Linux文本三剑客总结
Linux文本处理三剑客
grep
文本过滤(模式:pattern)工具 grep, egrep, fgrep(不支持正则表达式搜索)
grep
grep: Global search REgular expression and Print out the line
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
grep [OPTIONS] PATTERN [FILE...]
grep root /etc/passwd
grep "$USER" /etc/passwd
grep '$USER' /etc/passwd
grep `whoami` /etc/passwd
grep命令选项
--color=auto: 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系
grep –e ‘cat ’ -e ‘dog’ file
-w 匹配整个单词
-E 使用ERE
-F 相当于fgrep,不支持正则表达式
-f file 根据模式文件处理
正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
程序支持:grep,sed,awk,vim, less,nginx,varnish等
分两类:
基本正则表达式:BRE
扩展正则表达式:ERE
grep -E, egrep
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块
PCRE(Perl Compatible Regular Expressions)
元字符分类:字符匹配、匹配次数、位置锚定、分组
man 7 regex
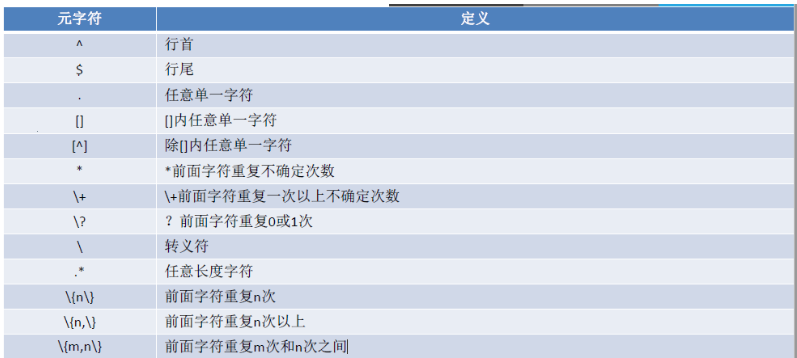
基本正则表达式元字符 字符匹配:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符
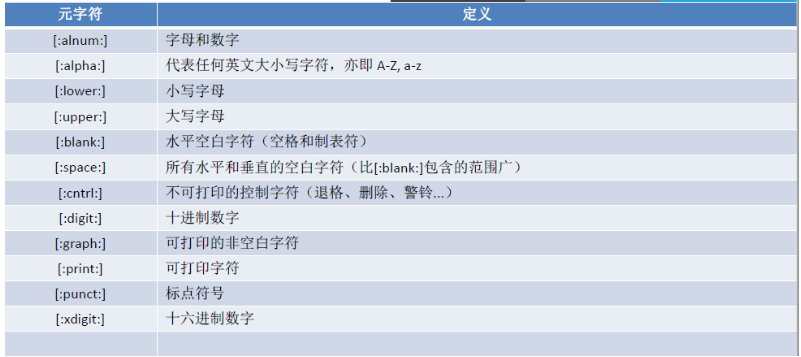
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母 [:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
匹配前面的字符任意次,包括0次
贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体处理,如:\(root\)\+
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例: \(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
或者:\|
示例:a\|b a或b
C\|cat C或cat
\(C\|c\)at Cat或cat
练习题:
1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
[root@shell ~]# grep -in '^s' /proc/meminfo [root@shell ~]# cat /proc/meminfo |grep "^[sS]" cat /proc/meminfo | grep '^[sS]' # 匹配开头[sS]任意单个字符 cat /proc/meminfo | grep '^[s\|S]' # 匹配开头s或者S grep '^s\|^S' /proc/meminfo # 匹配开头s或者开头S grep -i '^s' /proc/meminfo # 匹配开头s忽略大小写
2、显示/etc/passwd文件中不以/bin/bash结尾的行
[root@shell ~]#cat /etc/passwd |grep -nv “/bin/bash$”
3、显示用户rpc默认的shell程序
cat /etc/passwd | grep -w '^root' | grep -o '[^/]\+$'
4、找出/etc/passwd中的两位或三位数
grep "\b[0-9]\{2,3\}\b" /etc/passwd # \b 词首锚定,\b 词尾锚定
grep '\<[0-9]\{2,3\}\>' /etc/passwd # \< 词首锚定,\> 词尾锚定
grep -w '[0-9]\{2,3\}' /etc/passwd
egrep -w '[0-9]{2,3}' /etc/passwd
5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非空白字符的行
grep '^[[:space:]]\+[^[:graph:]]' /etc/grub2.cfg egrep '^[[:space:]]+[^[:graph:]]' /etc/grub2.cfg
6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
netstat -tan | grep 'LISTEN[[:space:]]*$'
7、显示CentOS7上所有UID小于1000以内的用户名和UID
cut -d: -f 1,3 /etc/passwd | grep '\<[0-9]\{0,3\}\>' # 匹配任意数字至少0个字符,至多3个字符
cut -d: -f 1,3 /etc/passwd | grep '\b[0-9]\{0,3\}\b'
cut -d: -f 1,3 /etc/passwd | grep -w '[0-9]\{0,3\}'
cut -d: -f 1,3 /etc/passwd | egrep -w '[0-9]{0,3}'
cut -d: -f 1,3 /etc/passwd | tr : ' ' | awk '{if($2<1000)print $1,$2}'| tr ' ' :
8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找出/etc/passwd用户名和shell同名的行
useradd bash && useradd testbash && useradd basher && useradd sh && useradd -s /sbin/nologin nologin
cat /etc/passwd | grep '\(^[a-zA-Z0-9]\+\>\).*\<\1$'
cat /etc/passwd | egrep '(^[[:alnum:]]+\>).*\<\1$'
# 匹配以任意数字或字母开头的单词至少一次,放入内置变量 \1,再匹配任意字符任意次直到结尾前一个单词是 \1
9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
df | grep ^/dev | grep -o '[0-9]\{1,\}%'|sort -nr # -o 只显示匹配的字符串
df | grep ^/dev | egrep -o '[0-9]{1,}%'|sort -nr # {1,} 匹配前一个字符至少1次
egrep
egrep及扩展的正则表达式
egrep = grep -E egrep [OPTIONS] PATTERN [FILE...] 扩展正则表达式的元字符: 字符匹配: . 任意单个字符 [] 指定范围的字符 [^] 不在指定范围的字符
扩展正则表达式
次数匹配:
.匹配前面字符任意次
? 0或1次
+ 1次或多次
{m} 匹配m次
{m,n} 至少m,至多n次
扩展正则表达式 位置锚定:
