





数据可视化之Zeppelin
前言
数据可视化这块不是项目的重点,不过为了让大家能有一个更加直观的感受,我们可以选择一些现成的数据可视化工具实现。
我们前面分析过,想要查询hive中的数据可以使用hue,不过hue无法自动生成图表。
所以我们可以考虑使用Zeppelin,Zeppelin是一个Apache的孵化项目.一个基于web的笔记本,支持交互式数据分析。你可以用SQL、Scala等做出数据驱动的、交互、协作的文档。(类似于ipython notebook,可以直接在浏览器中写代码、笔记并共享)
针对一些复杂的图表,可以选择定制开发,使用echarts等组件实现
安装部署
下载
注意:不要使用Zeppelin0.8.2版本,这个版本有bug,无法使用图形展现数据。这里我们使用zeppelin-0.9.0-preview1这个版本
下载地址,安装包比较大,1.5G左右,这里我们使用阿里云镜像。
修改配置
复制mv zeppelin-env.sh.template zeppelin-env.sh
mv zeppelin-site.xml.template zeppelin-site.xml
vim zeppelin-site.xml
将默认的127.0.0.1改为0.0.0.0 否则默认情况下只能在本机访问zeppline,监听端口默认8080,如果已经被使用了,修改为其他端口,这里我们修改为9090。
复制<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>9090</value>
</property>
增加Hive依赖jar包
由于我们需要使用Zepplien连接hive,它里面默认没有集成Hive的依赖jar包,所以最简单的方式就是将Hive的lib目录中的所有jar包全复制到Zeppline中的interpreter/jdbc目录中
启动
复制bin/zeppelin-daemon.sh start
停止
复制bin/zeppelin-daemon.sh stop
界面参数配置
Zepplin启动之后可以通过9090端口进行访问 http://bigdata01:9090/
在使用之前需要先配置hive的基本信息
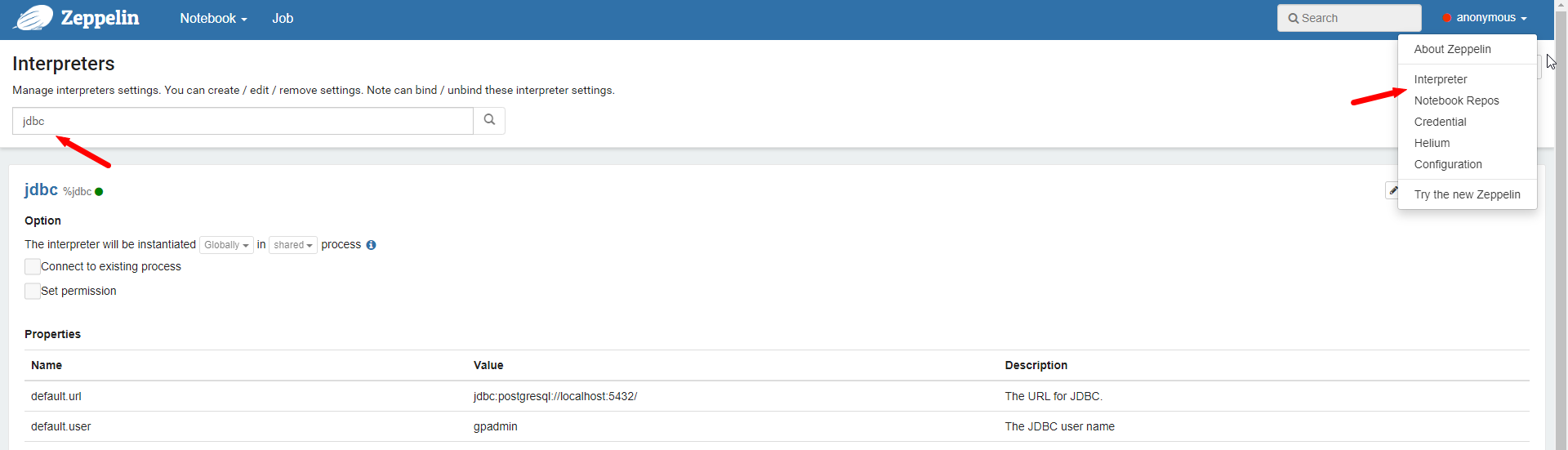
修改这四项的内容即可,这里的内容其实就是我们之前学习hive的jdbc操作时指定的参数
复制参数 值 解释
default.url jdbc:hive2://ip:10000 里面的ip是启动hiveserver2服务的机器ip
default.user root
default.password any 注意:密码随便填即可
default.driver org.apache.hive.jdbc.HiveDriver
注意:需要在服务器上启动hiveserver2服务,否则在zeppline中连不上hive
复制bin/hiveserver2
Zepplin的使用
创建一个note,类似于工作台的概念
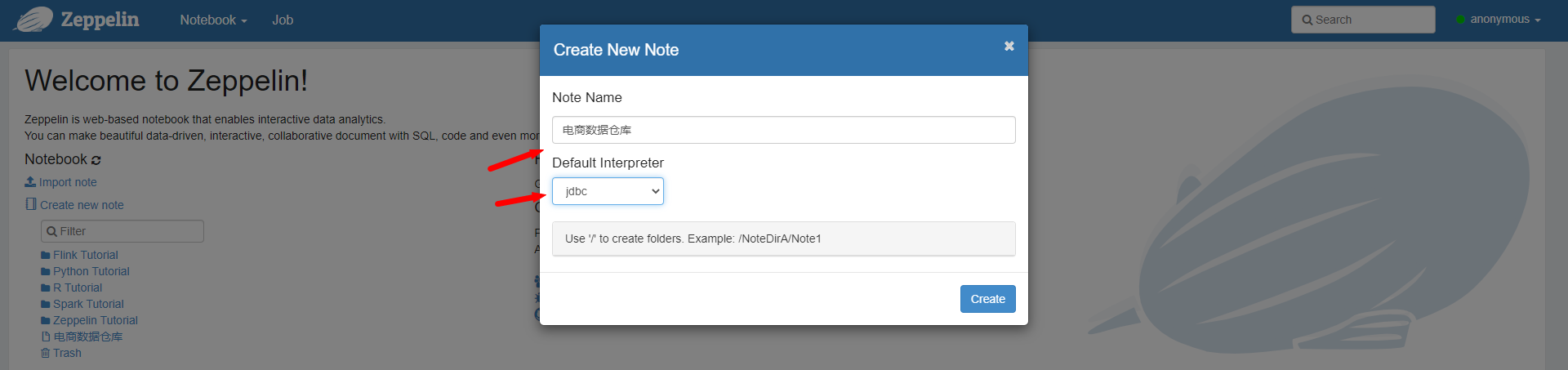
此时就可以在里面写SQL了。
如果想以图形的形式展示结果,点击对应图形的图标即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
· 零经验选手,Compose 一天开发一款小游戏!
2022-06-03 Kotlin学习之反射
2022-06-03 Kotlin学习之Kotlin和Java之间相互调用