





Flume高级组件
Event
Event是Flume传输数据的基本单位,也是事务的基本单位,在文本文件中,通常一行记录就是一个Event
Event中包含header和body;
- body是采集到的那一行记录的原始内容
- header类型为Map<String, String>,里面可以存储一些属性信息,方便后面使用
我们可以在Source中给每一条数据的header中增加key-value,在Channel和Sink中就可以使用header中的值了。
Source Interceptors
Source可以指定一个或者多个拦截器按先后顺序依次对采集到的数据进行处理。
系统中已经内置提供了很多Source Interceptors
常见的Source Interceptors类型:Timestamp Interceptor、Host Interceptor、Search and Replace Interceptor 、Static Interceptor、Regex Extractor Interceptor 等
- Timestamp Interceptor:向event中的header里面添加timestamp 时间戳信息
- Host Interceptor:向event中的header里面添加host属性,host的值为当前机器的主机名或者ip
- Search and Replace Interceptor:根据指定的规则查询Event中body里面的数据,然后进行替换,这个拦截器会修改event中body的值,也就是会修改原始采集到的数据内容
- Static Interceptor:向event中的header里面添加固定的key和value
- Regex Extractor Interceptor:根据指定的规则从Event中的body里面抽取数据,生成key和value,再把key和value添加到header中
event中的header里面添加key-value类型的数据,方便后面的channel和sink组件使用,对采集到的原始数据内容没有任何影响
Search and Replace Interceptor是会根据规则修改event中body里面的原始数据内容,对header没有任何影响,使用这个拦截器需要特别小心,因为它会修改原始数据内容。
这里面这几个拦截器,其中Search and Replace Interceptor和Regex Extractor Interceptor 我们在工作中使用的比较多一些
案例-对采集到的数据按天按类型分目录存储
需求分析
对采集到的数据按天按类型分目录存储,原始数据是这样的,看这个文件,Flume测试数据格式.txt
{"video_id":"1111111111","uid:"222222222","type":"video_info"}
{"uid":"1111111111","nickname:"male","type":"user_info"}
{"send_id":"3333333333","video_id:"1111111111","type":"gift_record"}
这份数据中有三种类型的数据,视频信息、用户信息、送礼信息,数据都是json格式的,这些数据还有一个共性就是里面都有一个type字段,type字段的值代表数据类型
当我们的直播平台正常运行的时候,会实时产生这些日志数据,我们希望把这些数据采集到hdfs上进行存储,并且要按照数据类型进行分目录存储,视频数据放一块、用户数据放一块、送礼数据放一块
针对这个需求配置agent的话,source使用基于文件的execsource、channle使用基于文件的channle,我们希望保证数据的完整性和准确性,sink使用hdfssink
但是注意了,hdfssink中的path不能写死,首先是按天 就是需要动态获取日期,然后是因为不同类型的数据要存储到不同的目录中
那也就意味着path路径中肯定要是有变量,除了日期变量还要有数据类型变量,这里的数据类型的格式都是单词中间有一个下划线,但是我们的要求是目录中的单词不要出现下划线,使用驼峰的命名格式。所以最终在hdfs中需要生成的目录大致是这样的
hdfs://bigdata01:9000/moreType/20200101/videoInfo
hdfs://bigdata01:9000/moreType/20200101/userInfo
hdfs://bigdata01:9000/moreType/20200101/giftRecord
这里的日期变量好获取,但是数据类型如何获取呢?
