文本三剑客之awk用法
第1章 AWK命令
1.1 awk命令解释
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
1)编程语言 三个人写的 A和W和K 三个人 GNU 2)查找匹配文件内容 3)格式化输出结果printf 4)统计数据 5)支持 for while if 数组等
[root@oldboyedu-lnb ~]# ll /usr/bin/awk # GNU AWK
lrwxrwxrwx. 1 root root 4 Jul 15 15:06 /usr/bin/awk -> gawk
1.2 awk对文件数据进行统计
awk主要对哪些文件进行数据统计
1)日志文件(服务日志 SSHD NGINX MySQL 自研发的服务) 2)系统配置文件 3)常规普通文件
1.3 awk命令格式和选项
1.3.1 语法形式
awk [options] 'script' var=value file(s) awk [options] -f scriptfile var=value file(s)
1)模式 匹配查找字符串的过程
2)awk的工作 必须在花括号内
3)只有模式没有动作 默认会执行print输出操作 # py print echo shell编程
4)如果没有模式(找谁)、默认的是对所有行进行操作
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F: -v var=value 赋值一个用户定义变量,将外部变量传递给awk -f scripfile 从脚本文件中读取awk命令 -m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。
这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
1.3.2 awk模式
awk '模式{动作}' file
awk '找谁{干啥}' file
cat file|awk '模式{动作}'
模式可以是以下任意一个
/正则表达式/:使用通配符的扩展集。 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。 模式匹配表达式:用运算符~(匹配)和~!(不匹配)。 BEGIN语句块、pattern语句块、END语句块:
1.3.3 操作
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内,主要部分是:
1.4 awk脚本基本结构
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file
一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成,这三个部分是可选的。任意一个部分都可以不出现在脚本中,脚本通常是被单引号或双引号中,例如:
awk 'BEGIN{ i=0 } { i++ } END{ print i }' filename awk "BEGIN{ i=0 } { i++ } END{ print i }" filename
1.5 awk的工作原理
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
第一步:执行BEGIN{ commands }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{ commands }语句块。
BEGIN语句块
在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块
在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块
中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
[root@centos7 ~]# echo -e "A line 1\nA line 2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" }'
Start
A line 1
A line 2
End
当使用不带参数的print时,它就打印当前行,当print的参数是以逗号进行分隔时,打印时则以空格作为定界符。在awk的print语句块中双引号是被当作拼接符使用,例如:
示例:[root@centos7 ~]# echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1,var2,var3; }'
v1 v2 v3
双引号拼接使用
[root@centos7 ~]# echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1"="var2"="var3; }'
v1=v2=v3
{ }类似一个循环体,会对文件中的每一行进行迭代,通常变量初始化语句(如:i=0)以及打印文件头部的语句放入BEGIN语句块中,将打印的结果等语句放在END语句块中。
1.6 awk内置变量(预定义变量)
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。[N] ARGC 命令行参数的数目。 [G] ARGIND 命令行中当前文件的位置(从0开始算)。 [N] ARGV 包含命令行参数的数组。 [G] CONVFMT 数字转换格式(默认值为%.6g)。 [P] ENVIRON 环境变量关联数组。 [N] ERRNO 最后一个系统错误的描述。 [G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。 [A] FILENAME 当前输入文件的名。 [P] FNR 同NR,但相对于当前文件。 [A] FS 字段分隔符(默认是任何空格)。 [G] IGNORECASE 如果为真,则进行忽略大小写的匹配。 [A] NF 表示字段数,在执行过程中对应于当前的字段数。 [A] NR 表示记录数,在执行过程中对应于当前的行号。 [A] OFMT 数字的输出格式(默认值是%.6g)。 [A] OFS 输出字段分隔符(默认值是一个空格)。 [A] ORS 输出记录分隔符(默认值是一个换行符)。 [A] RS 记录分隔符(默认是一个换行符)。 [N] RSTART 由match函数所匹配的字符串的第一个位置。 [N] RLENGTH 由match函数所匹配的字符串的长度。 [N] SUBSEP 数组下标分隔符(默认值是34)。
环境准备
1 Wu Waiwai 70271111 :250:80:75
2 Liu Bingbing 41117483 :250:100:175
3 Wang Xiaoai 3515064655 :50:95:135
4 Zi Gege 1986787350 :250:168:200
5 Li Youjiu 918391635 :175:75:300
6 Lao Nanhai 918391635 :250:100:176
1.7 awk 中的变量
awk中的变量(类似于操作系统自带的变量 LANG PATH PS1 $?上一条命令执行的返回结果)
1) NR 行号 把文件的所有行按照顺序都会记录到NR变量中
2) $0 $1 表示文件的所有和文件的第n列
3) , 逗号在awk中表示空格
4) NF 存储了每一行的最后一列的列号
1.7.1 awk取行 NR 行号
NR的表示符号 == 等于 在大部分的命令中一个等号是赋值 变量的意思 != 不等于 > 大于 < 小于 >= 大于等于 <= 小于等于 && 并且 两端同时成立 || 或者
1.7.2 输出文件中的第三行
awk 'NR==3' file [root@oldboyedu-lnb ~]# awk 'NR==3' oldboy.txt Wang Xiaoai 3515064655 :50:95:135
1.7.3 输出文件中大于3的行
[root@oldboyedu-lnb ~]# awk 'NR>3' oldboy.txt
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:176
1.7.4 输出文件不等于5的行
[root@oldboyedu-lnb ~]# awk 'NR!=5' oldboy.txt
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Lao Nanhai 918391635 :250:100:176
1.7.5 输出文件大于等于3的行
[root@oldboyedu-lnb ~]# awk 'NR>=3' oldboy.txt
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:176
1.7.6 输出文件内容等于2并且大于1的行
[root@oldboyedu-lnb ~]# awk 'NR==2 && NR>1' oldboy.txt