^ 行首 $ 行尾 \<, \b 语首 \>, \b 语尾 分组: () 后向引用:\1, \2, ... 或者: a|b a或b C|cat C或cat (C|c)at Cat或cat
练习题:
1、显示三个用户root、mage、wang的UID和默认shell
cut -d: -f1,3,7 /etc/passwd | grep -w '^\(root\|mage\|wang\)' cut -d: -f1,3,7 /etc/passwd | egrep -w '^(root|mage|wang)'
2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
egrep -o '^.*\(\)' /etc/rc.d/init.d/functions grep -o '^[a-zA-Z0-9_].*()' /etc/rc.d/init.d/functions grep -o '^[[:alnum:]_].*()' /etc/rc.d/init.d/functions
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
echo /etc/rc.d/init.d/functions | egrep -o '[^/]+$'
# 从最后一个字符开始向前匹配,排除/至少一次后停止
echo /etc/rc.d/init.d/functions | egrep -ow '[[:alnum:]]+$'
# 从最后一个字符开始向前匹配,匹配到任意字母或数字组成的单词至少一次后停止,基名不能有特殊字符4、使用egrep取出上面路径的目录名
echo /etc/rc.d/init.d/functions | egrep -o '.*/\<' root@shell ~]# echo /etc/rc.d/init.d/functions | egrep -o '.*/\b' /etc/rc.d/init.d/ [root@shell ~]# echo /etc/rc.d/init.d/functions | grep -o '.*/\+\b' /etc/rc.d/init.d/
5、统计last命令中以root登录的每个主机IP地址登录次数
last | grep '^root' | awk '{print $1,$3}'| grep -v '[a-z]$'| sort | uniq -c
# 筛选root登陆;筛选只显示用户和主机IP;排除没有主机IP的行(不显示以任意字母结尾的行);排序;统计
last | grep ^root | egrep -o "([0-9]{1,3}\.){3}[0-9]{1,3}" | sort | uniq -c
# 筛选root登陆;筛选只显示主机IP;排序;统计
6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
echo {1..255} | egrep -wo '[0-9]' | tr "\n" " " ; echo
echo {1..255} | egrep -wo '[1-9][0-9]' | tr "\n" " " ; echo
echo {1..255} | egrep -wo '1[0-9]{2}' | tr "\n" " " ; echo
echo {1..255} | egrep -wo '2[0-4][0-9]' | tr "\n" " " ; echo
echo {1..255} | egrep -wo '25[0-5]' | tr "\n" " " ; echo
7、显示ifconfig命令结果中所有IPv4地址
ifconfig | egrep -o "\<(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4]0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>"
8、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
echo "welcome to magedu linux" | tr -d " " | egrep -o "." | sort | uniq -c | sort -nr
# 删除空格;拆分字符到每行(只显示匹配到的任意字符的行);排序;去重;按第一行数字降序排序
sed
stream editor,文本编辑工具
Stream EDitor, 行编辑器 sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。 功能:主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等 参考: http://www.gnu.org/software/sed/manual/sed.html
sed工具
用法:
sed [option]... 'script' inputfile...
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印 -e 多点编辑 -f /PATH/SCRIPT_FILE 从指定文件中读取编辑脚本 -r 支持使用扩展正则表达式 -i.bak 备份文件并原处编辑 script:
'地址命令'
地址定界:
(1) 不给地址:对全文进行处理 (2) 单地址: #:指定的行,$:最后一行 /pattern/:被此处模式所能够匹配到的每一行 (3) 地址范围: #,# #,+# /pat1/,/pat2/ #,/pat1/ (4) ~:步进 1~2 奇数行 2~2 偶数行
编辑命令:
d 删除模式空间匹配的行,并立即启用下一轮循环 p 打印当前模式空间内容,追加到默认输出之后 a [\]text 在指定行后面追加文本,支持使用\n实现多行追加 i [\]text 在行前面插入文本 c [\]text 替换行为单行或多行文本 w /path/file 保存模式匹配的行至指定文件 r /path/file 读取指定文件的文本至模式空间中匹配到的行后 = 为模式空间中的行打印行号 ! 模式空间中匹配行取反处理 s/// 查找替换,支持使用其它分隔符,s@@@,s### 替换标记: g 行内全局替换 p 显示替换成功的行 w /PATH/FILE 将替换成功的行保存至文件中
sed示例
sed ‘2p’ /etc/passwd
sed -n ‘2p’ /etc/passwd
sed -n ‘1,4p’ /etc/passwd
sed -n ‘/root/p’ /etc/passwd
sed -n ‘2,/root/p’ /etc/passwd 从2行开始
sed -n ‘/^$/=’ file 显示空行行号
sed -n -e ‘/^$/p’ -e ‘/^$/=’ file
Sed‘/root/a\superman’ /etc/passwd行后
sed ‘/root/i\superman’ /etc/passwd 行前
sed ‘/root/c\superman’ /etc/passwd 代替行
sed ‘/^$/d’ file
sed ‘1,10d’ file
nl /etc/passwd | sed ‘2,5d’
nl /etc/passwd | sed ‘2a tea’
sed 's/test/mytest/g' example
sed –n ‘s/root/&superman/p’ /etc/passwd 单词后
sed –n ‘s/root/superman&/p’ /etc/passwd 单词前
sed -e ‘s/dog/cat/’ -e ‘s/hi/lo/’ pets
sed –i.bak ‘s/dog/cat/g’ pets
sed [options] 'script' inputfile...
