顺序调用触发器。要更改触发器的顺序,需要在FOR EACH ROW子句之后指定FOLLOWS或PRECEDES。如下说明 -
-
FOLLOWS选项允许新触发器在现有触发器之后激活。 -
PRECEDES选项允许新触发器在现有触发器之前激活。
以下是使用显式顺序创建新的附加触发器的语法:
DELIMITER $$
CREATE TRIGGER trigger_name
[BEFORE|AFTER] [INSERT|UPDATE|DELETE] ON table_name
FOR EACH ROW [FOLLOWS|PRECEDES] existing_trigger_name
BEGIN
…
END$$
DELIMITER ;
SQL
MySQL多重触发器示例
我们来看如何一个在表中的同一个事件和动作上,创建多个触发器的例子。
下面将使用
首先,使用
USE yiibaidb;
CREATE TABLE price_logs (
id INT(11) NOT NULL AUTO_INCREMENT,
product_code VARCHAR(15) NOT NULL,
price DOUBLE NOT NULL,
updated_at TIMESTAMP NOT NULL DEFAULT
CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
KEY product_code (product_code),
CONSTRAINT price_logs_ibfk_1 FOREIGN KEY (product_code)
REFERENCES products (productCode)
ON DELETE CASCADE
ON UPDATE CASCADE
);
SQL
其次,当表的BEFORE UPDATE事件发生时,创建一个新的触发器。触发器名称为before_products_update,具体实现如下所示:
DELIMITER $$
CREATE TRIGGER before_products_update
BEFORE UPDATE ON products
FOR EACH ROW
BEGIN
INSERT INTO price_logs(product_code,price)
VALUES(old.productCode,old.msrp);
END$$
DELIMITER ;
SQL
第三,我们更改产品的价格,并使用以下
UPDATE products SET msrp = 95.1 WHERE productCode = 'S10_1678'; -- 查询结果价格记录 SELECT * FROM price_logs; SQL
上面查询语句执行后,得到以下结果 -
+----+--------------+-------+---------------------+
| id | product_code | price | updated_at |
+----+--------------+-------+---------------------+
| 1 | S10_1678 | 95.7 | 2017-08-03 02:46:42 |
+----+--------------+-------+---------------------+
1 row in set
SQL
可以看到结果中,它按我们预期那样工作了。
假设不仅要看到旧的价格,改变的时候,还要记录是谁修改了它。 我们可以向price_logs表添加其他列。 但是,为了实现多个触发器的演示,我们将创建一个新表来存储进行更改的用户的数据。这个新表的名称为user_change_logs,结构如下:
USE yiibaidb; CREATE TABLE user_change_logs ( id int(11) NOT NULL AUTO_INCREMENT, product_code varchar(15) DEFAULT NULL, updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, updated_by varchar(30) NOT NULL, PRIMARY KEY (id), KEY product_code (product_code), CONSTRAINT user_change_logs_ibfk_1 FOREIGN KEY (product_code) REFERENCES products (productCode) ON DELETE CASCADE ON UPDATE CASCADE ); SQL
现在,我们创建一个在products表上的BEFORE UPDATE事件上激活的第二个触发器。 此触发器将更改的用户信息更新到user_change_logs表。 它在before_products_update触发后被激活。
DELIMITER $$
CREATE TRIGGER before_products_update_2
BEFORE UPDATE ON products
FOR EACH ROW FOLLOWS before_products_update
BEGIN
INSERT INTO user_change_logs(product_code,updated_by)
VALUES(old.productCode,user());
END$$
DELIMITER ;
SQL
下面我们来做一个快速测试。
首先,使用
UPDATE products SET msrp = 95.3 WHERE productCode = 'S10_1678'; SQL
其次,分别从price_logs和user_change_logs表查询数据:
SELECT * FROM price_logs; SQL
上面查询语句执行后,得到以下结果 -
mysql> SELECT * FROM price_logs;
+----+--------------+-------+---------------------+
| id | product_code | price | updated_at |
+----+--------------+-------+---------------------+
| 1 | S10_1678 | 95.7 | 2017-08-03 02:46:42 |
| 2 | S10_1678 | 95.1 | 2017-08-03 02:47:21 |
+----+--------------+-------+---------------------+
2 rows in set
SQL
SELECT * FROM user_change_logs;
SQL
上面查询语句执行后,得到以下结果 -
mysql> SELECT * FROM user_change_logs;
+----+--------------+---------------------+----------------+
| id | product_code | updated_at | updated_by |
+----+--------------+---------------------+----------------+
| 1 | S10_1678 | 2017-08-03 02:47:21 | root@localhost |
+----+--------------+---------------------+----------------+
1 row in set
SQL
如上所见,两个触发器按照预期的顺序激活执行相关操作了。
触发器顺序
如果使用SHOW TRIGGERS语句,则不会在表中看到触发激活同一事件和操作的顺序。
SHOW TRIGGERS FROM yiibaidb;
SQL
要查找此信息,需要如下查询information_schema数据库的triggers表中的action_order列,如下查询语句 -
SELECT
trigger_name, action_order
FROM
information_schema.triggers
WHERE
trigger_schema = 'yiibaidb'
ORDER BY event_object_table ,
action_timing ,
event_manipulation;
SQL
上面查询语句执行后,得到以下结果 -
mysql> SELECT
trigger_name, action_order
FROM
information_schema.triggers
WHERE
trigger_schema = 'yiibaidb'
ORDER BY event_object_table ,
action_timing ,
event_manipulation;
+--------------------------+--------------+
| trigger_name | action_order |
+--------------------------+--------------+
| before_employee_update | 1 |
| before_products_update | 1 |
| before_products_update_2 | 2 |
+--------------------------+--------------+
3 rows in set
触发器作为纯文本文件存储在以下数据库文件夹中:
/data_folder/database_name/table_name.trg
SQL
也可通过查询information_schema数据库中的triggers表来显示触发器,如下所示:
SELECT
*
FROM
information_schema.triggers
WHERE
trigger_schema = 'database_name'
AND trigger_name = 'trigger_name';
SQL
该语句允许您查看触发器的内容及其元数据,例如:关联表名和定义器,这是创建触发器的
如果要检索指定数据库中的所有触发器,则需要使用以下
SELECT
*
FROM
information_schema.triggers
WHERE
trigger_schema = 'database_name';
SQL
要查找与特定表相关联的所有触发器,请使用以下查询:
SELECT
*
FROM
information_schema.triggers
WHERE
trigger_schema = 'database_name'
AND event_object_table = 'table_name';
SQL
例如,以下查询语句与yiibaidb数据库中的employees表相关联的所有触发器。
SELECT * FROM information_schema.triggers
WHERE trigger_schema = 'yiibaidb'
AND event_object_table = 'employees';
SQL
执行上面查询,得到以下结果 -
mysql> SELECT * FROM information_schema.triggers
WHERE trigger_schema = 'yiibaidb'
AND event_object_table = 'employees';
+-----------------+----------------+------------------------+--------------------+----------------------+---------------------+--------------------+--------------+------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+---------------+----------------------------+----------------------------+--------------------------+--------------------------+------------------------+-----------------------------------------------------------------------------------+----------------+----------------------+----------------------+--------------------+
| TRIGGER_CATALOG | TRIGGER_SCHEMA | TRIGGER_NAME | EVENT_MANIPULATION | EVENT_OBJECT_CATALOG | EVENT_OBJECT_SCHEMA | EVENT_OBJECT_TABLE | ACTION_ORDER | ACTION_CONDITION | ACTION_STATEMENT | ACTION_ORIENTATION | ACTION_TIMING | ACTION_REFERENCE_OLD_TABLE | ACTION_REFERENCE_NEW_TABLE | ACTION_REFERENCE_OLD_ROW | ACTION_REFERENCE_NEW_ROW | CREATED | SQL_MODE | DEFINER | CHARACTER_SET_CLIENT | COLLATION_CONNECTION | DATABASE_COLLATION |
+-----------------+----------------+------------------------+--------------------+----------------------+---------------------+--------------------+--------------+------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+---------------+----------------------------+----------------------------+--------------------------+--------------------------+------------------------+-----------------------------------------------------------------------------------+----------------+----------------------+----------------------+--------------------+
| def | yiibaidb | before_employee_update | UPDATE | def | yiibaidb | employees | 1 | NULL | BEGIN
INSERT INTO employees_audit
SET action = 'update',
employeeNumber = OLD.employeeNumber,
lastname = OLD.lastname,
changedat = NOW();
END | ROW | BEFORE | NULL | NULL | OLD | NEW | 2017-08-02 22:06:36.40 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | root@localhost | utf8 | utf8_general_ci | utf8_general_ci |
+-----------------+----------------+------------------------+--------------------+----------------------+---------------------+--------------------+--------------+------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+---------------+----------------------------+----------------------------+--------------------------+--------------------------+------------------------+-----------------------------------------------------------------------------------+----------------+----------------------+----------------------+--------------------+
1 row in set
SQL
MySQL SHOW TRIGGERS语句
在特定数据库中显示触发器的另一种方法是使用SHOW TRIGGERS语句,如下所示:
SHOW TRIGGERS [FROM|IN] database_name
[LIKE expr | WHERE expr];
SQL
例如,如果要查看当前数据库中的所有触发器,可以使用SHOW TRIGGERS语句,如下所示:
SHOW TRIGGERS;
SQL
要获取特定数据库中的所有触发器,请在SHOW TRIGGERS语句中指定数据库名称,比如要查询数据库:yiibaidb下的所有触发器,如下所示:
SHOW TRIGGERS FROM yiibaidb;
SQL
上面语句返回yiibaidb数据库中的所有触发器。
要获取与特定表相关联的所有触发器,可以使用SHOW TRIGGERS语句中的WHERE子句。 以下语句返回与employees表相关联的所有触发器:
SHOW TRIGGERS FROM yiibaidb
WHERE `table` = 'employees';
SQL
请注意,我们使用反引号包装table列,因为table是MySQL中的保留关键字。
当执行SHOW TRIGGERS语句时,MySQL返回以下列 -
-
Trigger:存储触发器的名称,例如before_employee_update触发器。 -
Event:指定事件,例如,调用触发器的INSERT,UPDATE或DELETE。 -
Table:指定触发器与例如相关联的表,如employees表。 -
Statement:存储调用触发器时要执行的语句或复合语句。 -
Timing:接受两个值:BEFORE和AFTER,它指定触发器的激活时间。 -
Created:在创建触发器时记录创建的时间。 -
sql_mode:指定触发器执行时的SQL模式。 -
Definer:记录创建触发器的帐户。
请注意,要执行
SHOW TRIGGERS语句,您必须具有SUPER权限。
删除触发器
要删除现有的触发器,请使用DROP TRIGGER语句,如下所示:
DROP TRIGGER table_name.trigger_name;
SQL
例如,如果要删除与employees表相关联的before_employees_update触发器,则可以执行以下语句:
DROP TRIGGER employees.before_employees_update;
SQL
要修改触发器,必须首先删除它并使用新的代码重新创建。在MySQL中没有类似:ALTER TRIGGER语句,因此,您不能像修改其他数据库对象,如
事件
MySQL事件调度器配置
MySQL使用一个名为事件调度线程的特殊线程来执行所有调度的事件。可以通过执行以下命令来查看事件调度程序线程的状态:
SHOW PROCESSLIST;
SQL
执行上面查询语句,得到以下结果 -
mysql> SHOW PROCESSLIST; +----+------+-----------------+----------+---------+------+----------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+-----------------+----------+---------+------+----------+------------------+ | 2 | root | localhost:50405 | NULL | Sleep | 1966 | | NULL | | 3 | root | localhost:50406 | yiibaidb | Sleep | 1964 | | NULL | | 4 | root | localhost:50407 | yiibaidb | Query | 0 | starting | SHOW PROCESSLIST | +----+------+-----------------+----------+---------+------+----------+------------------+ 3 rows in set Shell
默认情况下,事件调度程序线程未启用。 要启用和启动事件调度程序线程,需要执行以下命令:
SET GLOBAL event_scheduler = ON;
SQL
现在看到事件调度器线程的状态,再次执行SHOW PROCESSLIST命令,结果如下所示 -
