





数据仓库之数据生成与采集
数据生成
我们需要先生成测试数据,一份是服务端数据,还有一份是客户端数据
【客户端数据】用户行为数据
首先我们模拟生成用户行为数据,也就是客户端数据,主要包含用户打开APP、点击、浏览等行为数据
用户行为数据:通过埋点上报,后端日志服务器(http)负责接收数据
埋点上报数据基本格式:
{
"uid":1001, //用户ID
"xaid":"ab25617-c38910-m2991", //手机设备ID
"platform":2, //设备类型, 1:Android-APP, 2:IOS-APP, 3:PC
"ver":"3.5.10", //大版本号
"vercode":"35100083", //子版本号
"net":1, //网络类型, 0:未知, 1:WIFI, 2:2G , 3:3G, 4:4G, 5:5G
"brand":"iPhone", //手机品牌
"model":"iPhone8", //机型
"display":"1334x750", //分辨率
"osver":"ios13.5", //操作系统版本号
"data":[ //用户行为数据
{"act":1,"acttime":1592486549819,"ad_status":1,"loading_time":100},
{"act":2,"acttime":1592486549819,"goods_id":"2881992"}
]
}
这个json串中的data是一个json数组,它里面包含了多种用户行为数据。
json串中的其它字段属于公共字段
注意:考虑到性能,一般数据上报都是批量上报,假设间隔10秒上报一次,这种数据延迟是可以接受的
所以在每次上报的时候,公共字段只需要报一份就行,把不同的用户行为相关的业务字段放到data数组中,这样可以避免上报大量的重复数据,影响数据上报性能,我们只需要在后期解析的时候,把公共字段和data数组总的每一条业务字段进行拼装,就可以获取到每一个用户行为的所有字段信息。
act代表具体的用户行为,在这列出来几种
act=1:打开APP
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
ad_status 开屏广告展示状态, 1:成功 2:失败
loading_time 开屏广告加载耗时(单位毫秒)
act=2:点击商品
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
goods_id 商品ID
location 商品展示顺序:在列表页中排第几位,从0开始
act=3:商品详情页
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
goods_id 商品ID
stay_time 页面停留时长(单位毫秒)
loading_time 页面加载耗时(单位毫秒)
act=4:商品列表页
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
loading_time 页面加载耗时(单位毫秒)
loading_type 加载类型:1:读缓存 2:请求接口
goods_num 列表页加载商品数量
act=5:app崩溃数据
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
生成数据的代码在这里:
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
/**
* 需求:生成用户行为数据(客户端数据),模拟埋点上报数据
*/
public class GenerateUserActionData {
public static void main(String[] args) {
//通过接口获取用户行为数据
String dataUrl = "http://data.xuwei.tech/d1/wh1";
JSONObject paramObj = new JSONObject();
//TODO code:校验码
paramObj.put("code", "JD3B37868104C5F2A");//校验码
paramObj.put("num", 100);//指定生成多少用户的行为数据
paramObj.put("date", "2026-01-01");//指定用户行为产生的日期
//{"data":[{"uid":"100001","ver":"3.0.0","data":"[{\"act\":4,\"loading_time\":823,\"goods_num\":9,\"acttime\":1577865686000,\"loading_type\":1},{\"act\":3,\"loading_time\":482,\"goods_id\":\"100090\",\"acttime\":1577865686000,\"stay_time\":4284},{\"act\":1,\"loading_time\":501,\"acttime\":1577865686000,\"ad_status\":1},{\"act\":3,\"loading_time\":598,\"goods_id\":\"100033\",\"acttime\":1577865686000,\"stay_time\":4537}]","display":"1334x750","model":"huawei21","net":5,"xaid":"ab25617-c38910-m1","brand":"huawei","osver":"5.1","vercode":"35100053","platform":2}]}
JSONObject dataObj = HttpUtil.doPost(dataUrl, paramObj);
System.out.println(dataObj.toJSONString());
//判断获取的用户行为数据是否正确
boolean flag = dataObj.containsKey("error");
if (!flag) {
//TODO 调用接口模拟埋点上报数据,这里的主机名需要改为实际机器的主机名(ip)
String uploadUrl = "http://bigdata01:8080/v1/ua";
//获取dataObj中的data属性的值
JSONArray resArr = dataObj.getJSONArray("data");
long start = System.currentTimeMillis();
System.out.println("===============start 上报数据==============");
//迭代接口返回的数据,一条一条模拟上报