sed [options] -f scriptfile file(s)
-e<script>,--expression=<script> 以指定的 script 来处理输入的文件,用于顺序执行多条命令
-f<script 文件>,--file=<script 文件> 以指定的 script 文件来处理输入的文件
-n,--quiet,——silent 取消自动打印模式空间
-i[SUFFIX], --in-place[=SUFFIX] 直接编辑文件(如果提供后缀,则进行备份)
-r 使用扩展正则表达式
sed元字符集
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
* 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed。
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\< 匹配单词的开始,如:/\<love/匹配包含以love开头的单词的行。
\> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行。
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行。
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行。
sed地址定界:默认对全文进行处理
# 指定行
$ 最后一行
/pattern/ 被 pattern 匹配到的每一行
#,# 区间
#,+# 区间 +#=#+1
/pat1/,/pat2/
#,/pat1/
first~step 步进(stepping) 先定位 first 所在行,然后每经过step行再定位一次
1~2 奇数行
2~2 偶数行
first,~N 从 first 所在的行至往后第一个可以被N整除的行
GNU扩展的sed,支持特殊序列(special sequence),它由一个反斜线和一个字母组成:
\L:将replacement替换成小写直到遇到\U或者\E。
\l:将下一个字符替换成小写。
\U:将replacement替换成大写直到遇到\L或者\E。
\u:将下一个字符替换成大写。
\E:停止\U或者\L带来的大小写转换功能。
Examples:
sed '2p' /etc/passwd 打印文件内容,并重复打印文件第2行
sed -n '2p' /etc/passwd 只打印文件第2行
sed -n '1,4p' /etc/passwd 只打印文件第1到4行
sed -n '/root/p' /etc/passwd 只打印文件匹配 root 的行
sed -n '2,/root/p' /etc/passwd 只打印文件从第2行开始到匹配 root 的行
sed -n '/^$/=' file 显示空行行号(只打印文件匹配 ^$ 的行及其行号)
sed -n -e '/^$/p' -e '/^$/=' file 只打印文件空行和空行及其行号
sed '/root/a superman' /etc/passwd 匹配 root 的行后追加一行 superman
sed '/root/i superman' /etc/passwd 匹配 root 的行前追加一行 superman
sed '/root/c superman' /etc/passwd 用 superman 代替匹配 root 的行
nl /etc/passwd | sed '2a tea' 文件第2行后追加一行 tea
sed -n 's/root/&superman/p' /etc/passwd 只打印匹配 root 单词后追加 superman 单词的行
sed -n 's/root/superman&/p' /etc/passwd 只打印匹配 root 单词前追加 superman 单词的行
sed -i.bak 's/dog/cat/g' file 备份.bak 后,在原文件中替换并保存
sed -i.bak 's/dog/cat/g' file 备份.bak 后,在原文件中替换并保存
已匹配字符串标记&
sed 's/\w\+/[&]/g' file # \w\+ 匹配每一个单词
替换操作:s命令
sed 's/book/books/' file
sed -n 's/test/TEST/p' file # -n 抑制自动打印原文本,p 打印处理后的行。只打印发生替换的行
删除操作:d命令
sed '/^$/d' file 删除空白行
sed '/^test/d' file 删除文件中所有开头是test的行
sed '2d' file 删除文件的第2行
sed '$d' file 删除文件最后一行
sed '2,$d' file 删除文件的第2行到末尾所有行
地址定界:,(逗号)
sed -n '/test/,/check/p' file 所有在模板test和check所确定的范围内的行都被打印
sed -n '5,/^test/p' file 打印从第5行开始到第一个包含以test开始的行之间的所有行:
sed '/test/,/west/s/$/aaa/' file 模板test和west之间的行,每行的末尾用字符串aaa替换
模式空间:
sed '1!G;h;$!d' FILE ; sed -n '1!G;h;$p' FILE 倒序输出(模拟tac)
sed 'N;D' FILE ; sed '$!d' FILE 输出文件最后一行
sed '$!N;$!D' FILE 输出文件最后2行
sed 'G' FILE 给每行结尾添加一行空行
sed 'g' FILE 将文件全部行替换成空行
sed 'N;s/\n//g' FILE 将文件的n和n+1行合并为一行,n为奇数行
sed ':a;N;$!ba;s/\n//g' 将文件所有行合为一行
sed '/^$/d;G' FILE 删除空白行后,给每行结尾添加一行空行
sed 'n;d' FILE 删除偶数行
sed -n 'p;n' test.txt #奇数行
sed -n 'n;p' test.txt #偶数行
sed '/test/{ n; s/aa/bb/; }' file 匹配test,移动到下一行,替换aa为bb,并打印该行
打印匹配字符串的下一行
grep -A 1 SCC URFILE
sed -n '/SCC/{n;p}' URFILE
awk '/SCC/{getline; print}' URFILE
sed ':a;N;$!ba;s/\n//g' ; sed ':a;$!N;s/\n//g;ta' 将文件所有行合为一行
:a # 建立分支标记
N # 读取下一行追加至模式空间
$!ba # 分支到脚本中带有标记的地方
s/\n//g # 替换\n为空
练习题
1、删除centos7系统/etc/grub2.cfg文件中所有以空白开头的行行首的空白字符
sed 's#[[:space:]]*##g' /etc/grub2.cfg
2、删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
sed -r s/^#[[:space:]*// /etc/fstab
3、在centos6系统/root/install.log每一行行首增加#号