Liu Bingbing 41117483 :250:100:175
[root@oldboyedu-lnb ~]# awk 'NR==2 || NR==5' oldboy.txt
Liu Bingbing 41117483 :250:100:175
Li Youjiu 918391635 :175:75:300
[root@oldboyedu-lnb ~]# awk 'NR==2 || NR==10' oldboy.txt
Liu Bingbing 41117483 :250:100:175
1.7.7 查找文件的3-5行
[root@oldboyedu-lnb ~]# awk 'NR>2&& NR<6' oldboy.txt Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300
1.7.8 查找文件的2-6行
[root@oldboyedu-lnb ~]# awk 'NR>=2&& NR<=6' oldboy.txt Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:176
1.8 awk取列
1.8.1 变量
$0 awk在执行过程中把每一行都赋值给$0 $0表示所有文件内容
$1 文件中的第一列
$2 文件中的第二列
$n 文件中的第n列 n代表数字
默认的列是以tab键或空格来分隔
1.8.1.1 $0 输出文件所有内容
[root@oldboyedu-lnb ~]# awk '{print $0}' oldboy.txt
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:176
1.9 取文件中的列数
语法格式:
awk '{print $n}' file # 输出文件中的第n列
#PS:查找行
awk '模式' file
#PS:查找列
awk '{动作}' file # 对文件中所有的行都进行动作处理
1.9.1 输出文件中的第一列
[root@oldboyedu-lnb ~]# awk '{print $1}' oldboy.txt
Wu
Liu
Wang
Zi
Li
Lao
1.9.2 输出文件中的第一列和最后一列 使用逗号分隔 逗号是awk中的变量
[root@oldboyedu-lnb ~]# awk '{print $1,$4}' oldboy.txt
Wu :250:80:75
Liu :250:100:175
Wang :50:95:135
Zi :250:168:200
Li :175:75:300
Lao :250:100:176
1.9.3 输出文件中的最后一列 变量 NF 表示每一行最后一列的总列数
[root@oldboyedu-lnb ~]# cat oldboy.txt
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:176
Aug 5 12:01:01 oldboyedu-lnb systemd: Started Session 26 of user root.
alex test
[root@oldboyedu-lnb ~]# awk '{print NF}' oldboy.txt
4
4
4
4
4
4
11
2
1.9.4 输出文件中的最后一列
[root@oldboyedu-lnb ~]# awk '{print $NF}' oldboy.txt
:250:80:75
:250:100:175
:50:95:135
:250:168:200
:175:75:300
:250:100:176
root.
test
[root@oldboyedu-lnb ~]# awk '{print $(NF-1)}' oldboy.txt
70271111
41117483
3515064655
1986787350
918391635
918391635
user
alex
awk '{print $3}' oldboy.txt ======= awk '{print $(4-1)}' oldboy.txt
[root@oldboyedu-lnb ~]# awk 'BEGIN{print 10*1000/100+2^3}' # 了解
108
PS:awk中的动作都是变量 取消变量使用双引号
awk动作中可以输出任何自己想要的字符串 必须加双引号
awk动作中不在双引号中的字符串都被视为变量
[root@oldboyedu-lnb ~]# awk '{print $1"hehe"$4}' oldboy.txt
Wuhehe:250:80:75
Liuhehe:250:100:175
Wanghehe:50:95:135
Zihehe:250:168:200
Lihehe:175:75:300
Laohehe:250:100:176
[root@oldboyedu-lnb ~]#
[root@oldboyedu-lnb ~]# awk '{print $1" "$4}' oldboy.txt
Wu :250:80:75
Liu :250:100:175
Wang :50:95:135
Zi :250:168:200
Li :175:75:300
Lao :250:100:176
[root@oldboyedu-lnb ~]# awk '{print $1"-----"$4}' oldboy.txt
Wu-----:250:80:75
Liu-----:250:100:175
Wang-----:50:95:135
Zi-----:250:168:200
Li-----:175:75:300
Lao-----:250:100:176
[root@oldboyedu-lnb ~]# awk '{print $1" awk "$4}' oldboy.txt
Wu awk :250:80:75
Liu awk :250:100:175
Wang awk :50:95:135
Zi awk :250:168:200
Li awk :175:75:300
Lao awk :250:100:176
[root@oldboyedu-lnb ~]# awk '{print $1"\t"$4}' oldboy.txt
Wu :250:80:75
Liu :250:100:175
Wang :50:95:135
Zi :250:168:200
Li :175:75:300
Lao :250:100:176
[root@oldboyedu-lnb ~]# awk '{print $1"\n"$4}' oldboy.txt
Wu
:250:80:75
Liu
1.9.5 取出/etc/passwd中的第一列
-F 指定分割符(可指定任意的) 默认以tab键和空格来分隔
-F的第一种写法:
[root@oldboyedu-lnb ~]# cat passwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F ":" '{print $1}' passwd.txt
root
bin
-F 的第二种写法:
[root@oldboyedu-lnb ~]# awk -F: '{print $1}' passwd.txt
root
bin
[root@oldboyedu-lnb ~]# awk -F: '{print $1,$2,$3,$4,$5,$6,$7}' passwd.txt
root x 0 0 root /root /bin/bash
bin x 1 1 bin /bin /sbin/nologin
1.9.6 取出passwd中的第6列但是不要/
awk -F 指定多个分隔符
语法格式:
awk -F ":/" awk -F "[:/]"
案例1: 使用":/" 视作一个整体作为分隔符
[root@oldboyedu-lnb ~]# cat passwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F ":/" '{print $1 }' passwd.txt
root:x:0:0:root
bin:x:1:1:bin
[root@oldboyedu-lnb ~]# awk -F ":/" '{print $2 }' passwd.txt
root
bin
[root@oldboyedu-lnb ~]# awk -F ":/" '{print $3 }' passwd.txt
bin/bash
sbin/nologin
案例2: 使用"[:/]" 或者: 或者/ 作为分隔符
[root@oldboyedu-lnb ~]# cat passwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F "[:/]" '{print $9}' passwd.txt
bin
sbin
案例3:使用"[:/]+"
