





Hadoop之MapReduce详解
前言
前面我们学习了Hadoop中的HDFS,HDFS主要是负责存储海量数据的,如果只是把数据存储起来,除了浪费磁盘空间,是没有任何意义的,我们把数据存储起来之后是希望能从这些海量数据中分析出来一些有价值的内容,这个时候就需要有一个比较厉害的计算框架,来快速计算这一批海量数据,所以MapReduce应运而生了。
MapReduce介绍
以计算扑克牌中的黑桃个数为例,mapreduce就是把数据分配给多个人,并行计算,每一个人获得一个局部聚合的临时结果,最终再统一汇总一下。这样就可以快速得到答案了,这其实就是MapReduce的计算思想。
分布式计算介绍
以我们平时使用比较多的JDBC代码执行的流程来说。我们自己写的JDBC代码是在一台机器上运行,mysql数据库是在另一台机器上运行。
正常情况下,我们通过jdbc代码去mysql中获取一条数据,速度还是很快的,但是有一个极端情况,如果我们要获取的数据量很大,达到了几个G,甚至于几十G。这个时候我们使用jdbc代码去拉取数据的时候,就会变得非常慢,
这个慢主要是由于两个方面造成的,
- 一个是磁盘io(会进行磁盘读写操作),
- 一个是网络io(网络传输)。
这两个里面其实最耗时的还是网络io,我们平时在两台电脑之间传输一个几十G的文件也需要很长时间的,但是如果是使用U盘拷贝就很快了,所以可以看出来主要耗时的地方是在网络IO上面。这种计算方式我们称之为移动数据 ,就是把mysql数据库中的数据移动到计算程序所在的机器上面
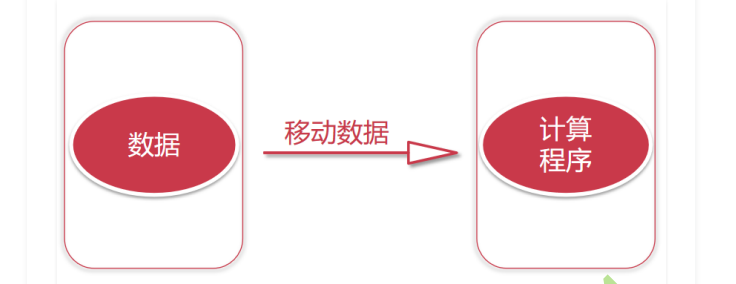
如果我们考虑把计算程序移动到mysql所在机器上面去执行,是不是就可以节省网络io了,是的!
这种方式称之为移动计算,就是把计算程序移动到数据所在的节点上面
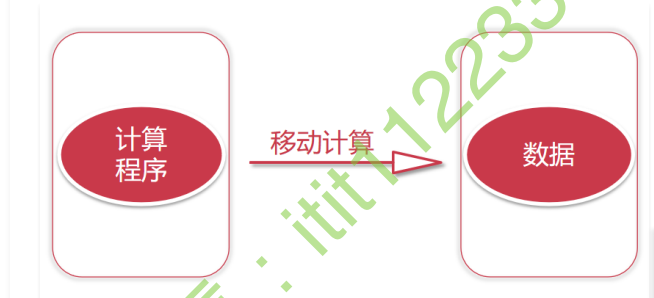
移动数据是传统的计算方式,现在的一种新思路是移动计算。如果我们数据量很大的话,我们的数据肯定是由很多个节点存储的,这个时候我们就可以把我们的程序代码拷贝到对应的节点上面去执行,程序代码都是很小的,一般也就几十KB或者几百KB,加上外部依赖包,最大也就几兆 ,甚至几十兆,但是我们需要计算的数据动辄都是几十G、几百G,他们两个之间的差距不是一星半点啊,
这样我们的代码就可以在每个数据节点上面执行了,但是这个代码只能计算当前节点上的数据的,如果我们想要统计数据的总行数,这里每个数据节点上的代码只能计算当前节点上数据的行数,所以还的有一个汇总程序,这样每个数据节点上面计算的临时结果就可以通过汇总程序得到最终的结果了。此时汇总程序需要传递的数据量就很小了,只需要接收一个数字即可。
这个计算过程就是分布式计算,这个步骤分为两步
- 第一步:对每个节点上面的数据进行局部计算
- 第二步:对每个节点上面计算的局部结果进行全局汇总
MapReduce原理剖析
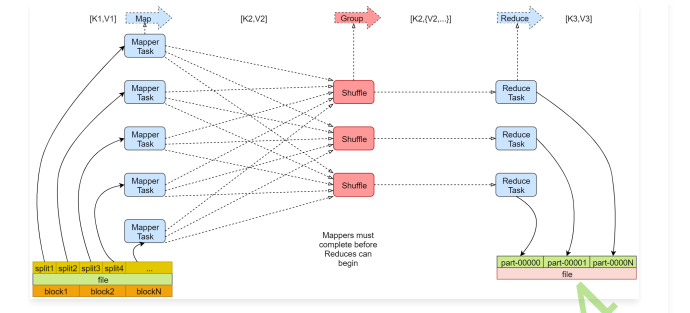
左下角是一个文件,文件最下面是几个block块,说明这个文件被切分成了这几个block块,文件上面是一些split,一个split产生一个map任务。
block块是文件的物理切分,在磁盘上是真实存在的,是对文件的真正切分,而split是逻辑划分,不是对文件真正的切分,默认情况下我们可以认为一个split的大小和一个block的大小是一样的,所以实际上是一个split会产生一个map task
这里面的map Task就是我们前面说的map任务,看后面有一个reduce Task,reduce会把结果数据输出到hdfs上,有几个reduce任务就会产生几个文件,这里有三个reduce任务,就产生了3个文件,我们前面分析的案例中只有一个reduce任务做全局汇总。
map的输入是k1,v1 输出是k2,v2
reduce的输入是k2,v2 输出是k3,v3 都是键值对的形式。
MapReduce之Map阶段
mapreduce主要分为两大步骤 map和reduce,map和reduce在代码层面对应的就是两个类,map对应
的是mapper类,reduce对应的是reducer类,下面我们就来根据一个案例具体分析一下这两个步骤
假设我们有一个文件,文件里面有两行内容
第一行是hello you
第二行是hello me
我们想统计文件中每个单词出现的总次数
首先是map阶段
第一步:
