





机器学习之KNN算法入门
简介
k近邻算法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。
它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。
一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
KNN算法是非常适合入门机器学习的算法,因为
- 思想极度简单
- 应用数学知识少
- 效果好
- 可以解释机器学习算法使用过程中的很多细节问题
- 更完整地刻画机器学习应用的流程
代码实现KNN算法
import matplotlib.pyplot as plt
import numpy as np
# 原始训练数据如下
raw_data_X = [[3.39, 2.33],
[3.11, 1.78],
[1.34, 3.36],
[3.58, 4.67],
[2.28, 2.86],
[7.42, 4.69],
[5.74, 3.53],
[9.17, 2.51],
[7.79, 3.42],
[7.93, 0.79]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 待求数据如下
x = np.array([8.09, 3.36])
数据准备
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color = 'g')
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color = 'r')
plt.scatter(x[0], x[1], color = 'b')
plt.show()
效果
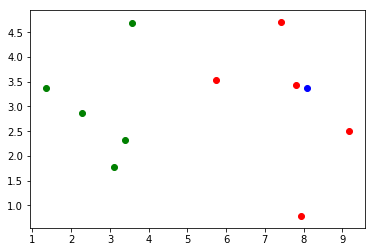
KNN过程
假设有a, b两个点,平面中两个点之间的欧拉距离为:
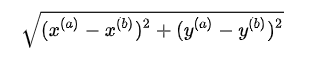
立体中两个点的欧拉距离为:
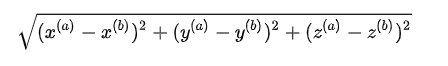
任意维度中两个点的欧拉距离为:
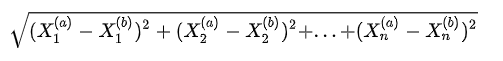
或
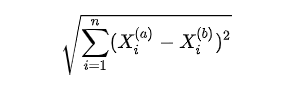
其中上标a, b代码第a, b个数据。下标1, 2代码数据的第1, 2个特征
代码如下:
# 计算距离
from math import sqrt
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]
# 得到 [8, 7, 5, 6, 9, 3, 0, 1, 4, 2],距离最近的点在原来数组中的索引
nearest = np.argsort(distances)
# [1, 1, 1, 1, 1, 0] 找出距离最近的k个点的y值
k = 6
topK_y = [y_train[i] for i in nearest[:k]]
# 统计出其中最多的1个元素
from collections import Counter
votes = Counter(topK_y)
# votes.most_common(1)结果为[(1, 5)]
predict_y = votes.most_common(1)[0][0]
运行结果:predict_y = 1
什么是机器学习
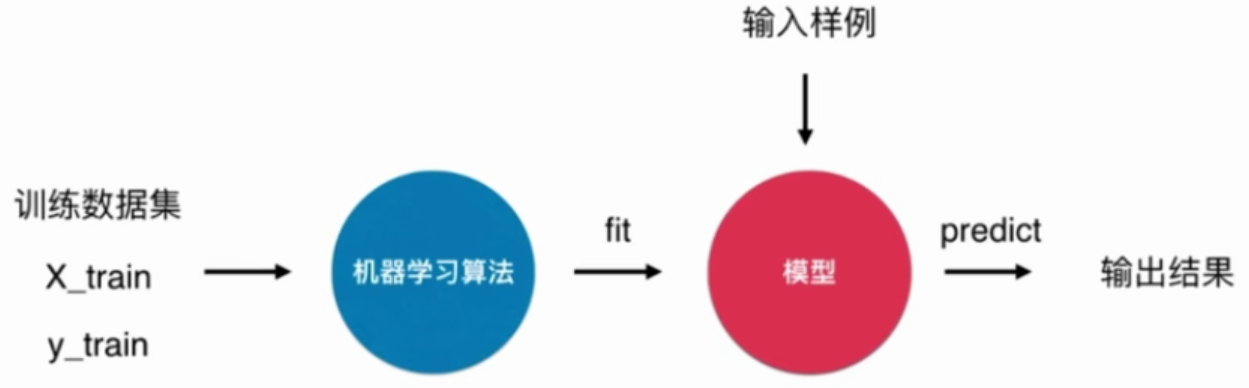
KNN是一个不需要训练的算法
KNN没有模型,或者说训练数据就是它的模型
使用scikit-learn中的kNN
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
# 得到模型
kNN_classifier.fit(X_train, y_train)
# 数组转换为矩阵
X_predict = x.reshape(1, -1)
# 得到预测值 array([1])
y_predict = kNN_classifier.predict(X_predict)
重新整理我们的kNN的代码
封装成sklearn风格的类,封装到kNN.py中
import numpy as np
from math import sqrt
from collections import Counter
class kNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "K must be valid!"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], "the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], "the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict, 返回表示X_predict的结果向量"""
assert self._X_train is not None and self._X_train is not None, "must fit before predict"
assert self._X_train.shape[1] == X_predict.shape[1], "the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待测数据x,返回x的预测结果"""
assert self._X_train.shape[1] == x.shape[0], "the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train-x)**2)) for x_train in self._X_train]
nearst = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearst[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
加载python文件
%run kNN.py
使用kNNClassifier