sed s/^Installing/#Installing/g /root/install.log
4、在/etc/fstab文件中不以#开头的行的行首增加#号
sed -r "s/(^[^#])*/#\1/" /etc/fstab
5、处理/etc/fstab路径,使用sed命令取出其目录名和基名
基名:echo /etc/fstab | sed -r "s#^(/.*/)([^/]+/?)#\2#" 目录名:echo /etc/fstab | sed -r "s#^(/.*/)([^/]+/?)#\1#g"
6、利用sed 取出ifconfig命令中本机的IPv4地址
ifconfig ens33 |sed -n '2p' | sed -r "s/.*inet[[:space:]]*//" | sed -r "s/[[:space:]]*netmask.*//"
7、统计centos安装光盘中Package目录下的所有rpm文件的以.分隔倒数第二个字段的重复次数
ls /run/media/root/CentOS\ 7\ x86_64/Packages/ | grep -v "TBL" |sed -r "s#(.*\.([^.]+).rpm$)#\2#"
8、统计/etc/init.d/functions文件中每个单词的出现次数,并排序(用grep和sed两种方法分别实现)
grep方法:cat /etc/init.d/functions |grep -io "\<[[:alpha:]]*\>" |sort -rn |uniq -c |sort -n sed方法:sed "s/[^[:alpha:]]/\n/g" /etc/init.d/functions" | sort -rn | uniq -c |sort -n
9、将文本文件的n和n+1行合并为一行,n为奇数行
sed 'N;s/\n//'
awk
Linux上的实现gawk,文本报告生成器
awk介绍 awk:Aho, Weinberger, Kernighan,报告生成器,格式化文本输出 有多种版本:New awk(nawk),GNU awk( gawk) gawk:模式扫描和处理语言 基本用法: awk [options] 'program' var=value file… awk [options] -f programfile var=value file… awk [options] 'BEGIN{action;… }pattern{action;… }END{action;… }' file ... awk 程序可由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块,共3部分组成 program 通常是被放在单引号中 选项: -F “分隔符” 指明输入时用到的字段分隔符 -v var=value 变量赋值
awk语言
基本格式:awk [options] 'program' file…
Program:pattern{action statements;..}
pattern和action
•pattern部分决定动作语句何时触发及触发事件
BEGIN,END
•action statements对数据进行处理,放在{}内指明
print, printf
分割符、域和记录
•awk执行时,由分隔符分隔的字段(域)标记$1,$2...$n称为域标识。$0为所有域,注意:此时和shell中变量$符含义不同
•文件的每一行称为记录
•省略action,则默认执行 print $0 的操作
awk工作原理
第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
awk print格式:print item1, item2, ... 要点:
(1) 逗号分隔符
(2) 输出item可以字符串,也可是数值;当前记录的字段、变量或awk的表达式
(3) 如省略item,相当于print $0
示例:
awk '{print "hello,awk"}'
awk –F: '{print}' /etc/passwd
awk –F: ‘{print “wang”}’ /etc/passwd
awk –F: ‘{print $1}’ /etc/passwd
awk –F: ‘{print $0}’ /etc/passwd
awk –F: ‘{print $1”\t”$3}’ /etc/passwd
grep “^UUID”/etc/fstab | awk ‘{print $2,$4}’
awk变量 变量:内置和自定义变量
FS:输入字段分隔符,默认为空白字符
awk -v FS=':' '{print $1,FS,$3}’ /etc/passwd
awk –F: '{print $1,$3,$7}’ /etc/passwd
OFS:输出字段分隔符,默认为空白字符
awk -v FS=‘:’ -v OFS=‘:’ '{print $1,$3,$7}’ /etc/passwd
RS:输入记录分隔符,指定输入时的换行符
awk -v RS=' ' ‘{print }’ /etc/passwd
ORS:输出记录分隔符,输出时用指定符号代替换行符
awk -v RS=' ' -v ORS='###'‘{print }’ /etc/passwd
NF:字段数量
awk -F:‘{print NF}’ /etc/fstab 引用变量时,变量前不需加$
awk -F:‘{print $(NF-1)}' /etc/passwd
NR:记录号
awk ‘{print NR}’ /etc/fstab ; awk END‘{print NR}’ /etc/fstab
FNR:各文件分别计数,记录号
awk '{print FNR}' /etc/fstab /etc/inittab
FILENAME:当前文件名
awk '{print FILENAME}’ /etc/fstab
ARGC:命令行参数的个数
awk '{print ARGC}’ /etc/fstab /etc/inittab
awk ‘BEGIN {print ARGC}’ /etc/fstab /etc/inittab
ARGV:数组,保存的是命令行所给定的各参数
awk ‘BEGIN {print ARGV[0]}’ /etc/fstab /etc/inittab
awk ‘BEGIN {print ARGV[1]}’ /etc/fstab /etc/inittab
自定义变量(区分字符大小写)
(1) -v var=value
(2) 在program中直接定义
示例:
awk -v test='hello gawk' '{print test}' /etc/fstab
awk -v test='hello gawk' 'BEGIN{print test}'
awk 'BEGIN{test="hello,gawk";print test}'
awk -F:‘{sex=“male”;print $1,sex,age;age=18}’ /etc/passwd
cat awkscript
{print script,$1,$2}
awk -F: -f awkscript script=“awk” /etc/passwd
printf命令
格式化输出:printf “FORMAT”, item1, item2, ...
