





06 2023 档案
摘要:### 下载 [下载地址](https://www.elastic.co/cn/downloads/past-releases#filebeat),这里我们使用7.4.2版本。 ### 配置控制台输出 FileBeat就是一个采集工具,使用起来很简单,只需要指定input和output,也就是指定输
阅读全文
摘要:下面我们就从第一个模块,数据采集模块开始。 注意:在实际工作中,数据采集模块不是只针对某一个项目而言的,而是一个公共的采集平台,所有项目依赖的数据全部是来源于数据采集模块,所以在设计采集模块的时候要考虑通用性。 ### 数据采集架构详细分析 在具体开始之前,我们还要再分析一些内容 我们前面在分析整体
阅读全文
摘要:针对这个项目中用到的技术组件,只有filebeat和neo4j我们没有使用过 不过filebeat比较简单,类似于flume,在使用的时候主要是写配置文件,所以在后面用到的时候我们再具体分析。 下面我们来学习一下neo4j的使用,快速了解它并掌握它的常见用法。 ### Neo4j介绍 Neo4j是一
阅读全文
摘要:### 项目效果 在直播平台中,用户在主播页面关注该主播时,粉丝状态栏下方插入三度关系推荐模块,显示该主播的粉丝同时又关注了哪些主播,按照推荐重合度且满足一定的筛选条件进行择优展示,这样推荐的主播才是用户最可能会喜欢的。 这样可以帮助用户发现更多他喜欢的主播,促进用户活跃,进而挖掘用户消费潜力。 #
阅读全文
摘要:### Window(窗口) Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。 通常来讲,Window是一种可以把无界数据切割为有界数据块的手段 例如,对流中的所有元素进行计
阅读全文
摘要:### Table API & SQL 注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现Flink中所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。 Table API和SQL的由来: Flink针对标准的流处理和批处理提供了两种
阅读全文
摘要:### DataSet API DataSet API主要可以分为3块来分析:DataSource、Transformation、Sink。 DataSource是程序的数据源输入。 Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap、filt
阅读全文
摘要: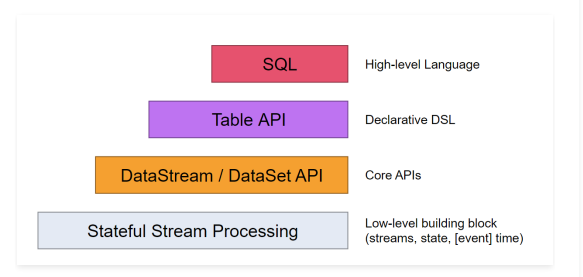 Flink中提供了4种不同层次的API,每种API在简洁和易表达之间有自己的权衡,适用于不同的场景。目前
阅读全文
摘要:### Flink集群安装部署 Flink支持多种安装部署方式 - Standalone - ON YARN - Mesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境
阅读全文
摘要:### 什么是Flink Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。 分布式:表示flink程序可以运行在很多台机器上, 高性能:表示Flink处理性能比较高 高可用:表示flink支持程序的自动重启机制。 准确的:表示flink可以保证处理数据的准确性。 Fl
阅读全文
摘要:针对数据仓库中的任务脚本我们前面已经整理过了,任务脚本还是比较多的,针对初始化表的脚本只需要执行一次即可,其它的脚本需要每天都执行一次,这个时候就需要涉及到任务定时调度了。 ### Crontab调度器的使用 我们前面在学习Linux的时候学过一个crontab调度器,通过它可以实现定时执行指定的脚
阅读全文
摘要:### 前言 数据可视化这块不是项目的重点,不过为了让大家能有一个更加直观的感受,我们可以选择一些现成的数据可视化工具实现。 我们前面分析过,想要查询hive中的数据可以使用hue,不过hue无法自动生成图表。 所以我们可以考虑使用Zeppelin,Zeppelin是一个Apache的孵化项目.一个
阅读全文
摘要:### 什么是拉链表 针对订单表、订单商品表,流水表,这些表中的数据是比较多的,如果使用全量的方式,会造成大量的数据冗余,浪费磁盘空间。 所以这种表,一般使用增量的方式,每日采集新增的数据。 在这注意一点:针对订单表,如果单纯的按照订单产生时间增量采集数据,是有问题的,因为用户可能今天下单,明天才支
阅读全文
摘要:### ods 层 在 ods_mall 中需要创建以下针对商品订单数据的表 ```txt 表名 说明 导入方式 ods_user 用户信息表 全量 ods_user_extend 用户扩展表 全量 ods_user_addr 用户收货地址表 全量 ods_goods_info 商品信息表 全量 o
阅读全文
摘要:数据仓库分为 4层:ods层、dwd层、dws层、app层, 我们先来构建第一层:ods层 ### ods 层 在 ods_mall中需要创建以下针对用户行为数据的表 ```txt 表名 解释 ods_user_active 用户主动活跃表(act=1) ods_click_good 点击商品表(a
阅读全文
摘要:### Sqoop下载及安装 Sqoop目前有两大版本,Sqoop1和Sqoop2,这两个版本都是一直在维护者的,所以使用哪个版本都可以。 这两个版本我都用过,还是感觉Sqoop1用起来比较方便,使用Sqoop1的时候可以将具体的命令全部都写到脚本中,这样看起来是比较清晰的,但是有一个弊端,就是在操
阅读全文