mysql> SHOW PROCESSLIST; +----+-----------------+-----------------+----------+---------+------+------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-----------------+-----------------+----------+---------+------+------------------------+------------------+ | 2 | root | localhost:50405 | NULL | Sleep | 1986 | | NULL | | 3 | root | localhost:50406 | yiibaidb | Sleep | 1984 | | NULL | | 4 | root | localhost:50407 | yiibaidb | Query | 0 | starting | SHOW PROCESSLIST | | 5 | event_scheduler | localhost | NULL | Daemon | 6 | Waiting on empty queue | NULL | +----+-----------------+-----------------+----------+---------+------+------------------------+------------------+ 4 rows in set SQL
要禁用并停止事件调度程序线程,可通过执行SET GLOBAL命令将event_scheduler其值设置为OFF:
SET GLOBAL event_scheduler = OFF;
SQL
创建新的MySQL事件
创建事件与创建其他数据库对象(如存储过程或触发器)类似。事件是一个包含SQL语句的命名对象。
要创建和计划新事件,请使用CREATE EVENT语句,如下所示:
CREATE EVENT [IF NOT EXIST] event_name
ON SCHEDULE schedule
DO
event_body
SQL
下面让我们更详细地解释语法中的一些参数 -
-
首先,在
CREATE EVENT子句之后指定事件名称。事件名称在数据库模式中必须是唯一的。 -
其次,在
ON SCHEDULE子句后面加上一个表。如果事件是一次性事件,则使用语法:AT timestamp [+ INTERVAL],如果事件是循环事件,则使用EVERY子句:EVERY interval STARTS timestamp [+INTERVAL] ENDS timestamp [+INTERVAL] -
第三,将
DO语句放在DO关键字之后。请注意,可以在事件主体内调用存储过程。 如果您有复合SQL语句,可以将它们放在BEGIN END块中。
我们来看几个创建事件的例子来了解上面的语法。
首先,创建并计划将一个消息插入到messages表中的一次性事件,请执行以下步骤:
USE testdb;
CREATE TABLE IF NOT EXISTS messages (
id INT PRIMARY KEY AUTO_INCREMENT,
message VARCHAR(255) NOT NULL,
created_at DATETIME NOT NULL
);
SQL
其次,使用CREATE EVENT语句创建一个事件:
CREATE EVENT IF NOT EXISTS test_event_01
ON SCHEDULE AT CURRENT_TIMESTAMP
DO
INSERT INTO messages(message,created_at)
VALUES('Test MySQL Event 1',NOW());
SQL
第三,检查messages表; 会看到有1条记录。这意味着事件在创建时被执行。
SELECT * FROM messages;
SQL
执行上面查询语句,得到以下结果 -
mysql> SELECT * FROM messages; +----+--------------------+---------------------+ | id | message | created_at | +----+--------------------+---------------------+ | 1 | Test MySQL Event 1 | 2017-08-03 04:23:11 | +----+--------------------+---------------------+ 1 row in set Shell
要显示数据库(testdb)的所有事件,请使用以下语句:
SHOW EVENTS FROM testdb;
SQL
执行上面查询看不到任何行返回,因为事件在到期时自动删除。 在我们的示例中,它是一次性的事件,在执行完成时就过期了。
要更改此行为,可以使用ON COMPLETION PRESERVE子句。以下语句创建另一个一次性事件,在其创建时间1分钟后执行,执行后不会被删除。
CREATE EVENT test_event_02
ON SCHEDULE AT CURRENT_TIMESTAMP + INTERVAL 1 MINUTE
ON COMPLETION PRESERVE
DO
INSERT INTO messages(message,created_at)
VALUES('Test MySQL Event 2',NOW());
SQL
等待1分钟后,查看messages表,添加了另一条记录:
SELECT * FROM messages;
SQL
执行上面查询语句,得到以下结果 -
mysql> SELECT * FROM messages; +----+--------------------+---------------------+ | id | message | created_at | +----+--------------------+---------------------+ | 1 | Test MySQL Event 1 | 2017-08-03 04:23:11 | | 2 | Test MySQL Event 2 | 2017-08-03 04:24:48 | +----+--------------------+---------------------+ 2 rows in set Shell
如果再次执行SHOW EVENTS语句,看到事件是由于ON COMPLETION PRESERVE子句的影响:
SHOW EVENTS FROM testdb;
SQL
执行上面查询语句,得到以下结果 -
mysql> SHOW EVENTS FROM testdb; +--------+---------------+----------------+-----------+----------+---------------------+----------------+----------------+--------+------+----------+------------+----------------------+----------------------+--------------------+ | Db | Name | Definer | Time zone | Type | Execute at | Interval value | Interval field | Starts | Ends | Status | Originator | character_set_client | collation_connection | Database Collation | +--------+---------------+----------------+-----------+----------+---------------------+----------------+----------------+--------+------+----------+------------+----------------------+----------------------+--------------------+ | testdb | test_event_02 | root@localhost | SYSTEM | ONE TIME | 2017-08-03 04:24:48 | NULL | NULL | NULL | NULL | DISABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci | +--------+---------------+----------------+-----------+----------+---------------------+----------------+----------------+--------+------+----------+------------+----------------------+----------------------+--------------------+ 1 row in set Shell
以下语句创建一个循环的事件,每分钟执行一次,并在其创建时间的1小时内过期:
CREATE EVENT test_event_03
ON SCHEDULE EVERY 1 MINUTE
STARTS CURRENT_TIMESTAMP
ENDS CURRENT_TIMESTAMP + INTERVAL 1 HOUR
DO
INSERT INTO messages(message,created_at)
VALUES('Test MySQL recurring Event',NOW());
SQL
请注意,使用STARTS和ENDS子句定义事件的有效期。等待个3,5分钟后再查看messages表数据,以测试验证此循环事件的执行。
SELECT * FROM messages;
SQL
执行上面查询语句,得到以下结果 -
mysql> SELECT * FROM messages; +----+----------------------------+---------------------+ | id | message | created_at | +----+----------------------------+---------------------+ | 1 | Test MySQL Event 1 | 2017-08-03 04:23:11 | | 2 | Test MySQL Event 2 | 2017-08-03 04:24:48 | | 3 | Test MySQL recurring Event | 2017-08-03 04:25:20 | | 4 | Test MySQL recurring Event | 2017-08-03 04:26:20 | | 5 | Test MySQL recurring Event | 2017-08-03 04:27:20 | +----+----------------------------+---------------------+ 5 rows in set Shell
删除MySQL事件
要删除现有事件,请使用DROP EVENT语句,如下所示:
DROP EVENT [IF EXISTS] event_name;
SQL
例如,要删除test_event_03的事件,请使用以下语句:
DROP EVENT IF EXISTS test_event_03;
MySQL允许您更改现有事件的各种属性。要更改现有事件,请使用ALTER EVENT语句,如下所示:
ALTER EVENT event_name
ON SCHEDULE schedule
ON COMPLETION [NOT] PRESERVE
RENAME TO new_event_name
ENABLE | DISABLE
DO
event_body
SQL
请注意,ALTER EVENT语句仅适用于存在的事件。如果您尝试修改不存在的事件,MySQL将会发出一条错误消息,因此在更改事件之前,应先使用SHOW EVENTS语句检查事件的存在。
SHOW EVENTS FROM testdb;
SQL
执行上面查询,得到以下结果 -
mysql> SHOW EVENTS FROM testdb;
+--------+---------------+----------------+-----------+----------+---------------------+----------------+----------------+--------+------+----------+------------+----------------------+----------------------+--------------------+
| Db | Name | Definer | Time zone | Type | Execute at | Interval value | Interval field | Starts | Ends | Status | Originator | character_set_client | collation_connection | Database Collation |
+--------+---------------+----------------+-----------+----------+---------------------+----------------+----------------+--------+------+----------+------------+----------------------+----------------------+--------------------+
| testdb | test_event_02 | root@localhost | SYSTEM | ONE TIME | 2017-08-03 04:24:48 | NULL | NULL | NULL | NULL | DISABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
+--------+---------------+----------------+-----------+----------+---------------------+----------------+----------------+--------+------+----------+------------+----------------------+----------------------+--------------------+
1 row in set
Shell
ALTER EVENT示例
我们创建一个示例事件来演示如何使用ALTER EVENT语句的各种功能。
以下语句创建一个事件,每分钟将一条新记录插入到messages表中。
USE testdb;
CREATE EVENT test_event_04
ON SCHEDULE EVERY 1 MINUTE
DO
INSERT INTO messages(message,created_at)
VALUES('Test ALTER EVENT statement',NOW());
SQL
改变调度时间
要修改事件为每2分钟运行一次,请使用以下语句:
ALTER EVENT test_event_04
ON SCHEDULE EVERY 2 MINUTE;
SQL
改变事件的主体代码逻辑
您还可以通过指定新的逻辑来更改事件的主体代码,如下所示:
ALTER EVENT test_event_04
DO
INSERT INTO messages(message,created_at)
VALUES('Message from event',NOW());
-- 清空表中的数据
truncate messages;
SQL
上面修改完成后,可以等待2分钟,再次查看messages表:
SELECT * FROM messages;
SQL
执行上面查询,得到以下结果 -
mysql> SELECT * FROM messages;
+----+--------------------+---------------------+
| id | message | created_at |
+----+--------------------+---------------------+
| 1 | Message from event | 2017-08-03 04:46:47 |
| 2 | Message from event | 2017-08-03 04:48:47 |
+----+--------------------+---------------------+
2 rows in set
Shell
禁用事件
要禁用某个事件,请在ALTER EVENT语句之后使用DISABLE关键字,请使用以下语句:
ALTER EVENT test_event_04
DISABLE;
SQL
也可以通过使用SHOW EVENTS语句来查看事件的状态,如下所示:
SHOW EVENTS FROM testdb;
SQL
执行上面查询,得到以下结果 -
mysql> SHOW EVENTS FROM testdb;
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
| Db | Name | Definer | Time zone | Type | Execute at | Interval value | Interval field | Starts | Ends | Status | Originator | character_set_client | collation_connection | Database Collation |
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
| testdb | test_event_02 | root@localhost | SYSTEM | ONE TIME | 2017-08-03 04:24:48 | NULL | NULL | NULL | NULL | DISABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
| testdb | test_event_04 | root@localhost | SYSTEM | RECURRING | NULL | 2 | MINUTE | 2017-08-03 04:44:47 | NULL | DISABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
2 rows in set
Shell
启用事件
要启用已禁用的事件,请在ALTER EVENT语句之后使用ENABLE关键字,如下所示:
ALTER EVENT test_event_04
ENABLE;
SQL
查询上面语句执行结果,得到以下结果 -
mysql> SHOW EVENTS FROM testdb;
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
| Db | Name | Definer | Time zone | Type | Execute at | Interval value | Interval field | Starts | Ends | Status | Originator | character_set_client | collation_connection | Database Collation |
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
| testdb | test_event_02 | root@localhost | SYSTEM | ONE TIME | 2017-08-03 04:24:48 | NULL | NULL | NULL | NULL | DISABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
| testdb | test_event_04 | root@localhost | SYSTEM | RECURRING | NULL | 2 | MINUTE | 2017-08-03 04:44:47 | NULL | ENABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
2 rows in set
Shell
重命名事件
MySQL不提供类似RENAME EVENT语句。幸运的是,我们可以使用ALTER EVENT重命名现有事件,如下所示:
ALTER EVENT test_event_04
RENAME TO test_event_05;
SQL
查询上面语句执行结果,得到以下结果 -
mysql> SHOW EVENTS FROM testdb;
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
| Db | Name | Definer | Time zone | Type | Execute at | Interval value | Interval field | Starts | Ends | Status | Originator | character_set_client | collation_connection | Database Collation |
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
| testdb | test_event_02 | root@localhost | SYSTEM | ONE TIME | 2017-08-03 04:24:48 | NULL | NULL | NULL | NULL | DISABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
