





直播平台三度关系推荐项目介绍
项目效果
在直播平台中,用户在主播页面关注该主播时,粉丝状态栏下方插入三度关系推荐模块,显示该主播的粉丝同时又关注了哪些主播,按照推荐重合度且满足一定的筛选条件进行择优展示,这样推荐的主播才是用户最可能会喜欢的。
这样可以帮助用户发现更多他喜欢的主播,促进用户活跃,进而挖掘用户消费潜力。
项目需求分析
想要实现前面所说的三度关系推荐,是需要有数据来支撑的,那么数据从哪里来呢?
这就涉及到我们的第一块内容,数据采集:
我们需要将项目中需要的所有数据全部采集过来,包括离线数据和实时数据
这些数据采集过来以后就需要涉及第二块内容了,数据存储,
离线数据一般存储到分布式文件系统中,实时数据一般存储到消息队列中
数据存储起来以后就需要涉及到数据计算了,
数据计算模块对前面存储起来的数据进行计算,分为离线计算和实时计算,计算之后的结果数据还会进行存储
计算出来结果之后就会涉及到数据展示了
将数据在页面中展现,查看最终的推荐效果
所以这个项目的四个大模块之间的关系是这样的
在这里我们先从整体上对这个项目进行了一个划分,后面还会有更详细的划分。
技术选型
接下来我们先针对这四个模块分析一下具体需要使用的技术框架,俗称技术选型。
数据采集:FileBeat+Flume+Kafka+Sqoop
我们首先来看一下数据采集工具的选择
针对日志数据目前业内常用的采集工具有 Apache开源的顶级项目Flume,还有elastic公司的Logstash,Filebeat等组件
在这里我把Kafka也列出来了,但是kafka并不算是采集工具,只是它一般会和采集工具一块使用,所以就在这里一块列出来了,以及这个Sqoop组件
首先是Flume
Flume是基于java语言实现的,Flume主要由source、channel和sink这三个组件组成,针对这三个组件,Flume中提供了很多实现,针对source有基于文件的、基于socket的、基于kafka的等等还有很多,我们常用的数据源 Flume几乎都提供了支持
针对channel提供的有常见的基于文件的、基于内存的
针对Sink有基于hdfs的,基于kafka的等等还有很多,我们常用的存储系统几乎都提供了支持
就算是部分特殊的source和sink, Flume没有提供支持,那也没有关系,Fluem允许我们自定义这些组件,由于Flume是基于java的,所以开发这些自定义的组件也没有多大问题。所以目前在企业中针对日志数据采集这一块,Flume占据了主要地位。
接下来我们来看一下Logstash
Logstash是基于Jruby实现的,jruby是ruby语言的java实现,Logstash的架构有点类似于Flume,它主要由输入、输出、和过滤组成,这里的输入和输出类似于Flume中的source和sink,logstash也提供了很多输入和输出的支持,常见数据源和存储系统也都是支持的,并且logstash中还提供了强大的过滤功能,可以将采集到的数据进行一些处理之后再写出去。
Flume中的拦截器也可以实现类似的功能。
Logstash可以和elasticseach、kibana,轻松的实现一个日志收集、检索、展现平台,非常方便,俗称elk全家桶。
那其实分析到这,我们会发现Flume和logstash还是非常相似的,但是他们两个的典型应用场景是有一些区别的
