数据仓库之订单拉链表实战
什么是拉链表
针对订单表、订单商品表,流水表,这些表中的数据是比较多的,如果使用全量的方式,会造成大量的数据冗余,浪费磁盘空间。
所以这种表,一般使用增量的方式,每日采集新增的数据。
在这注意一点:针对订单表,如果单纯的按照订单产生时间增量采集数据,是有问题的,因为用户可能今天下单,明天才支付,但是Hive是不支持数据更新的,这样虽然MySQL中订单的状态改变了,但是Hive中订单的状态还是之前的状态。
想要解决这个问题,一般有这么几种方案:
- 第一种:每天全量导入订单表的数据,这种方案在项目启动初期是没有多大问题的,因为前期数据量不大,但是随着项目的运营,订单量暴增,假设每天新增1亿订单,之前已经累积了100亿订单,如果每天都是全量导入的话,那也就意味着每天都需要把数据库中的100多亿订单数据导入到HDFS中保存一份,这样会极大的造成数据冗余,太浪费磁盘空间了。
- 第二种:只保存当天的全量订单表数据,每次在导入之前,删除前一天保存的全量订单数据,这种方式虽然不会造成数据冗余,但是无法查询订单的历史状态,只有当前的最新状态,也不太好。
- 第三种:拉链表,这种方式在普通增量导入方式的基础之上进行完善,把变化的数据也导入进来,这样既不会造成大量的数据冗余,还可以查询订单的历史状态。
拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓 拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有历史变化的信息。
下面就是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期。
我们可以使用这张表拿到当天的最新数据以及之前的历史数据
用户编号 手机号码 start_time end_time 解释
001 1111 2026-01-01 9999-12-31 初始数据
002 2222 2026-01-01 2026-01-01 初始数据
003 3333 2026-01-01 9999-12-31 初始数据
002 2333 2026-01-02 9999-12-31 修改
004 4444 2026-01-03 9999-12-31 新增
说明:
start_time 表示该条记录的生命周期开始时间,end_time 表示该条记录的生命周期结束时间;
end_time ='9999-12-31’表示该条记录目前处于有效状态;
如果查询当前所有有效的记录,则使用 SQL
select * from user where end_time ='9999-12-31'
如果查询 2026-01-02 的历史快照【获取指定时间内的有效数据】,则使用SQL
select * from user where start_time <= '2026-01-02' and end_time >= '2026-01-02'
这就是拉链表。
如何制作拉链表
那针对我们前面分析的订单表,希望使用拉链表的方式实现数据采集,因为每天都保存全量订单数据比较浪费磁盘空间,但是只采集增量的话无法反应订单的状态变化。
所以需要 既采集增量,还要采集订单状态变化了的数据。
针对订单表中的订单状态字段有这么几个阶段
未支付
已支付
未发货
已发货
在这我们先分析两种状态: 未支付和已支付。
我们先举个例子:
假设我们的系统是2026年3月1日开始运营的
那么到3月1日结束订单表所有数据如下:
订单id 创建时间 更新时间 订单状态 解释
001 2026-03-01 null 未支付 新增
002 2026-03-01 2026-03-01 已支付 新增
3月2日结束订单表所有数据如下:
订单id 创建时间 更新时间 订单状态 解释
001 2026-03-01 2026-03-02 已支付 修改
002 2026-03-01 2026-03-01 已支付
003 2026-03-02 2026-03-02 已支付 新增
基于订单表中的这些数据如何制作拉链表?