框架会把输入文件(夹)划分为很多InputSplit,这里的inputsplit就是前面我们所说的split【对文件进行逻辑划分产生的】,默认情况下,每个HDFS的Block对应一个InputSplit。再通过RecordReader类,把每个InputSplit解析成一个一个的<k1,v1>。默认情况下,每一行数据,都会被解析成一个<k1,v1>。这里的k1是指每一行的起始偏移量,v1代表的是那一行内容,
所以,针对文件中的数据,经过map处理之后的结果是这样的
<0,hello you>
<10,hello me>
注意:map第一次执行会产生<0,hello you>,第二次执行会产生<10,hello me>,并不是执行一次就获取到这两行结果了,因为每次只会读取一行数据,我在这里只是把这两行执行的最终结果都列出来了
第二步:
框架调用Mapper类中的map(…)函数,map函数的输入是<k1,v1>,输出是<k2,v2>。一个因为我们需要统计文件中每个单词出现的总次数,所以需要先把每一行内容中的单词切开,然后记录出现次数为1,这个逻辑就需要我们在map函数中实现了
那针对<0,hello you>执行这个逻辑之后的结果就是
<hello,1>
<you,1>
针对<10,hello me>执行这个逻辑之后的结果是
<hello,1>
<me,1>
第三步:
框架对map函数输出的<k2,v2>进行分区。不同分区中的<k2,v2>由不同的reduce task处理,默认只有1个分区,所以所有的数据都在一个分区,最后只会产生一个reduce task。经过这个步骤之后,数据没什么变化,如果有多个分区的话,需要把这些数据根据分区规则分开,在这里默认只有1个分区。
<hello,1>
<you,1>
<hello,1>
<me,1>
我们在这所说的单词计数,其实就是把每个单词出现的次数进行汇总即可,需要进行全局的汇总,不需要进行分区,所以一个redeuce任务就可以搞定,如果你的业务逻辑比较复杂,需要进行分区,那么就会产生多个reduce任务了,那么这个时候,map任务输出的数据到底给哪个reduce使用?这个就需要划分一下,要不然就乱套了。假设有两个reduce,map的输出到底给哪个reduce,如何分配,这是一个问题。这个问题,由分区来完成。map输出的那些数据到底给哪个reduce使用,这个就是分区干的事了。
第四步:
框架对每个分区中的数据,都会按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。先按照k2排序
<hello,1>
<hello,1>
<me,1>
<you,1>
然后按照k2进行分组,把相同k2的v2分成一个组
<hello,{1,1}>
<me,{1}>
<you,{1}>
第五步:
在map阶段,框架可以选择执行Combiner过程。
Combiner可以翻译为规约,规约是什么意思呢? 在刚才的例子中,我们最终是要在reduce端计算单词出现的总次数的,所以其实是可以在map端提前执行reduce的计算逻辑,先对在map端对单词出现的次数进行局部求和操作,这样就可以减少map端到reduce端数据传输的大小,这就是规约的好处,当然了,并不是所有场景都可以使用规约,针对求平均值之类的操作就不能使用规约了,否则最终计算的结果就不准确了。Combiner一个可选步骤,默认这个步骤是不执行的
第六步:
框架会把map task输出的<k2,v2>写入到linux 的磁盘文件中
<hello,{1,1}>
<me,{1}>
<you,{1}>
至此,整个map阶段执行结束
最后注意一点:
MapReduce程序是由map和reduce这两个阶段组成的,但是reduce阶段不是必须的,也就是说有的mapreduce任务只有map阶段,为什么会有这种任务呢?是这样的,我们前面说过,其实reduce主要是做最终聚合的,如果我们这个需求是不需要聚合操作,直接对数据做过滤处理就行了,那也就意味着数据经过map阶段处理完就结束了,所以如果reduce阶段不存在的话,map的结果是可以直接保存到HDFS中的。
注意,如果没有reduce阶段,其实map阶段只需要执行到第二步就可以,第二步执行完成以后,结果就可以直接输出到HDFS了。针对我们这个单词计数的需求是存在reduce阶段的,所以我们继续往下面分析。
MapReduce之Reduce阶段
第一步:
框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle
针对我们这个需求,只有一个分区,所以把数据拷贝到reduce端之后还是老样子
<hello,{1,1}>
<me,{1}>
<you,{1}>
第二步:
框架对reduce端接收的相同分区的<k2,v2>数据进行合并、排序、分组。reduce端接收到的是多个map的输出,对多个map任务中相同分区的数据进行合并 排序 分组
注意,之前在map中已经做了排序 分组,这边也做这些操作 重复吗?不重复,因为map端是局部的操作 reduce端是全局的操作
之前是每个map任务内进行排序,是有序的,但是多个map任务之间就是无序的了。不过针对我们这个需求只有一个map任务一个分区,所以最终的结果还是老样子
<hello,{1,1}>
<me,{1}>
<you,{1}>
第三步:
框架调用Reducer类中的reduce方法,reduce方法的输入是<k2,{v2}>,输出是<k3,v3>。一个<k2,{v2}>调用一次reduce函数。程序员需要覆盖reduce函数,实现具体的业务逻辑。那我们在这里就需要在reduce函数中实现最终的聚合计算操作了,将相同k2的{v2}累加求和,然后再转化为k3,v3写出去,在这里最终会调用三次reduce函数
<hello,2>
<me,1>
<you,1>
第四步:
框架把reduce的输出结果保存到HDFS中。
hello 2
me 1
you 1
至此,整个reduce阶段结束。
实战:WordCount案例开发
需求
需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数
hello.txt文件内容如下:
hello you
hello me
最终需要的结果形式如下:
hello 2
me 1
you 1
代码实现
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 需求:读取hdfs上/hello.txt文件内容,计算每个单词出现的总次数
* 原始内容如下:
* hello you
* hello me
* 最终需要的结果形式:
* hello 2
* you 1
* me 1
*/
public class WordCountJob {
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 接收<k1,v1>,产生<k2,v2>
*
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
//k1表示每一行数据的行首偏移量,v1表示每一行数据的内容 <0,hello you> <10,hello me>
String[] words = v1.toString().split(" ");
for (String word : words) {
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1);
//将<k2,v2>写出去
context.write(k2, v2);
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 接收<k2,v2>,产生<k3,v3>
*
* @param k2
* @param v2
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable num : v2) {
sum += num.get();
}
Text k3 = new Text(k2.toString());
LongWritable v3 = new LongWritable(sum);
//将<k3,v3>写出去
context.write(k3, v3);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个job
Configuration config = new Configuration();
Job job = Job.getInstance(config, "wordCountJob");
//必须设置 不然找不到执行类
job.setJarByClass(WordCountJob.class);
//设置输入路径和输出路径