logstash常用的场景是帮助运维人员采集服务器自身的运行日志,方便运维人员排查服务器的问题,这种场景下,对数据的完整性和安全性要求不是很高,因为logstash内部没有一个持久化的队列,所以在异常情况下,是可能出现数据丢失的问题的。
而Flume是有自己内部的ack机制确保这个问题,所以可以用于一些更重要的业务日志采集
接下来我们看一下FileBeat
Filebeat是采用go语言开发,仅支持文件数据采集,它可以将文件中的数据采集到kafka、es等常见存储系统中,它会记录文件采集的offset信息,就算fileebat采集进程挂掉也不会导致数据丢失。并且它还是一个轻量级采集工具
我们前面分析的Flume和logstash都是一些重量级的采集工具。
在某些特定场景下轻量级组件会更合适。
Filebeat和logstash同属于elastic公司,这个公司提供了很多beat组件,Filebeat只是其中一个,因为我们的数据采集主要是基于文件的,所以在这里就只分析了这个filebeat。
总结
目前为止,这三个采集工具我们都分析过了,flume、logstash都是属于重量级的组件,都是基于jvm虚拟机运行的,filebeat是一个轻量级的组件,是基于go语言的,从语言层面来分析,go语言开发的程序性能消耗是比基于jvm虚拟机运行的程序要小的,并且我们也在实际的服务器上进行了测试,相同数据规模下,filebeat的内存和cpu消耗是比flume和logstash低的。
那我们就直接选择filebeat了吗?并不是,因为filebeat的优点是性能消耗低,但是他的功能是有点弱的
所以我们在实际工作中会这样做,在前端业务机器上部署filebeat将日志数据采集到消息队列中,因为这个时候的要求是尽可能少的占用服务器资源,保证服务器上的其它业务正常运行
数据到了消息队列以后,后面我们可能还需要对数据进行一些简单的预处理之后再存储到不同的地方,
所以这个地方就可以使用Flume了,因为Flume提供了丰富的source和sink,并且也可以使用拦截器对数据进行一些简单的处理,这个时候就不需要太纠结性能消耗了,因为flume是部署在单独的服务器上面,不会对其他应用程序造成影响。
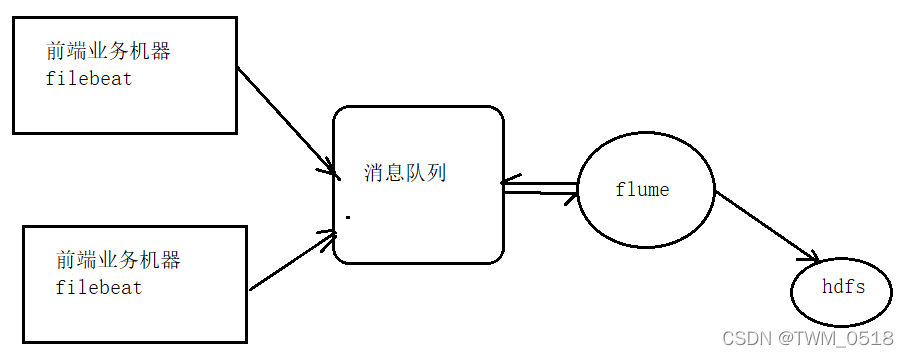
所以在这里我们就需要选择Filebeat和flume了,
这里的消息队列我们就直接使用kafka了,因为kafka是大数据领域中最常用的消息队列了。
所以 我们最终的选择就是FileBeat+Kafka+Flume,这就是针对日志数据采集工具的选择。
后面我们也会涉及到数据库数据的采集,在我们这个项目中,需要从数据库中采集的数据量比较小,可以选择使用sqoop,或者我们使用mysql -e命令直接导出数据也是可以的,上一个项目我们已经使用过sqoop采集mysql中的数据了,在这我们就使用一个不一样的,自己开发脚本使用mysql的命令导出数据。不过我们在最后是需要把HDFS中的结果数据导出到MySQL中,这个时候还是需要用到Sqoop的。
数据存储:HDFS+MySQL+Neo4j
前面把数据采集工具分析完了,下面我们来分析一下数据存储系统的选择
我们采集到的数据最终会存储到分布式文件系统中,这个分布式文件系统一般就直接选择hadoop中的hdfs了,这个就不需要额外的对比了,因为我们在搭建大数据平台的时候,hdfs已经安装好了,并且他也可以和很多采集工具和计算框架无缝衔接,所以大数据领域的分布式存储一般都是使用hdfs。