for (int i = 0; i < resArr.size(); i++) {
JSONObject resObj = resArr.getJSONObject(i);
JSONObject res = HttpUtil.doPost(uploadUrl, resObj);
int status = res.getIntValue("status");
if (status != 200) {
System.err.println("数据上报失败:" + resObj.toJSONString());
} else {
System.out.println("数据上报成功:第 " + (i + 1) + " 条!");
}
}
System.out.println("===============end 上报数据==============");
long end = System.currentTimeMillis();
System.out.println("===============耗时: " + (end - start) / 1000 + "秒===============");
} else {
System.err.println("获取用户行为数据失败:" + dataObj.toJSONString());
}
}
}
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import okhttp3.ConnectionPool;
import okhttp3.MediaType;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.RequestBody;
import okhttp3.Response;
import java.util.concurrent.TimeUnit;
@Slf4j
public class HttpUtil {
private static final OkHttpClient okHttpClient;
static {
okHttpClient = new okhttp3.OkHttpClient.Builder()
.connectionPool(new ConnectionPool(50, 5L, TimeUnit.MINUTES))
.connectTimeout(30L, TimeUnit.SECONDS)
.readTimeout(30L, TimeUnit.SECONDS).build();
}
public static JSONObject doPost(String dataUrl, JSONObject paramObj) {
try {
MediaType jsonType = MediaType.parse("application/json");
String jsonRequestBody = paramObj.toJSONString();
RequestBody requestBody = RequestBody.create(jsonType, jsonRequestBody);
Request request = new Request.Builder()
.url(dataUrl)
.post(requestBody)
.build();
Response response = okHttpClient.newCall(request).execute();
String resp = response.body().string();
return JSON.parseObject(resp);
} catch (Exception e) {
throw new RuntimeException("http请求失败", e);
}
}
}
校验码是假的,不可用
部署日志采集服务
模拟埋点上报数据的流程,代码在db_data_warehouse中的data_collect这个子项目中,将这个子项目打成jar包,部署到bigdata04服务器中,并且启动此HTTP服务。这个项目就是一个简单的springboot项目。
首先解析data属性的值,里面包含了多个用户的行为数据
并且每个用户的行为数据中还包含了多种具体的行为操作,因为客户端在上报数据的时候不是产生一条就上报一条,这样效率太低了,一般都会批量上报,所以内层json串中还有一个data参数,data参数的值是一个JSONArray,里面包含一个用户的多种行为数据
然后通过接口模拟上报数据,data_collect接口接收到数据之后,会对数据进行拆分,将包含了多个用户行为的数据拆开,打平,输出多条日志数据,最终的日志数据会保存在data_collect这个日志采集服务所在的机器上,通过logback记录到/data/log目录下面。
【服务端数据】商品订单相关数据
接下来需要生成商品订单相关数据,这些数据都是存储在mysql中的
注意:MySQL在这里我使用的版本是8.x
相关表名为:
订单表:user_order
商品信息表:goods_info
订单商品表:order_item
商品类目码表:category_code
订单收货表:order_delivery
支付流水表:payment_flow
用户收货地址表:user_addr
用户信息表:user
用户扩展表:user_extend
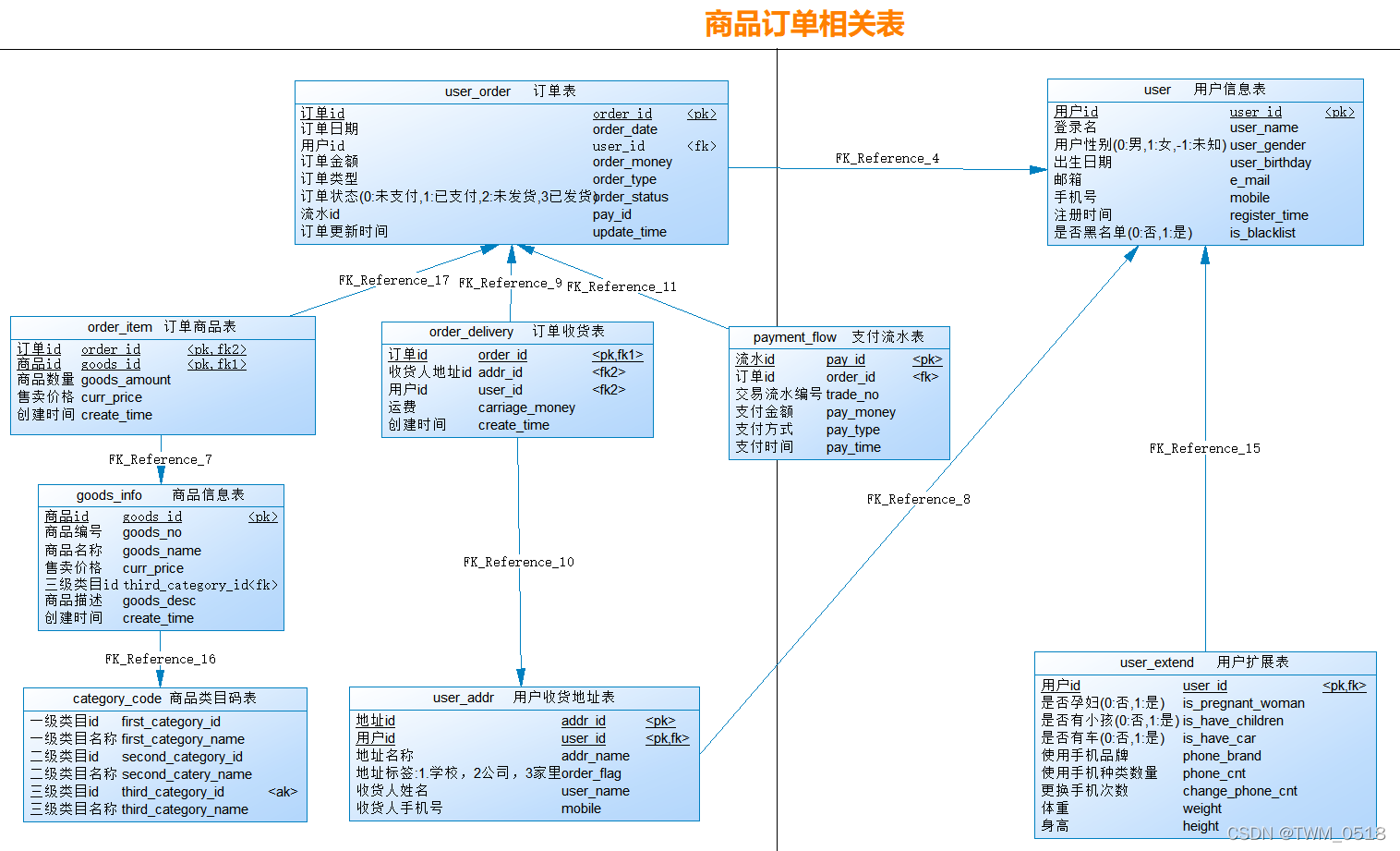
首先在MySQL中初始化数据库和表。使用这个脚本进行初始化:init_mysql_tables.sql
create database if not exists mall;
use mall;
drop table if exists user;
create table user
(
user_id bigint not null,
user_name varchar(64) not null,
user_gender tinyint not null,
user_birthday datetime not null,
e_mail varchar(256) not null,
mobile bigint not null,
register_time datetime not null,
is_blacklist tinyint not null,
primary key (user_id)
);
drop table if exists user_extend;
create table user_extend
(
user_id bigint not null ,
is_pregnant_woman tinyint not null,
is_have_children tinyint not null,
is_have_car tinyint not null,