knn_clf = kNNClassifier(k=6)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_predict)
判断机器学习算法的性能
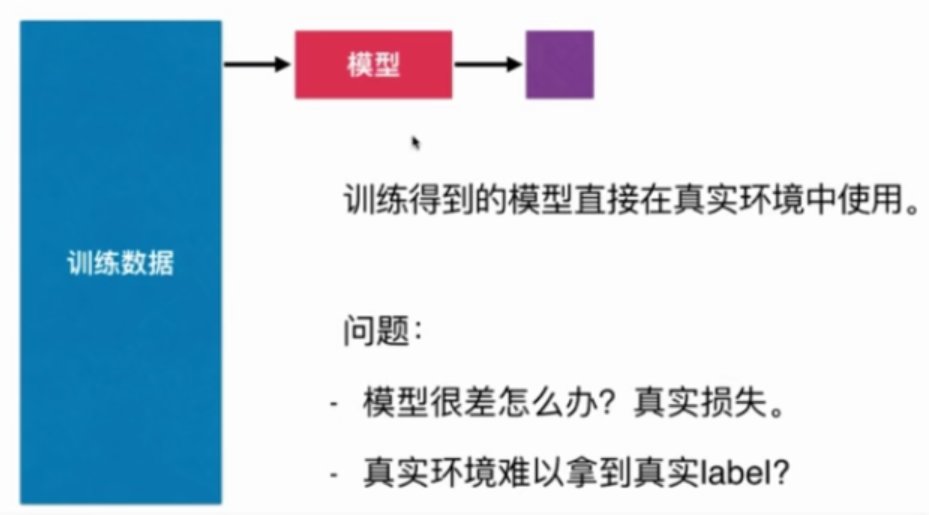
改进:训练和测试数据集的分离,train test split
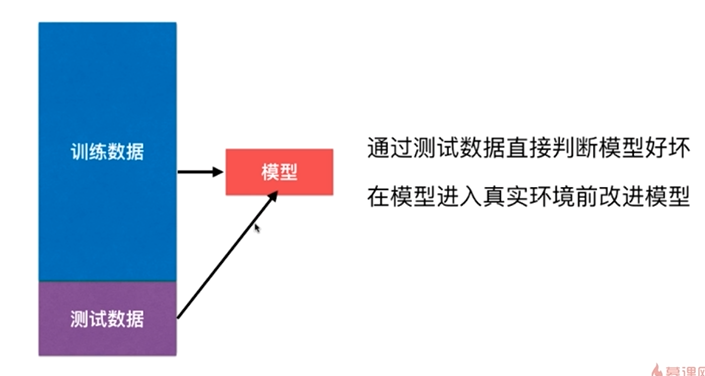
准备iris数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X.shape为(150, 4),y.shape为(150,)
train_test_split
- 注意1:本例中训练数据集的数据如下,因此按顺序取前多少个样本不会有很好的效果,要先对数据乱序化
- 注意2:本例中X和y是分离的,但它们不能分别乱序化。乱序化的同时要保证样本和标签是对应的。
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
在Notebook实现
# 对一个[0,len(X)]的数组乱序,np.random.permutation(5)结果为array([0, 1, 3, 2, 4])
shuffle_indexes = np.random.permutation(len(X))
# 前20%为测试数据集,后80%为训练数据集
test_ratio = 0.2
test_size = int(len(x) * test_ratio)
test_indexes = shuffle_indexes[:test_size]
train_indexes = shuffle_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
将train_test_split封装成函数
封装到之前kNN.py文件中
import numpy as np
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将X和y按照test_ratio分割成X_train,X_test,y_train,y_test"""
assert X.shape[0] == y.shape[0], "the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, "test_ration must be valid"
if seed:
np.random.seed(seed)
shuffle_indexes = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_indexes = shuffle_indexes[:test_size]
train_indexes = shuffle_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
KNN结合train_test_split计算分类准确度
加载python文件
%run kNN.py
计算分类准确度
# 获取测试和训练分离数据
X_train, X_test, y_train, y_test = train_test_split(X, y)
my_Knn_clf = kNNClassifier(k = 3) # kNNClassifier在上一节实现
my_Knn_clf.fit(X_train, y_train)
y_predict = my_Knn_clf.predict(X_test)
accuracy = sum(y_predict == y_test) / len(y_test)
得到准确度为0.9666666666666667
使用sklearn中的train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
使用accuracy来评价KNN算法对手写数据集的分类效果
加载手写数据集
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
digits的内容如下:
输入:digits.keys()
输出:dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])
输入:print(digits.DESCR)
输出:digits的官方说明
输入:digits.data.shape()
输出:(1797, 64)
输入:digits.target.shape()
输出:(1797,)
输入:digits.target_names
输出:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
X = digits.data
some_digit = X[666]
some_digit_image = some_digit.reshape(8, 8)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary)
plt.show()
输出:第666个样本的图像
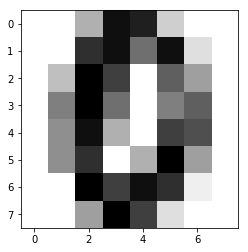
train_test_split + KNN + accuracy
%run kNN.py
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_ratio=0.2)
my_knn_clf = kNNClassifier(k=3)
my_knn_clf.fit(X_train, y_train)
y_predict = my_knn_clf.predict(X_test)
accuracy = sum(y_predict == y_test) / len(y_test)
得到准确度
使用scikit-learn中的accuracy_score
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_predict) # 得到准确度
也可以
knn_clf.score(X_test,y_test)
不需要得到预测值这个中间结果
参考
机器学习实战教程(一):K-近邻算法(史诗级干货长文)
KNN - K近邻算法 - K-Nearest Neighbors

 浙公网安备 33010602011771号
浙公网安备 33010602011771号