| testdb | test_event_05 | root@localhost | SYSTEM | RECURRING | NULL | 2 | MINUTE | 2017-08-03 04:44:47 | NULL | ENABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
+--------+---------------+----------------+-----------+-----------+---------------------+----------------+----------------+---------------------+------+----------+------------+----------------------+----------------------+--------------------+
2 rows in set
Shell
将事件移动到其他数据库
可以通过使用RENAME TO子句将事件从一个数据库移动到另一个数据库中,如下所示:
ALTER EVENT testdb.test_event_05
RENAME TO newdb.test_event_05;
SQL
查询上面语句执行结果,得到以下结果 -
mysql> SHOW EVENTS FROM newdb;
+-------+---------------+----------------+-----------+-----------+------------+----------------+----------------+---------------------+------+---------+------------+----------------------+----------------------+--------------------+
| Db | Name | Definer | Time zone | Type | Execute at | Interval value | Interval field | Starts | Ends | Status | Originator | character_set_client | collation_connection | Database Collation |
+-------+---------------+----------------+-----------+-----------+------------+----------------+----------------+---------------------+------+---------+------------+----------------------+----------------------+--------------------+
| newdb | test_event_05 | root@localhost | SYSTEM | RECURRING | NULL | 2 | MINUTE | 2017-08-03 04:44:47 | NULL | ENABLED | 0 | utf8 | utf8_general_ci | utf8_general_ci |
+-------+---------------+----------------+-----------+-----------+------------+----------------+----------------+---------------------+------+---------+------------+----------------------+----------------------+--------------------+
1 row in set
SQL
假设newdb数据库在MySQL数据库服务器中可用。
在本教程中,我们向您展示了如何使用ALTER EVENT语句更改MySQL事件的各种属性。
视图
数据库视图是虚拟表或逻辑表,它被定义为具有
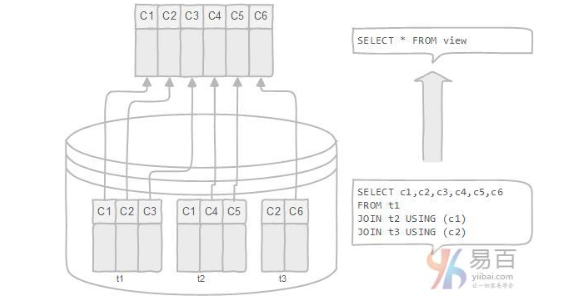
数据库视图是动态的,因为它与物理模式无关。数据库系统将数据库视图存储为具有连接的
数据库视图的优点
以下是使用数据库视图的优点 -
-
数据库视图允许简化复杂查询:数据库视图由与许多基础表相关联的SQL语句定义。 您可以使用数据库视图来隐藏最终用户和外部应用程序的基础表的复杂性。 通过数据库视图,您只需使用简单的SQL语句,而不是使用具有多个连接的复杂的SQL语句。
-
数据库视图有助于限制对特定用户的数据访问。 您可能不希望所有用户都可以查询敏感数据的子集。可以使用数据库视图将非敏感数据仅显示给特定用户组。
-
数据库视图提供额外的安全层。 安全是任何关系数据库管理系统的重要组成部分。 数据库视图为数据库管理系统提供了额外的安全性。 数据库视图允许您创建只读视图,以将只读数据公开给特定用户。 用户只能以只读视图检索数据,但无法更新。
-
数据库视图启用计算列。 数据库表不应该具有计算列,但数据库视图可以这样。 假设在
orderDetails表中有quantityOrder(产品的数量)和priceEach(产品的价格)列。 但是,orderDetails表没有一个列用来存储订单的每个订单项的总销售额。如果有,数据库模式不是一个好的设计。 在这种情况下,您可以创建一个名为total的计算列,该列是quantityOrder和priceEach的乘积,以表示计算结果。当您从数据库视图中查询数据时,计算列的数据将随机计算产生。 -
数据库视图实现向后兼容。 假设你有一个中央数据库,许多应用程序正在使用它。 有一天,您决定重新设计数据库以适应新的业务需求。删除一些表并创建新的表,并且不希望更改影响其他应用程序。在这种情况下,可以创建与将要删除的旧表相同的模式的数据库视图。
数据库视图的缺点
除了上面的优点,使用数据库视图有几个缺点:
-
性能:从数据库视图查询数据可能会很慢,特别是如果视图是基于其他视图创建的。
-
表依赖关系:将根据数据库的基础表创建一个视图。每当更改与其相关联的表的结构时,都必须更改视图。
在MySQL中,视图的几乎特征符合SQL:2003标准。 MySQL以两种方式处理对视图的查询:
-
第一种方式,MySQL会根据视图定义语句创建一个
-
第二种方式,MySQL将传入查询与查询定义为一个查询并执行组合查询。
MySQL支持版本系统的视图。每次
MySQL允许基于其他视图创建视图。在视图定义的
MySQL视图的限制
不能在视图上创建
在MySQL 5.7.7之前版本,是不能在SELECT语句的FROM子句中使用
如果删除或
一个简单的视图可以
MySQL不像:
CREATE VIEW语句简介
要在MySQL中创建一个新视图,可以使用CREATE VIEW语句。 在MySQL中创建视图的语法如下:
CREATE
[ALGORITHM = {MERGE | TEMPTABLE | UNDEFINED}]
VIEW [database_name].[view_name]
AS
[SELECT statement]
SQL
下面我们来详细的查看上面的语法。
查看处理算法
算法属性允许您控制MySQL在创建视图时使用的机制,MySQL提供了三种算法:MERGE,TEMPTABLE和UNDEFINED。
-
使用
MERGE算法,MySQL首先将输入查询与定义视图的 -
使用
TEMPTABLE算法,MySQL首先根据定义视图的SELECT语句 -
当您创建视图而不指定显式算法时,
UNDEFINED是默认算法。UNDEFINED算法使MySQL可以选择使用MERGE或TEMPTABLE算法。MySQL优先使用MERGE算法进行TEMPTABLE算法,因为MERGE算法效率更高。
查看名称
在数据库中,视图和表共享相同的命名空间,因此视图和表不能具有相同的名称。 另外,视图的名称必须遵循表的命名规则。
SELECT语句
在SELECT语句中,可以从数据库中存在的任何表或视图查询数据。SELECT语句必须遵循以下几个规则:
-
SELECT语句可以在 -
SELECT语句不能引用任何变量,包括局部变量,用户变量和会话变量。 -
SELECT语句不能引用准备语句的参数。
请注意,
SELECT语句不需要引用任何表。
创建MySQL视图示例
创建简单的视图
我们来看看orderDetails表。基于orderDetails表来创建一个表示每个订单的总销售额的视图。
CREATE VIEW SalePerOrder AS
SELECT
orderNumber, SUM(quantityOrdered * priceEach) total
FROM
orderDetails
GROUP by orderNumber
ORDER BY total DESC;
SQL
如果使用SHOW TABLES命令来查看示例数据库(yiibaidb)中的所有表,我们还会看到SalesPerOrder视图也显示在表的列表中。如下所示 -
mysql> SHOW TABLES;
+--------------------+
| Tables_in_yiibaidb |
+--------------------+
| article_tags |
| contacts |
| customers |
| departments |
| employees |
| offices |
| offices_bk |
| offices_usa |
| orderdetails |
| orders |
| payments |
| productlines |
| products |
| saleperorder |
+--------------------+
14 rows in set
SQL
这是因为视图和表共享相同的命名空间。要知道哪个对象是视图或表,请使用SHOW FULL TABLES命令,如下所示:
mysql> SHOW FULL TABLES;
+--------------------+------------+
| Tables_in_yiibaidb | Table_type |
+--------------------+------------+
| article_tags | BASE TABLE |
| contacts | BASE TABLE |
| customers | BASE TABLE |
| departments | BASE TABLE |
| employees | BASE TABLE |
| offices | BASE TABLE |
| offices_bk | BASE TABLE |
| offices_usa | BASE TABLE |
| orderdetails | BASE TABLE |
| orders | BASE TABLE |
| payments | BASE TABLE |
| productlines | BASE TABLE |
| products | BASE TABLE |
| saleperorder | VIEW |
+--------------------+------------+
14 rows in set
SQL
结果集中的table_type列指定哪个对象是视图,哪个对象是一个表(基表)。如上所示,saleperorder对应table_type列的值为:VIEW。
如果要查询每个销售订单的总销售额,只需要对SalePerOrder视图执行一个简单的SELECT语句,如下所示:
SELECT
*
FROM
salePerOrder;
SQL
执行上面查询语句,得到以下结果 -
+-------------+----------+
| orderNumber | total |
+-------------+----------+
| 10165 | 67392.85 |
| 10287 | 61402.00 |
| 10310 | 61234.67 |
| 10212 | 59830.55 |
|-- 此处省略了一大波数据-- |
| 10116 | 1627.56 |
| 10158 | 1491.38 |
| 10144 | 1128.20 |
| 10408 | 615.45 |
+-------------+----------+
327 rows in set
SQL
基于另一个视图创建视图
MySQL允许您基于另一个视图创建一个视图。例如,可以根据SalesPerOrder视图创建名为大销售订单(BigSalesOrder)的视图,以显示总计大于60,000的每个销售订单,如下所示:
CREATE VIEW BigSalesOrder AS
SELECT
orderNumber, ROUND(total,2) as total
FROM
saleperorder
WHERE
total > 60000;
SQL
现在,我们可以从BigSalesOrder视图查询数据,如下所示:
SELECT
orderNumber, total
FROM
BigSalesOrder;
SQL
执行上面查询语句,得到以下结果 -
+-------------+----------+
| orderNumber | total |
+-------------+----------+
| 10165 | 67392.85 |
| 10287 | 61402.00 |
| 10310 | 61234.67 |
+-------------+----------+
3 rows in set
SQL
使用连接表创建视图
以下是使用
CREATE VIEW customerOrders AS
SELECT
c.customerNumber,
p.amount
FROM
customers c
INNER JOIN
payments p ON p.customerNumber = c.customerNumber
GROUP BY c.customerNumber
ORDER BY p.amount DESC;
SQL
要查询customerOrders视图中的数据,请使用以下查询:
SELECT * FROM customerOrders;
SQL
执行上面查询语句,得到以下结果 -
+----------------+-----------+
| customerNumber | amount |
+----------------+-----------+
| 124 | 101244.59 |
| 321 | 85559.12 |
| 239 | 80375.24 |
| **** 此处省略了一大波数据 ***|
| 219 | 3452.75 |
| 216 | 3101.4 |
| 161 | 2434.25 |
| 172 | 1960.8 |
+----------------+-----------+
98 rows in set
Shell
使用子查询创建视图
以下说明如何使用
CREATE VIEW aboveAvgProducts AS
SELECT
productCode, productName, buyPrice
FROM
products
WHERE
buyPrice >
(SELECT
AVG(buyPrice)
FROM
products)
ORDER BY buyPrice DESC;
SQL
查询上述视图:aboveAvgProducts的数据简单如下:
SELECT
*
FROM
aboveAvgProducts;
SQL
执行上面查询语句,得到以下结果 -
+-------------+-----------------------------------------+----------+
| productCode | productName | buyPrice |
+-------------+-----------------------------------------+----------+
| S10_4962 | 1962 LanciaA Delta 16V | 103.42 |
| S18_2238 | 1998 Chrysler Plymouth Prowler | 101.51 |
| S10_1949 | 1952 Alpine Renault 1300 | 98.58 |
|************* 此处省略了一大波数据 *********************************|
| S18_3320 | 1917 Maxwell Touring Car | 57.54 |
| S24_4258 | 1936 Chrysler Airflow | 57.46 |
| S18_3233 | 1985 Toyota Supra | 57.01 |
| S18_2870 | 1999 Indy 500 Monte Carlo SS | 56.76 |
| S32_4485 | 1974 Ducati 350 Mk3 Desmo | 56.13 |
| S12_4473 | 1957 Chevy Pickup | 55.7 |
| S700_3167 | F/A 18 Hornet 1/72 | 54.4 |
+-------------+-----------------------------------------+----------+
54 rows in set
MySQL可更新视图简介
在MySQL中,视图不仅是可查询的,而且是可更新的。这意味着您可以使用
但是,要创建可更新
-
-
-
-
-
-
-
SELECT子句中的
-
引用
FROM子句中的不可更新视图 -
仅引用文字值
-
对基表的任何列的多次引用
如果使用
请注意,有时可以使用
MySQL可更新视图示例
让我们先来看看如何创建一个可更新的视图。
首先,基于
CREATE VIEW officeInfo
AS
SELECT officeCode, phone, city
FROM offices;
SQL
接下来,使用以下语句从officeInfo视图中查询数据:
SELECT
*
FROM
officeInfo;
SQL
执行上面查询语句,得到以下结果 -
mysql> SELECT * FROM officeInfo;
+------------+------------------+---------------+
| officeCode | phone | city |
+------------+------------------+---------------+
| 1 | +1 650 219 4782 | San Francisco |
| 2 | +1 215 837 0825 | Boston |
| 3 | +1 212 555 3000 | NYC |
| 4 | +33 14 723 4404 | Paris |
| 5 | +86 33 224 5000 | Beijing |
| 6 | +61 2 9264 2451 | Sydney |
| 7 | +44 20 7877 2041 | London |
+------------+------------------+---------------+
7 rows in set
SQL
然后,使用以下
UPDATE officeInfo
SET
phone = '+86 089866668888'
WHERE
officeCode = 4;
SQL
最后,验证更改结果,通过执行以下查询来查询officeInfo视图中的数据:
mysql> SELECT
*
FROM
officeInfo
WHERE
officeCode = 4;
+------------+------------------+-------+
| officeCode | phone | city |
+------------+------------------+-------+
| 4 | +86 089866668888 | Paris |
+------------+------------------+-------+
1 row in set
Shell
检查可更新视图信息
通过从information_schema数据库中的views表查询is_updatable列来检查数据库中的视图是否可更新。
以下查询语句将查询yiibaidb数据库获取所有视图,并显示哪些视图是可更新的。
SELECT
table_name, is_updatable
FROM
information_schema.views
WHERE
table_schema = 'yiibaidb';
SQL
执行上面查询语句,得到以下结果 -
+------------------+--------------+
| table_name | is_updatable |
+------------------+--------------+
| aboveavgproducts | YES |
| bigsalesorder | YES |
| customerorders | NO |
| officeinfo | YES |
| saleperorder | NO |
+------------------+--------------+
5 rows in set
SQL
通过视图删除行
首先,创建一个名为items的表,在items表中插入一些行,并创建一个查询包含价格大于700的项的视图。
USE testdb;
-- create a new table named items
CREATE TABLE items (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price DECIMAL(11 , 2 ) NOT NULL
);
-- insert data into the items table
INSERT INTO items(name,price)
VALUES('Laptop',700.56),('Desktop',699.99),('iPad',700.50) ;
-- create a view based on items table
