





Hadoop之YARN详解
YARN的由来
从Hadoop2开始,官方把资源管理单独剥离出来,主要是为了考虑后期作为一个公共的资源管理平台,任何满足规则的计算引擎都可以在它上面执行。所以YARN可以实现HADOOP集群的资源共享,不仅仅可以跑MapReduce,还可以跑Spark、Flink。
YARN架构分析
我们之前部署Hadoop集群的时候对YARN的架构有了基本的了解,YARN主要负责集群资源的管理和调度 ,支持主从架构,主节点最多可以有2个,从节点可以有多个
其中
- ResourceManager:主节点,主要负责集群资源的分配和管理
- NodeManager:从节点,主要负责当前机器资源管理
YARN资源管理模型
YARN主要管理内存和CPU这两种资源类型
当NodeManager节点启动的时候自动向ResourceManager注册,将当前节点上的可用CPU信息和内存信息注册上去。这样所有的nodemanager注册完成以后,resourcemanager就知道目前集群的资源总量了。那我们现在来看一下我这个一主两从的集群资源是什么样子的,打开yarn的8088界面

但是这个数值和我们的实际值是对不上的,那为什么在这里显示是内存是8G,CPU是8个呢?
- yarn.nodemanager.resource.memory-mb:单节点可分配的物理内存总量,默认是8MB*1024,即8G
- yarn.nodemanager.resource.cpu-vcores:单节点可分配的虚拟CPU个数,默认是8
看到没有,这都是默认单节点的内存和CPU信息,就算你这个机器没有这么多资源,但是在yarndefault.xml中有这些默认资源的配置,这样当nodemanager去上报资源的时候就会读取这两个参数的值,这也就是为什么我们在前面看到了单节点都是8G内存和8个cpu,其实我们的linux机器是没有这么大资源的,那这就是虚标啊,肯定不能这样干,应该实际有多少就是多少,所以我们可以修改这些参数的值,修改的话就在yarn-site.xml中进行配置即可,改完之后就可以看到真实的信息了,这里我就先不改了,针对我们的学习环境不影响使用,修改的意义不大,知道有这回事就行了。
YARN中的调度器
接下来我们来详细分析一下YARN中的调度器,这个是非常实用的东西。