phone_brand varchar(64) not null,
phone_cnt int not null,
change_phone_cnt int not null,
weight int not null,
height int not null,
primary key (user_id)
);
drop table if exists user_order;
create table user_order
(
order_id bigint not null,
order_date datetime not null,
user_id bigint not null,
order_money decimal(18,2) not null,
order_type int not null,
order_status int not null,
pay_id bigint not null,
update_time datetime not null,
primary key (order_id)
);
drop table if exists payment_flow;
create table payment_flow
(
pay_id bigint not null,
order_id bigint not null,
trade_no bigint not null,
pay_money decimal(18,2) not null,
pay_type int not null,
pay_time datetime not null,
primary key (pay_id)
);
drop table if exists category_code;
create table category_code
(
first_category_id int not null,
first_category_name varchar(32) not null,
second_category_id int not null,
second_catery_name varchar(32) not null,
third_category_id int not null,
third_category_name varchar(32) not null
);
drop table if exists goods_info;
create table goods_info
(
goods_id bigint not null,
goods_no varchar(64) not null,
goods_name varchar(256) not null,
curr_price decimal(18,2) not null,
third_category_id int not null,
goods_desc varchar(256) not null,
create_time datetime not null,
primary key (goods_id)
);
drop table if exists order_item;
create table order_item
(
order_id bigint not null,
goods_id bigint not null,
goods_amount int not null,
curr_price decimal(18,2) not null,
create_time datetime not null,
primary key (order_id, goods_id)
);
drop table if exists user_addr;
create table user_addr
(
addr_id bigint not null,
user_id bigint not null,
addr_name varchar(512) not null,
order_flag tinyint not null,
user_name varchar(64) not null,
mobile bigint not null,
primary key (addr_id, user_id)
);
drop table if exists order_delivery;
create table order_delivery
(
order_id bigint not null,
addr_id bigint not null,
user_id bigint not null,
carriage_money decimal(18,2) not null,
create_time datetime not null,
primary key (order_id)
);
接下来需要向表中初始化数据。
使用generate_data项目中的这个类:GenerateGoodsOrderData
项目的resources目录下的db.properties文件
className=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://ip:port/mall?serverTimezone=UTC
user=root
password=xxx
import com.alibaba.fastjson.JSONObject;
import java.util.ArrayList;
import java.util.List;
/**
* 需求:生成商品订单相关数据(服务端数据),初始化到MySql中
* 【注意】:在执行代码之前需要先执行init_mysql_tables.sql脚本进行数据库和表的初始化
*/
public class GenerateGoodsOrderData {
public static void main(String[] args) {
//通过接口获取用户行为数据
String dataUrl = "http://data.xuwei.tech/d1/go1";
JSONObject paramObj = new JSONObject();
//TODO code:校验码,需要到微信公众号上获取有效校验码,具体操作流程见电子书
paramObj.put("code", "JD3B37868104C5F2A");//校验码
paramObj.put("date", "2026-01-01");//指定数据产生的日期
paramObj.put("user_num", 100);//指定生成的用户数量
paramObj.put("order_num", 1000);//指定生成的订单数量
//insert into t1(...) values(...)
JSONObject dataObj = HttpUtil.doPost(dataUrl, paramObj);