当然了目前一些大的厂商也有一些分部式存储的服务,例如亚马逊的s3,也可以选择使用这些服务,但是这样的话,针对数据计算就不太友好了,分布式计算框架无法实现本地计算,因为数据和计算节点不在一块。
所以在这离线数据我们就使用HDFS来存储了
我们的计算框架计算的结果数据,有一些是需要和前端交互的,这些数据前期可以选择存储到MySQL中。
在维护用户三度关系数据的时候,如果使用普通的关系型数据库进行存储的话会造成很多数据冗余,并且查询起来也非常麻烦,所以一般会使用一些图数据库
这里面的Graphx和Gelly,Graphx是spark中的图计算、Gelly属于flink中的图计算,它们只能实现分布式图计算,不能保存图数据,所以并不满足我们的需求
下面是Neo4j、OrientDB、Titan

这些是属于图领域中的图数据库
Neo4j是目前人气最高的图数据库,它可支持高度扩展,完全支持ACID
它提供的Cypher查询语言是比较人性化的,非常容易上手使用。
它支持社区版和商业版,社区版不支持分布式,商业版支持分布式。
Neo4j 入门相当简单,学习成本比较低,并且比较稳定。
还有就是Neo4j对各种语言的支持比较好,java、python等语言都支持,并且官方提供的也有一个connector插件可以实现spark直接操作neo4j,非常方便。
在这我们主要考虑到易用性以及快速上线,所以Neo4j是最优的选择。
那最终针对存储系统的选择就是:HDFS+MySQL+Neo4j
数据计算
那接下来我们来看一下数据计算框架的选择
目前大数据领域最常见的几种计算框架包括:MapReduce、Storm、Spark、Flink
MapReduce
其中mapreduce是第一代计算引擎,它主要针对离线数据进行计算,
由于mapreduce计算框架的模型是固定的,针对复杂的计算需要开发多个mapreduce任务,代码量比较多,也比较麻烦,并且它的计算是基于磁盘的,计算效率也比较低,所以现在已经很少使用了
Storm
那接下来看一下storm这个计算框架,storm是一个比较早的实时计算框架,可以实现真正意义上的实时处理,在前期的数据实时计算领域立下了汗马功劳,但是由于此框架太过于独立,没有自己的生态圈,所以最近这几年日渐没落
Spark
接下来看一下spark这个计算框架,他是一个分布式的内存计算框架,支持离线和实时数据计算,由于它是基于内存的,所以它的计算性能非常高
但是在这需要注意一下,虽然spark支持实时计算,但是它的实时计算并不是真正意义上的实时,这是由于它底层的计算模型决定的,spark最快只能支持到秒级别的实时计算,相当于一秒执行一个小型的批处理任务。
Flink
最后我们来看一下flink这个计算框架,flink属于最近新兴起的一个流式计算框架,它侧重的是实时计算,
flink在支持实时计算的基础上也可以实现离线数据计算。所以说flink也是支持离线和实时数据计算的。
总结
在我们这个项目中,既需要离线计算,也需要实时计算,所以单纯的使用mapreduce或者storm都不合适,所以需要在spark和flink中进行选择
当时我们在开发这个项目的时候,Flink才刚出来,还不是很稳定,并且我们团队内部也是刚开始接触Flink,之前我们一直是使用Spark,所以为了保证项目快速稳定上线,我们当时决定先使用Spark,等后期对项目进行迭代优化的时候再考虑使用Flink。
所以在这我们选择使用Spark