大家可以想象一个场景,我们集群的资源是有限的,在实际工作中会有很多人向集群中提交任务,那这时候资源如何分配呢?如果你提交了一个很占资源的任务,这一个任务就把集群中90%的资源都占用了,后面别人再提交任务,剩下的资源就不够用了,这个时候怎么办?让他们等你的任务执行完了再执行?还是说你把你的资源匀出来一些分给他,你少占用一些,让他也能慢慢执行。具体如何去做是由YARN中的调度器负责的。
YARN中支持三种调度器
- FIFO Scheduler:先进先出(first in, first out)调度策略
- Capacity Scheduler:FIFO Scheduler的多队列版本
- FairScheduler:多队列,多用户共享资源
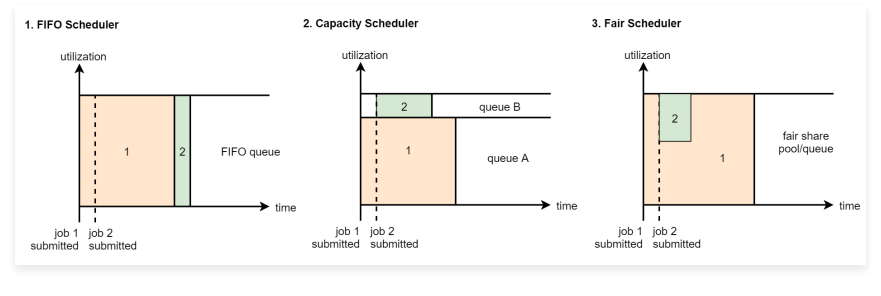
- FIFO Scheduler:是先进先出的,大家都是排队的,如果你的任务申请不到足够的资源,那你就等着,等前面的任务执行结束释放了资源之后你再执行。这种在有些时候是不合理的,因为我们有一些任务的优先级比较高,我们希望任务提交上去立刻就开始执行,这个就实现不了了。
- CapacityScheduler:它是FifoScheduler的多队列版本,就是我们先把集群中的整块资源划分成多份,我们可以人为的给这些资源定义使用场景,例如图里面的queue A里面运行普通的任务,queueB中运行优先级比较高的任务。这两个队列的资源是相互对立的。但是注意一点,队列内部还是按照先进先出的规则。
- FairScheduler:支持多个队列,每个队列可以配置一定的资源,每个队列中的任务共享其所在队列的所有资源,不需要排队等待资源。具体是这样的,假设我们向一个队列中提交了一个任务,这个任务刚开始会占用整个队列的资源,当你再提交第二个任务的时候,第一个任务会把他的资源释放出来一部分给第二个任务使用
在实际工作中我们一般都是使用第二种, CapacityScheduler ,从hadoop2开始, CapacityScheduler也是集群中的默认调度器了。那下面我们到集群上看一下,点击左侧的Scheduler查看
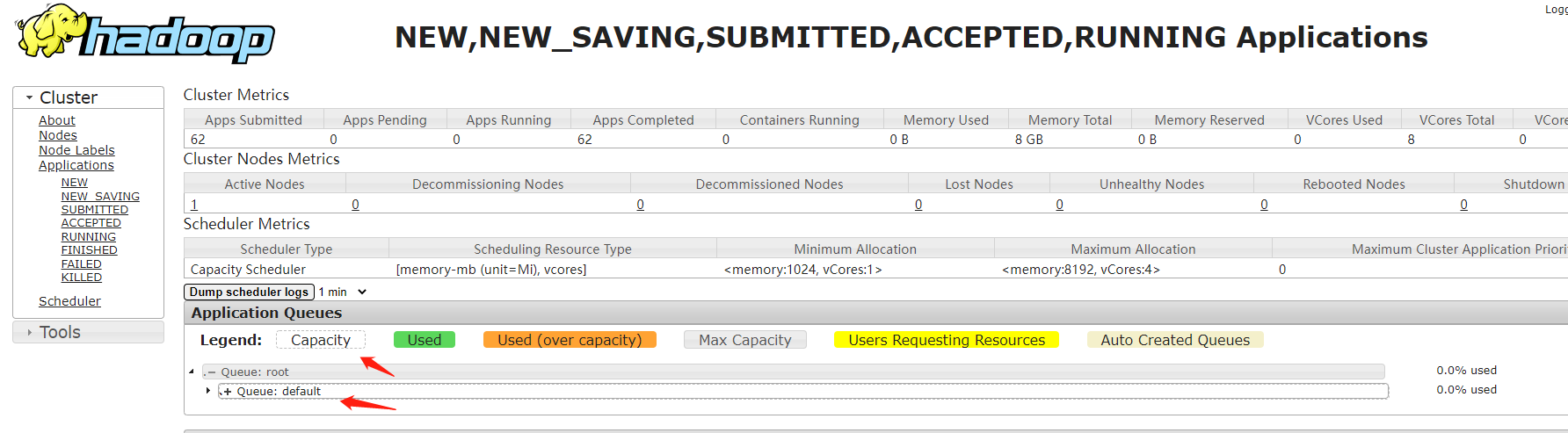
案例:YARN多资源队列配置和使用