//判断获取的用户行为数据是否正确
boolean flag = dataObj.containsKey("error");
if (!flag) {
//通过JDBC的方式初始化数据到MySQL中
String data = dataObj.getString("data");
String[] splits = data.split("\n");
long start = System.currentTimeMillis();
System.out.println("===============start init===============");
List<String> tmpSqlList = new ArrayList<String>();
for (int i = 0; i < splits.length; i++) {
tmpSqlList.add(splits[i]);
if (tmpSqlList.size() % 100 == 0) {
MyDbUtils.batchUpdate(tmpSqlList);
tmpSqlList.clear();
}
}
//把剩余的数据批量添加到数据库中
MyDbUtils.batchUpdate(tmpSqlList);
System.out.println("===============end init==============");
long end = System.currentTimeMillis();
System.out.println("===============耗时: " + (end - start) / 1000 + "秒===============");
} else {
System.err.println("获取商品订单相关数据错误:" + dataObj.toJSONString());
}
}
}
import com.zaxxer.hikari.HikariDataSource;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class MyDbUtils {
public static void batchUpdate(List<String> sqlList) {
try {
DataSource dataSource = dataSource();
Connection connection = dataSource.getConnection();
connection.setAutoCommit(false);
Statement statement = connection.createStatement();
for (String sql : sqlList) {
statement.addBatch(sql);
}
statement.executeBatch();
connection.commit();
} catch (Exception e) {
throw new RuntimeException("数据库插入数据错误", e);
}
}
private static DataSource dataSource() {
HikariDataSource dataSource = new HikariDataSource();
Map<String, String> dbProperties = getDbProperties();
dataSource.setJdbcUrl(dbProperties.get("url"));
dataSource.setUsername(dbProperties.get("user"));
dataSource.setPassword(dbProperties.get("password"));
dataSource.setDriverClassName(dbProperties.get("className"));
return dataSource;
}
private static Map<String, String> getDbProperties() {
InputStream inputStream = MyDbUtils.class.getResourceAsStream("/db.properties");
Properties properties = new Properties();
try {
properties.load(inputStream);
return new HashMap<String, String>((Map) properties);
} catch (IOException e) {
throw new RuntimeException("获取数据库参数错误", e);
}
}
}
采集数据
采集用户行为数据
数据接收到以后,需要使用flume采集数据,按照act值的不同,将数据分目录存储
flume Agent配置内容如下:useraction-to-hdfs.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/user_action.log
# 配置拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = "act":(\\d)
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = act
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata01:9000/data/ods/user_action/%Y%m%d/%{act}
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#增加文件前缀和后缀
a1.sinks.k1.hdfs.filePrefix = data
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
然后启动这个 Agent
bin/flume-ng agent --name a1 --conf conf --conf-file conf/useraction-to-hdfs.conf
重新执行 GenerateUserActionData 模拟上报数据
此时数据最终会被Flume采集到HDFS上面,到HDFS中查看数据
采集商品订单相关数据
下面我们需要将商品订单数据采集到HDFS里面,咱们前面分析过,在这里针对关系型数据库数据的采集我们使用Sqoop
使用sqoop的导入功能,将MySQL中的数据导入到HDFS上面
数据采集方式
下面我们就需要使用Sqoop进行数据采集了。将服务端数据库中的表全部导入到HDFS里面。但是在采集之前,我们需要分析一下,针对数据库中的那些表应该使用什么策略去采集