(1) 必须指定FORMAT
(2) 不会自动换行,需要显式给出换行控制符,\n
(3) FORMAT中需要分别为后面每个item指定格式符
格式符:与item一一对应
%c:显示字符的ASCII码
%d, %i:显示十进制整数
%e, %E:显示科学计数法数值
%f:显示为浮点数
%g, %G:以科学计数法或浮点形式显示数值
%s:显示字符串
%u:无符号整数
%%:显示%自身
修饰符
#[.#] 第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f
- 左对齐(默认右对齐) %-15s
+ 显示数值的正负符号 %+d
printf示例
awk -F: ‘{printf "%s",$1}’ /etc/passwd
awk -F: ‘{printf "%s\n",$1}’ /etc/passwd
awk -F: '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
awk -F:‘ {printf "Username: %s\n",$1}’ /etc/passwd
awk -F: ‘{printf “Username: %s,UID:%d\n",$1,$3}’ /etc/passwd
awk -F: ‘{printf "Username: %15s,UID:%d\n",$1,$3}’ /etc/passwd
awk -F: ‘{printf "Username: %-15s,UID:%d\n",$1,$3}’ /etc/passwd
操作符
算术操作符:
x+y, x-y, x*y, x/y, x^y, x%y
- x:转换为负数
+x:将字符串转换为数值
字符串操作符:没有符号的操作符,字符串连接
赋值操作符:
=, +=, -=, *=, /=, %=, ^=,++, --
下面两语句有何不同
•awk ‘BEGIN{i=0;print ++i,i}’
•awk ‘BEGIN{i=0;print i++,i}’
操作符
比较操作符:
==, !=, >, >=, <, <=
模式匹配符:
~:左边是否和右边匹配,包含
!~:是否不匹配
示例:
awk -F: '$0 ~ /root/{print $1}‘ /etc/passwd
awk '$0~“^root"' /etc/passwd
awk '$0 !~ /root/‘ /etc/passwd
awk -F: ‘$3==0’ /etc/passwd
逻辑操作符:与&&,或||,非!
示例:
•awk -F: '$3>=0 && $3<=1000 {print $1}' /etc/passwd
•awk -F: '$3==0 || $3>=1000 {print $1}' /etc/passwd
•awk -F: ‘!($3==0) {print $1}' /etc/passwd
•awk -F: ‘!($3>=500) {print $3}’ /etc/passwd
条件表达式(三目表达式)
selector?if-true-expression:if-false-expression
•示例:
awk -F: '{$3>=1000?usertype="Common User":usertype=" SysUser";printf "%15s:%-s\n",$1,usertype}' /etc/passwd
PATTERN:根据pattern条件,过滤匹配的行,再做处理
(1)如果未指定:空模式,匹配每一行
(2) /regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来
awk '/^UUID/{print $1}' /etc/fstab
awk '!/^UUID/{print $1}' /etc/fstab
(3) relational expression: 关系表达式,结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值
示例:
awk -F: 'i=1;j=1{print i,j}' /etc/passwd
awk ‘!0’ /etc/passwd ; awk ‘!1’ /etc/passwd
Awk -F: '$3>=1000{print $1,$3}' /etc/passwd
awk -F: '$3<1000{print $1,$3}' /etc/passwd
awk -F: '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd
awk -F: '$NF ~ /bash$/{print $1,$NF}' /etc/passwd
awk PATTERN
line ranges:行范围
startline,endline:/pat1/,/pat2/ 不支持直接给出数字格式
awk -F: ‘/^root\>/,/^nobody\>/{print $1}' /etc/passwd
awk -F: ‘(NR>=10&&NR<=20){print NR,$1}' /etc/passwd
BEGIN/END模式
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次
awk -F : ‘BEGIN {print “USER USERID”} {print $1“:”$3}
END{print “END FILE"}' /etc/passwd
awk -F : '{print "USER USERID“;print $1":"$3} END{print "END FILE"}' /etc/passwd
awk -F: 'BEGIN{print " USER UID \n--------------- "}{print $1,$3}' /etc/passwd
awk -F: ‘BEGIN{print “ USER UID \n--------------- ”}{print $1,$3}’END{print “==============”} /etc/passwd
seq 10 | awk 'i=0'
seq 10 | awk 'i=1'
seq 10 | awk 'i=!i'
seq 10 | awk '{i=!i;print i}'
seq 10 | awk ‘!(i=!i)'
seq 10 |awk -v i=1 'i=!i'
awk action 常用的action分类
(1) Expressions:算术,比较表达式等
(2) Control statements:if, while等
(3) Compound statements:组合语句
(4) input statements
(5) output statements:print等
awk控制语句
{ statements;… } 组合语句
if(condition) {statements;…}
if(condition) {statements;…} else {statements;…}
while(conditon) {statments;…}
do {statements;…} while(condition)
for(expr1;expr2;expr3) {statements;…}
break
continue
delete array[index]
delete array
exit
awk控制语句if-else 语法:if(condition){statement;…}[else statement] if(condition1){statement1}else if(condition2){statement2}else{statement3} 使用场景:对awk取得的整行或某个字段做条件判断 示例:
awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd
awk -F: '{if($NF=="/bin/bash") print $1}' /etc/passwd
awk '{if(NF>5) print $0}' /etc/fstab
awk -F: '{if($3>=1000) {printf "Common user: %s\n",$1} else {printf "root or Sysuser: %s\n",$1}}' /etc/passwd
awk -F: '{if($3>=1000) printf "Common user: %s\n",$1; else printf "root or Sysuser: %s\n",$1}' /etc/passwd
df -h|awk -F% '/^\/dev/{print $1}'|awk '$NF>=80{print $1,$5}‘
awk ‘BEGIN{ test=100;if(test>90){print “very good“}
else if(test>60){ print ”good”}else{print “no pass”}}’
while循环 语法:while(condition){statement;…} 条件“真”,进入循环;条件“假”,退出循环 使用场景: 对一行内的多个字段逐一类似处理时使用 对数组中的各元素逐一处理时使用 示例:
awk '/^[[:space:]]*linux16/{i=1;while(i<=NF)
{print $i,length($i); i++}}' /etc/grub2.cfg