String inputPath = args[0];
String outputPath = args[1];
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
//设置mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}
}
上传到集群执行
我们需要打jar包上传到集群上去执行,这个时候需要在pom文件中添加maven的编译打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.5.5</version>
<configuration>
<archive>
<manifest>
<mainClass>com.imooc.bigdata.mr.WordCountJob</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
还需要在pom中的hadoop-client依赖中增加scope属性,值为provided,表示只在编译的时候使用这个依赖,在执行以及打包的时候都不使用,因为hadoop-client在集群中是有的,所以在打jar包的时候就不需要打进去了。注意,需要使用jar-with-dependencies结尾的那个jar包。
bin/hdfs dfs -put hello.txt /hello.txt
编辑hello.txt并上传到hdfs,内容为
hello you
hello me
bin/hadoop jar bigdata.jar /hello.txt /out
bin/hadoop jar bigdata.jar com.imooc.bigdata.mr.WordCountJob /hello.txt /out
注意,如果pom文件中指定了mainClass,这里就不需要指定了。
- hadoop:表示使用hadoop脚本提交任务,其实在这里使用yarn脚本也是可以的,从hadoop2开始
支持使用yarn,不过也兼容hadoop1,也继续支持使用hadoop脚本,所以在这里使用哪个都可以,具体看个人喜好 - jar:表示执行jar包
- bigdata.jar:指定具体的jar包路径信息
- com.imooc.bigdata.mr.WordCountJob:指定要执行的mapreduce代码的全路径
- /hello.txt:指定mapreduce接收到的第一个参数,代表的是输入路径,这里的输入路径可以直
接指定hello.txt的路径,也可以直接指定它的父目录,因为它的父目录里面也没有其它无关的文件,
如果指定目录的话就意味着hdfs会读取这个目录下所有的文件,所以后期如果我们需要处理一批文
件,那就可以把他们放到同一个目录里面,直接指定目录即可。 - /out:指定mapreduce接收到的第二个参数,代表的是输出目录,这里的输出目录必须是不存在
的,MapReduce程序在执行之前会检测这个输出目录,如果存在会报错,因为它每次执行任务都需
要一个新的输出目录来存储结果数据
查看执行结果
任务提交到集群上面之后,可以在shell窗口中看到如下日志信息,最终map执行到100%,reduce执行
到100%,说明任务执行成功了。
2020-04-22 15:12:59,887 INFO mapreduce.Job: map 0% reduce 0%
2020-04-22 15:13:08,050 INFO mapreduce.Job: map 100% reduce 0%
2020-04-22 15:13:16,261 INFO mapreduce.Job: map 100% reduce 100%
当然了,也可以到web界面中查看任务执行情况 http://ip:8088。
在/out输出目录中,_SUCCESS是一个标记文件,有这个文件表示这个任务执行成功了。
part-r-00000是具体的数据文件,如果有多个reduce任务会产生多个这种文件,多个文件的话会按照从0
开始编号,00001,00002等等…
还要一点需要注意的,part后面的r表示这个结果文件是reduce步骤产生的,如果一个mapreduce只有
map阶段没有reduce阶段,那么产生的结果文件是part-m-00000这样的。
MapReduce任务日志查看
如果想要查看mapreduce任务执行过程产生的日志信息怎么办呢?