那我们在这就可以通过Regex Extractor Interceptor获取原始数据中的type字段的值,获取出来以后存储到header中,这样在sink阶段就可以获取到了。但是这个时候直接获取到的type的值是不满足要求的,需要对type的值进行转换,去掉下划线,转换为驼峰形式
所以可以先使用Search and Replace Interceptor对原始数据中type的值进行转换,然后使用Regex Extractor Interceptor指定规则获取type字段的值,添加到header中。
配置agent
那下面我们来配置Agent,在bigdata01机器上创建 file-to-hdfs-moreType.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/test_flume/source/moreType/moreType.log
# 配置拦截器 [多个拦截器按照顺序依次执行]
a1.sources.r1.interceptors = i1 i2 i3 i4
a1.sources.r1.interceptors.i1.type = search_replace
a1.sources.r1.interceptors.i1.searchPattern = "type":"video_info"
a1.sources.r1.interceptors.i1.replaceString = "type":"videoInfo"
a1.sources.r1.interceptors.i2.type = search_replace
a1.sources.r1.interceptors.i2.searchPattern = "type":"user_info"
a1.sources.r1.interceptors.i2.replaceString = "type":"userInfo"
a1.sources.r1.interceptors.i3.type = search_replace
a1.sources.r1.interceptors.i3.searchPattern = "type":"gift_record"
a1.sources.r1.interceptors.i3.replaceString = "type":"giftRecord"
a1.sources.r1.interceptors.i4.type = regex_extractor
a1.sources.r1.interceptors.i4.regex = "type":"(\\w+)"
a1.sources.r1.interceptors.i4.serializers = s1
a1.sources.r1.interceptors.i4.serializers.s1.name = logType
# 配置channel组件
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /root/test_flume/channel/checkpoint/moreType
a1.channels.c1.dataDirs = /root/test_flume/channel/data/moreType
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata01:9000/moreType/%Y%m%d/%{logType}
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#增加文件前缀和后缀
a1.sinks.k1.hdfs.filePrefix = data
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:这里面的拦截器,拦截器可以设置一个或者多个,source采集的每一条数据都会经过所有的拦截器进行处理,多个拦截器按照顺序执行。
创建测试数据
/root/test_flume/source/moreType/moreType.log
{"video_id":"1111111111","uid:"222222222","type":"video_info"}
{"uid":"1111111111","nickname:"male","type":"user_info"}
