





KNN算法之超参数
超参数和模型参数
- 超参数是指运行机器学习算法之前要指定的参数
KNN算法中的K就是一个超参数 - 模型参数:算法过程中学习的参数
KNN算法没有模型参数
调参是指调超参数
如何寻找好的超参数
- 领域知识
- 经验数值
- 实验搜索
寻找最好的K
数据准备
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
# 加载手写识别数据
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 测试和训练数据集分类
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
代码实现
# 查找最好的k值
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k = ", best_k)
print("best_score = ", best_score)
输出:
best_k = 4
best_score = 0.9916666666666667
KNN的超参数weights
-
普通的KNN算法:蓝色获胜
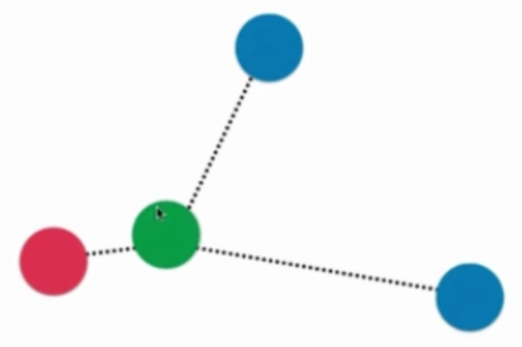
-
考虑距离的KNN算法:红色:1, 蓝色:1/3 + 1/4 = 7/12,蓝色获胜
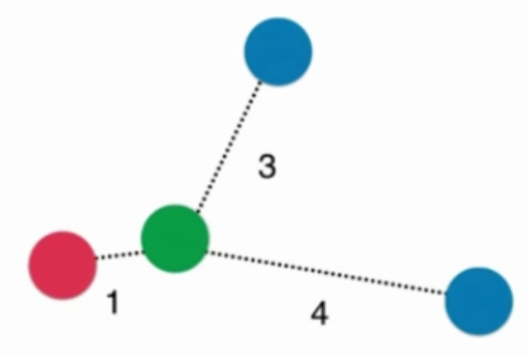
考虑距离的另一个优点:解决平票的情况
best_method = ""
best_score = 0.0
best_k = -1
# uniform为默认值,不考虑距离,distance表示考虑距离的权重
for method in ["uniform", "distance"]:
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_k = ", best_k)
print("best_score = ", best_score)
print("best_method = ", best_method)
输出结果:
best_k = 4
best_score = 0.9916666666666667
best_method = uniform
KNN的超参数p
关于距离的更多定义
- 欧拉距离
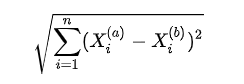
- 曼哈顿距离
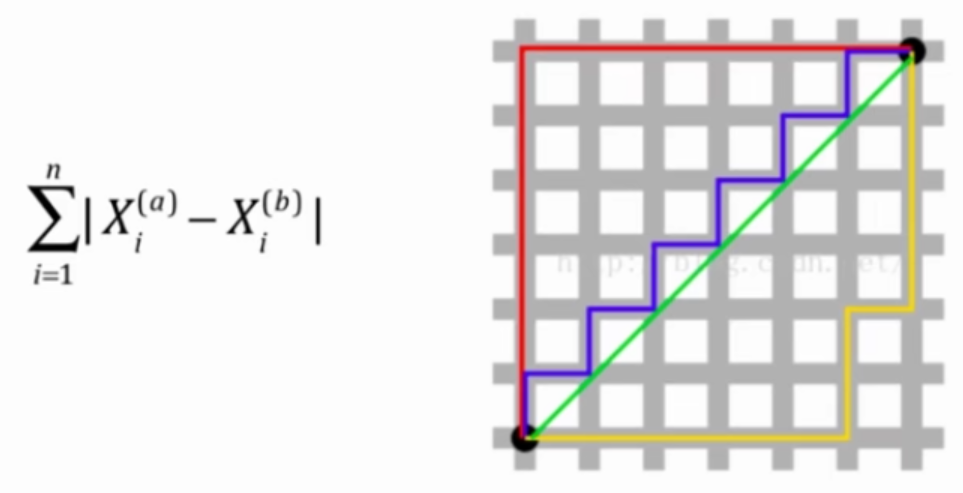
- 欧拉距离与曼哈顿距离的数学形式一致性
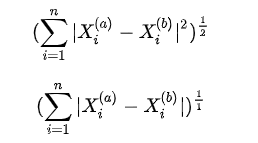
- 明可夫斯基距离 Minkowski distance
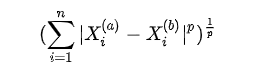
把欧拉距离和曼哈顿距离进一步抽象,得到以下公式
- p = 1: 曼哈顿距离
- p = 2: 欧拉距离
- p > 2: 其他数学意义
%%time
best_p = -1
best_score = 0.0
best_k = -1
for k in range(1, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights="distance", p = p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_p = p
print("best_k = ", best_k)
print("best_score = ", best_score)
print("best_p = ", best_p)
输出结果:
best_k = 3
best_score = 0.9888888888888889
best_p = 2
Wall time: 9.78 s
网格搜索
上面我们通过多层for循环来得到最好的超参数,其实sklearn提供了网格搜索的方法来得到此结果
数据准备
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
# 加载手写识别数据
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 测试和训练数据集分类
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
使用网格搜索
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 网格定义
param_grid = [
{
'weights':['uniform'],
'n_neighbors': [i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)]
}
]
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid)
%%time
grid_search.fit(X_train, y_train)
Wall time: 1min 33s
查看运行结果
grid_search.best_score_ # 最好的分数 0.9853862212943633
grid_search.best_params_ # 最好的分类器的超参数 {'n_neighbors': 3, 'p': 3, 'weights': 'distance'}
grid_search.best_estimator_ # 最好的分类器
# KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
# metric_params=None, n_jobs=1, n_neighbors=3, p=3,
# weights='distance')
- 注意1:这里的搜索结果与前面我们自己编写的网格搜索得到的结果不同,是因为评价方法不同,不用care
- 注意2:以_结尾的参考表示计算得到的参数,而不是用户输入的参数
knn_clf = grid_search.best_estimator_
knn_clf.score(X_test, y_test)
输出结果: 0.9833333333333333
其它GridSearchCV参数
- njobs:使用多核计算
- verbose:中间过程的打印级别,值越大信息越详细
%%time
# n_jobs=-1表示使用计算机所有核
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1,verbose=2)
grid_search.fit(X_train, y_train)
中间打印信息为
Fitting 3 folds for each of 60 candidates, totalling 180 fits
[Parallel(n_jobs=-1)]: Done 17 tasks | elapsed: 6.6s
[Parallel(n_jobs=-1)]: Done 138 tasks | elapsed: 22.0s
[Parallel(n_jobs=-1)]: Done 180 out of 180 | elapsed: 27.9s finished
更多的距离定义
对应KNeighborsClassifier的metric参数,更多值可以查看sklearn.neighbors.DistanceMetric类,默认使用minkowski明可夫斯基距离
- 向量空间余弦相似度 Cosine Similarity
- 调整余弦相似度 Adjusted Cosine Similarity
- 皮尔森相关系数 Pearson Correlation Coefficient
- Jaccard相似系数 Jaccard Coefficient

 浙公网安备 33010602011771号
浙公网安备 33010602011771号