数据展现
数据展现模块我们不需要实现,这块是由Andriod开发组和IOS开发组负责的,我们只需要把结果数据计算好存储起来就可以了。
技术选项总结
在对各个模块进行技术选型的时候,不要盲目的追新。
要根据具体的业务场景和不同框架的特点进行选择,同时还要考虑已经在使用的成熟的框架,不要盲目追求一些所谓的好的、新的框架,因为技术成本也要考虑。
所以技术选型,不单单是选技术,是要在结合业务场景的前提下进行选择。
整体架构设计
前面我们把技术选型搞定了,下面我们来看一下项目的整体架构设计
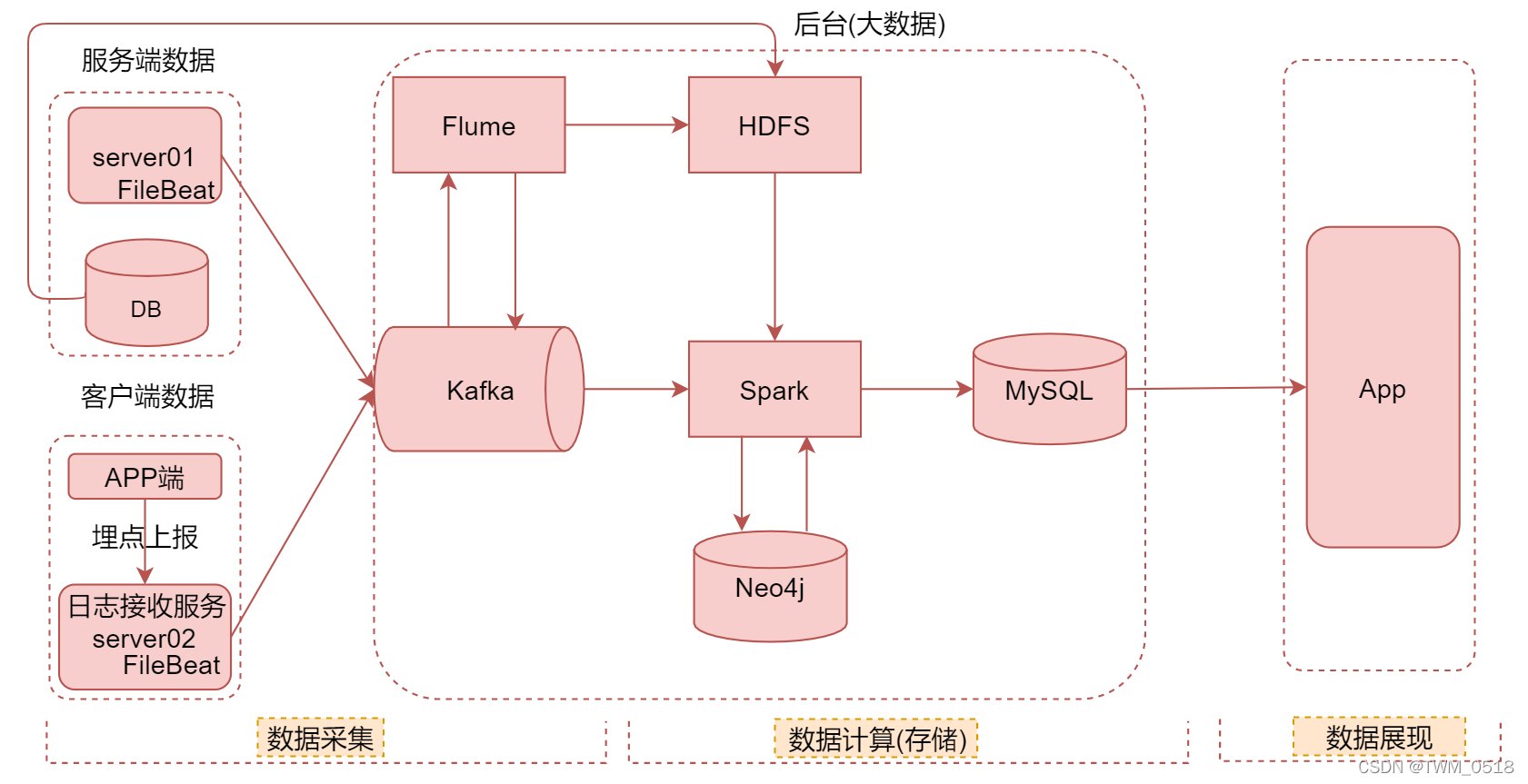
在这里我把项目分为了3个模块
数据采集、数据计算(存储) 和数据展现
因为计算以后就涉及到存储,所以把这两个划分到一块了
接下来我们来详细分析一下项目的整体流程
数据采集模块
首先是数据采集模块,数据采集模块的数据包含两大类,服务端数据和客户端数据,
其中服务端数据中包含服务器中接口调用时记录的日志数据和数据库中的数据
在这里注意一下
针对服务端日志数据的采集是在提供接口服务的机器上部署filebeat来采集,这样的机器会有上百台,在这里我们先用一台server01来表示,这里的DB表示的就是mysql数据库。
接下来是客户端数据
客户端数据就是用户使用app时上报的一些用户行为日志
例如打开、关闭APP,以及在app中的滑动、点击等行为其实都会记录日志,这些数据客户端会通过接口定时上报,接口收到请求之后,会把请求中包含的日志信息记录到本地文件中,然后使用filebeat进行采集。
也就是说我们会在server02上部署接口服务,接收客户端上报的日志数据。
这样其实就可以统一流程,针对服务端日志数据和客户端日志数据,最终都是通过filebeat采集到kafka中
针对服务端数据库里面的数据,我们会通过脚本导入到HDFS上
filebeat采集的实时数据导入到kafka以后,还会通过flume对数据进行分发处理,以及落盘到HDFS的操作,落盘就是存储的意思
针对这里面的数据分发的详细内容,我们在后面开发数据采集模块的时候会详细分析。
这就是数据采集模块的主要内容。
数据计算(存储)模块
那接下来我们来看一下数据计算(存储)模块
计算模块主要是利用Spark,针对kafka中的数据进行实时计算,针对HDFS中的数据进行离线计算,
在计算的时候还会和neo4j图数据库中的数据进行交互,既会向里面写数据,也会从里面读取数据。
最后会被把Spark计算的结果使用sqoop导出到MySQL中。
针对计算这块,一共有六七种计算指标,具体这些计算指标,我们在开发数据计算模块的时候会详细分析。
这就是计算模块的大致流程。
数据展现模块
最后一个是数据展现,在这个模块中可以看到我们最终的项目效果,这里其实就是一个手机端的项目。
总结
这就是我们这个项目的整体架构设计。
注意:这个架构里面其实存在三个主要的问题
- 针对实时计算,Spark其实不是最优的选择,最好是使用Flink
- 针对结果数据存储,mysql也不是最优的选择,最好是使用Redis
- 针对数据展现,直接查询mysql中的数据也不是最优的选择,最好是开发数据接口,对外提供接口查询数据
不过我们为了快速迭代上线,所以前期会使用相对来说比较简洁的架构,先把功能快速上线,后面再迭代优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号