{"send_id":"3333333333","video_id:"1111111111","type":"gift_record"}
启动agent
bin/flume-ng agent --name a1 --conf conf --conf-file conf/file-to-hdfs-moreType.conf -Dflume.root.logger=INFO,console
验证结果
在bigdata01节点上查看
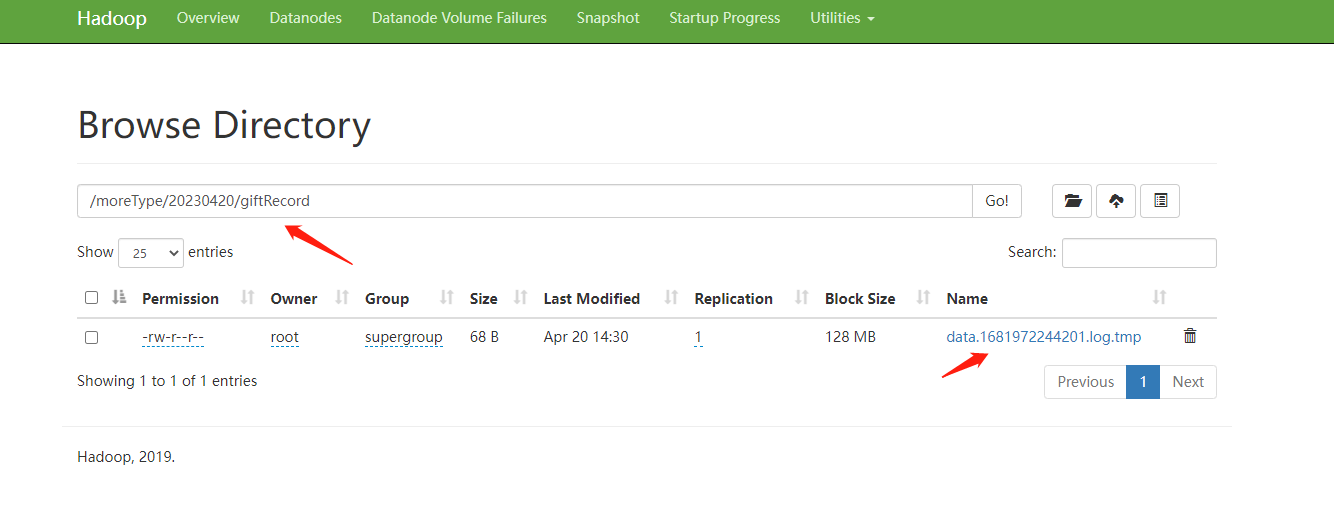
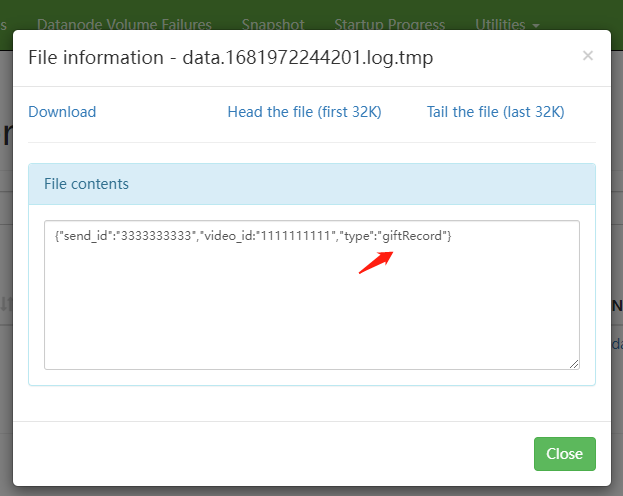
这就实现了按天,按类型分目录存储。
Channel Selectors
Source发往多个Channel的策略设置,如果source后面接了多个channel,到底是给所有的channel都发,还是根据规则发送到不同channel,这些是由Channel Selectors来控制的
Channel Selectors类型包括:Replicating Channel Selector 和Multiplexing Channel Selector
- Replicating Channel Selector是默认的channel 选择器,它会将Source采集过来的Event发往所有channel
- Multiplexing Channel Selector,它会根据Event中header里面的值将Event发往不同的Channel
案例一:多Channel之Replicating Channel Selector
需求分析
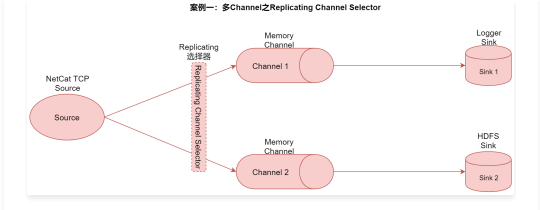
在这个案例中我们使用Replicating选择器,将source采集到的数据重复发送给两个channle,最后每个channel后面接一个sink,负责把数据存储到不同存储介质中,方便后期使用。
在实际工作中这种需求还是比较常见的,就是我们希望把一份数据采集过来以后,分别存储到不同的存储介质中,不同存储介质的特点和应用场景是不一样的,典型的就是hdfssink 和kafkasink,
通过hdfssink实现离线数据落盘存储,方便后面进行离线数据计算
通过kafkasink实现实时数据存储,方便后面进行实时计算,由于我们还没有学kafka,所以在这里先使用loggersink代理。
配置agent
在bigdata01中flume的conf目录中创建 tcp-to-replicatingchannel.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channle选择器[默认就是replicating,所以可以省略]
a1.sources.r1.selector.type = replicating
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = logger
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://bigdata01:9000/replicating
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.filePrefix = data
a1.sinks.k2.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
启动Agent
bin/flume-ng agent --name a1 --conf conf --conf-file conf/tcp-to-replicatingchannel.conf -Dflume.root.logger=INFO,console
生成测试数据
通过telnet连接到socket
telnet localhost 44444
查看效果
可以看到Flume在控制台输出的日志信息,在hdfs中也能看到生成的文件中的内容
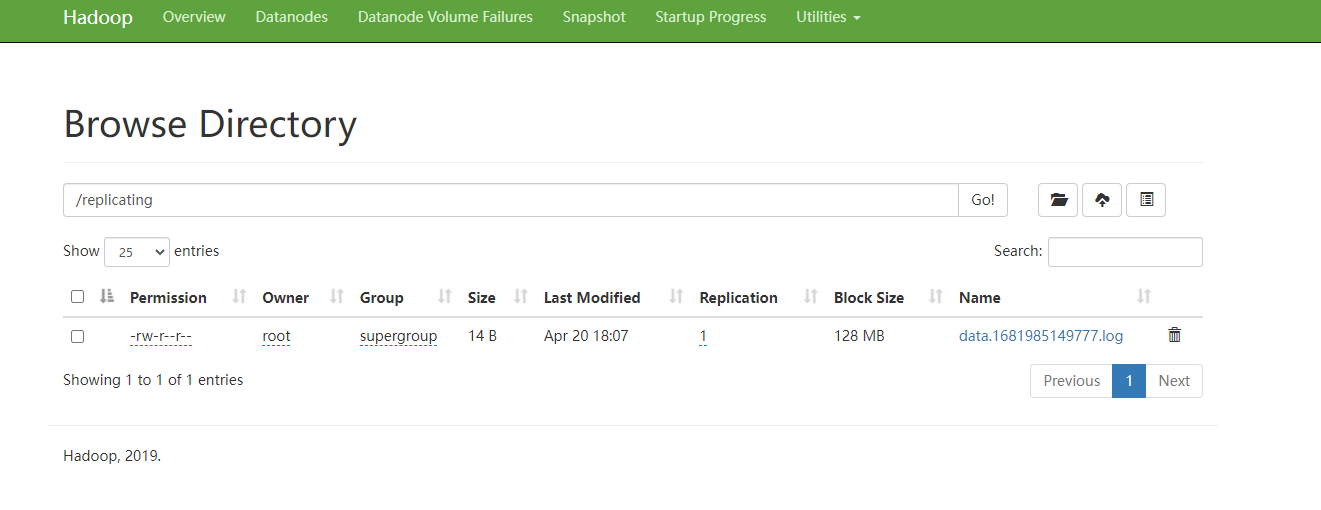
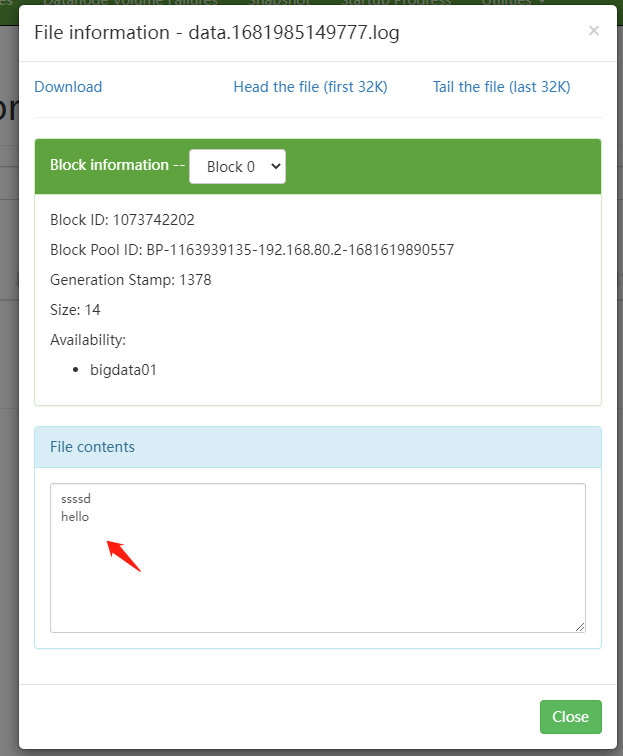
注意,如果开启了VPN,会提示Couldn't preview the file.,不能查看文件的内容,将VPN关了就可以了。