需求
我们的需求是这样的,希望增加2个队列,一个是online队列,一个是offline队列。然后向offline队列中提交一个mapreduce任务
online队列里面运行实时任务
offline队列里面运行离线任务,我们现在学习的mapreduce就属于离线任务
实时任务我们后面会学习,等讲到了再具体分析。
具体步骤
修改集群中 etc/hadoop 目录下的 capacity-scheduler.xml 配置文件
修改和增加以下参数,针对已有的参数,修改value中的值,针对没有的参数,则直接增加
这里的 default 是需要保留的,增加 online,offline ,这三个队列的资源比例为 7:1:2
具体的比例需要根据实际的业务需求来,哪种类型的任务比较多,对应的队列中资源比例就调高一些,我们现在暂时还没有online任务,所以我就把online队列的资源占比设置的小一些。
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,online,offline</value>
<description>队列列表,多个队列之间使用逗号分割</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>default队列70%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.capacity</name>
<value>10</value>
<description>online队列10%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.capacity</name>
<value>20</value>
<description>offline队列20%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>70</value>
<description>Default队列可使用的资源上限.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.maximum-capacity</name>
<value>10</value>
<description>online队列可使用的资源上限.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.maximum-capacity</name>
<value>20</value>
<description>offline队列可使用的资源上限.</description>
</property>
重启集群,进入yarn的web界面,查看最新的调度器队列信息
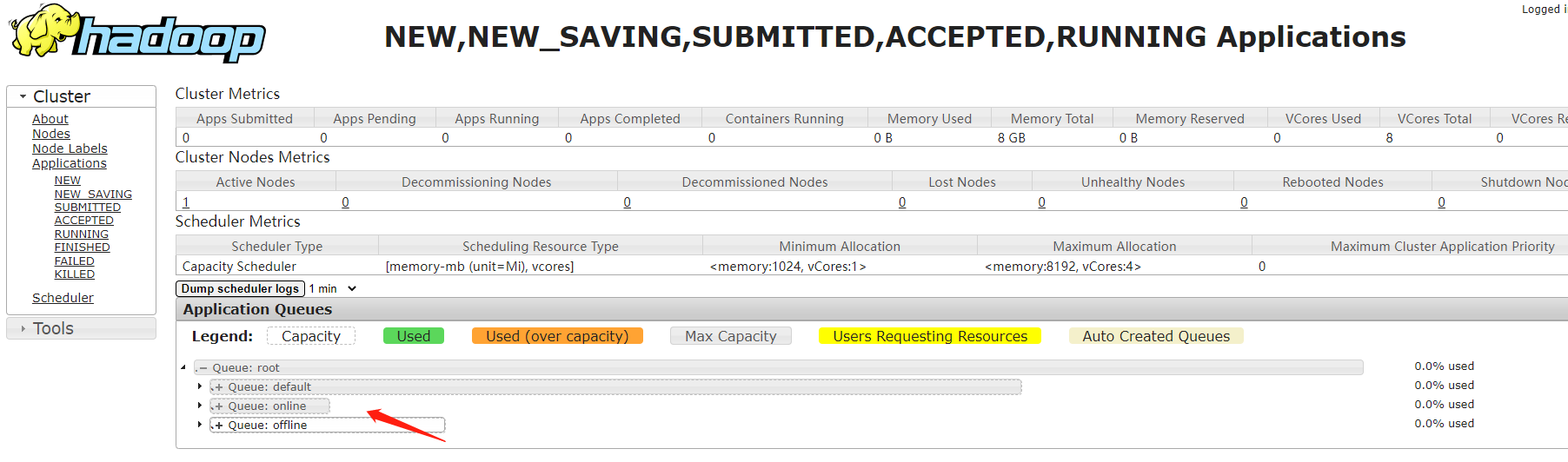
注意了,现在默认提交的任务还是会进入default的队列,如果希望向offline队列提交任务的话,需要指定队列名称,不指定就进默认的队列。
在这里我们还需要同步微调一下代码,否则我们指定的队列信息 代码是无法识别的
//创建一个job
Configuration config = new Configuration();
//解析命令行中-D后面传递过来的参数,添加到conf中
String[] remainingArgs = new GenericOptionsParser(config, args).getRemainingArgs();
Job job = Job.getInstance(config, "wordCountJob");
//必须设置 不然找不到执行类
job.setJarByClass(WordCountJobQueue.class);
重新编译打包,上传到服务器
bin/hadoop jar bigdata.jar com.imooc.bigdata.mr.WordCountJobQueue -Dmapreduce.job.queuename=offline /hello.txt /out11
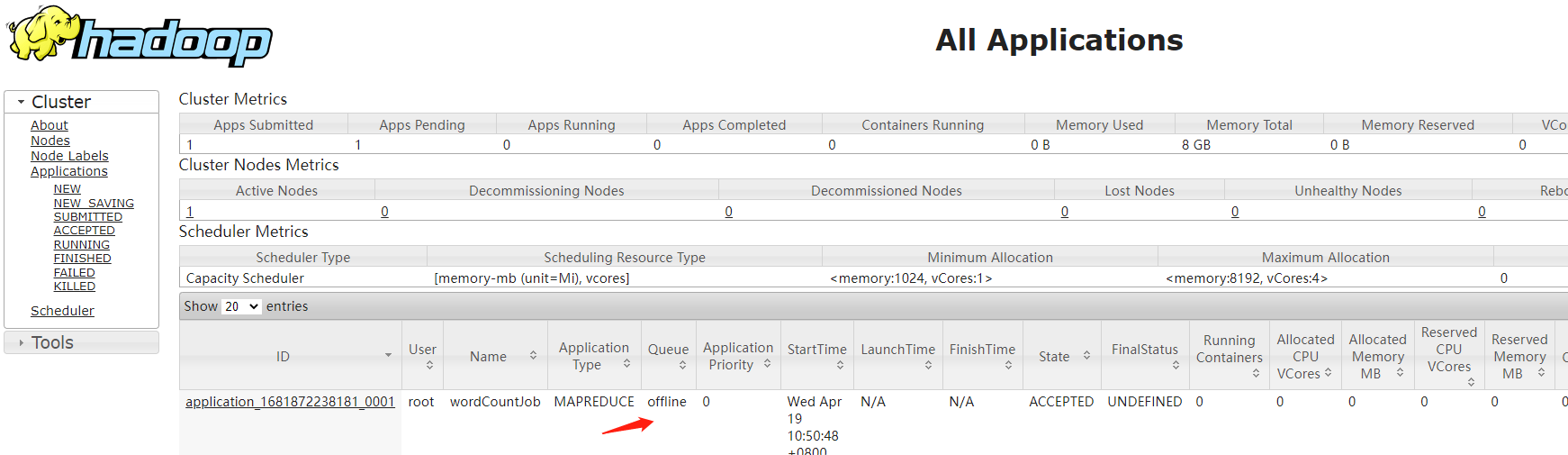
如果我们去掉指定队列名称的配置,此时还会使用default队列
遇到的问题
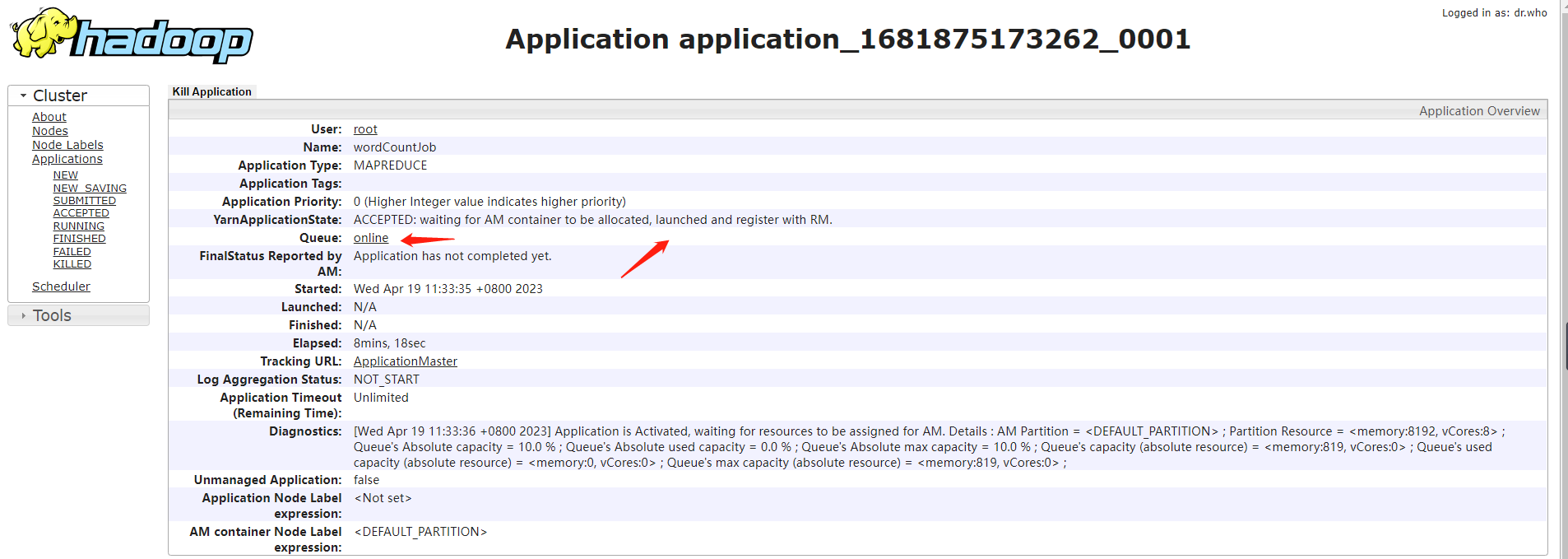
指定了offline队列的任务没有执行成功,应该是资源不足导致的,暂时还未解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号