[root@oldboyedu-lnb ~]# cat passwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F "[:/]+" '{print $6}' passwd.txt
root
bin
[root@oldboyedu-lnb ~]# echo :://...---alex:..oldboy|awk -F "[:/.]+" '{print $2}'
---alex
[root@oldboyedu-lnb ~]#
[root@oldboyedu-lnb ~]# echo :://...---alex:..oldboy|awk -F "[:/.-]+" '{print $2}'
alex
[root@oldboyedu-lnb ~]# echo :://...---alex:..oldboy|awk -F "[:/.-]+" '{print $3}'
oldboy
[root@oldboyedu-lnb ~]# echo :://...---alex:..oldboy|awk -F ":/.-" '{print $2}'
[root@oldboyedu-lnb ~]# echo :://...---alex:..oldboy|awk -F "[:/.-]" '{print $2}'
[root@oldboyedu-lnb ~]# echo :://...---alex:..oldboy|awk -F "[:/.-]+" '{print $2}'
alex
问题1: 出现连续的分隔符
[root@oldboyedu-lnb ~]# cat passwd.txt
root::x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F: '{print $6}' passwd.txt
root
/bin
问题2: 以单引号或者任意符号作为分隔符
[root@oldboyedu-lnb ~]# awk -F\' '{print $3}' passwd.txt
test
[root@oldboyedu-lnb ~]# awk -F "[']" '{print $3}' passwd.txt
test
[root@oldboyedu-lnb ~]# cat passwd.txt
root:'x:0:0:root:/root:/bin/bash'test
bin:x:1:1:bin:/bin:/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F0 '{print $1}' passwd.txt
root:'x:
[root@oldboyedu-lnb ~]# cat test.txt
alex
[root@oldboyedu-lnb ~]# awk -Fl '{print $1}' test.txt
a
[root@oldboyedu-lnb ~]# awk -Fl '{print $2}' test.txt
ex
1.9.7 输出文件内容的第二行的第六列
语法格式:
awk '模式{动作}' file
[root@oldboyedu-lnb ~]# awk -F: 'NR==2{print $6}' passwd.txt
/bin
[root@oldboyedu-lnb ~]# awk -F: 'NR>1{print $NF}' passwd.txt
/sbin/nologin
[root@oldboyedu-lnb ~]# awk -F: 'NR>1&&NR==2{print $NF}' passwd.txt
/sbin/nologin
1.9.8 使用模糊匹配
语法格式:
grep '过滤的内容' file sed -n '/匹配的内容/' file awk '//' file awk '//,//' file
1.9.8.1 查找包含root的行
[root@oldboyedu-lnb ~]# awk '/root/' passwd.txt root:'x:0:0:root:/root:/bin/bash'test
1.9.8.2 查找包含root或者nologin的行
[root@oldboyedu-lnb ~]# awk '/root|nologin/' passwd.txt root:'x:0:0:root:/root:/bin/bash'test bin:x:1:1:bin:/bin:/sbin/nologin ntp:x:38:38::/etc/ntp:/sbin/nologin
1.9.8.3 区间匹配
[root@oldboyedu-lnb ~]# awk '/root/,/ntp/' passwd.txt root:'x:0:0:root:/root:/bin/bash'test bin:x:1:1:bin:/bin:/sbin/nologin ntp:x:38:38::/etc/ntp:/sbin/nologin
1.9.9 判断 可以是字符串的比对 也可以按照列数判断(数字)
字符串比对
格式: $1=="root" 等于root说明成功 成功后执行print动作 &&
格式2: $3>100 第三列的每一个行的数字都和100进行比较 如果没有动作默认输出 大于100的所有行
比较符:
== # 字符串使用== 和!=
>
<
!=
>=
<=
[root@oldboyedu-lnb ~]# awk -F: '$1=="root"{print $2}' passwd.txt
'x
[root@oldboyedu-lnb ~]# cat count.txt
alex 1 2 3 4 5 6
oldboy 10 20 30 40
lidao 100 200 300 400
[root@oldboyedu-lnb ~]# awk '$3>10' count.txt
oldboy 10 20 30 40
lidao 100 200 300 400
[root@oldboyedu-lnb ~]# awk '$3>10{print $1}' count.txt
oldboy
lidao
[root@oldboyedu-lnb ~]# awk '$2==100' count.txt
lidao 100 200 300 400
[root@oldboyedu-lnb ~]# awk '$2==100{print $NF}' count.txt
400
[root@oldboyedu-lnb ~]# awk '$2>=1&& $2<400' count.txt
alex 1 2 3 4 5 6
oldboy 10 20 30 40
lidao 100 200 300 400
[root@oldboyedu-lnb ~]# awk '$2==1|| $4==300' count.txt
alex 1 2 3 4 5 6
lidao 100 200 300 400
[root@oldboyedu-lnb ~]# awk '$2==1|| $4==600' count.txt
alex 1 2 3 4 5 6
1.9.10 NR行号
[root@oldboyedu-lnb ~]# awk '{print NR}' passwd.txt
1
2
3
4
[root@oldboyedu-lnb ~]# awk '{print NR,$0}' passwd.txt
1 root:'x:0:0:root:/root:/bin/bash'test
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 ntp:x:38:38::/etc/ntp:/sbin/nologin
4 alexdsx:x:1001:1001::/home/alexdsx:/bin/bash
根据文件的行数来执行相应的动作 动作可以和文件无关
[root@oldboyedu-lnb ~]# awk -F: '{print "ok"}' passwd.txt
ok
ok
ok
ok
[root@oldboyedu-lnb ~]# awk -F: '{a++}' passwd.txt
[root@oldboyedu-lnb ~]# awk -F: '{a++}END{print a}' passwd.txt
4
1.9.11 BEGIN 在动作之前做什么操作
语法格式:
awk 'BEGIN{动作}{执行文件的动作}' file
[root@oldboyedu-lnb ~]# awk 'BEGIN{print "开始了"}{print "ok"}' passwd.txt
开始了
ok
ok
ok
ok
[root@oldboyedu-lnb ~]# awk '{print 10*10}' passwd.txt
100
100
100
100
1.9.12 END 在执行完所有的操作后执行END动作
语法格式:
awk '{执行文件的动作}END{print "执行完文件后的动作"}' file
[root@oldboyedu-lnb ~]# awk '{print 10*10}END{print "end......"}' passwd.txt
100
100
100
100
end......