CREATE VIEW LuxuryItems AS
SELECT
*
FROM
items
WHERE
price > 700;
-- query data from the LuxuryItems view
SELECT
*
FROM
LuxuryItems;
SQL
执行上面查询语句后,得到以下结果 -
+----+--------+--------+
| id | name | price |
+----+--------+--------+
| 1 | Laptop | 700.56 |
| 3 | iPad | 700.5 |
+----+--------+--------+
2 rows in set
Shell
其次,使用DELETE语句来删除id为3的行。
DELETE FROM LuxuryItems
WHERE
id = 3;
SQL
MySQL返回一条消息,表示有1行受到影响。
Query OK, 1 row affected
SQL
第三步,再次通过视图检查数据。
mysql> SELECT * FROM LuxuryItems; +----+--------+--------+ | id | name | price | +----+--------+--------+ | 1 | Laptop | 700.56 | +----+--------+--------+ 1 row in set SQL
第四步,还可以从基表items查询数据,以验证DELETE语句是否实际删除了该行。
mysql> SELECT * FROM items; +----+---------+--------+ | id | name | price | +----+---------+--------+ | 1 | Laptop | 700.56 | | 2 | Desktop | 699.99 | +----+---------+--------+ 2 rows in set SQL
如上面所示,ID为3的行在基表中被删除。
WITH CHECK OPTION子句简介
有时候,
下面说明了WITH CHECK OPTION子句的语法 -
CREATE OR REPLACE VIEW view_name
AS
select_statement
WITH CHECK OPTION;
SQL
请注意,将分号(;)放在WITH CHECK OPTION子句的末尾,而不是在
我们来看一下使用WITH CHECK OPTION子句的例子。
MySQL WITH CHECK OPTION子句示例
首先,我们根据employees表
CREATE OR REPLACE VIEW vps AS
SELECT
employeeNumber,
lastname,
firstname,
jobtitle,
extension,
email,
officeCode,
reportsTo
FROM
employees
WHERE
jobTitle LIKE '%VP%';
SQL
接下来,使用以下语句从vps视图中查询数据:
SELECT * FROM vps;
SQL
执行上面查询语句,得到以下结果 -
mysql> SELECT * FROM vps;
+----------------+----------+-----------+--------------+-----------+----------------------+------------+-----------+
| employeeNumber | lastname | firstname | jobtitle | extension | email | officeCode | reportsTo |
+----------------+----------+-----------+--------------+-----------+----------------------+------------+-----------+
| 1056 | Hill | Mary | VP Sales | x4611 | mary.hill@yiibai.com | 1 | 1002 |
| 1076 | Firrelli | Jeff | VP Marketing | x9273 | jfirrelli@yiibai.com | 1 | 1002 |
+----------------+----------+-----------+--------------+-----------+----------------------+------------+-----------+
2 rows in set
SQL
因为vps是一个简单的视图,因此它是可更新的。
然后,我们通过vps视图将一行员工数据信息插入。
INSERT INTO vps(employeeNumber,firstname,lastname,jobtitle,extension,email,officeCode,reportsTo)
values(1703,'Lily','Bush','IT Manager','x9111','lilybush@yiiibai.com',1,1002);
SQL
请注意,新创建的员工通过vps视图不可见,因为她的职位是IT经理,而不是VP。使用以下SELECT语句来验证它。
SELECT * FROM employees WHERE employeeNumber=1703;
SQL
执行上面语句,得到以下结果 -
+----------------+-----------+-----------+-----------+-----------------------+------------+-----------+----------------------+
| employeeNumber | lastName | firstName | extension | email | officeCode | reportsTo | jobTitle |
+----------------+-----------+-----------+-----------+-----------------------+------------+-----------+----------------------+
| 1703 | Bush | Lily | x9111 | lilybush@yiiibai.com | 1 | 1002 | IT Manager |
| 1702 | Gerard | Martin | x2312 | mgerard@gmail.com | 4 | 1102 | Sales Rep |
| 1625 | Kato | Yoshimi | x102 | ykato@gmail.com | 5 | 1621 | Sales Rep |
| 1621 | Nishi | Mami | x101 | mnishi@gmail.com | 5 | 1056 | Sales Rep |
SQL
但这可能不是我们想要的,因为通过vps视图暴露VP员工,而不是其他员工。
为了确保视图的一致性,用户只能显示或更新通过视图可见的数据,则在创建或修改视图时使用WITH CHECK OPTION。
让我们修改视图以包括WITH CHECK OPTION选项。
CREATE OR REPLACE VIEW vps AS
SELECT
employeeNumber,
lastname,
firstname,
jobtitle,
extension,
email,
officeCode,
reportsTo
FROM
employees
WHERE
jobTitle LIKE '%VP%'
WITH CHECK OPTION;
SQL
请注意在CREATE OR REPLACE语句的结尾处加上WITH CHECK OPTION子句。
之后,再次通过vps视图将一行插入employees表中,如下所示:
INSERT INTO vps(employeeNumber,firstname,lastname,jobtitle,extension,email,officeCode,reportsTo)
VALUES(1704,'John','Minsu','IT Staff','x9112','johnminsu@yiibai.com',1,1703);
SQL
这次MySQL拒绝插入并发出以下错误消息:
Error Code: 1369 - CHECK OPTION failed 'yiibaidb.vps'
SQL
最后,我们通过vps视图将一个职位为SVP Marketing的员工插入employees表,看看MySQL是否允许这样做。
INSERT INTO vps(employeeNumber,firstname,lastname,jobtitle,extension,email,officeCode,reportsTo)
VALUES(1704,'John','Minsu','SVP Marketing','x9112','johnminsu@classicmodelcars.com',1,1076);
SQL
MySQL发出1行受影响(Query OK, 1 row affected)。
可以通过根据vps视图查询数据来再次验证插入操作。
SELECT * FROM vps;
SQL
如上查询结果所示,它的确按预期工作了。
mysql> SELECT * FROM vps;
+----------------+----------+-----------+---------------+-----------+--------------------------------+------------+-----------+
| employeeNumber | lastname | firstname | jobtitle | extension | email | officeCode | reportsTo |
+----------------+----------+-----------+---------------+-----------+--------------------------------+------------+-----------+
| 1056 | Hill | Mary | VP Sales | x4611 | mary.hill@yiibai.com | 1 | 1002 |
| 1076 | Firrelli | Jeff | VP Marketing | x9273 | jfirrelli@yiibai.com | 1 | 1002 |
| 1704 | Minsu | John | SVP Marketing | x9112 | johnminsu@classicmodelcars.com | 1 | 1076 |
+----------------+----------+-----------+---------------+-----------+--------------------------------+------------+-----------+
3 rows in set
LOCAL&CASCADED检查范围介绍
当使用WITH CHECK OPTION子句
为了确定检查的范围,MySQL提供了两个选项:LOCAL和CASCADED。如果您没有在WITH CHECK OPTION子句中显式指定关键字,则MySQL默认使用CASCADED。
MySQL与CASCADC检查选项
要了解使用CASCADED CHECK OPTION的效果,请参阅下面的例子。
首先,
USE testdb;
CREATE TABLE t1 (
c INT
);
SQL
接下来,基于t1表创建一个名为v1的视图,以选择值大于10的行记录。
CREATE OR REPLACE VIEW v1
AS
SELECT
c
FROM
t1
WHERE
c > 10;
SQL
因为没有指定WITH CHECK OPTION,所以以下语句即使不符合v1视图的定义也可以工作。
INSERT INTO v1(c) VALUES (5);
SQL
然后,基于v1视图创建v2视图。在v2视图中添加一个WITH CASCADED CHECK OPTION子句。
CREATE OR REPLACE VIEW v2
AS
SELECT
c
FROM
v1
WITH CASCADED CHECK OPTION;
SQL
现在,通过v2视图在t1表中
INSERT INTO v2(c) VALUES (5);
SQL
MySQL发出以下错误消息:
Error Code: 1369. CHECK OPTION failed 'testdb.v2'
SQL
它失败了,因为它创建一个不符合v2视图定义的新行。
之后,我们再创建一个基于v2的名为v3的新视图。
CREATE OR REPLACE VIEW v3
AS
SELECT
c
FROM
v2
WHERE
c < 20;
SQL
我们通过v3视图插入一个新行到t1表中,值为8。
INSERT INTO v3(c) VALUES (8);
SQL
MySQL发出以下错误信息:
Error Code: 1369. CHECK OPTION failed 'testdb.v3'
SQL
上面插入语句看起来符合v3视图的定义,
这是为什么呢?
因为v3视图取决于v2视图,v2视图具有WITH CASCADED CHECK OPTION。
但是,以下插入语句能正常工作。
INSERT INTO v3(c) VALUES (30);
SQL
因为v3视图没有使用WITH CHECK OPTION定义,并且该语句符合v2视图的定义。
所以,总而言之:
当视图使用WITH CASCADED CHECK OPTION时,MySQL会循环检查视图的规则以及底层视图的规则。
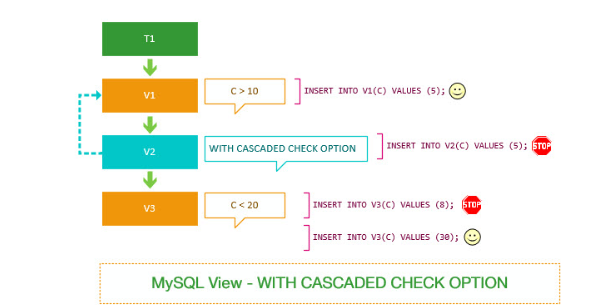
下面将演示使用 WITH LOCAL CHECK OPTION 选项,使用上面相同的示例来查看差异。
首先,将v2视图更改为使用WITH LOCAL CHECK OPTIONS替代。
ALTER VIEW v2 AS
SELECT
c
FROM
v1
WITH LOCAL CHECK OPTION;
SQL
其次,插入与上述示例相同的行。
INSERT INTO v2(c) VALUES (5);
SQL
它是可以成功执行的。
因为v2视图没有任何规则。 v2视图取决于v1视图。 但是,v1视图没有指定检查选项,因此MySQL跳过检查v1视图中的规则。
请注意,在使用
WITH CASCADED CHECK OPTION创建的v2视图中,此语句失败。
第三,通过v3视图将相同的行插入t1表。
INSERT INTO v3(c) VALUES (8);
SQL
在这种情况下可以执行成功,因为MySQL视图中的WITH LOCAL CHECK OPTIONS选项没有检查v1视图的规则。 另外,请注意,在使用WITH CASCADED CHECK OPTION创建的v2视图示例中,此语句执行失败。
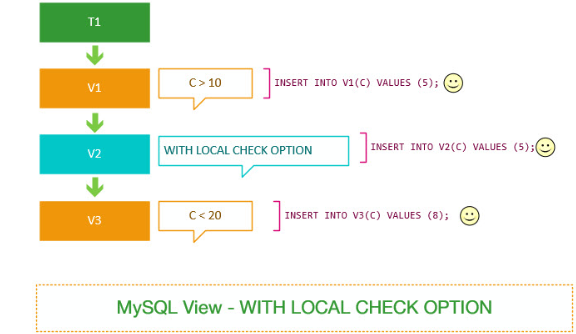
因此,如果视图使用WITH LOCAL CHECK OPTION,MySQL会检查WITH LOCAL CHECK OPTION和WITH CASCADED CHECK OPTION选项的视图规则。
与使用WITH CASCADED CHECK OPTION的视图不同,MySQL检查所有依赖视图的规则。
注意,在MySQL 5.7.6之前,如果您使用带有
WITH LOCAL CHECK OPTION的视图,MySQL只会检查当前视图的规则,并且不会检查底层视图的规则。
查看视图定义
MySQL提供了用于显示视图定义的SHOW CREATE VIEW语句。
以下是SHOW CREATE VIEW语句的语法:
SHOW CREATE VIEW [database_name].[view_ name];
SQL
要显示视图的定义,需要在SHOW CREATE VIEW子句之后指定视图的名称。
为了更好的演示,我们先来
假设根据employees表创建一个简单的视图用来显示公司组织结构:
USE yiibaidb;
CREATE VIEW organization AS
SELECT
CONCAT(E.lastname, E.firstname) AS Employee,
CONCAT(M.lastname, M.firstname) AS Manager
FROM
employees AS E
INNER JOIN
employees AS M ON M.employeeNumber = E.ReportsTo
ORDER BY Manager;
SQL
从以上视图中查询数据,得到以下结果 -
mysql> SELECT * FROM organization;
+------------------+------------------+
| Employee | Manager |
+------------------+------------------+
| BondurLoui | BondurGerard |
| CastilloPamela | BondurGerard |
| JonesBarry | BondurGerard |
| HernandezGerard | BondurGerard |
.......此处省略了一大波数据.......
| KatoYoshimi | NishiMami |
| KingTom | PattersonWilliam |
| MarshPeter | PattersonWilliam |
| FixterAndy | PattersonWilliam |
+------------------+------------------+
24 rows in set
SQL
要显示视图的定义,请使用SHOW CREATE VIEW语句如下:
SHOW CREATE VIEW organization;
SQL
还可以使用任何纯文本编辑器(如记事本)显示视图的定义,以打开数据库文件夹中的视图定义文件。
例如,要打开organization视图定义,可以使用以下路径找到视图定义文件:\data\yiibaidb\organization.frm。
但是,不应该直接在.frm文件中修改视图的定义。
修改视图
MySQL提供两个语句,允许您修改现有视图:ALTER VIEW和CREATE OR REPLACE VIEW 。
使用ALTER VIEW语句修改视图
创建视图后,可以使用ALTER VIEW语句修改视图。
ALTER VIEW语句的语法类似于CREATE VIEW语句,除了CREATE关键字被ALTER关键字替换外,其它都一样。
ALTER
[ALGORITHM = {MERGE | TEMPTABLE | UNDEFINED}]
VIEW [database_name]. [view_name]
AS
[SELECT statement]
SQL
以下语句通过添加email列来演示如何修改organization视图。
ALTER VIEW organization
AS
SELECT CONCAT(E.lastname,E.firstname) AS Employee,
E.email AS employeeEmail,
CONCAT(M.lastname,M.firstname) AS Manager
FROM employees AS E
INNER JOIN employees AS M
ON M.employeeNumber = E.ReportsTo
ORDER BY Manager;
SQL
要验证更改,可以从organization视图中查询数据:
SELECT
*
FROM
Organization;
SQL
执行上面查询语句,得到以下结果 -
Shell
使用CREATE OR REPLACE VIEW语句修改视图
除ALTER VIEW语句外,还可以使用CREATE OR REPLACE VIEW语句来创建或替换现有视图。如果一个视图已经存在,MySQL只会修改视图。如果视图不存在,MySQL将创建一个新的视图。
以下语句使用CREATE OR REPLACE VIEW语法根据employees表创建一个名称为v_contacts的视图:
CREATE OR REPLACE VIEW v_contacts AS
SELECT
firstName, lastName, extension, email
FROM
employees;
-- 查询视图数据
SELECT * FROM v_contacts;
SQL
执行上面查询语句,得到以下结果 -
+-----------+-----------+-----------+--------------------------------+
| firstName | lastName | extension | email |
+-----------+-----------+-----------+--------------------------------+
| Diane | Murphy | x5800 | dmurphy@yiibai.com |
| Mary | Hill | x4611 | mary.hill@yiibai.com |
| Jeff | Firrelli | x9273 | jfirrelli@yiibai.com |
| William | Patterson | x4871 | wpatterson@yiibai.com |
| Gerard | Bondur | x5408 | gbondur@gmail.com |
| Anthony | Bow | x5428 | abow@gmail.com |
| Leslie | Jennings | x3291 | ljennings@yiibai.com |
.............. 此处省略了一大波数据 ..................................
