





更多有关K近邻算法的思考
优点
- 解决分类问题,天然可以解决多分类问题
- 思想简单,效果强大
- 可以解决回归问题,距离最近的k个点的平均值,考虑上距离的话,可以使用加权平均,sklearn提供了KNeighborsRegressor

缺点
- 效率低下,m个特征n个样本,预测一个数据的时间复杂度为O(m * n)
可以使用树结构KD-Tree,Ball-Tree来优化,但是依然也是效率低的。 - 高度数据相关,如果我们使用k=3,但有2个错误值,那么预测结果就会是错误的
- 预测结果不具有可解释性,一个新的样本属于距离最近的样本所属的分类,但不能给出原因
- 维数灾难:随着维度的增加,看似相近的两个点距离越来越大,解决方法:降维

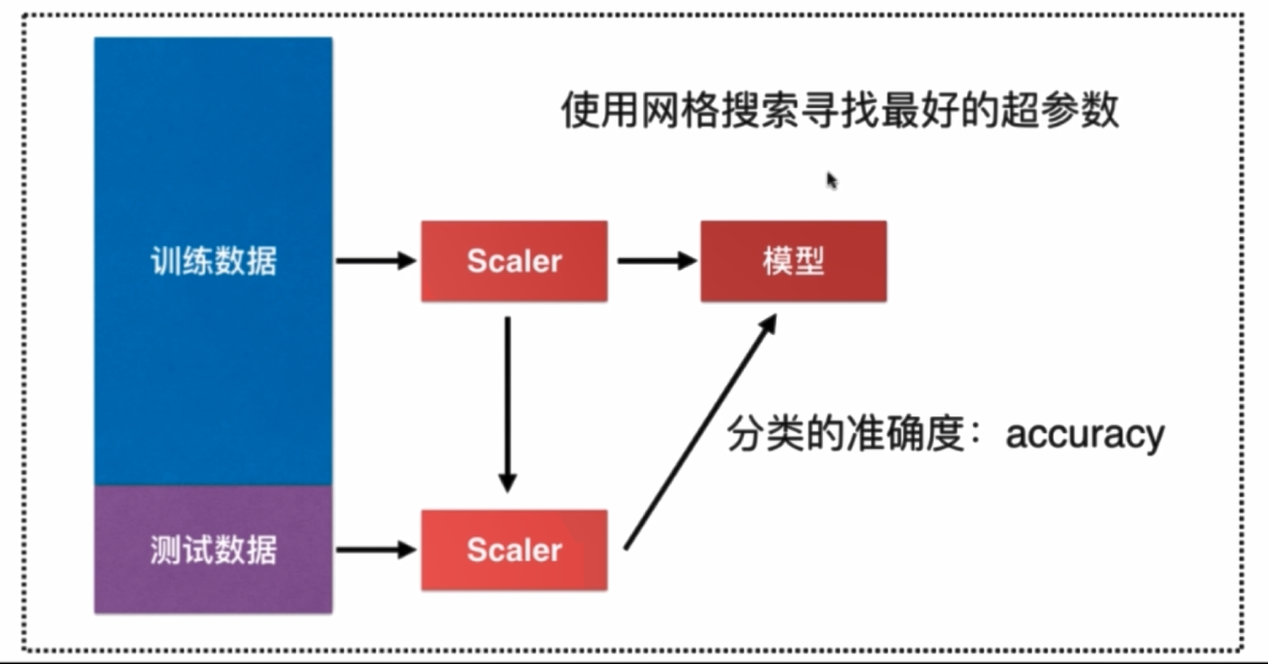
机器学习流程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号