BEGIN和END结合
语法:
awk 'BEGIN{执行文件前的动作}{执行文件的动作}END{执行完文件后的动作}' file
[root@oldboyedu-lnb ~]# awk -F: 'BEGIN{print "开始执行"}{print $1}END{print "执行完成"}'passwd.txt
开始执行
root
bin
ntp
alexdsx
执行完成
案例
[root@oldboyedu-lnb ~]# awk -F: '$3>0&&$3<1000{a++}END{print a}' /etc/passwd
23
1.9.13 按照匹配规则匹配
sed -n '/^root/p' passwd.txt
grep '^root' passwd.txt
[root@oldboyedu-lnb ~]# awk '/^root/' passwd.txt root:'x:0:0:root:/root:/bin/bash'test [root@oldboyedu-lnb ~]# grep 'test$' passwd.txt root:'x:0:0:root:/root:/bin/bash'test [root@oldboyedu-lnb ~]# sed -n '/test$/p' passwd.txt root:'x:0:0:root:/root:/bin/bash'test [root@oldboyedu-lnb ~]# awk '/test$/' passwd.txt root:'x:0:0:root:/root:/bin/bash'test [root@oldboyedu-lnb ~]# awk -F: '$1 ~ /^ntp/' passwd.txt ntp:x:38:38::/etc/ntp:/sbin/nologin [root@oldboyedu-lnb ~]# awk -F: '$7 ~ /bash$/' passwd.txt alexdsx:x:1001:1001::/home/alexdsx:/bin/bash [root@oldboyedu-lnb ~]# awk -F: '$7 ~ /nologin$/' passwd.txt bin:x:1:1:bin:/bin:/sbin/nologin ntp:x:38:38::/etc/ntp:/sbin/nologin
awk -F: '$1 ~ /in$/{动作}' file
[root@oldboyedu-lnb ~]# awk -F: '$7 ~ /nologin$/{print "ok"}' passwd.txt
ok
ok
[root@oldboyedu-lnb ~]# awk -F: '$7 ~ /nologin$/{print $1}' passwd.txt
bin
ntp
[root@oldboyedu-lnb ~]# awk -F: '$7 ~ /nologin$/{print $NF}' passwd.txt
/sbin/nologin
/sbin/nologin
awk 匹配取反 了解
[root@oldboyedu-lnb ~]# awk -F: '$7 !~ /nologin$/' passwd.txt root:'x:0:0:root:/root:/bin/bash'test alexdsx:x:1001:1001::/home/alexdsx:/bin/bash
案例:
已知系统用户 管理员UID 0 虚拟用户 1-999 普通用户UID999+
/etc/passwd 中以冒号分隔的第三列是UID
如何使用awk统计出每类用户的数量
第一步: 获取没类用户的总数
[root@oldboyedu-lnb ~]# awk -F: '$3==0' /etc/passwd [root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000' /etc/passwd [root@oldboyedu-lnb ~]# awk -F: '$3>999' /etc/passwd
第二步: 统计输出到屏幕上的行数 wc -l
[root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000' /etc/passwd|less -N [root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000' /etc/passwd|grep -n . [root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000' /etc/passwd|cat -n [root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000' /etc/passwd|wc -l 23 ------------------ [root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000' /etc/passwd|wc -l # 虚拟用户 23 [root@oldboyedu-lnb ~]# awk -F: '$3>999' /etc/passwd |wc -l # 普通用户 2 [root@oldboyedu-lnb ~]# awk -F: '$3==0' /etc/passwd |wc -l # 管理员用户 1
--------------------------扩展了解------------------------------------------