| Martin | Gerard | x2312 | mgerard@gmail.com |
| Lily | Bush | x9111 | lilybush@yiiibai.com |
| John | Minsu | x9112 | johnminsu@classicmodelcars.com |
+-----------+-----------+-----------+--------------------------------+
25 rows in set
Shell
假设您要将职位(jobtitle)列添加到v_contacts视图中,只需使用以下语句 -
CREATE OR REPLACE VIEW v_contacts AS
SELECT
firstName, lastName, extension, email, jobtitle
FROM
employees;
-- 查询视图数据
SELECT * FROM v_contacts;
SQL
执行上面查询语句后,可以看到添加一列数据 -
+-----------+-----------+-----------+--------------------------------+----------------------+
| firstName | lastName | extension | email | jobtitle |
+-----------+-----------+-----------+--------------------------------+----------------------+
| Diane | Murphy | x5800 | dmurphy@yiibai.com | President |
| Mary | Hill | x4611 | mary.hill@yiibai.com | VP Sales |
| Jeff | Firrelli | x9273 | jfirrelli@yiibai.com | VP Marketing |
................... 此处省略了一大波数据 ....................................................
| Yoshimi | Kato | x102 | ykato@gmail.com | Sales Rep |
| Martin | Gerard | x2312 | mgerard@gmail.com | Sales Rep |
| Lily | Bush | x9111 | lilybush@yiiibai.com | IT Manager |
| John | Minsu | x9112 | johnminsu@classicmodelcars.com | SVP Marketing |
+-----------+-----------+-----------+--------------------------------+----------------------+
25 rows in set
SQL
删除视图
创建视图后,可以使用DROP VIEW语句将其删除。下面说明了DROP VIEW语句的语法:
DROP VIEW [IF EXISTS] [database_name].[view_name]
SQL
IF EXISTS是语句的可选子句,它允许您检查视图是否存在。它可以避免删除不存在的视图的错误。
例如,如果要删除organization视图,可以按如下所示使用DROP VIEW语句:
DROP VIEW IF EXISTS organization;
SQL
每次修改或删除视图时,MySQL会将视图定义文件备份到/database_name/arc/目录中。 如果您意外修改或删除视图,可以从/database_name/arc/文件夹获取其备份。
三.元数据获取
-
3.1 show
MySQL5.7show结构
show databases; #查看所有数据库
show tables; #查看当前库的所有表
SHOW TABLES FROM #查看某个指定库下的表
show create database world #查看建库语句
show create table world.city #查看建表语句
show grants for root@'localhost' #查看用户的权限信息
show charset; #查看字符集
show collation #查看校对规则
show processlist; #查看数据库连接情况
show index from #表的索引情况
show status #数据库状态查看
SHOW STATUS LIKE '%lock%'; #模糊查询数据库某些状态
SHOW VARIABLES #查看所有配置信息
SHOW variables LIKE '%lock%'; #查看部分配置信息
show engines #查看支持的所有的存储引擎
show engine innodb status\G #查看InnoDB引擎相关的状态信息
show binary logs #列举所有的二进制日志
show master status #查看数据库的日志位置信息
show binlog evnets in #查看二进制日志事件
show slave status \G #查看从库状态
SHOW RELAYLOG EVENTS #查看从库relaylog事件信息
desc (show colums from city) #查看表的列定义信息
3.2 information_schema
-
a.介绍
视图,查询元数据的方法
-
b.tables视图应用
TABLE_SCHEMA ---->表所在库
TABLE_NAME ---->表名
ENGINE ---->存储引擎
TABLE_ROWS ---->表的行数(粗略统计)
AVG_ROW_LENGTH ---->表中行的平均行(字节)(粗略统计)
INDEX_LENGTH ---->索引的占用空间大小(字节)(粗略统计)
DATA_FREE ---->碎片数
TABLE_COMMENT ---->表注释
例子:
-
1.查询整个数据库中所有库和所对应的表信息
库名 表个数 表名
world 3 city,a,b
SELECT table_schema,count(*) ,GROUP_CONCAT(table_name)
FROM information_schema.tables
GROUP BY table_schema;
-
2.统计每个库的数据量大小
-- 表的数据量=平均行长度*行数+索引长度
SELECT table_schema,sum(TABLE_ROWS*AVG_ROW_LENGTH+INDEX_LENGTH)/1024
FROM information_schema.tables
GROUP BY table_schema;
3.3concat()拼接语句
-
a. 查询一下业务数据库中,非InnoDB的表
mysql> create table t2(id int)engine=myisam;
SELECT table_schema , table_name ,engine FROM information_schema.tables
WHERE
table_schema NOT IN ('mysql','sys','information_schema','performance_schema')
AND ENGINE <>'innodb';
mysql> alter table t2 engine=innodb;
mysql> alter table world.t3 engine=innodb;
mysql> select concat(user,"@",host) from mysql.user;
SELECT CONCAT("table_schema" , "table_name" ,"engine") FROM information_schema.tables
WHERE
table_schema NOT IN ('mysql','sys','information_schema','performance_schema')
AND ENGINE <>'innodb';
-
b. 将非InnoDB表批量替换为InnoDB
SELECT concat("alter table ",table_schema,".",table_name," engine=innodb;") FROM information_schema.tables
WHERE
table_schema NOT IN ('mysql','sys','information_schema','performance_schema','world')
AND ENGINE <>'innodb' into outfile '/tmp/alter.sql' ;
[root@db01 ~]#mysqldump -uroot -p123 world city>/tmp/world_city.sql#备份/tmp/world_city.sql
[root@db01 ~]#mysqldump -uroot -p123 world city >/databak/world_city.sql
SELECT concat("mysqldump -uroot -p123 ",table_schema," ",table_name," >/databak/",table_schema,"_",table_name,".sql") FROM information_schema.tables
WHERE
table_schema NOT IN ('mysql','sys','information_schema','performance_schema') into outfile '/tmp/bak.sh' ; #导出到/tmp/bak.sh
[root@db01 ~]# sh /tmp/bak.sh
3.4 COLUMNS
TABLE_SCHEMA ---->库名
TABLE_NAME ---->表名
COLUMN_NAME ---->列名
DATA_TYPE ---->数据类型
COLUMN_KEY ---->列键
COLUMN_COMMENT ---->列注释
mysql> select id,command from processlist where command='sleep'
mysql>kill 10:\
mysql>kill 11:\
四.索引及执行计划
1.介绍
类似于一本书中的目录,起到优化查询的作用(select,update,delete)
2.种类
Btree(平衡多叉树):b-tree b+tree(b*tree),优点:范围查找
HASH :优点,比较适合随机的等值。
Rtree
FullText
GIS 索引
二叉树
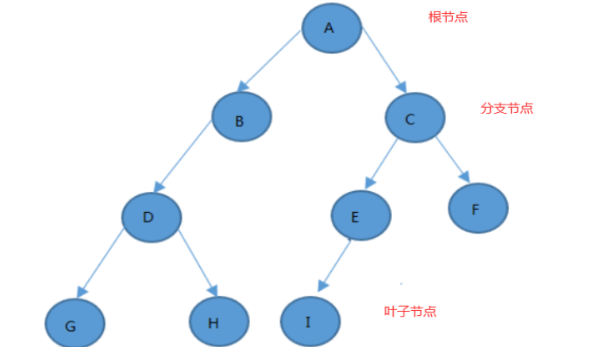
原理:
1> 将数据存放在一个一个节点上;
2> 节点又分为三种节点:最上面的叫根节点,中间的叫分支节点,最下面的到底叫叶子节点。
3> 每个分支节点有一个分支,或者两个分支。
缺点
二叉树存在不平衡的问题。
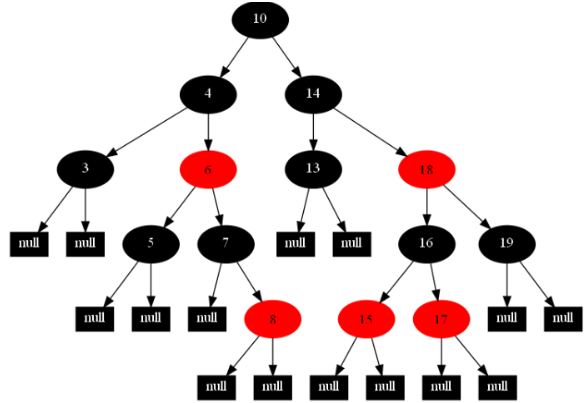
原理:
红黑树(Red-Black Tree)是二叉搜索树(Binary Search Tree)的一种改进。我们知道二叉搜索树在最坏的情况下可能会变成一个链表(当所有节点按从小到大的顺序依次插入后)。
而红黑树在每一次插入或删除节点之后都会花O(log N)的时间来对树的结构作修改,以保持树的平衡。也就是说,红黑树的查找方法与二叉搜索树完全一样;插入和删除节点的的方法前半部分节与二叉搜索树完全一样,而后半部分添加了一些修改树的结构的操作。
缺点: 查询数字的速度慢。
3.Btree的细分
Btree树
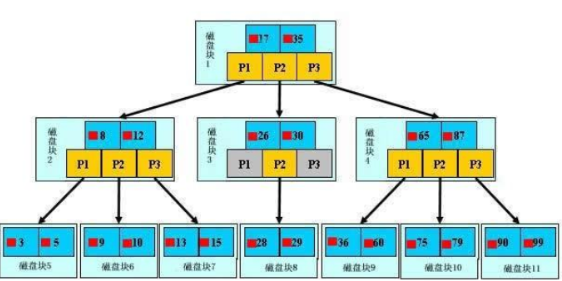
B树(B-Tree,并不是B“减”树,横杠为连接符,容易被误导)
<br> 是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
注意:B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
每次查找数据时,都去根节点查找数据,查找效率低下。
B+TREE
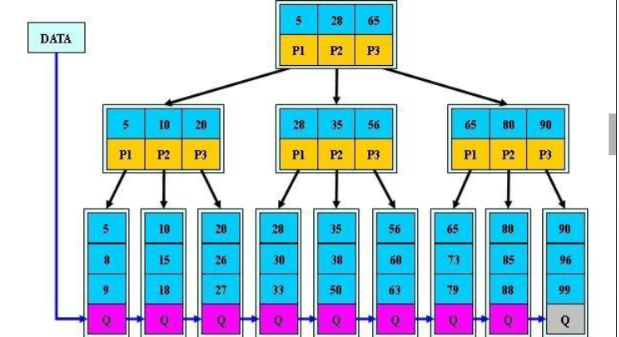
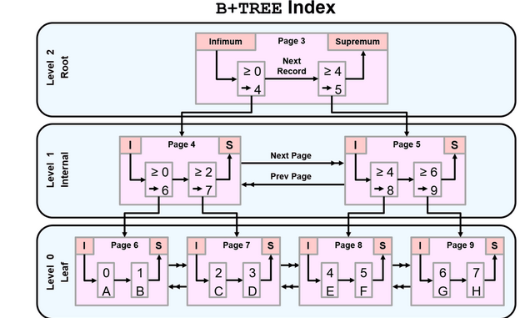
通常所说的索引是指 B-Tree索引,它是目前关系型数据库中查找数据最为常用和有效的索引,大多数存储引擎都支持这种索引,且 MySQL 默认采用这种索引。使用 B-Tree 这个术语,是因为 MySQL 在 CREATE TABLE 或其它语句中使用这个关键字,
但实际上不同的存储引擎可能使用不同的数据结构,比如 InnoDB 就是使用的 B+Tree。B+Tree中的B是指balance,意为平衡。相对 Hash索引,B+Tree在查找单条记录的速度比不上 Hash索引,但是因为更适合排序等操作,所以它更受欢迎。毕竟不可能只对数据库进行单条记录的操作
注 : B+树索引 并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据
叶子节点只放数据,根节点和分支节点只放索引。
B+树特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
5.叶子节点最下面的数据块指针直接指向下一个数据块的位置,适合按顺序范围查询,搜索一定的范围,速度非常快。
6.所有的记录优先级一致,查询次数一致,效率一致。
B+Tree索引:顺序存储,每一个叶子节点到根结点的距离是相同的;左前缀索引,适合查询范围类的数据
可以使用B+Tree索引的查询类型:
全值匹配:精确所有索引列,如:姓wang,名xiaochun,年龄30
匹配最左前缀:即只使用索引的第一列,如:姓wang