实现思路
1:首先针对3月1号中的订单数据构建初始的拉链表,拉链表中需要有一个start_time(数据生效开始时间)和end_time(数据生效结束时间),默认情况下start_time等于表中的创建时间,end_time初始化为一个无限大的日期9999-12-31
将3月1号的订单数据导入到拉链表中。
此时拉链表中数据如下:
订单id 订单状态 start_time end_time
001 未支付 2026-03-01 9999-12-31
002 已支付 2026-03-01 9999-12-31
2:在3月2号的时候,需要将订单表中发生了变化的数据和新增的订单数据整合到之前的拉链表中
此时需要先创建一个每日更新表,将每日新增和变化了的数据保存到里面
然后基于拉链表和这个每日更新表进行left join,根据订单id进行关联,如果可以关联上,就说明这个订单的状态发生了变化,然后将订单状态发生了变化的数据的end_time改为2026-03-01(当天日期-1天)
然后再和每日更新表中的数据执行union all操作,将结果重新insert到拉链表中
最终拉链表中的数据如下:
订单id 订单状态 start_time end_time
001 未支付 2026-03-01 2026-03-01
002 已支付 2026-03-01 9999-12-31
001 已支付 2026-03-02 9999-12-31
003 已支付 2026-03-02 9999-12-31
解释:
因为在3月2号的时候,订单id为001的数据的订单状态发生了变化,所以拉链表中订单id为001的原始数据的end_time需要修改为2026-03-01。