awk ‘/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=10) {print $i,length($i)}; i++}}’ /etc/grub2.cfg
[root@shell ~]# echo I am oldboy teacher welcome to oldboy training class|awk '{for(i=1;i<=NF;i++){if (length($i)<=6) {print $i}}}'
I
am
oldboy
to
oldboy
class
do-while循环
语法:do {statement;…}while(condition)
意义:无论真假,至少执行一次循环体
示例:
awk 'BEGIN{ total=0;i=0;do{ total+=i;i++;}while(i<=100);print total}’
for循环
语法:for(expr1;expr2;expr3) {statement;…}
常见用法:
for(variable assignment;condition;iteration process)
{for-body}
特殊用法:能够遍历数组中的元素
语法:for(var in array) {for-body}
示例:
awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg
性能比较
time (awk 'BEGIN{ total=0;for(i=0;i<=10000;i++){total+=i;};print total;}')
time(total=0;for i in {1..10000};do total=$(($total+i));done;echo $total)
time(for ((i=0;i<=10000;i++));do let total+=i;done;echo $total)
time(seq –s ”+” 10000|bc)
switch语句
语法:switch(expression) {case VALUE1 or /REGEXP/: statement1; case VALUE2 or /REGEXP2/: statement2; ...; default: statementn}
break和continue
awk ‘BEGIN{sum=0;for(i=1;i<=100;i++)
{if(i%2==0)continue;sum+=i}print sum}'
awk ‘BEGIN{sum=0;for(i=1;i<=100;i++)
{if(i==66)break;sum+=i}print sum}'
break [n]
continue [n]
next:
提前结束对本行处理而直接进入下一行处理(awk自身循环)
awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd
awk数组 关联数组:array[index-expression] index-expression:
(1) 可使用任意字符串;字符串要使用双引号括起来
(2) 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”
(3) 若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
示例:
weekdays["mon"]="Monday"
awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";
print weekdays["mon"]}‘
awk '!line[$0]++' dupfile
awk '{!line[$0]++;print $0, line[$0]}' dupfile
若要遍历数组中的每个元素,要使用for循环
for(var in array) {for-body}
注意:var会遍历array的每个索引
示例: awk‘BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday"; for(i in weekdays) {print weekdays[i]}}'
netstat -tan | awk '/^tcp/{state[$NF]++}
END{for(i in state) { print i,state[i]}}'
awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log
数值处理:
rand():返回0和1之间一个随机数
awk 'BEGIN{srand(); for (i=1;i<=10;i++)print int(rand()*100) }'
字符串处理:
length([s]):返回指定字符串的长度
sub(r,s,[t]):对t字符串搜索r表示模式匹配的内容,并将第一个匹配内容替换为s
echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)'
echo "2008:08:08 08:08:08" | awk '{sub(/:/,"-",$1);print $0}'
•gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表示的内容
echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)'
echo "2008:08:08 08:08:08" | awk '{gsub(/:/,"-",$0);print $0}'
•split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,…
netstat -tn | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}
END{for (i in count) {print i,count[i]}}’
数值处理:
rand():返回0和1之间一个随机数
awk 'BEGIN{srand(); for (i=1;i<=10;i++)print int(rand()*100) }'
字符串处理:
•length([s]):返回指定字符串的长度
•sub(r,s,[t]):对t字符串搜索r表示模式匹配的内容,并将第一个匹配内容替换为s
echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)'
echo "2008:08:08 08:08:08" | awk '{sub(/:/,"-",$1);print $0}'
•gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表示的内容
echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)'
echo "2008:08:08 08:08:08" | awk '{gsub(/:/,"-",$0);print $0}'
•split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,…
netstat -tn | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}
END{for (i in count) {print i,count[i]}}’
awk函数 自定义函数格式:
function name ( parameter, parameter, ... ) {
statements
return expression
}
示例:
cat fun.awk
function max(x,y) {
x>y?var=x:var=y
return var
}
BEGIN{a=3;b=2;print max(a,b)}
awk -f fun.awk
awk中调用shell命令
system命令
空格是awk中的字符串连接符,如果system中需要使用awk中的变量可以使用空格分隔,或者说除了awk的变量外其他一律用""引用起来
awk 'BEGIN{system("hostname") }'
awk 'BEGIN{score=100; system("echo your score is " score) }'
awk脚本
将awk程序写成脚本,直接调用或执行 示例:
cat f1.awk
{if($3>=1000)print $1,$3}
awk -F: -f f1.awk /etc/passwd
cat f2.awk
#!/bin/awk –f
#this is a awk script
{if($3>=1000)print $1,$3}
chmod +x f2.awk
f2.awk –F: /etc/passwd
向awk脚本传递参数
格式:
awkfile var=value var2=value2... Inputfile
注意:在BEGIN过程中不可用。直到首行输入完成以后,变量才可用。可以通过-v 参数,让awk在执行BEGIN之前得到变量的值。命令行中每一个指定的变量都需要一个-v参数
示例:
cat test.awk
#!/bin/awk –f
{if($3 >=min && $3<=max)print $1,$3}
chmod +x test.awk
test.awk -F: min=100 max=200 /etc/passwd
awk补充
awk [options] -f progfile [var=value] file ...