匹配列前缀:只匹配一列值开头部分,如:姓以w开头的
匹配范围值:如:姓ma和姓wang之间
精确匹配某一列并范围匹配另一列:如:姓wang,名以x开头的只访问索引的查询
B+Tree索引的限制
1> 如不从最左列开始,则无法使用索引,如:查找名为xiaochun,或姓为g结尾
2> 不能跳过索引中的列:如:查找姓wang,年龄30的,只能使用索引第一列
3> 如果查询中某个列是为范围查询,那么其右侧的列都无法再使用索引:如:姓wang,名x%,年龄30,只能利用姓和名上面的索引
特别提示:
1> 索引列的顺序和查询语句的写法应相匹配,才能更好的利用索引
2> 为优化性能,可能需要针对相同的列但顺序不同创建不同的索引来满足不同类型的查询需求
冗余和重复索引:
冗余索引:(A),(A,B)
重复索引:已经有索引,再次建立索引
索引优化策略:
1> 独立地使用列:尽量避免其参与运算,独立的列指索引列不能是表达式的一部分,也不能是函数的参数,在where条件中,始终将索引列单独放在比较符号的一侧
2> 左前缀索引:构建指定索引字段的左侧的字符数,要通过索引选择性来评估
3> 索引选择性:不重复的索引值和数据表的记录总数的比值
4> 多列索引:AND操作时更适合使用多列索引,而非为每个列创建单独的索引
5> 选择合适的索引列顺序:无排序和分组时,将选择性最高放左侧
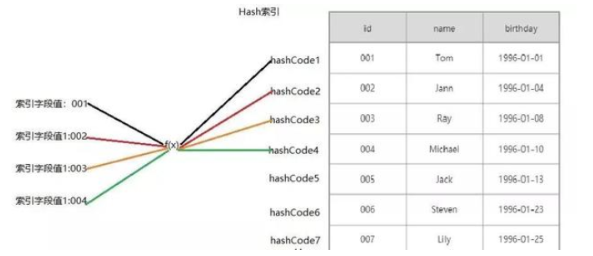
Hash 索引
mysql 中,只有 Memory(Memory表只存在内存中,断电会消失,适用于临时表) 存储引擎显示支持 Hash索引,是 Memory表的默认索引类型,尽管 Memory表也可以使用 B+Tree索引。Hash索引 把数据以 hash 形式组织起来,因此当查找某一条记录的时候,速度非常快。<br>但是因为 hash 结构,每个键只对应一个值,而且是散列的方式分布,所以它并不支持范围查找和排序等功能
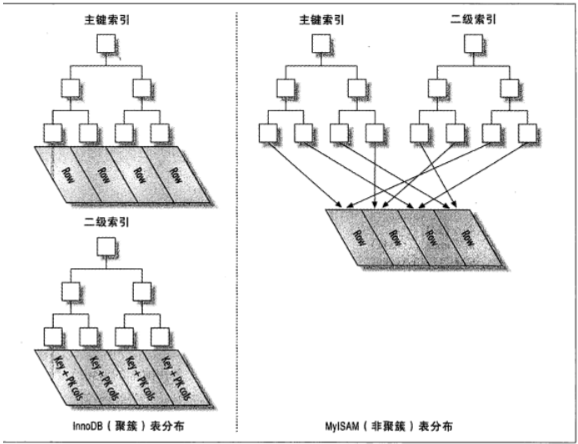
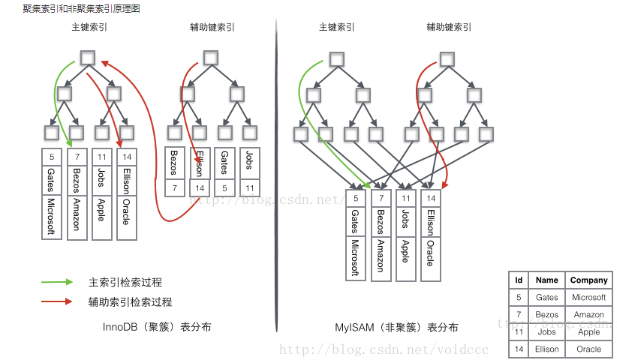
MyISAM:frm后缀的文件(存放表结构)、文件后缀是YMD(存放数据文件)和YMI后缀的文件(存放索引文件),索引和数据分开存放,为非聚簇索引
innodb:文件中frm后缀(存放表结构)和idb后缀的文件存放(索引和数据文件),索引和数据文件在一起存放,为聚簇索引
稠密索引:一个索引对应了所有的数据。
稀疏索引:一个索引对应了一个数据,且对应的数据不全。
简单索引:对单个字段创建索引
复合索引:对多个字段创建索引
索引的设计原则
1> 选择唯一性索引,可更快通过索引确定某条记录
2> 为经常需要 排序ORDER BY、分组GROUP BY 和 联合操作UNION 的字段建立索引
3> 为常作为查询条件的字段建立索引
4> 限制索引的数目,索引太多需要的磁盘空间就越大,修改表示对索引的重构和更新会很麻烦
5> 尽量使用数据量少的索引,对 CHAR(100) 全文索引肯定会比 CHAR(10) 耗时多
6> 尽量使用前缀来索引
7> 删除不再使用或者很少使用的索引
8> 避免多个范围条件 : MySQL 支持单列的范围索引,但不支持多列范围索引
9> 尽量避免NULL,含有 NULL 的索引将很难进行优化
索引优化建议
1> 只要列中含有NULL值,就最好不要在此例设置索引,复合索引如果有NULL值,此列在使用时也不会使用索引
2> 尽量使用短索引,如果可以,应该制定一个前缀长度
3> 对于经常在where子句使用的列,最好设置索引
4> 对于有多个列where或者order by子句,应该建立复合索引
5> 对于like语句,以%或者‘-’开头的不会使用索引,以%结尾会使用索引
6> 尽量不要在列上进行运算(函数操作和表达式操作)
7> 尽量不要使用not in和<>操作
SQL语句性能优化
1> 查询时,能不要*就不用*,尽量写全字段名
2> 大部分情况连接效率远大于子查询
3> 多表连接时,尽量小表驱动大表,即小表 join 大表
4> 在有大量记录的表分页时使用limit
5> 对于经常使用的查询,可以开启缓存
6> 多使用explain和profile分析查询语句
7> 查看慢查询日志,找出执行时间长的sql语句优化
聚簇索引:主键索引
(1)MySQL 会自动选择主键作为聚集索引列,没有主键会选择唯一键,如果都没有会生成隐藏的.
(2)MySQL进行存储数据时,会按照聚集索引列值得顺序,有序存储数据行
(3)聚集索引直接将原表数据页,作为叶子节点,然后提取聚集索引列向上生成枝和根
辅助索引:
(1) 提取索引列的所有值,进行排序
(2) 将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点
(3) 在叶子节点中的值,都会对应存储主键ID
单列
联合
唯一
前缀
聚集索引和辅助索引的区别
(1) 表中任何一个列都可以创建辅助索引,在你有需要的时候,只要名字不同即可
(2) 在一张表中,聚集索引只能有一个,一般是主键.
(3) 辅助索引,叶子节点只存储索引列的有序值+聚集索引列值(id列值).
(4) 聚集索引,叶子节点存储的是有序的整行数据.
4.索引的管理
#索引建立之前压测:
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='test' \
--query="select * from test.t100w where k2='VMlm'" engine=innodb \
--number-of-queries=2000 -uroot -p123 -verbose
mysql> alter table t100w add index idx_k2(k2);#优化索引
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 3.443 seconds
Minimum number of seconds to run all queries: 3.443 seconds
Maximum number of seconds to run all queries: 3.443 seconds
Number of clients running queries: 100
Average number of queries per client: 20
4.1 查询索引
mysql> use information_schema; mysql> show tables; use world a.desc city; PRI: 主键索引 MUL: 普通索引 UNI: 唯一索引 b.mysql> show index from city; Table 表名 Key_name 索引名 Column_name 列名 Cardinality 基数(选择度),位置值的多少
面试题:
Cardinality 建立索引之前,基数如何计算的?(重复值高于80%的不建议建立索引) select count(distinct countrycode)from city; +-----------------------------+ | count(distinct countrycode) | +-----------------------------+ | 232 | +-----------------------------+ mysql> select count(*)from city; mysql> select count(id)from city; +-----------+ | count(id) | +-----------+ | 4079 | +-----------+
4.2建立索引
a.单列索引
mysql> alter table city add index i_name(name);
b.联合索引
mysql> alter table city add index i_d_p(district,population);
c.前缀索引
mysql> alter table city add index i_n(name(10)); mysql> alter table city_demo add key(city(5)); Query OK, 0 rows affected (0.34 sec) Records: 0 Duplicates: 0 Warnings: 0
d.唯一索引
mysql> alter table tt add unique index ui(telnum);
去重复
mysql> select count(distinct district) from city;
4.3删除索引
mysql> show index from city; mysql> alter table city drop index i_name; mysql> alter table city drop index i_c_p; mysql> alter table city drop index i_n;
4.4 MySQL8.0新特性---> invisible index 不可见索引
语法:
ALTER TABLE t1 ALTER INDEX i_idx INVISIBLE;
ALTER TABLE t1 ALTER INDEX i_idx VISIBLE;
mysql> alter table city alter index idx_name invisible;
SELECT INDEX_NAME, IS_VISIBLE
FROM INFORMATION_SCHEMA.STATISTICS
WHERE TABLE_SCHEMA = 'world' AND table_name='city';
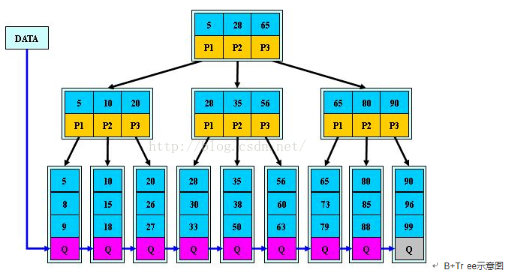
5.B+tree查找算法介绍
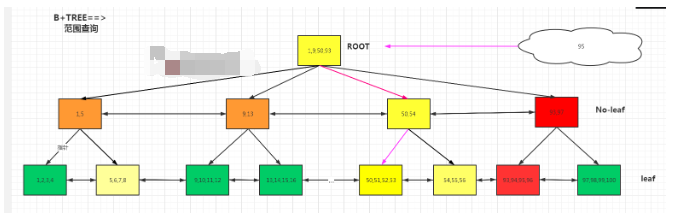
5.1 平衡
不管查找哪个数,需要查找次数理论上是相同的,对于一个三层b树来讲,理论上查找每个值都是三次IO。
讲究快速锁定范围
B+tree,加入了双向指针(头尾相接),进一步增强范围查找,减少对于ROOT和NO-LEAF的访问次数。
5.3构建过程
叶子:先将数据排序,生成叶子节点。
枝:保存叶子节点的范围(>=1 <5)+指针(→)
根:保存枝节点范围+指针
叶子节点和枝节点都有双向指针。
6.MySQL中如何应用B+TREE
6.1名词解释
区(簇)extent:连续的64pages ,默认是1M存储空间
page页:16KB大小,MySQL中最小的IO单元
6.2IOT组织表
数据应该按照索引结构有序(顺序)组织和存储数据
MySQL使用聚簇索引组织存储数据。
6.3 聚簇(区)索引
6.3.1 构建条件
a. 如果表中有主键,主键就被作为聚簇索引.
b. 没有主键,第一个不为空的唯一键.
c. 什么都没有,自动生成一个6字节的隐藏列,作为聚簇索引.
https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
When you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index. Define a primary key for each table that you create. If there is no logical unique and non-null column or set of columns, add a new auto-increment column, whose values are filled in automatically.
If you do not define a PRIMARY KEY for your table, MySQL locates the first UNIQUE index where all the key columns are NOT NULL and InnoDB uses it as the clustered index.
If the table has no PRIMARY KEY or suitable UNIQUE index, InnoDB internally generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column containing row ID values. The rows are ordered by the ID that InnoDB assigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
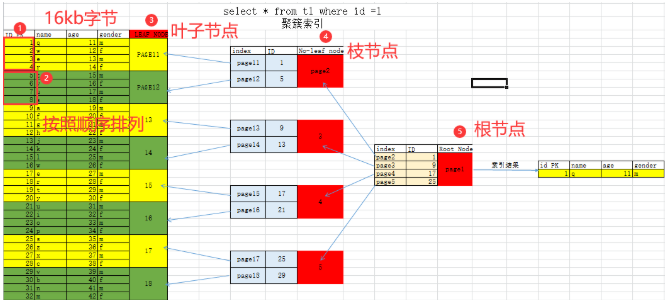
6.3.2 如何形成B树结构.
叶子节点: 聚簇索引组织表,存数据时,已经是按照ID列有序存储数据到各个连续的数据页中.原表数据存储结构就是叶子节点.
枝节点:叶子节点中ID范围+指针
根节点:枝节点的ID范围+指针
叶子节点和枝节点都有双向指针.
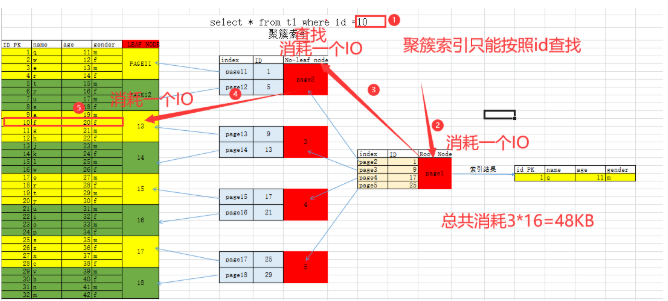
6.3.3 优化了哪些查询?
只能优化基于ID作为条件.索引单纯使用ID列查询,很局限.
> < = group by
where
6.4 辅助索引
需要人为按照需求创建辅助索引.
6.4.2 如何形成B树结构(面试题)
alter table t1 add index idx(name);
叶子节点 : 将辅助索引列值(name)+ID提取出来,按照辅助索引列值从小到大排序,存储到各个page中,生成叶子节点.
枝节点 : 存储了叶子节点中,name列范围+指针.
根节点 : 枝节点的name的范围+指针.
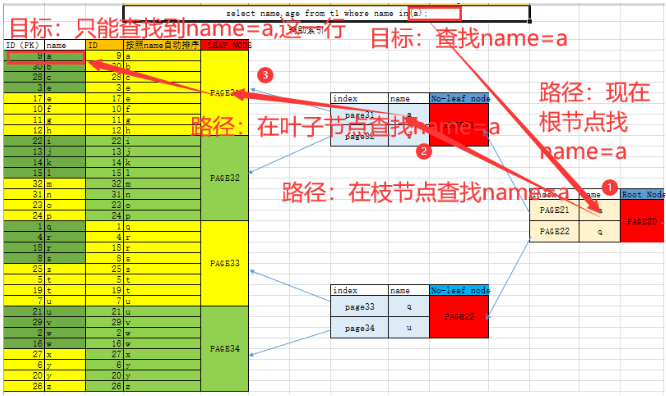
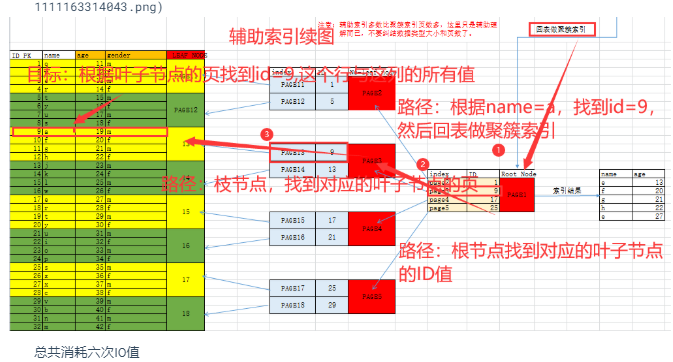
6.4.3 优化了哪些查询?