System.out.println("k2:"+word+"...v2:1");
log.info("k2:"+word+"...v2:1");
重新打包上传,等待任务执行结束,我们发现在控制台上是看不到任务中的日志信息的,为什么呢?因为我们在这相当于
是通过一个客户端把任务提交到集群里面去执行了,所以日志是存在在集群里面的。想要查看需要需要到
一个特殊的地方查看这些日志信息。先进入到yarn的web界面,访问8088端口,点击对应任务的history链接 http://ip:8088
注意了,在这里我们发现这个链接是打不开的,
这里有两个原因,
- 第一个原因是windows的hosts文件中没有配置bigdata01和ip的映射关系。
- 第二个原因就是这里必须要启动historyserver进程才可以,并且还要开启日志聚合功能,才能在web界
面上直接查看任务对应的日志信息,因为默认情况下任务的日志是散落在nodemanager节点上的,想要
查看需要找到对应的nodemanager节点上去查看,这样就很不方便,通过日志聚合功能我们可以把之前
本来散落在nodemanager节点上的日志统一收集到hdfs上的指定目录中,这样就可以在yarn的web界面
中直接查看了。
开启日志聚合功能
修改yarn-site.xml文件,添加以下属性,重启集群
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs/</value>
</property>
启动historyserver进程
bin/mapred --daemon start historyserver
重新再提交mapreduce任务
bin/hadoop jar bigdata2.jar com.imooc.bigdata.mr.WordCountJob /hello.txt /out2
此时再进入yarn的8088界面,点击任务对应的history链接就可以打开了。
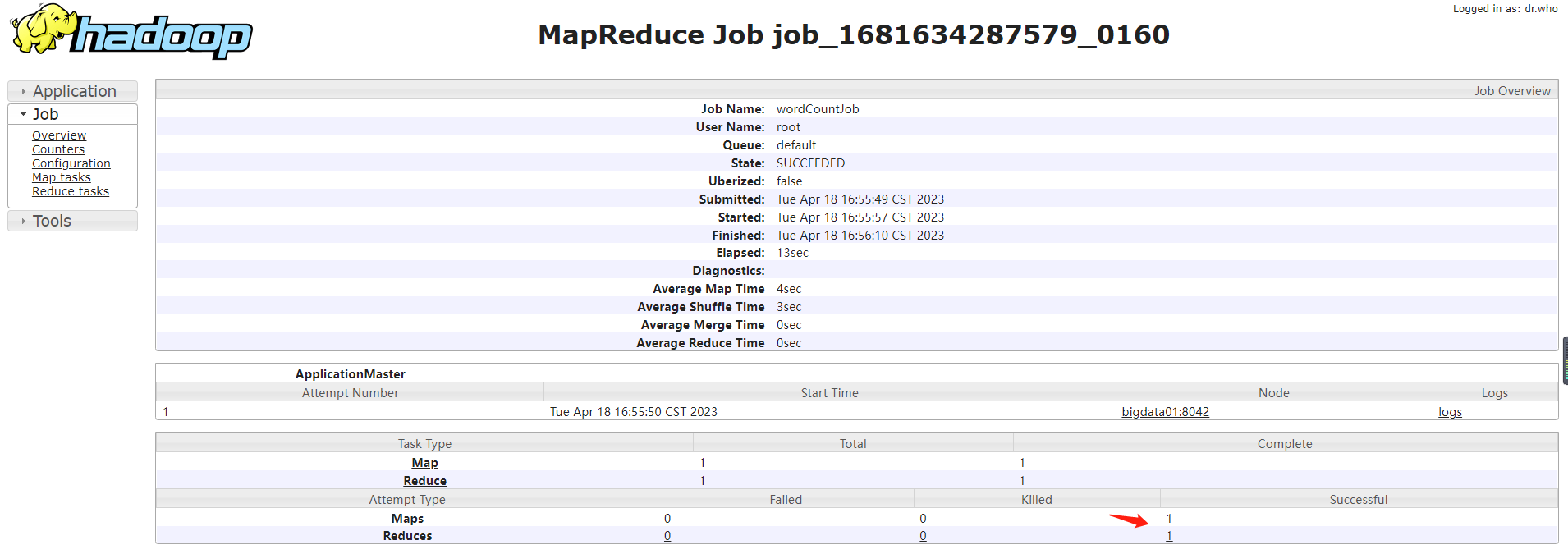

点击之后,遇到了这个问题
Logs not available for attempt_1681634287579_0160_r_000000_0. Aggregation may not be complete, Check back later or try the nodemanager at bigdata01:35349
Or see application log at http://bigdata01:35349/node/application/application_1681634287579_0160