awk [options] [var=value] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile 从脚本文件中读取awk命令
-F fs --field-separator=fs 指定分隔符,fs是一个字符串或正则表达式
-v var=val --assign=var=val 赋值一个自定义变量
Short options: GNU long options: (extensions)
-b --characters-as-bytes 将所有输入数据视为单字节字符(--posix覆盖这个选项)
-c --traditional 在兼容模式下运行,awk=gawk
-d[file] --dump-variables[=file] 打印已排序的全局变量列表,没有 file 打印帮助
-e 'program-text' --source='program-text' 使用 program-text 作为AWK程序源代码
-g --gen-pot 扫描并解析AWK程序,生成一个GNU.pot
可移植对象模板)格式的文件
-n --non-decimal-data 识别输入数据中的八进制和十六进制值
-r --re-interval 在正则表达式匹配中启用间隔表达式的使用
awk内置变量:
$n 当前记录的第n个字段,字段间由FS分隔
$0 完整的输入记录
ARGC 命令行参数的数目
ARGIND 命令行中当前文件的位置(从0开始算)
ARGV 包含命令行参数的数组
CONVFMT 数字转换格式(默认值为%.6g)
ENVIRON 环境变量关联数组
ERRNO 最后一个系统错误的描述
FIELDWIDTHS 字段宽度列表(用空格键分隔)
FILENAME 当前文件名
FNR 各文件分别计数的行号
FS 字段分隔符(默认是任何空格)
IGNORECASE 如果为真,则进行忽略大小写的匹配
NF 一条记录的字段的数目
NR 已经读出的记录数,就是行号,从1开始
OFMT 数字的输出格式(默认值是%.6g)
OFS 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符
ORS 输出记录分隔符(默认值是一个换行符)
RLENGTH 由match函数所匹配的字符串的长度
RS 记录分隔符(默认是一个换行符)
RSTART 由match函数所匹配的字符串的第一个位置
SUBSEP 数组下标分隔符(默认值是/034)
= += -= *= /= %= ^= **= 赋值
?: C条件表达式
|| 逻辑或
&& 逻辑与
~ 和 !~ 匹配正则表达式和不匹配正则表达式
< <= > >= != == 关系运算符
空格 连接
+ - 加,减
* / % 乘,除与求余
+ - ! 一元加,减和逻辑非
^ 求幂
++ -- 增加或减少,作为前缀或后缀
$ 字段引用
in 数组成员
条件语句
if (expression) {
statement;
statement;
... ...
}
if (expression) {
statement;
} else {
statement2;
}
if (expression) {
statement1;
} else if (expression1) {
statement2;
} else {
statement3;
}
循环语句
C语言:while、do/while、for、break、continue
Examples:
一.命令行方式调用awk
awk [-F field-separator] 'commands' input-file(s)
1 搜索/etc/passwd有root关键字的所有行
awk -F: '/root/' /etc/passwd
2 搜索/etc/passwd有root关键字的所有行,并显示对应的shell
awk -F: '/root/{print $7}' /etc/passwd
3 打印/etc/passwd 中以:为分隔符分割的每行第一项
awk -F: '{ print $1 }' /etc/passwd
4 使用","分割,-F相当于内置变量FS, 指定分隔符
awk -F, '{print $1,$2}' filename
awk 'BEGIN{FS=","} {print $1,$2}' filename
5 使用多个分隔符:先使用空格分割,然后对分割结果再使用","分割
awk -F '[ ,]' '{print $1,$2,$5}' filename
6 统计 file 行数
awk '{ sum += $1 }; END { print sum }' file
7 统计用户个数
awk '{count++;print $0;} END{print "user count is ",count}' /etc/passwd
8 行匹配语句 awk '' 只能用单引号
awk '{[pattern] action}' {filenames}
9 每行输出文本中的1、4项,按空格或TAB分割
awk '{print $1,$4}' filename
10 格式化每行输出文本中的1、4项,按空格或TAB分割
awk '{printf "%-8s %-10s\n",$1,$4}' filename
11 设置变量a=1,b=s,每行输出文本中的1项、1项+a(数字求和,非数字直接是a)、1项添加后缀b,按空格或TAB分割
awk -va=1 -vb=s '{print $1,$1+a,$1b}' filename
12 查看filename文件内第20到第30行的所有内容
awk '{if(NR>=20 && NR<=30) print $0}' filename
13 统计当前目录下文件总大小,以M为单位输出
ll |awk 'BEGIN{size=0;} {size=size+$5;} END{print "[end]size is ",size/1024/1024,"M"}'
14 显示/etc/passwd的账户,for循环遍历数组
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
15 按降序排序,筛选第二行小于70,统计总数(行数)
sort -rnk2 1.txt|awk '$2<70'|wc-l
二.shell脚本方式
#!/bin/awk -f
BEGIN{ 这里面放的是执行前的语句 }
{这里面放的是处理每一行时要执行的语句}
END {这里面放的是处理完所有的行后要执行的语句 }
三.将所有的awk命令插入一个单独文件,然后调用
awk -f awk-script-file input-file(s)
gsub函数的用法
sub匹配第一次出现的符合模式的字符串,相当于 sed 's//' 。
gsub匹配所有的符合模式的字符串,相当于 sed 's//g' 。
例如:
awk '{sub(/Mac/,"Macintosh");print}' urfile 用Macintosh替换Mac
awk '{sub(/Mac/,"MacIntosh",$1); print}' file 第一个域内用Macintosh替换Mac
把上面sub换成gsub就表示在满足条件得域里面替换所有的字符。
awk的sub函数用法:
sub函数匹配指定域/记录中最大、最靠左边的子字符串的正则表达式,并用替换字符串替换这些字符串。
如果没有指定目标字符串就默认使用整个记录。替换只发生在第一次匹配的时候。格式如下:
sub (regular expression, substitution string): sub (regular expression, substitution string, target string)
实例:
$ awk '{ sub(/test/, "mytest"); print }' testfile
$ awk '{ sub(/test/, "mytest", $1); print }' testfile
第一个例子在整个记录中匹配,替换只发生在第一次匹配发生的时候。
第二个例子在整个记录的第一个域中进行匹配,替换只发生在第一次匹配发生的时候。
如要在整个文件中进行匹配需要用到gsub
gsub函数作用如sub,但它在整个文档中进行匹配。格式如下:
gsub (regular expression, substitution string)
gsub (regular expression, substitution string, target string)
实例:
$ awk '{ gsub(/test/, "mytest"); print }' testfile
$ awk '{ gsub(/test/, "mytest", $1); print }' testfile
第一个例子在整个文档中匹配test,匹配的都被替换成mytest。
第二个例子在整个文档的第一个域中匹配,所有匹配的都被替换成mytest。
另外, 只有当记录中的域有改变的时候 ,指定0FS变量才有用, 如果记录中的域无变化, 指定OFS产生不了实际效果。
awk -F'|' -v OFS='|' '{ gsub(/[0-9]/, "", $3); print $0; }' data.txt
将把第三个域中所有数字都去掉。
另外,对于数字的匹配,可以使用十六进制。
awk -F'|' -v OFS='|' '{ gsub(/[/x30-/x39]/, "", $3); print $0; }' data.txt
基本正则表达式 BRE 元字符
字符匹配:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符
匹配次数:
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
匹配次数:
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
- 位置锚定:
定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
\w 某个单词
分组:\(\)
将一个或多个字符捆绑在一起,当作一个整体处理,如:\(root\)\+
分组括号中的模式匹配到的内容,会被正则表达式引擎记录于内部的变量中,
这些变量的命名方式为: \1, \2, \3, ...