[root@oldboyedu-lnb ~]# awk -F: '$3>0 && $3<1000{a++}END{print a}' /etc/passwd
23
[root@oldboyedu-lnb ~]# awk -F: '$3==0{a++}END{print a}' /etc/passwd
1
[root@oldboyedu-lnb ~]# awk -F: '$3>999{a++}END{print a}' /etc/passwd
2
1.9.14 使用if判断来统计用户个数
扩展: for while if 数组
[root@oldboyedu-lnb ~]# awk -F: '{if($3==0){a++}else if($3>0&&$3<1000){b++}else($3>999){c++}}END{print a,b,c}' /etc/passwd
1 23 2
[root@oldboyedu-lnb ~]# awk -F: '{if($3==0){a++}else if($3>0&&$3<1000){b++}else{c++}}END{print a,b,c}' /etc/passwd
1 23 2
1.9.15 算数运算
[root@oldboyedu-lnb ~]# awk 'BEGIN{print 10*1000/100+2^3}' # 了解
108
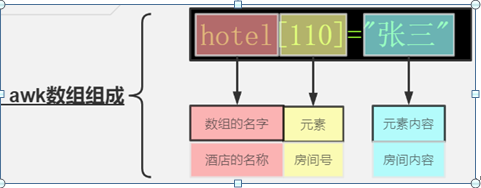
1.10 数组
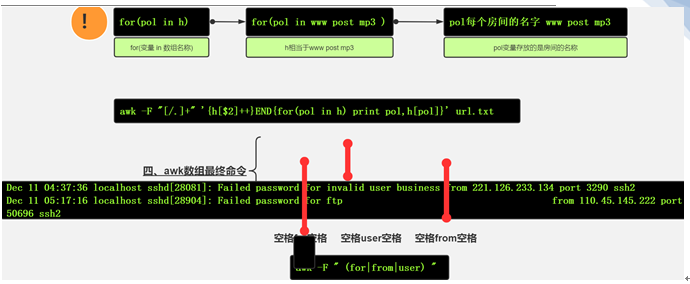
1.11 awk 小结
取行NR
取列$0 $1
NF 每行最后一列的列号 $NF 最后一列的内容
字符串比对 $1==root
数字比对 $3==0 $3>=0
awk 动作中所有的字符变量 输出内容加双引号
, 空格
-F 分隔符 空格 tab分隔 "[:/]+" 多个字符作为分隔符
BEGIN
END
1.12 awk运算与判断
作为一种程序设计语言所应具有的特点之一,awk支持多种运算,这些运算与C语言提供的基本相同。awk还提供了一系列内置的运算函数(如log、sqr、cos、sin等)和一些用于对字符串进行操作(运算)的函数(如length、substr等等)。这些函数的引用大大的提高了awk的运算功能。作为对条件转移指令的一部分,关系判断是每种程序设计语言都具备的功能,awk也不例外,awk中允许进行多种测试,作为样式匹配,还提供了模式匹配表达式~(匹配)和~!(不匹配)。作为对测试的一种扩充,awk也支持用逻辑运算符。
1.13 算术运算符
特殊示例:
1.14 操作符
比较操作符:
==, !=, >, >=, <, <=模式匹配符: ~:左边是否和右边匹配,包含 !~:是否不匹配[root@centos7~]#awk '$0~"^root"' /etc/passwd $0显示的行满足^root的正则表达式进行打印
root:x:0:0:root:/root:/bin/bash
[root@centos7~]#awk '$0!~"^root"' /etc/passwd $0显示的行满足非以^root为行首的正则表达式进行打印
[root@centos7~]#awk -F: '$3==0' /etc/passwd 第三列等于0的行进行打印
root:x:0:0:root:/root:/bin/bash
[root@centos7~]#lastb | awk '$3~/[[:digit:]]/{print $3}' $3显示的行满足数字的正则表达进行打印第三列
192.168.34.100
192.168.34.1
192.168.34.1
192.168.34.1
192.168.34.1
[root@centos7~]#lastb | awk '$3 ~ /^[[:digit:]]/{print $3}' | sort | uniq -c |awk '$1 >=3{print $1,$2}' 显示IP地址连接次数大于3的进行打印
[root@centos7~]#awk -F: '($3>=1000){print $1,$3}' /etc/passwd 显示第三列大于1000的第1行和第3行。
nfsnobody 65534
liu 1000
操作符
逻辑操作符:与&&,或||,非!
示例:
[root@centos7~]#awk -F: '$3>=1000 && $3<=2000{print $1,$3}' /etc/passwd 显示第3列大于1000
且小于2000的第1和第3列<br>liu 1000
[root@centos7~]#awk -F: '$3==0 || $3>=1000 {print $1,$3}' /etc/passwd
显示等于0和大于等于1000的第一和第三列
root 0
nfsnobody 65534
liu 1000
条件表达式(三目表达式)
selector?if-true-expression:if-false-expression
示例:
[root@centos7~]#awk -F: '{$3>=1000?name="common user":name="system user";print name,$1,$3}' /etc/passwd $3大于1000的显示第一和第三列的name命名为common user,小于1000的,命名为system usersystem user root 0system user bin 1system user daemon 2system user adm 3 |
printf命令
格式化输出:printf “FORMAT”, item1, item2, ...