案例二:多Channel之Multiplexing Channel Selector
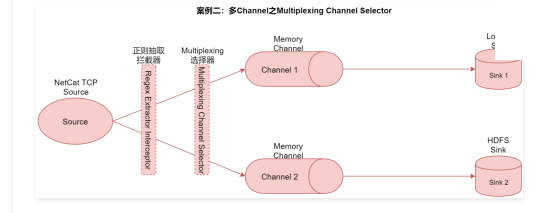
把不同channel中的数据存储到不同介质中。在这里面我们需要用到正则抽取拦截器在Event的header中生成key-value作为Multiplexing选择器的规则
假设我们的原始数据为
{"name":"jack","age":19,"city":"bj"}
{"name":"tom","age":26,"city":"sh"}
配置agent
在bigdata01上创建新文件 tcp-to-multiplexingchannel.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置source拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = "city":"(\\w+)"
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = city
# 配置channle选择器
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = city
a1.sources.r1.selector.mapping.bj = c1
a1.sources.r1.selector.default = c2
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = logger
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://bigdata01:9000/multiplexing
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.writeFormat = Text
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.useLocalTimeStamp = true
a1.sinks.k2.hdfs.filePrefix = data
a1.sinks.k2.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
启动Agent
bin/flume-ng agent --name a1 --conf conf --conf-file conf/tcp-to-multiplexingchannel.conf -Dflume.root.logger=INFO,console
生成测试数据
通过telnet连接到socket,向服务器输入
{"name":"jack","age":19,"city":"bj"}
{"name":"tom","age":26,"city":"sh"}
查看结果
可以看到Flume在控制台输出的日志信息(city:bj),在hdfs中也能看到生成的文件中的内容(city:sh)。
Sink Processors
Sink 发送数据的策略设置,一个channel后面可以接多个sink,channel中的数据是被哪个sink获取,这个是由Sink Processors控制的
Sink Processors类型包括这三种:Default Sink Processor、Load balancing Sink Processor和Failover Sink Processor
- DefaultSink Processor是默认的,不用配置sinkgroup,就是咱们现在使用的这种最普通的形式,一个channel后面接一个sink的形式
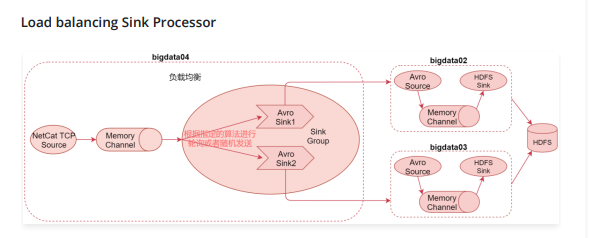
- Load balancing Sink Processor是负载均衡处理器,一个channle后面可以接多个sink,这多个sink属于一个sink group,根据指定的算法进行轮询或者随机发送,减轻单个sink的压力
- Failover Sink Processor是故障转移处理器,一个channle后面可以接多个sink,这多个sink属于一个sink group,按照sink的优先级,默认先让优先级高的sink来处理数据,如果这个sink出现了故障,则用优先级低一点的sink处理数据,可以保证数据不丢失。