如果查询条件使用了name列,都会先扫描辅助索引,获得ID,再回到聚簇索引(回表),按照ID进行聚簇索引扫描,最终获取到数据行.
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index.
If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.htm
6.5 联合辅助索引结构
6.5.1 构建过程
alter table t1 add index idx_n_g(a,b)
叶子节点 : 提取a+b+id列值,按照a,b联合排序(从小到大),生成叶子节点.
枝节点 : 叶子节点最左列范围+指针
根节点 : 枝节点的范围+指针.
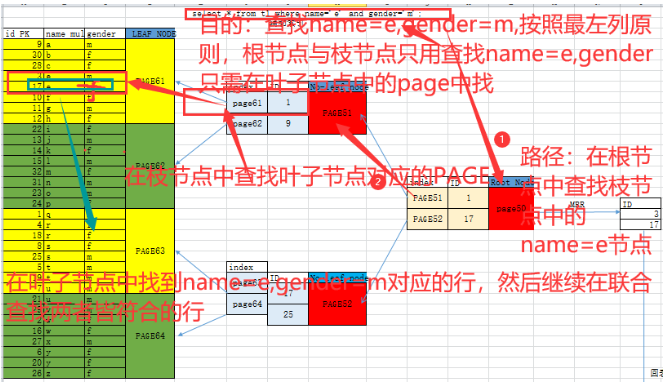
回表做聚簇索引
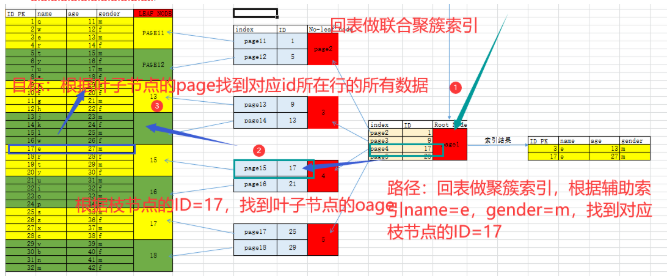
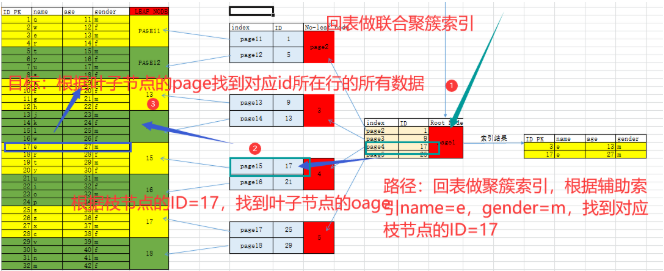
6.5.2 优化了哪些查询?
查询条件中必须包含最左列条件(a),先通过 a条件 扫描联合索引的根节点和枝节点,从而得到叶子节点范围.再拿b作为条件过滤一次. 最终目的,得到更精确的ID .理论上减少回表的次数.
6.5.3 最左原则
建立联合索引时,选择基数大(重复值少)作为最左列. 查询条件中必须要包含最左列条件.
7.索引树高度
一般建议3-4层为准,3层b树,2000w+
a.数据行多
分区表
定期归档:一般按照时间字段,定期归档到历史库中。pt-archiver
分库分表:分布式
b.索引列长度过长
前缀索引
c.数据类型
足够
简短的
合适的
影响索引树高度的因素
-
数据量级,解决方法:
分区表:
定期归档:一般按照时间字段,定期归档到历史库中,
pt-archiver分库,分表,分布式
-
索引列值过长,解决方法:
业务允许,尽量选择字符长度短的列作为索引列
业务不允许,采用前缀索引.
-
数据类型:
变长长度字符串,使用了
char,解决方案:变长长度字符串使用varcharenum使用短字符代替长字符enum ('山东','河北','黑龙江','吉林','辽宁','陕西'......)
enum ( 1 2 3 4 5 6 )
8.回表问题
8.1回表是什么?
辅助索引扫描之后,得到ID,再回到聚簇索引查找的过程
8.2回表会带来什么问题?
回表是随机IO,会导致IO的次数(IOPS)和量(吞吐量)增加
IOPS(Input/Output Operations Per Second):每秒的读写次数,用于衡量随机访问的性能
吞吐量:单位时间内成功地传送数据的数量(例如 200M/s)
8.3减少回表的方法
a.建索引使用联合索引(覆盖),尽可能多将查询条件的数据包含联合索引中
b.精细查询条件(业务方面>and < ,limit)
c.查询条件要符合联合索引规则。覆盖的列越多越好。
a b c
where a= and b= and c=
9.扩展项: 索引自优化AHI(自适应hash索引)\change buffer
AHI : 索引的索引. 为内存中的热点索引页,做了一个HASH索引表,能够快速找到需要的索引页地址. https://dev.mysql.com/doc/refman/8.0/en/innodb-adaptive-hash.html https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html change buffer : 对于辅助索引的变化,不会立即更新到索引中.暂存至change buffer . https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html
10.分析执行计划
10.1 分析执行计划定义:
优化器(算法)最终得出的,代价最低的,SQL语句的执行方案.
10.2 为什么要分析执行计划?
场景一: 分析比较慢的语句.
场景二: 上线新业务,可能会包含很多select update delete...,提前发现问题.
10.3 如何抓取执行计划
a. 抓取目标
select update delete
b. 方法
mysql> desc select * from world.city where countrycode='CHN'; mysql> explain select * from world.city where countrycode='CHN'; +----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | | ---- | ----------- | ----- | ---------- | ---- | ------------- | ---- | ------- | ---- | ---- | -------- | ----- | | | | | | | | | | | | | | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL | | ---- | ------ | ---- | ---- | ---- | ----------- | ----------- | ---- | ----- | ---- | ------ | ---- | | | | | | | | | | | | | | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
type
从上往下效率依次升高
-
ALL:全表扫描,不走索引
① 查询全表
DESC SELECT * FROM world.city;
② 查询条件出现以下语句
DESC SELECT * FROM world.city WHERE countrycode LIKE '%HN';
③ 辅助索引列的查询条件出现以下语句
DESC SELECT * FROM world.city WHERE countrycode != 'CHN';
DESC SELECT * FROM world.city WHERE countrycode <> 'CHN';
DESC SELECT * FROM world.city WHERE countrycode NOT IN ('CHN','USA' );
注意:对于聚集索引,使用例③语句,依然会走RANGE索引
DESC SELECT * FROM world.city WHERE id <> 10;
DESC SELECT * FROM world.city WHERE id != 10;
DESC SELECT * FROM world.city WHERE id NOT IN ('1','2' );
-
INDEX:全索引扫描
1. 查询需要获取整颗索引树,才能得到想要的结果时
DESC SELECT countrycode FROM world.city;
2. 联合索引中,任何一个非最左列作为查询条件时
idx_a_b_c(a,b,c) ---> a ab abc
SELECT * FROM t1 WHERE b
SELECT * FROM t1 WHERE c
RANGE:索引范围扫描
辅助索引列 > < >= <= LIKE IN OR
DESC SELECT * FROM world.city WHERE Population > 1000000;
DESC SELECT * FROM world.city WHERE Population < 100;
DESC SELECT * FROM world.city WHERE Population >= 1000000;
DESC SELECT * FROM world.city WHERE Population <= 100;
DESC SELECT * FROM world.city WHERE countrycode LIKE 'CH%';
DESC SELECT * FROM world.city WHERE countrycode IN ('CHN','USA');
DESC SELECT * FROM world.city WHERE Population < 100 OR Population > 1000000;
-
主键列
> < >= <= IN OR <> != NOT INDESC SELECT * FROM world.city WHERE id<5; DESC SELECT * FROM world.city WHERE id>5; DESC SELECT * FROM world.city WHERE id<=5; DESC SELECT * FROM world.city WHERE id>=5; DESC SELECT * FROM world.city WHERE id IN ('1','2' ); DESC SELECT * FROM world.city WHERE id < 5 OR id > 10; DESC SELECT * FROM world.city WHERE id <> 10; DESC SELECT * FROM world.city WHERE id != 10;DESC SELECT * FROM world.city WHERE id NOT IN ('1','2' );
注意:
IN不能享受到B+树的双向指针DESC SELECT * FROM world.city WHERE countrycode IN ('CHN','USA');可以改写为
DESC SELECT * FROM world.city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM world.city WHERE countrycode='USA';具体效果看压测结果
如果索引列的重复值太多, 改写为
UNION没有意义
-
ref:非唯一性索引,等值查询
DESC SELECT * FROM world.city WHERE countrycode='CHN';
-
eq_ref:在多表连接查询时,连接条件使用了主键或唯一键索引(uk pK)的非驱动表
DESC SELECT b.name,a.name
FROM city a
JOIN country b
ON a.countrycode=b.code
WHERE a.population <100;
-
const(system):唯一索引的等值查询
DESC SELECT * FROM world.city WHERE id=10;
10.4 如何分析执行计划
table : 操作的表
type : 操作类型(全表\索引) ,ALL index range ref eq_ref const(system)
possible_keys : 有可能用的索引
key : 真正要用是哪索引
key_len: 索引覆盖长度(联合索引)
rows : 预估需要扫描的行数
Extra : using where using index using index condition using filesort sort using temp
EXPLAIN
1.通过EXPLAIN来分析索引的有效性
2.EXPLAIN SELECT clause
获取查询执行计划信息,用来查看查询优化器如何执行查询
输出信息说明: 参考 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
id: 当前查询语句中,每个SELECT语句的编号
复杂类型的查询有三种:
简单子查询
用于FROM中的子查询
联合查询:UNION
注意:UNION查询的分析结果会出现一个额外匿名临时表
3.select_type:简单查询为SIMPLE 复杂查询:
SUBQUERY 简单子查询
PRIMARY 最外面的SELECT
DERIVED 用于FROM中的子查询
UNION UNION语句的第一个之后的SELECT语句
UNION RESULT 匿名临时表
table:SELECT语句关联到的表
4.type:关联类型或访问类型,即MySQL决定的如何去查询表中的行的方式,以下顺序,性能从低到高
ALL: 全表扫描
index:根据索引的次序进行全表扫描;如果在Extra列出现“Using index”表示了使用覆盖索引,而非全表扫描
range:有范围限制的根据索引实现范围扫描;扫描位置始于索引中的某一点,结束于另一点
ref: 根据索引返回表中匹配某单个值的所有行
eq_ref:仅返回一个行,但与需要额外与某个参考值做比较
const, system: 直接返回单个行
5.possible_keys:查询可能会用到的索引 6.key: 查询中使用到的索引 7.key_len: 在索引使用的字节数
explain(desc)使用场景(面试题)
题目意思: 我们公司业务慢,请你从数据库的角度分析原因
1.mysql出现性能问题,我总结有两种情况:
(1)应急性的慢:突然夯住
应急情况:数据库hang(卡了,资源耗尽)
处理过程:
1.show processlist; 获取到导致数据库hang的语句
2. explain 分析SQL的执行计划,有没有走索引,索引的类型情况
3. 建索引,改语句
(2)一段时间慢(持续性的):
(1)记录慢日志slowlog,分析slowlog
(2)explain 分析SQL的执行计划,有没有走索引,索引的类型情况
(3)建索引,改语句
10.5 type 详解
-
a. ALL 全表扫描
mysql> explain select * from world.city ;
mysql> explain select * from world.city where countrycode!='chn';
mysql> explain select * from world.city where countrycode like '%hn%';
mysql> explain select * from world.city where countrycode not in ('chn','usa');
-
b. index 全索引扫描
需要扫描整颗索引树,才能得到想要的结果.
desc select id ,countrycode from world.city;
-
c. range 索引范围 是我们应用索引优化的底线,也是应用最多的.
mysql> desc select * from city where id<10;
mysql> desc select * from city where countrycode like 'ch%';
mysql> desc select * from city where countrycode in ('CHN','USA');
SQL 改写为:
desc
select * from city where countrycode='CHN' union all select * from city where countrycode='USA'
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='world' \
--query=" select * from city where countrycode in ('CHN','USA')" engine=innodb \
--number-of-queries=2000 -uroot -p123 -verbose
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='world' \
--query="select * from city where countrycode='CHN' union all select * from city where countrycode='USA'" engine=innodb \
--number-of-queries=2000 -uroot -p123 -verbose
小经验:
索引列基数多少 + 压测结果,最终评估是否需要使用union .
d. ref : 辅助索引等值查询
mysql> desc select * from city where countrycode='CHN';
e. eq_ref : 非驱动表,连接条件是主键或唯一键.