数据采集策略大体上来说有两种
- 全量采集
针对用户表、商品表等这些实体表,数据量不是特别大,通常可以每天做全量采集,就是每天保存一份完整的数据
如果针对一些维度表,例如:存储城市信息的表,这种表里面的数据一般是几十年都不变的,针对这种表在采集的时候只需要做一次全量采集就可以了,不需要每天都做。
如果表中的数据可能会变,那就只能每天做一次全量采集了。 - 增量采集
针对订单表、订单商品表,流水表,这些表中的数据是比较多的,如果使用全量的方式,会造成大量的数据冗余,浪费磁盘空间。
所以这种表,一般使用增量的方式,每日采集新增的数据。
在这注意一点:针对订单表,如果单纯的按照订单产生时间增量采集数据,是有问题的,因为用户可能今天下单,明天才支付,但是Hive是不支持数据更新的,这样虽然MySQL中订单的状态改变了,但是Hive中订单的状态还是之前的状态。
想要比较好的解决这个问题,最好是使用拉链表的形式,这个我们在最后的时候会详细分析拉链表的实现
在这里针对订单表,我们暂时使用普通增量的方式进行数据采集,大家先带着这个问题,后面我们再详细分析拉链表。
表名 说明 导入方式
user 用户基本信息表 全量
user_extend 用户信息扩展表 全量
user_addr 用户收货地址表 全量
goods_info 商品信息表 全量
category_code 商品类目码表 全量
user_order 订单表 增量
order_item 订单商品表 增量
order_delivery 订单收货表 增量
payment_flow 支付流水表 增量
注意:手机号在采集的时候需要脱敏处理,因为数据进入到数据仓库之后会有很多人使用,为保护用户隐私,最好在采集的时候进行脱敏处理。所以在采集user和user_addr表中的数据时对手机号进行脱敏。
数据采集脚本开发
下面就开始进行数据采集,其实就是使用Sqoop实现的数据导入,开发一个通用的sqoop数据采集脚本
创建脚本sqoop_collect_data_util.sh
[root@bigdata04 warehouse_shell_good_order]#vi sqoop_collect_data_util.sh
#!/bin/bash
# 采集MySQL中的数据导入到HDFS中
if [ $# != 2 ]
then
echo "参数异常:sqoop_collect_data_util.sh <sql> <hdfs_path>"
exit 100
fi
# 数据SQL
# 例如:select id,name from user where id >1
sql=$1
# 导入到HDFS上的路径
hdfs_path=$2
/root/test_sqoop/sqoop1.4.7/bin/sqoop import \
--connect jdbc:mysql://ip:port/mall?serverTimezone=UTC \
--username root \
--password xxx \
--target-dir "${hdfs_path}" \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query "${sql}"' and $CONDITIONS;' \
--null-string '\\N' \
--null-non-string '\\N'
开始采集数据
针对全量数据采集和增量数据采集开发不同的脚本
全量数据采集: collect_data_full.sh
[root@bigdata04 warehouse_shell_good_order]#vi collect_data_full.sh
#!/bin/bash
# 全量数据采集
# 每天凌晨执行一次
# 默认获取昨天的日期,也支持传参指定一个日期
if [ "z$1" = "z" ]
then
dt=`date +%Y%m%d --date="1 days ago"`
else
dt=$1
fi
# SQL语句
user_sql="select user_id,user_name,user_gender,user_birthday,e_mail,concat(left(mobile,3), '****' ,right(mobile,4)) as mobile,register_time,is_blacklist from user where 1=1"
user_extend_sql="select user_id,is_pregnant_woman,is_have_children,is_have_car,phone_brand,phone_cnt,change_phone_cnt,weight,height from user_extend where 1=1"
user_addr_sql="select addr_id,user_id,addr_name,order_flag,user_name,concat(left(mobile,3), '****' ,right(mobile,4)) as mobile from user_addr where 1=1"
goods_info_sql="select goods_id,goods_no,goods_name,curr_price,third_category_id,goods_desc,create_time from goods_info where 1=1"
category_code_sql="select first_category_id,first_category_name,second_category_id,second_catery_name,third_category_id,third_category_name from category_code where 1=1"
# 路径前缀
path_prefix="hdfs://bigdata01:9000/data/ods"
# 输出路径
user_path="${path_prefix}/user/${dt}"
user_extend_path="${path_prefix}/user_extend/${dt}"
user_addr_path="${path_prefix}/user_addr/${dt}"
goods_info_path="${path_prefix}/goods_info/${dt}"
category_code_path="${path_prefix}/category_code/${dt}"
sqoop_collect_data_util_path=/root/test_sqoop/sqoop_collect_data_util.sh
# 采集数据
echo "开始采集..."