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件,[为了方便演示效果,把batch-size设置为1]
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=bigdata01
a1.sinks.k1.port=41414
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=192.168.182.102
a1.sinks.k2.port=41414
a1.sinks.k2.batch-size = 1
# 配置sink策略
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
- sinks:指定这个sink groups中有哪些sink,指定sink的名称,多个的话中间使用空格隔开即可
- processor.type:针对负载均衡的sink处理器,这里需要指定load_balance
- processor.selector:此参数的值内置支持两个,round_robin和random,round_robin表示轮询,按照sink的顺序,轮流处理数据,random表示随机。
- processor.backoff:默认为false,设置为true后,故障的节点会列入黑名单,过一定时间才会再次发送数据,如果还失败,则等待时间是指数级增长;一直到达到最大的时间。如果不开启,故障的节点每次还会被重试发送,如果真有故障节点的话就会影响效率。
- processor.selector.maxTimeOut:最大的黑名单时间,默认是30秒
负载均衡可以解决之前单节点输出能力有限的问题,可以通过多个sink后面连接多个Agent实现负载均衡,如果后面的Agent挂掉1个,也不会影响整体流程,只是处理效率又恢复到了之前的状态。
这个案例需要多台服务器,暂时没有实践。
各种自定义组件
前面讲了很多组件,有核心组件和高级组件source、channel、sink以及Source Interceptors,Channel Selectors、Sink Processors
针对这些组件,Flume都内置提供了组件的很多具体实现,在实际工作中,95%以上的数据采集需求都是可以满足的,但是谁也不敢保证100%都能满足,因为什么奇怪的需求都会有,那针对系统内没有提供的一些组件怎么办呢?
假设我们想把flume采集到的数据输出到mysql中,那这个时候就需要有针对mysql的sink组件了,但是Flume中并没有,因为这种需求不常见,往mysql中写的都是结构化数据,数据的格式是固定的,但是flume采集的一般都是日志数据,这种属于非结构化数据,不支持也是正常的,但是我们在这里就是需要使用Flume往mysql中写数据,那怎么办?
那我们是不是可以自己写一个自定义的组件呢?可以的,并且flume也很欢迎你这样去做,它把开发文档什么的东西都给你准备好了。
注意了,就算没有文档,我们也要想办法去自定义,没有文档的话就需要去看Flume的源码了。
import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.source.AbstractSource;
/**
* 自定义source
*/
public class CustomSource extends AbstractSource implements Configurable, PollableSource {
@Override
public Status process() throws EventDeliveryException {
return null;
}
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
@Override
public void configure(Context context) {
}
}
Flume优化
调整Flume进程的内存大小
建议设置1G~2G,太小的话会导致频繁GC。因为Flume进程也是基于Java的,所以就涉及到进程的内存设置,一般建议启动的单个Flume进程(或者说单个Agent)内存设置为1G~2G,内存太小的话会频繁GC,影响Agent的执行效率。
那具体设置多少合适呢?