补充:多表连接时,小结果集的表驱动大表
优化会自动判断查询语句中的谁作为驱动表更合适,有可能会出现选择错误
我们可以通过left join强制驱动表干预执行计划。
如何在任务判断一条连接语句中,谁是驱动表

mysql>select count(*) from city where city.population<100000; mysql> desc select * from city join country on city.countrycode=country.code where city.population<100000 and country.SurfaceArea(国土面积 )>10000000;
b. 如何人为判断一条连接语句中,谁是驱动表 (工作中常用)
mysql> select count(*) from country where country.SurfaceArea>10000000; +----------+ | count(*) | +----------+ | 2 | +----------+ 1 row in set (0.00 sec) mysql> select count(*) from city where city.population<100000 ; +----------+ | count(*) | +----------+ | 517 | +----------+
补充: 如果 where后的列中都有索引,会选择结果集小的作为驱动表.
c. 压测.
mysql> desc select a.name, b.name,a.countrycode,a.population from city as a join country as b on a.countrycode=b.code where a.population<100;
f. const(system)
mysql> desc select * from city where id=1;
10.6 key_len详解
a.介绍
(联合)索引覆盖长度
idx(a,b,c) ------->a(10) b(20) c(30)
b.如何计算索引列的key_len
key_len和每个列的最大预留长度(字节)有关。
| 数据类型 | utf8mb4 | 没有 not null |
|---|---|---|
| tinyint | 1 | 1 |
| int | 4 | 1 |
| char(n) | 4*n | 1 |
| varchar(n) | 4*n+2 | 1 |
mysql> desc select * from t100w where num=10 and k1 ='aa' and k2='bb';
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | t100w | NULL | ref | idx_k2,idx | idx_k2 | 17 | const | 1 | 5.00 | Using where | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ 1 row in set, 1 warning (1.65 sec)
c.联合索引应用细节
idx(a,b,c)
完全覆盖
| a= | and b= | and c= |
|---|---|---|
| a= | and c= | and b= 等值打乱顺序的 |
| a= | and b= | and c范围 |
| a= | anb b字符范围 | and c= |
部分覆盖
| a= | and b= | |
|---|---|---|
| a= | ||
| a= | and b= | and c= |
| a= | and b数字范围 | and c= |
完全不覆盖 bc ----> bc b
b
c
bc
cb
优化案例: idx(k1,num,k2)
mysql> desc select * from t100w where k1='Vs' and num<27779 and k2='mnij'
优化方案: 修改索引为idx(k1,k2,num)
mysql> desc select * from t100w where k1='Vs' and k2='mnij'
10.7 extra
using index 使用了索引覆盖扫描
using where 使用where回表扫描数据行,说明目标表的索引没有设计好.
a. table ----> 获取到出问题的表
b. 看原始查询语句中的where条件列
c. 查询列的索引情况-----> show index from t1;
d. 按需优化索引.
using filesort 使用了额外排序.
a. table ---->获取到出问题的表
b. 查看原始语句中的: order by group by distinct
c. 查看列的索引情况
d. 按需优化索引.
优化案例:
mysql> desc select *from city where countrycode='CHN' order by population;
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+----------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+----------------+
mysql> show index from city;
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| city | 0 | PRIMARY | 1 | ID | A | 4188 | NULL | NULL | | BTREE | | | YES | NULL |
| city | 1 | CountryCode | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
mysql> alter table city add index idx(population);
mysql> desc select *from city where countrycode='CHN' order by population;
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+----------------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+----------------+
mysql> alter table city add index idx_c_p(countrycode,population);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc select *from city where countrycode='CHN' order by population;
+----+-------------+-------+------------+------+---------------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | city | NULL | ref | CountryCode,idx_c_p | idx_c_p | 3 | const | 363 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------------+---------+---------+-------+------+----------+-------+
查看冗余索引
mysql> select table_schema,table_name , redundant_index_name , redundant_index_columns from sys.schema_redundant_indexes; using temp --->
a. 条件范围是不是过大.
b. having order by 额外排序
c. 子查询
大几率开发需要改写语句了.
乱序查询
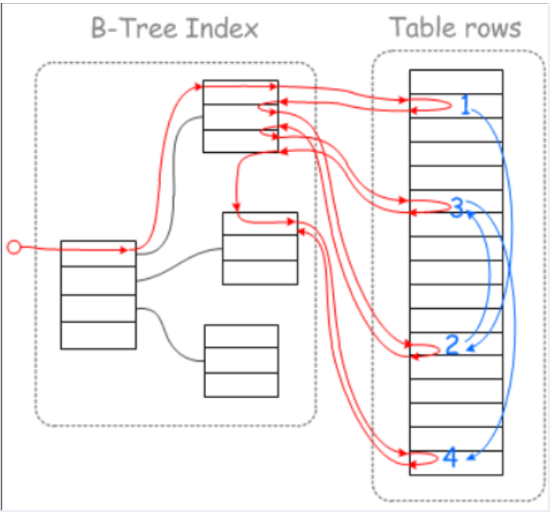
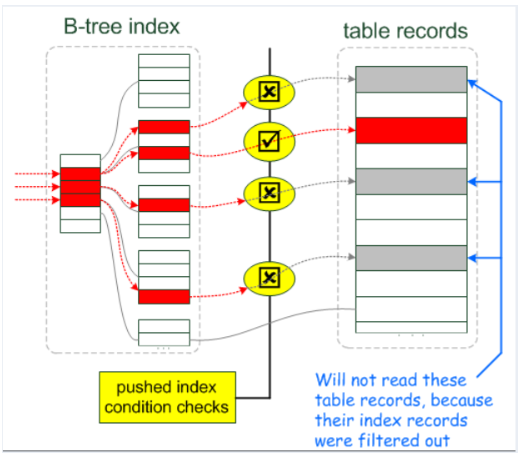
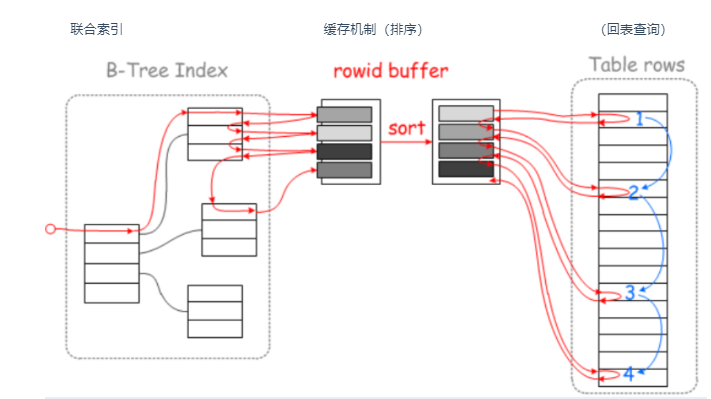
辅助索引查找过程
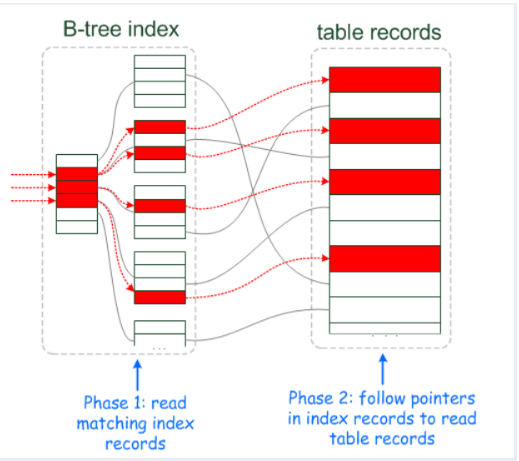
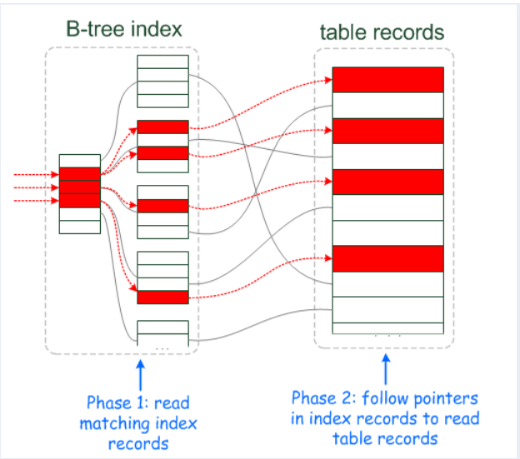
11.扩展项: 关于索引的优化器算法:ICP \ MRR
11.1 ICP : Index Condition Pushdown
优化器算法: a. 查询优化器算法:
mysql> select @@optimizer_switch;
b.设置优化器算法:
mysql> set global optimizer_switch='index_condition_pushdown=off';
hits方式: https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html 配置文件: my.cnf 例子 :
mysql> set global optimizer_switch='index_condition_pushdown=off'; mysql> desc select * from t100w where k1='Vs' and num<27779 and k2='mnij'; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t100w | NULL | range | idx | idx | 14 | NULL | 29 | 10.00 | Using where | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> set global optimizer_switch='index_condition_pushdown=on'; mysql> desc select * from t100w where k1='Vs' and num<27779 and k2='mnij'; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | t100w | NULL | range | idx | idx | 14 | NULL | 29 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) 压测: a. 开ICP 20000次语句压测 索引顺序不调整 mysqlslap --defaults-file=/etc/my.cnf \ --concurrency=100 --iterations=1 --create-schema='test' \ --query=" select * from t100w where k1='Vs' and num<27779 and k2='mnij'" engine=innodb \ --number-of-queries=20000 -uroot -p123 -verbose 4.580 seconds 4.569 seconds 4.431 seconds 4.433 seconds 4.391 seconds
b. 关 ICP 20000次语句压测 索引顺序不调整
5.327
5.516
5.267
5.330
5.293 seconds
c. 索引顺序优化 压测
4.251
4.143
11.2 MRR
MRR(Mean reciprocal rank)是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
https://dev.mysql.com/doc/refman/8.0/en/mrr-optimization.html
12.索引应用规范
业务
1.产品的功能
2.用户的行为
"热"查询语句 --->较慢--->slowlog
"热"数据
12.1 建立索引的原则(DBA运维规范)
(1) 必须要有主键,业务无关列。 (2) 经常做为where条件列 order by group by join on, distinct 的条件(业务:产品功能+用户行为) (3) 最好使用唯一值多的列作为索引列,如果索引列重复值较多,可以考虑使用联合索引 (4) 列值长度较长的索引列,我们建议使用前缀索引. mysql> select count(distinct left(name,19)) from city; (5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit(xxxxx) (6) 索引维护要避开业务繁忙期,建议用pt-osc。 (7) 联合索引最左原则
12.2 不走索引的情况(开发规范)
12.2.1 没有查询条件,或者查询条件没有建立索引
select * from t1 ; select * from t1 where id=1001 or 1=1;
作业: SQL审核和审计. yearning.io github, inception
12.2.2 查询结果集是原表中的大部分数据,应该是15-25%以上。
查询的结果集,超过了总数行数25%,优化器觉得就没有必要走索引了。 MySQL的预读功能有关。
可以通过精确查找范围,达到优化的效果。
1000000
500000 and
12.2.3 索引本身失效,统计信息不真实(过旧)
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
一般是删除重建
现象:
面试题
有一条select语句平常查询时很快,突然有一天很慢,会是什么原因 select? --->索引失效,统计数据不真实
innodb_index_stats 索引统计信息 innodb_table_stats 表的统计信息 mysql> ANALYZE TABLE world.city;
12.2.4 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例子:
错误的例子:select * from test where id-1=9;
正确的例子:select * from test where id=10;
算术运算
函数运算
子查询
12.2.5 隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
这样会导致索引失效. 错误的例子
mysql> alter table tab add index inx_tel(telnum); Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc tab; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | telnum | varchar(20) | YES | MUL | NULL | | +--------+-------------+------+-----+---------+-------+ 3 rows in set (0.01 sec) mysql> select * from tab where telnum='1333333'; +------+------+---------+ | id | name | telnum | +------+------+---------+ | 1 | a | 1333333 | +------+------+---------+ 1 row in set (0.00 sec) mysql> select * from tab where telnum=1333333; +------+------+---------+ | id | name | telnum | +------+------+---------+ | 1 | a | 1333333 | +------+------+---------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum='1333333'; +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | 1 | SIMPLE | tab | ref | inx_tel | inx_tel | 63 | const | 1 | Using index condition | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum=1333333; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | 2 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum=1555555; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | 2 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum='1555555'; +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | 1 | SIMPLE | tab | ref | inx_tel | inx_tel | 63 | const | 1 | Using index condition | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ 1 row in set (0.00 sec) mysql> desc select * from b where telnum=110; mysql> desc select * from b where telnum='110';
12.2.6 < > ,not in 不走索引(辅助索引)
EXPLAIN SELECT * FROM teltab WHERE telnum <> '110';
EXPLAIN SELECT * FROM teltab WHERE telnum NOT IN ('110','119');
mysql> select * from tab where telnum <> '1555555';
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| 1 | a | 1333333 |
+------+------+---------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum <> '1555555';
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit
or或in 尽量改成union
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119');
改写成:
EXPLAIN SELECT * FROM teltab WHERE telnum='110'
UNION ALL
SELECT * FROM teltab WHERE telnum='119
12.2.7 like "%_" 百分号在最前面不走
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%' 走range索引扫描 EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110' 不走索引 %linux%类的搜索需求,可以使用elasticsearch+mongodb 专门做搜索服务的数据库产品
Optimizer: 查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。就是优化客户端请求的 query(sql语句) ,根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果
他使用的是“选取-投影-联接”策略进行查询。 用一个例子就可以理解: select uid,name from user where gender = 1; 这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤 这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤 将这两个查询条件联接起来生成最终查询结果
Cache和Buffer: 查询缓存
他的主要功能是将客户端提交 给MySQL 的 Select 类 query 请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做 一个对应。该 Query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该 query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
存储引擎接口
存储引擎接口模块可以说是 MySQL 数据库中最有特色的一点了。目前各种数据库产品中,基本上只有 MySQL 可以实现其底层数据存储引擎的插件式管理。这个模块实际上只是 一个抽象类,但正是因为它成功地将各种数据处理高度抽象化,才成就了今天 MySQL 可插拔存储引擎的特色。
可以看出,MySQL区别于其他数据库的最重要的特点就是其插件式的表存储引擎。MySQL插件式的存储引擎架构提供了一系列标准的管理和服务支持,这些标准与存储引擎本身无关,可能是每个数据库系统本身都必需的,如SQL分析器和优化器等,而存储引擎是底层物理结构的实现,每个存储引擎开发者都可以按照自己的意愿来进行开发。 注意:存储引擎是基于表的,而不是数据库。
查询的执行路径
1> 客户端向 MySQL 服务器发送一条查询请求
2> 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段
3> 服务器进行 SQL解析、预处理、再由优化器生成对应的执行计划
4> MySQL 根据执行计划,调用存储引擎的 API来执行查询
5> 将结果返回给客户端,同时缓存查询结果
