会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
strongmore
怕什么真理无穷,进一寸有一寸的欢喜。
博客园
首页
新随笔
联系
订阅
管理
上一页
1
···
17
18
19
20
21
22
23
24
25
···
48
下一页
2023年6月3日
数据仓库项目介绍与分析
摘要: ### 项目效果展示 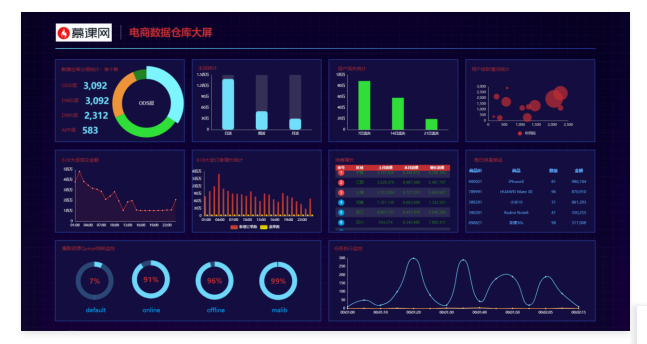 本身我们这个数据仓库项目其实是一个纯后台项目,不过为了让大家能够更加直观的感受项目
阅读全文
posted @ 2023-06-03 08:10 strongmore
阅读(538)
评论(0)
推荐(0)
2023年6月2日
Spark集成Hive
摘要: ### 命令行集成Hive 将hive中的`hive-site.xml`配置文件拷贝到spark配置文件目录下,仅需要以下内容 ```xml hive.metastore.warehouse.dir /user/hive/warehouse javax.jdo.option.ConnectionUR
阅读全文
posted @ 2023-06-02 20:33 strongmore
阅读(187)
评论(0)
推荐(0)
Spark3.x扩展内容
摘要: ### 3.0.0主要的新特性: 1. 在TPC-DS基准测试中,通过启用自适应查询执行、动态分区裁剪等其他优化措施,相比于Spark 2.4,性能提升了2倍 2. 兼容ANSI SQL 3. 对pandas API的重大改进,包括python类型hints及其他的pandas UDFs 4. 简化
阅读全文
posted @ 2023-06-02 20:21 strongmore
阅读(146)
评论(0)
推荐(0)
SparkSQL入门
摘要: ### Spark SQL Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。 hive on spark是表示把底层的mapreduce引擎替换为spark引擎。 而Spark SQL是Spark自己实现的一套SQL处理引擎。 Spark SQL是Spark中的
阅读全文
posted @ 2023-06-02 08:37 strongmore
阅读(62)
评论(0)
推荐(0)
Spark性能优化
摘要: ### 性能优化分析 一个计算任务的执行主要依赖于CPU、内存、带宽 Spark是一个基于内存的计算引擎,所以对它来说,影响最大的可能就是内存,一般我们的任务遇到了性能瓶颈大概率都是内存的问题,当然了CPU和带宽也可能会影响程序的性能,这个情况也不是没有的,只是比较少。 Spark性能优化,其实主要
阅读全文
posted @ 2023-06-02 08:18 strongmore
阅读(471)
评论(0)
推荐(0)
Spark扩展内容
摘要: ### 宽依赖和窄依赖 - 窄依赖(Narrow Dependency):指父RDD的每个分区只被子RDD的一个分区所使用,例如map、filter等这些算子 一个RDD,对它的父RDD只有简单的一对一的关系,也就是说,RDD的每个partition仅仅依赖于父RDD中的一个partition,父R
阅读全文
posted @ 2023-06-02 07:34 strongmore
阅读(72)
评论(0)
推荐(0)
Spark之RDD相关
摘要: ### 创建RDD RDD是Spark编程的核心,在进行Spark编程时,首要任务是创建一个初始的RDD,这样就相当于设置了Spark应用程序的输入源数据 然后在创建了初始的RDD之后,才可以通过Spark 提供的一些高阶函数,对这个RDD进行操作,来获取其它的RDD Spark提供三种创建RDD方
阅读全文
posted @ 2023-06-02 07:31 strongmore
阅读(55)
评论(0)
推荐(0)
Spark实战
摘要: ### WordCount程序 这个需求就是类似于我们在学习MapReduce的时候写的案例 需求这样的:读取文件中的所有内容,计算每个单词出现的次数 注意:由于Spark支持Java、Scala这些语言,目前在企业中大部分公司都是使用Scala语言进行开发,个别公司会使用java进行开发,为了加深
阅读全文
posted @ 2023-06-02 07:07 strongmore
阅读(108)
评论(0)
推荐(0)
Spark详解
摘要: ### 什么是Spark Spark是一个用于大规模数据处理的统一计算引擎 注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,所以说它是一个统一的计算引擎 既然说到了Spark,那就不得不提一下Spark里面最重要的
阅读全文
posted @ 2023-06-02 06:50 strongmore
阅读(941)
评论(0)
推荐(0)
2023年6月1日
Scala语言入门
摘要: ### 为什么要学习Scala语言 - 最直接的一点就是因为我们后面要学的Spark框架需要用到Scala这门语言,但是Spark其实是同时支持Scala语言和Java语言的,为什么非要学Scala呢,使用java难道不香吗? - 这就要说第二点了:scala相比java代码量更少,更适合函数式编程
阅读全文
posted @ 2023-06-01 20:48 strongmore
阅读(97)
评论(0)
推荐(0)
上一页
1
···
17
18
19
20
21
22
23
24
25
···
48
下一页
公告






 浙公网安备 33010602011771号
浙公网安备 33010602011771号