(1) 必须指定FORMAT
(2) 不会自动换行,需要显式给出换行控制符,\n
(3) FORMAT中需要分别为后面每个item指定格式符
格式符:与item一一对应
%c:显示字符的ASCII码 %d, %i:显示十进制整数 %e, %E:显示科学计数法数值 %f:显示为浮点数 %g, %G:以科学计数法或浮点形式显示数值 %s:显示字符串 %u:无符号整数 %%:显示%自身 修饰符 #[.#] 第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f - 左对齐(默认右对齐) %-15s + 显示数值的正负符号 %+d
示例:
[root@centos7~]#awk -F: '{printf "%-20s %-10s\n",$1,$3}' /etc/passwd 提取第1列和第3列将其进行左对齐
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
awk PATTERN
PATTERN:根据pattern条件,过滤匹配的行,再做处理
(1)如果未指定:空模式,匹配每一行
(2) /regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来
awk '/^UUID/{print $1}' /etc/fstab
awk '!/^UUID/{print $1}' /etc/fstab
(3) relational expression: 关系表达式,结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值
(4)BEGIN/END模式
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次
示例:
[root@centos7~]#df | awk -F"[[:space:]]+|%" '/^\/dev\/sd/{print $1,$5}' 以空白和%为界限,取出当前的IP地址和设备:
/dev/sda2 4
/dev/sda3 1
/dev/sda1 17
ss -nt | awk -F"[[:space:]]+|:" '/ESTAB/{print $6}' 取第6列的IP
ss -nt | awk -F"[[:space:]]+|:" '/ESTAB/{print $(NF-2)}' 取倒数第三列的IP
relational expression: 关系表达式,结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值
赋值为0的示例:得出的结果是假
[root@centos7~]# awk '0{print $0}' /etc/fstab
[root@centos7~]#echo $?
0
赋值为空的示例:得出的结果是假
[root@centos7~]# awk '""{print $0}' /etc/fstab
[root@centos7~]#echo $?
0
为非0时就会显示结果,就为真,示例如下:
[root@centos7~]# awk '"1"{print $0}' /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Aug 22 15:21:16 2019
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=38dd5f68-4f30-411c-b80a-0f4a60b06c6f / xfs defaults 0 0
UUID=4357cc0e-6ee7-4a8f-8064-d1a54bdbf17f /boot xfs defaults 0 0
UUID=eb4bf5e6-2645-4b1c-bda8-12c5831b81c2 /data xfs defaults 0 0
UUID=b8c37e0b-3628-40b6-ac44-c36ca09b448f swap swap defaults 0 0
line ranges:行范围
startline,endline:/pat1/,/pat2/ 不支持直接给出数字格式
示例:
[root@centos7~]#awk -F: '/^root/,/^adm/{print $1}' /etc/passwd 显示第1列root开头的行到adm开头的行
root
bin
daemon
adm
[root@centos7~]#awk -F: '(NR>=10&&NR<=14){print NR,$1}' /etc/passwd 显示第10行到14行的第1列
10 operator
11 games
12 ftp
13 nobody
14 systemd-netword
特殊示例:
打印奇数行:
[root@centos7~]#seq 10 | awk 'i=!i' 第一个i为空值,为假,取反就会打印出1,第二个出来为1时,为真,取反为假,就不打印2,以此类推,得出以下结果。 1 3 5 7 9
打印偶数行:
seq 10 | sed -n '1~2n' 打印奇数行 seq 10 | sed -n '2~2n' 打印偶数行 第一种情况:seq 10 | awk -v i="a" 'i=!i' 第二种情况:[root@centos7~]#seq 10 | awk '!(i=!i)' 2 4 6 8 10
常用的action分类
• (1) Expressions:算术,比较表达式等
• (2) Control statements:if, while等
• (3) Compound statements:组合语句
• (4) input statements
• (5) output statements:print等
awk控制语句
{ statements;… } 组合语句
if(condition) {statements;…}
if(condition) {statements;…} else {statements;…}
while(conditon) {statments;…}
do {statements;…} while(condition)
for(expr1;expr2;expr3) {statements;…}
break
continue
delete array[index]
delete array
uexit
awk控制语句if-else
语法:if(condition){statement;…}[else statement]
if(condition1){statement1}else if(condition2){statement2}else{statement3}
使用场景:对awk取得的整行或某个字段做条件判断
条件判断语句:if
格式中语句1可以是多个语句,为了方便判断和阅读,最好将多个语句用{}括起来。awk分枝结构允许嵌套,其格式为:
示例:
awk 'BEGIN{
test=100;
if(test>90){
print "very good";
}
else if(test>60){
print "good";
}
else{
print "no pass";
}
}'
very good
awk 'BEGIN{
test=100;
if(test>90){
print "very good";
}
else if(test>60){
print "good";
}
else{
print "no pass";
}
}'
very good
while循环
语法:while(condition){statement;…}
条件“真”,进入循环;条件“假”,退出循环
使用场景:
对一行内的多个字段逐一类似处理时使用
对数组中的各元素逐一处理时使用
示例:
显示第一行,且统计第一行有多少个字节,并打印每个字符。