然后需要新增一条订单id为001的数据,订单状态为已支付,start_time为2026-03-02,end_time为9999-12-31。
还需要将3月2号新增的订单id为003的数据也添加进来。
基于订单表的拉链表实现
下面我们开始实现:
1:首先初始化2026-03-01、2026-03-02和2026-03-03的订单表新增和变化的数据,ods_user_order(直接将数据初始化到HDFS中),这个表其实就是前面我们所说的每日更新表
注意:这里模拟使用sqoop从mysql中抽取新增和变化的数据,根据order_date和update_time这两个字段获取这些数据,所以此时ods_user_order中的数据就是每日的新增和变化了的数据。
2:创建拉链表,基于每日更新订单表构建拉链表中的数据
3:向拉链表中添加数据
3.1:添加2026-03-01的全量数据至拉链表(初始化操作)
3.2:添加2026-03-02的新增及变化的数据至拉链表
3.3:添加2026-03-03的新增及变化的数据至拉链表
拉链表的性能问题
拉链表也会遇到查询性能的问题,假设我们存放了5年的拉链数据,那么这张表势必会比较大,当查询的
时候性能就比较低了
可以用以下思路来解决:
- 可以尝试对start_time和end_time做索引,这样可以提高一些性能。
- 保留部分历史数据,我们可以在一张表里面存放全量的拉链表数据,然后再对外暴露一张只提供近3个月数据的拉链表。
商品订单数据数仓总结
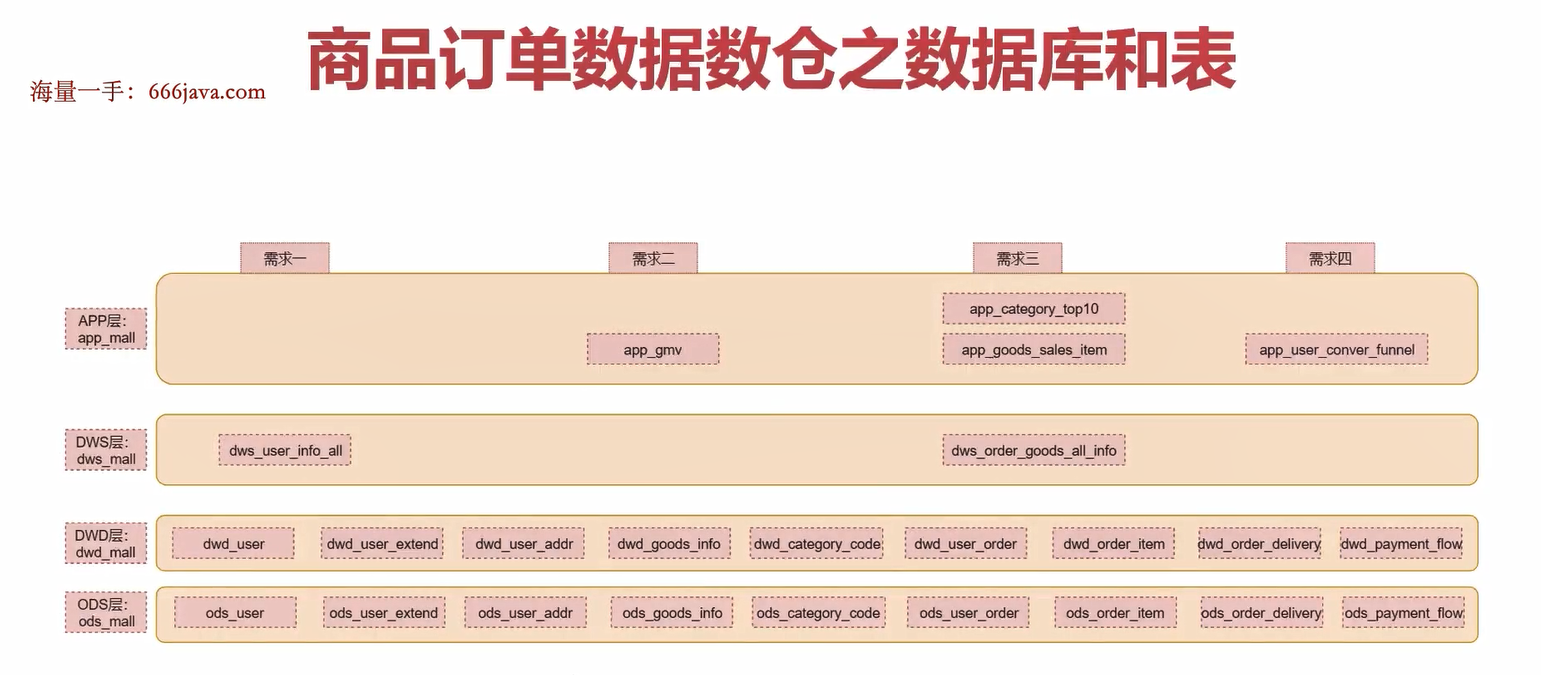
数据库和表梳理
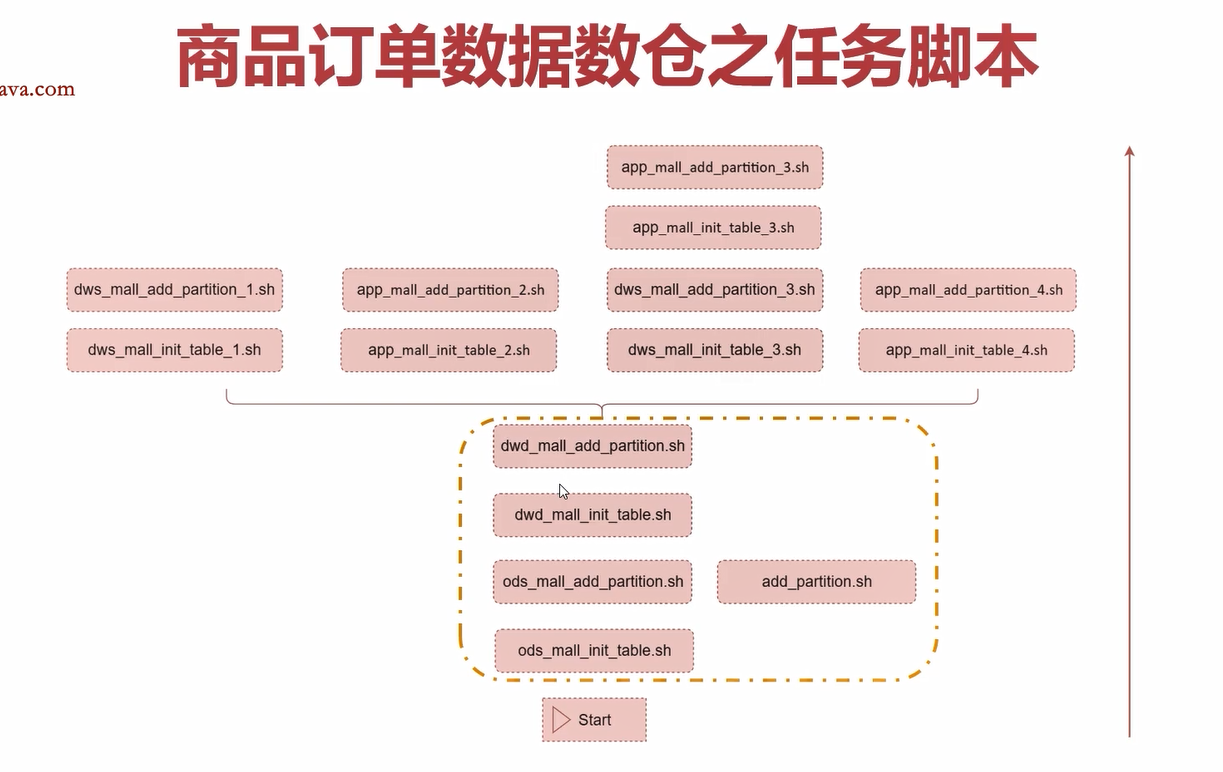
任务脚本梳理