摘要:### 数据生成 我们需要先生成测试数据,一份是服务端数据,还有一份是客户端数据 ### 【客户端数据】用户行为数据 首先我们模拟生成用户行为数据,也就是客户端数据,主要包含用户打开APP、点击、浏览等行为数据 用户行为数据:通过埋点上报,后端日志服务器(http)负责接收数据 埋点上报数据基本格式
阅读全文
摘要:### 项目效果展示  本身我们这个数据仓库项目其实是一个纯后台项目,不过为了让大家能够更加直观的感受项目
阅读全文
摘要:### 命令行集成Hive 将hive中的`hive-site.xml`配置文件拷贝到spark配置文件目录下,仅需要以下内容 ```xml hive.metastore.warehouse.dir /user/hive/warehouse javax.jdo.option.ConnectionUR
阅读全文
摘要:### 3.0.0主要的新特性: 1. 在TPC-DS基准测试中,通过启用自适应查询执行、动态分区裁剪等其他优化措施,相比于Spark 2.4,性能提升了2倍 2. 兼容ANSI SQL 3. 对pandas API的重大改进,包括python类型hints及其他的pandas UDFs 4. 简化
阅读全文
摘要:### Spark SQL Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。 hive on spark是表示把底层的mapreduce引擎替换为spark引擎。 而Spark SQL是Spark自己实现的一套SQL处理引擎。 Spark SQL是Spark中的
阅读全文
摘要:### 性能优化分析 一个计算任务的执行主要依赖于CPU、内存、带宽 Spark是一个基于内存的计算引擎,所以对它来说,影响最大的可能就是内存,一般我们的任务遇到了性能瓶颈大概率都是内存的问题,当然了CPU和带宽也可能会影响程序的性能,这个情况也不是没有的,只是比较少。 Spark性能优化,其实主要
阅读全文
摘要:### 宽依赖和窄依赖 - 窄依赖(Narrow Dependency):指父RDD的每个分区只被子RDD的一个分区所使用,例如map、filter等这些算子 一个RDD,对它的父RDD只有简单的一对一的关系,也就是说,RDD的每个partition仅仅依赖于父RDD中的一个partition,父R
阅读全文
摘要:### 创建RDD RDD是Spark编程的核心,在进行Spark编程时,首要任务是创建一个初始的RDD,这样就相当于设置了Spark应用程序的输入源数据 然后在创建了初始的RDD之后,才可以通过Spark 提供的一些高阶函数,对这个RDD进行操作,来获取其它的RDD Spark提供三种创建RDD方
阅读全文
摘要:### WordCount程序 这个需求就是类似于我们在学习MapReduce的时候写的案例 需求这样的:读取文件中的所有内容,计算每个单词出现的次数 注意:由于Spark支持Java、Scala这些语言,目前在企业中大部分公司都是使用Scala语言进行开发,个别公司会使用java进行开发,为了加深
阅读全文
摘要:### 什么是Spark Spark是一个用于大规模数据处理的统一计算引擎 注意:Spark不仅仅可以做类似于MapReduce的离线数据计算,还可以做实时数据计算,并且它还可以实现类似于Hive的SQL计算,所以说它是一个统一的计算引擎 既然说到了Spark,那就不得不提一下Spark里面最重要的
阅读全文
摘要:### 为什么要学习Scala语言 - 最直接的一点就是因为我们后面要学的Spark框架需要用到Scala这门语言,但是Spark其实是同时支持Scala语言和Java语言的,为什么非要学Scala呢,使用java难道不香吗? - 这就要说第二点了:scala相比java代码量更少,更适合函数式编程
阅读全文
摘要:### Hbase简介 Hbase是一种NoSQL数据库,这意味着它不像传统的RDBMS数据库那样支持SQL作为查询语言。Hbase是一种分布式存储的数据库,技术上来讲,它更像是分布式存储而不是分布式数据库,它缺少很多RDBMS系统的特性,比如列类型,辅助索引,触发器,和高级查询语言等待。那Hbas
阅读全文
摘要:### 一个SQL语句的分析 ```sql SELECT a.Key, SUM(a.Cnt) AS Cnt FROM ( SELECT Key, COUNT(*) AS Cnt FROM TableName GROUP BY Key, CASE WHEN Key = 'KEY001' THEN Ha
阅读全文
摘要:### 函数的基本操作 和mysql一样的,hive也是一个主要做统计的工具,所以为了满足各种各样的统计需要,它也内置了相当多的函数 ```sql show functions; # 查看所有内置函数 desc function functionName; # 查看指定函数的描述信息 desc fu
阅读全文
摘要:### Event Event是Flume传输数据的基本单位,也是事务的基本单位,在文本文件中,通常一行记录就是一个Event Event中包含header和body; - body是采集到的那一行记录的原始内容 - header类型为Map,里面可以存储一些属性信息,方便后面使用 我们可以在Sou
阅读全文
摘要:### 什么是Flume Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统,能够有效的收集、聚合、移动大量的日志数据。 通俗一点来说就是Flume是一个很靠谱,很方便、很强的日志采集工具。它是目前大数据领域数据采集最常用的一个框架 为什么它这么香呢?主要是因为使用Flume采集
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号