折腾了几个小时,最后发现是集群的停止功能没有生效,jps查看是没有进程的,但ps -ef | grep hadoop还是存在的,也不知道是如何出现的,最后kill -p pid,强制杀死hadoop进程,重新启动集群,重新提交任务,就可以看到日志了。
通过命令查看日志
通过web页面是工作中比较常用的查看日志的方式,但是还有一种使用命令查看的方式
bin/yarn logs -applicationId application_1681820630349_0001
注意:后面指定的是任务id,任务id可以到yarn的web界面上查看
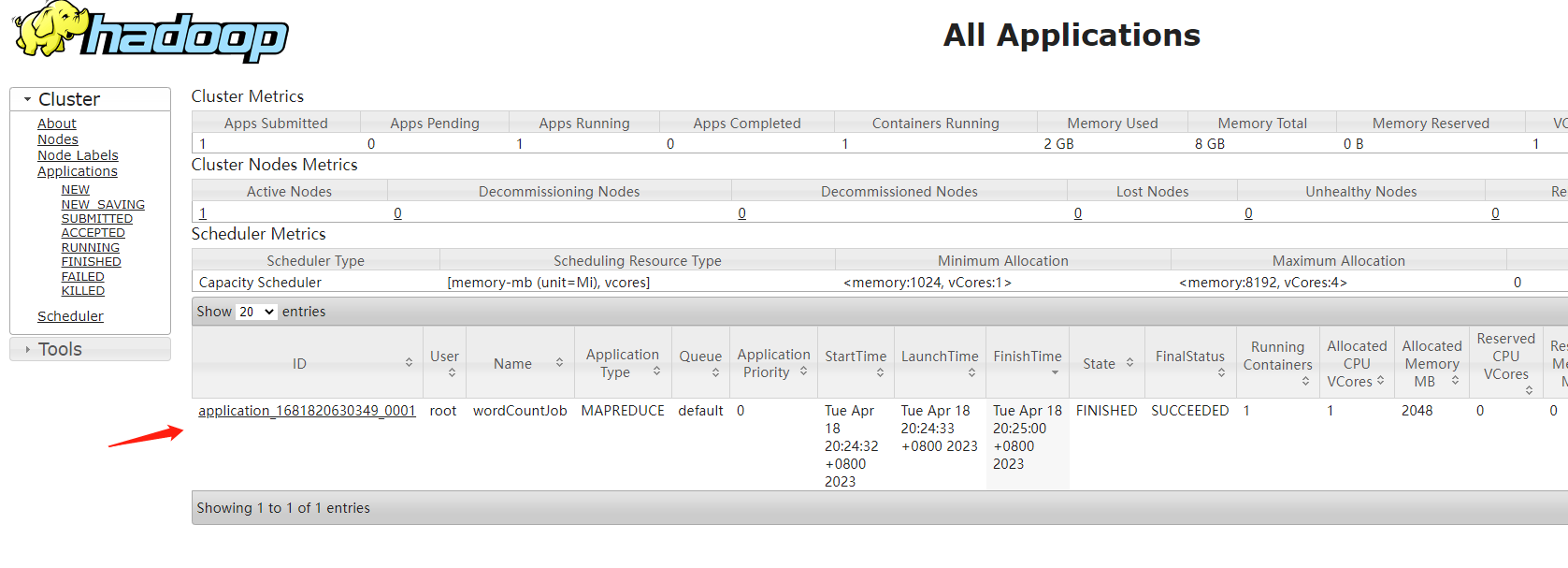
执行这个命令可以看到很多的日志信息,我们通过grep筛选一下日志
bin/yarn logs -applicationId application_1681820630349_0001 | grep "<k2"
这种方式也需要掌握住,在一些特殊的场景下,无法使用yarn的web界面查看日志,就需要使用yarn logs命令了。
停止Hadoop集群中的任务
如果一个mapreduce任务处理的数据量比较大的话,这个任务会执行很长时间,可能几十分钟或者几个小时都有可能,假设一个场景,任务执行了一半了我们发现我们的代码写的有问题,需要修改代码重新提交执行,这个时候之前的任务就没有必要再执行了,没有任何意义了,最终的结果肯定是错误的,所以我们就想把它停掉,要不然会额外浪费集群的资源,如何停止呢?
bin/yarn application -kill application_1681820630349_0001
MapReduce程序扩展
我们前面说过MapReduce任务是由map阶段和reduce阶段组成的
但是我们也说过,reduce阶段不是必须的,那也就意味着MapReduce程序可以只包含map阶段。
什么场景下会只需要map阶段呢?当数据只需要进行普通的过滤、解析等操作,不需要进行聚合,这个时候就不需要使用reduce阶段了
在代码层面该如何设置呢?很简单,在组装Job的时候设置reduce的task数目为0就可以了。并且Reduce代码也不需要写了。
//禁用reduce阶段
job.setNumReduceTasks(0);
参考
0747-5.16.2-YARN日志聚合目录说明
Yarn无法查看日志: Aggregation may not be complete, Check back later or try the nodemanager at xxxx:xxxx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号