echo "采集表:user"
sh "${sqoop_collect_data_util_path}" "${user_sql}" "${user_path}"
echo "采集表:user_extend"
sh "${sqoop_collect_data_util_path}" "${user_extend_sql}" "${user_extend_path}"
echo "采集表:user_addr"
sh "${sqoop_collect_data_util_path}" "${user_addr_sql}" "${user_addr_path}"
echo "采集表:goods_info"
sh "${sqoop_collect_data_util_path}" "${goods_info_sql}" "${goods_info_path}"
echo "采集表:category_code"
sh "${sqoop_collect_data_util_path}" "${category_code_sql}" "${category_code_path}"
echo "结束采集..."
增量数据采集: collect_data_incr.sh
#!/bin/bash
# 增量数据采集
# 每天凌晨执行一次
# 默认获取昨天的日期,也支持传参指定一个日期
if [ "z$1" = "z" ]
then
dt=`date +%Y%m%d --date="1 days ago"`
else
dt=$1
fi
# 转换日期格式,20260201 改为2026-02-01
dt_new=`date +%Y-%m-%d --date="${dt}"`
# SQL语句
user_order_sql="select order_id,order_date,user_id,order_money,order_type,order_status,pay_id,update_time from user_order where order_date >= '${dt_new} 00:00:00' and order_date <= '${dt_new} 23:59:59'"
order_item_sql="select order_id,goods_id,goods_amount,curr_price,create_time from order_item where create_time >= '${dt_new} 00:00:00' and create_time <= '${dt_new} 23:59:59'"
order_delivery_sql="select order_id,addr_id,user_id,carriage_money,create_time from order_delivery where create_time >= '${dt_new} 00:00:00' and create_time <= '${dt_new} 23:59:59'"
payment_flow_sql="select pay_id,order_id,trade_no,pay_money,pay_type,pay_time from payment_flow where pay_time >= '${dt_new} 00:00:00' and pay_time <= '${dt_new} 23:59:59'"
# 路径前缀
path_prefix="hdfs://bigdata01:9000/data/ods"
# 输出路径
user_order_path="${path_prefix}/user_order/${dt}"
order_item_path="${path_prefix}/order_item/${dt}"
order_delivery_path="${path_prefix}/order_delivery/${dt}"
payment_flow_path="${path_prefix}/payment_flow/${dt}"
sqoop_collect_data_util_path=/root/test_sqoop/sqoop_collect_data_util.sh
# 采集数据
echo "开始采集..."
echo "采集表:user_order"
sh "${sqoop_collect_data_util_path}" "${user_order_sql}" "${user_order_path}"
echo "采集表:order_item"
sh "${sqoop_collect_data_util_path}" "${order_item_sql}" "${order_item_path}"
echo "采集表:order_delivery"
sh "${sqoop_collect_data_util_path}" "${order_delivery_sql}" "${order_delivery_path}"
echo "采集表:payment_flow"
sh "${sqoop_collect_data_util_path}" "${payment_flow_sql}" "${payment_flow_path}"
echo "结束采集..."
参考
数据仓库之【用户行为数仓】04:数据生成与采集:用户行为数据、商品订单相关数据
刚刚!Apache 董事会宣布终止 Apache Sqoop 项目

 浙公网安备 33010602011771号
浙公网安备 33010602011771号