这个需求需要根据Agent读取的数据量的大小和速度有关系,所以需要具体情况具体分析,当Flume的Agent启动之后,对应就会启动一个进程,我们可以通过jstat -gcutil PID 1000来看看这个进程GC的信息,每一秒钟刷新一次,如果GC次数增长过快,说明内存不够用。
使用jps查看目前启动flume进程
[root@bigdata01 ~]# jps
24734 Application
24975 Jps
执行 jstat -gcutil PID 1000
[root@bigdata01 ~]# jstat -gcutil 24734 1000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
97.03 0.00 65.97 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.97 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.98 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.98 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.98 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.98 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.98 24.75 92.94 84.91 4 0.033 0 0.000 0.033
97.03 0.00 65.98 24.75 92.94 84.91 4 0.033 0 0.000 0.033
在这里主要看YGC YGCT FGC FGCT GCT
- YGC:表示新生代堆内存GC的次数,如果每隔几十秒产生一次,也还可以接受,如果每秒都会发生一次YGC,那说明需要增加内存了
- YGCT:表示新生代堆内存GC消耗的总时间
- FGC:FULL GC发生的次数,注意,如果发生FUCC GC,则Flume进程会进入暂停状态,FUCC GC执行完以后Flume才会继续工作,所以FUCC GC是非常影响效率的,这个指标的值越低越好,没有更好。
- GCT:所有类型的GC消耗的总时间
如果需要调整Flume进程内存的话,需要调整 flume-env.sh 脚本中的 JAVA_OPTS 参数
建议这里的 Xms 和 Xmx 设置为一样大,避免进行内存交换,内存交换也比较消耗性能。
修改配置区分日志文件
在一台服务器启动多个agent的时候,建议修改配置区分日志文件
因为在conf目录下有log4j.properties,在这里面指定了日志文件的名称和位置,所有使用conf目录下面配置启动的Agent产生的日志都会记录到同一个日志文件中,如果我们在一台机器上启动了10几个Agent,后期发现某一个Agent挂了,想要查看日志分析问题,这个时候就疯了,因为所有Agent产生的日志都混到一块了,压根都没法分析日志了。
所以建议拷贝多个conf目录,然后修改对应conf目录中log4j.properties日志的文件名称(可以保证多个agent的日志分别存储),并且把日志级别调整为warn(减少垃圾日志的产生),默认info级别会记录很多日志信息。这样在启动Agent的时候分别通过–conf参数指定不同的conf目录,后期分析日志就方便了,每一个Agent都有一个单独的日志文件。
Flume进程监控
需求分析
Flume的Agent服务是一个独立的进程,假设我们使用source->channel->sink实现了一个数据采集落盘的功能,如果这个采集进程被误操作干掉了,这个时候我们是发现不了的,什么时候会发现呢?可能第二天,产品经理找到你了,说昨天的这个指标值有点偏低啊,你来看下怎么回事,然后你就一顿操作猛如虎,结果发现原始数据少了一半多,那是因为Flume的采集程序在昨天下午的时候被误操作干掉了。
以针对这些存在单点故障的进程,我们都需要添加监控告警机制,最起码出问题能及时知道,再好一点的呢,可以尝试自动修复重启。
那针对Flume中的Agent我们就来实现一个监控功能,并且尝试自动重启,大致思路是这样的,
- 首先需要有一个配置文件,配置文件中指定你现在需要监控哪些Agent
- 有一个脚本负责读取配置文件中的内容,定时挨个检查Agent对应的进程还在不在,如果发现对应的进程不在,则记录错误信息,然后告警(发短信或者发邮件) 并尝试重启
编写脚本
创建一个文件 monlist.conf
文件中的第一列指定一个Agent的唯一标识,后期需要根据这个标识过滤对应的Flume进程,所以一定要保证至少在一台机器上是唯一的,等号后面是一个启动Flume进程的脚本,这个脚本和Agent的唯一标识是一一对应的,后期如果根据Agent标识没有找到对应的进程,那么就需要根据这个脚本启动进程
example=/root/test_flume/startExample.sh
这个脚本的内容如下: startExample.sh
#!/bin/bash
flume_path=/root/test_flume/flume1.9
nohup ${flume_path}/bin/flume-ng agent --name a1 --conf ${flume_path}/conf --conf-file ${flume_path}/conf/example.conf &
接着就是要写一个脚本来检查进程在不在,不在的话尝试重启,创建脚本 monlist.sh
#!/bin/bash
monlist=`cat monlist.conf`
echo "start check"
for item in ${monlist}
do
# 设置字段分隔符
OLD_IFS=$IFS
IFS="="
# 把一行内容转成多列[数组]
arr=($item)
# 获取等号左边的内容
name=${arr[0]}
# 获取等号右边的内容
script=${arr[1]}
echo "time is : "`date +"%Y-%m-%d %H:%M:%S"`" check "$name
if [ `jps -m | grep $name | wc -l` -eq 0 ]
then
# 发短信或者邮件告警
echo `date +"%Y-%m-%d %H:%M:%S"` $name "is none"
sh -x ${script}
fi
done
注意:这个需要定时执行,所以可以使用crontab定时调度
* * * * * root /bin/bash /root/test_flume/monlist.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号