[root@centos7~]#awk -F: 'NR==1{i=1;while(i<=NF){print $i,length($i);i++}}' /etc/passwd
root 4
x 1
0 1
0 1
root 4
/root 5
示例:
取出字符大于等于10的行,并统计字节数
[root@centos7~]#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF){if(length($i)>=10){print $i,length($i)};i++}}' /etc/grub2.cfg
/vmlinuz-3.10.0-957.el7.x86_64 30
root=UUID=38dd5f68-4f30-411c-b80a-0f4a60b06c6f 46
LANG=en_US.UTF-8 16
/vmlinuz-0-rescue-7a7fe51fce8c4639a5a046ac251485d0 50
示例:生成随机1000个数字
[root@centos7~]#for i in {1..1000};do if [ $i -eq 1 ];then echo -e "$RANDOM\c" >> f1.txt;else echo -e ",$RANDOM\c" >> f1.txt;fi;done
然后在随机数中取出最大值最小值:
[root@centos7~]#awk -F ',' '{i=2;max=$1;min=$1;while (i<=NF){if($i > max){max=$i}
else if($i <min){min=$i};i++}}END{print "max="max,"min="min}' f1.txt
max=1653826510 min=8
do-while循环
语法:do {statement;…}while(condition)
意义:无论真假,至少执行一次循环体
示例:1+2..100求和
[root@centos7~]#awk 'BEGIN{ total=0;i=0;do{ total+=i;i++;}while(i<=100);print total}'
5050
for循环
语法:for(expr1;expr2;expr3) {statement;…}
常见用法:
for(variable assignment;condition;iteration process)
{for-body}
u特殊用法:能够遍历数组中的元素
语法:for(var in array) {for-body}
示例:
[root@centos7~]#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg 显示当前行有多少个字符
linux16 7
/vmlinuz-3.10.0-957.el7.x86_64 30
root=UUID=38dd5f68-4f30-411c-b80a-0f4a60b06c6f 46
ro 2
rhgb 4
quiet 5
LANG=en_US.UTF-8 16
linux16 7
/vmlinuz-0-rescue-7a7fe51fce8c4639a5a046ac251485d0 50
root=UUID=38dd5f68-4f30-411c-b80a-0f4a60b06c6f 46
ro 2
rhgb 4
quiet 5
|
switch语句
语法:switch(expression) {case VALUE1 or /REGEXP/: statement1; case
VALUE2 or /REGEXP2/: statement2; ...; default: statementn}
break和continue
next:
continue语句:当 continue 语句用于 while 或 for 语句时,使程序循环移动到下一个迭代。
break语句:当 break 语句用于 while 或 for 语句时,导致退出程序循环。
示例:
awk 'BEGIN{total=0;for(i=1;i<=100;i++){if(i==50)break;total+=i};print total}'
next语句:能能够导致读入下一个输入行,并返回到脚本的顶部。这可以避免对当前输入行执行其他的操作过程。
示例:
awk -F: '{if(NR%2==0)next;print NR,$0}' /etc/passwd 显示的是奇数行
awk -F: '{if(NR%2==0)print NR,$0}' /etc/passwd 显示偶数行
数组应用
awk数组
关联数组:array[index-expression]
uindex-expression:
• (1) 可使用任意字符串;字符串要使用双引号括起来
• (2) 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值
初始化为“空串” 很重要,比较被遗忘的一个点
• (3) 若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
数字做数组索引(下标):
Array[1]="sun"
Array[2]="kai"
字符串做数组索引(下标):
Array["first"]="www"
Array["last"]="name"
Array["birth"]="1987"
使用中print Array[1]会打印出sun;使用print Array[2]会打印出kai;使用print Array["birth"]会得到1987。
示例:
[root@centos7~]#awk 'BEGIN{title["coo"]="wang";title["ceo"]="ma";print title["coo"]}'
wang
示例: 类似于去重的功能
解释:line[$0]第一次显示的值为空值;
然后取反就为真,打印第一个值,++会将第一次出现的值进行累加,然后取反为假,就不打印重复出现的值。
[root@centos7~]#awk '{!line[$0]++;print $0,line[$0]}' f1.txt 显示当前的详细过程,验证第一次数组赋值为空值,取反为1.
aaa 1
sss 1
aaa 2
ccc 1
ccc 2
[root@centos7~]#awk '!line[$0]++' f1.txt
aaa
sss
ccc
[root@centos7~]#cat f1.txt
aaa
sss
aaa
ccc
ccc
数组for循环语句用法:
若要遍历数组中的每个元素,要使用for循环
for(var in array) {for-body}
注意:var会遍历array的每个索引
示例:
[root@centos7~]#awk 'BEGIN{titel["coo"]="ma";titel["ceo"]="lige";
titel[3]="liu";for(i in titel){print i,titel[i]}}'
coo ma
ceo lige
3 liu
示例: 统计ip的tcp类型的次数
[root@centos7~]#ss -nt | awk -F"[[:space:]]+|:" '/ESTAB/{ip[$(NF-2)]++}END{for(i in ip){print i,ip[i]}}'
192.168.34.1 1
示例: 提取文件系统类型和计数
[root@centos7~]#awk '/^UUID/{type[$3]++}END{for(i in type){print i type[i]}}' /etc/fstab
swap1
xfs3
示例:分数求平均值
[root@centos6~]#cat f1.txt
name sex score
a f 90
b m 80
c f 50
d m 60