示例:
\(string1\(string2\)\)
\1 :string1\(string2\) # 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符。
\2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
或:\|
示例:a\|b a或b
C\|cat C或cat
\(C\|c\)at Cat或ca
字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
次数匹配:
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{m} 匹配m次
{m,n} 至少m,至多n次
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{m} 匹配m次
{m,n} 至少m,至多n次
位置锚定:
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
\w 单词
分组:()
后向引用:\1, \2, ...
或:
a|b a或b
C|cat C或cat
(C|c)at Cat或cat
特殊字符集
字符集需要用 [ ] 来包含住,否则不会生效
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:] 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
* 匹配任意零个或多个字符
? 匹配任意一个字符
[0-9] 匹配任意数字
[a-z] 匹配任意小写字母
[A-Z] 匹配任意大写字母
[] 匹配中括号里任意一个字符,- 指定范围
[^] ; [!] 匹配中括号里任意字符以外的字符,取反
大括号扩展
&>>file 把 标准输出 和 标准错误 都追加重定向到file
练习题:
1、文件ip_list.txt如下格式,请提取”.magedu.com”前面的主机名部分并写入到回到该文件中 1 blog.magedu.com 2 www.magedu.com … 999 study.magedu.com
[root.CentOS 7] ~ awk -F. '{print $1}' ip-list.txt >> ip-list.txt
2、统计/etc/fstab文件中每个文件系统类型出现的次数
[root.CentOS 7] ➤ awk '/^[^#].*$/{print $3}' /etc/fstab |sort|uniq -c
3、统计/etc/fstab文件中每个单词出现的次数
[root.CentOS 7] ➤ awk 'gsub(/[^[:alpha:]]/,"\n",$0)' /etc/fstab | sort|uniq -c
4、提取出字符串Yd$C@M05MB%9&Bdh7dq+YVixp3vpw中的所有数字
[root.CentOS 7] ➤ echo "Yd$C@M05MB%9&Bdh7dq+YVixp3vpw" | awk 'gsub(/[^[:digit:]]/,"",$0)'
5、有一文件记录了1-100000之间随机的整数共5000个,存储的格式100,50,35,89…请取出其中最大和最小的整数
awk -F, '{if($1>$2){big=$1;small=$2}\
else{big=$2;small=$1}\
for(i=3;i<=NF;i++){\
if(big<$i){big=$i}\
if(small>$i){small=$i}\
}}\
END{print "big:"big"\nsmall:"small}' RANDOM.txt
6、解决DOS攻击生产案例:根据web日志或者或者网络连接数,监控当某个IP并发连接数或者短时内PV达到100,即调用防火墙命令封掉对应的IP,监控频率每隔5分钟。防火墙命令为:iptables -A INPUT -s IP -j REJECT
>crontab -e
*/5 * * * * bash dos.sh
>cat dos.sh
#!/bin/bash
ss -t | awk -F "[[:space:]]+|:" '{count[$6]++;}END{for(i in count){if(count[i]>1){system("iptables -A INPUT -s " i " -j REJECT")}}}'
7、将以下文件内容中FQDN取出并根据其进行计数从高到低排序
http://mail.magedu.com/index.html
http://www.magedu.com/test.html
http://study.magedu.com/index.html
http://blog.magedu.com/index.html
http://www.magedu.com/images/logo.jpg
http://blog.magedu.com/20080102.html
[root.CentOS 7] ➤ awk -F "[/|.]" '{count[$3]++}END{for(i in count){print i,count[i]}}' url.txt
8、将以下文本以inode为标记,对inode相同的counts进行累加,并且统计出同一inode中,beginnumber的最小值和endnumber的最大值
inode|beginnumber|endnumber|counts| 106|3363120000|3363129999|10000| 106|3368560000|3368579999|20000|
310|3337000000|3337000100|101| 310|3342950000|3342959999|10000| 310|3362120960|3362120961|2|
311|3313460102|3313469999|9898| 311|3313470000|3313499999|30000| 311|3362120962|3362120963|2|
输出的结果格式为: 310|3337000000|3362120961|10103| 311|3313460102|3362120963|39900| 106|3363120000|3368579999|30000| awk -F "|" -v OFS="|" 'NR==1{print $0}\ NR>1{count[$1]+=$4;if(max[$1]<$3){max[$1]=$3}\ if(!min[$1]){min[$1]=$2}if(min[$i]>$2){min[$1]=$2}}\ END{for(i in count){print i,min[i],max[i],count[i]"|"}}' inode.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号