[root@centos6~]#awk '!/^name/{sum[$2]+=$3;num[$2]++}END{for(i in num){print i,sum[i]/num[i]}}' f1.txt
m 70
f 70
数值处理:
rand():返回0和1之间一个随机数
示例:随机生成四个数值,其中int是取整数,rand()默认取出的数值小数点两位,*100增大十倍
[root@centos6~]#awk 'BEGIN{srand();for(i=1;i<=4;i++)print int(rand()*100)}'
5
12
52
84
取出一位100以内的随机数:
[root@centos7~]#awk 'BEGIN{srand();print int(rand()*100)}'
56
字符串处理:
• length([s]):返回指定字符串的长度
• sub(r,s,[t]):对t字符串搜索r表示模式匹配的内容,并将第一个匹配内容替换为s
示例:将第一列的:替换为-
[root@centos7~]#echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)' 2008-08:08 08:08:08
• gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表
示的内容
示例:将整行:进行全部替换为-
[root@centos7~]#echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)' 2008-08-08 08-08-08
示例:将第一列全部替换为-
[root@centos7~]#echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$1)' 2008-08-08 08:08:08
• split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所
表示的数组中,第一个索引值为1,第二个索引值为2,…
示例一:将整行以:形式进行分割,最后显示当前行字符和序列号,其中i显示序号,str[i]显示处理后的字符
[root@centos7~]#echo "2008:08:08 08:08:08" | awk '{split($0,str,":")}END{for(i in str){print i,str[i]}}'
4 08
5 08
1 2008
2 08
3 08 08
示例二:整行以:为分割线,将第五列的ip地址取出并统计当前的次数
[root@centos7~]#ss -nt | awk '/^ESTAB/{split($5,ip,":");count[ip[1]]++}END{for(i in count){print i,count[i]}}'
192.168.34.1 1
自定义函数格式:
function name ( parameter, parameter, ... ) {
statements
return expression
}
示例:
cat fun.awk
function max(x,y) {
x>y?var=x:var=y 如果x>y则var=x,否则var=y
return var
}
BEGIN{a=3;b=2;print max(a,b)}
awk -f fun.awk
system命令用法:
空格是awk中的字符串连接符,如果system中需要使用awk中的变量可以使用
空格分隔,或者说除了awk的变量外其他一律用""引用起来
示例一:systeml 可以调用awk里边的命令变量
[root@centos7~]#awk 'BEGIN{system("hostname")}'
centos7.localdomain
示例二:
[root@centos7~]#awk 'BEGIN{system("ls /boot")}'
config-3.10.0-957.el7.x86_64 initramfs-3.10.0-957.el7.x86_64.img
efi symvers-3.10.0-957.el7.x86_64.gz
grub System.map-3.10.0-957.el7.x86_64
grub2 vmlinuz-0-rescue-7a7fe51fce8c4639a5a046ac251485d0
initramfs-0-rescue-7a7fe51fce8c4639a5a046ac251485d0.img vmlinuz-3.10.0-957.el7.x86_64
将awk程序写成脚本,直接调用或执行
示例一:调用文件
cat f1.awk
{if($3>=1000)print $1,$3}
awk -F: -f f1.awk /etc/passwd
cat f2.awk
示例二:调用脚本文件
#!/bin/awk -f
#this is a awk script
{if($3>=1000)print $1,$3}
加执行权限:chmod +x f2.awk
当前目录执行调用脚本:
./f2.awk -F: /etc/passwd
向awk脚本传递参数
格式:
awkfile var=value var2=value2... Inputfile
注意:在BEGIN过程中不可用。直到首行输入完成以后,变量才可用。可以通过-v 参数,让awk在执行BEGIN之前得到变量的值。命令行中每一个指定的变量都需要一个-v参数
示例:
cat test.awk
#!/bin/awk –f
{if($3 >=min && $3<=max)print $1,$3}
chmod +x test.awk
./test.awk -F: min=100 max=200 /etc/passwd
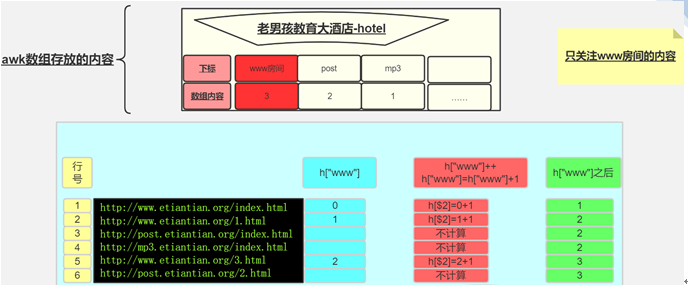
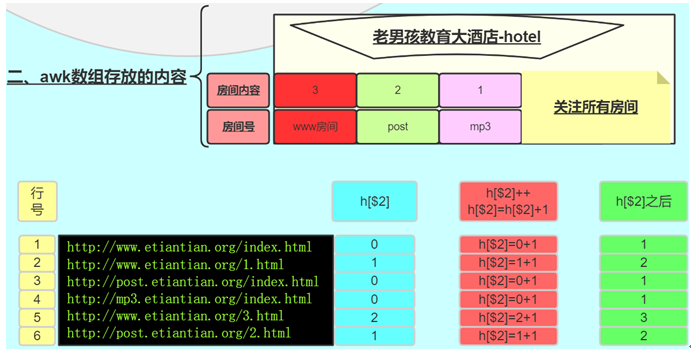
练习:将以下文件内容中FQDN取出域名并根据其进行计数从高到低排序
http://mail.magedu.com/index.html
http://www.magedu.com/test.html
http://study.magedu.com/index.html
http://blog.magedu.com/index.html
http://www.magedu.com/images/logo.jpg
http://blog.magedu.com/20080102.html
答案:
[root@centos7~]#cat f1.txt
http://mail.magedu.com/index.html
http://www.magedu.com/test.html
http://study.magedu.com/index.html
http://blog.magedu.com/index.html
http://www.magedu.com/images/logo.jpg
http://blog.magedu.com/20080102.html
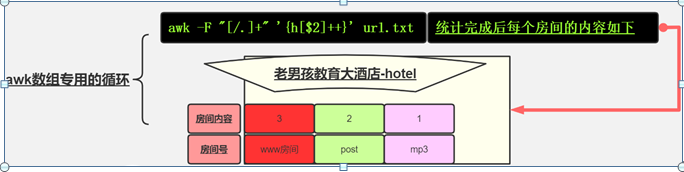
[root@centos7~]# awk -F"/" '{fqdn[$3]++}END{for(i in fqdn){print i,fqdn[i]}}' f1.txt | sort -nr -k2
www.magedu.com 2
blog.magedu.com 2
study.magedu.com 1
mail.magedu.com 1
参考文献
https://www.cnblogs.com/struggle-1216/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号