





Hadoop技术入门
什么是Hadoop
我们生活在一个数据大爆炸的时代,数据飞快的增长,急需解决海量数据的存储和计算问题。
这个时候,Hadoop就应运而生了。
Hadoop是一个适合海量数据的分布式存储和分布式计算的框架。
分布式存储,可以简单理解为存储数据的时候,数据不只存在一台机器上面,它会存在多台机器上面。
分布式计算简单理解,就是由很多台机器并行处理数据,我们在写java程序的时候,写的一般都是单机的程序,只在一台机器上运行,这样程序的处理能力是有限的。
Hadoop发行版介绍
官方原生版本:Apache Hadoop
我们后面学习的99%的大数据技术框架都是Apache开源的,所以在这里我们会学习原生的Hadoop,只要掌握了原生Hadoop使用,后期想要操作其它发行版的Hadoop也是很简单的,其它发行版都是会兼容原生Hadoop的,这一点大家不同担心。 原生Hadoop的缺点是没有技术支持,遇到问题需要自己解决,或者通过官网的社区提问,但是回复一般比较慢,也不保证能解决问题, 还有一点就是原生Hadoop搭建集群的时候比较麻烦,需要修改很多配置文件,如果集群机器过多的话,针对运维人员的压力是比较大的,这块等后面我们自己在搭建集群的时候大家就可以感受到了。
Cloudera Hadoop(CDH)
CDH是一个商业版本,它对官方版本做了一些优化,提供收费技术支持,提供界面操作,方便集群运维管理 CDH目前在企业中使用的还是比较多的,虽然CDH是收费的,但是CDH中的一些基本功能是不收费的,可以一直使用,高级功能是需要收费才能使用的,如果不想付费,也能凑合着使用。
HortonWorks(HDP)
是开源的,也提供的有界面操作,方便运维管理,一般互联网公司偏向于使用这个。
最新消息,目前HDP已经被CDH收购,都是属于一个公司的产品,后期HDP是否会合并到CDH中,还不得而知,具体还要看这个公司的运营策略了。
使用建议
最终的建议:建议在实际工作中搭建大数据平台时选择 CDH或者HDP,方便运维管理,要不然,管理上千台机器的原生Hadoop集群,运维同学是会哭的。
Hadoop版本演变历史
hadoop1.x:HDFS+MapReduce
hadoop2.x:HDFS+YARN+MapReduce
hadoop3.x:HDFS+YARN+MapReduce
HDFS是分布式存储,MapRecue是分布式计算。
在Hadoop1.x中,分布式计算和资源管理都是MapReduce负责的,从Hadoop2.x开始把资源管理单独拆分出来了,拆分出来的好处就是,YARN变成了一个公共的资源管理平台,在它上面不仅仅可以跑MapReduce程序,还可以跑很多其他的程序,只要你的程序满足YARN的规则即可,Spark、Flink等计算框架都是支持在YARN上面执行的,并且在实际工作中也都是在YARN上面执行。

Hadoop三大核心组件介绍
Hadoop主要包含三大组件:HDFS+MapReduce+YARN
- HDFS负责海量数据的分布式存储
- MapReduce是一个计算模型,负责海量数据的分布式计算
- YARN主要负责集群资源的管理和调度
配置jdk
编辑/root/.bash_profile文件,添加JAVA_HOME和PATH环境变量
source /root/.bash_profile
配置生效
设置hostname
vim /etc/hostname
修改为bigdata01,重启服务器才会生效。
配置ssh免密登录
hadoop集群就会使用到ssh,我们在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来。
但是现在有一个问题,就是我们使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
注意了,不管是几台机器的集群,启动集群中程序的步骤都是一样的,都是通过ssh远程连接去操作,就算是一台机器,它也会使用ssh自己连自己,我们现在使用ssh自己连自己也是需要密码的。
ssh-keygen -t rsa
rsa表示的是一种加密算法,执行以后会在/root/.ssh目录下生成对应的公钥和秘钥文件,下一步是把公钥拷贝到需要免密码登录的机器上面
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
然后就可以通过ssh 免密码登录到bigdata01机器了。
伪分布集群安装

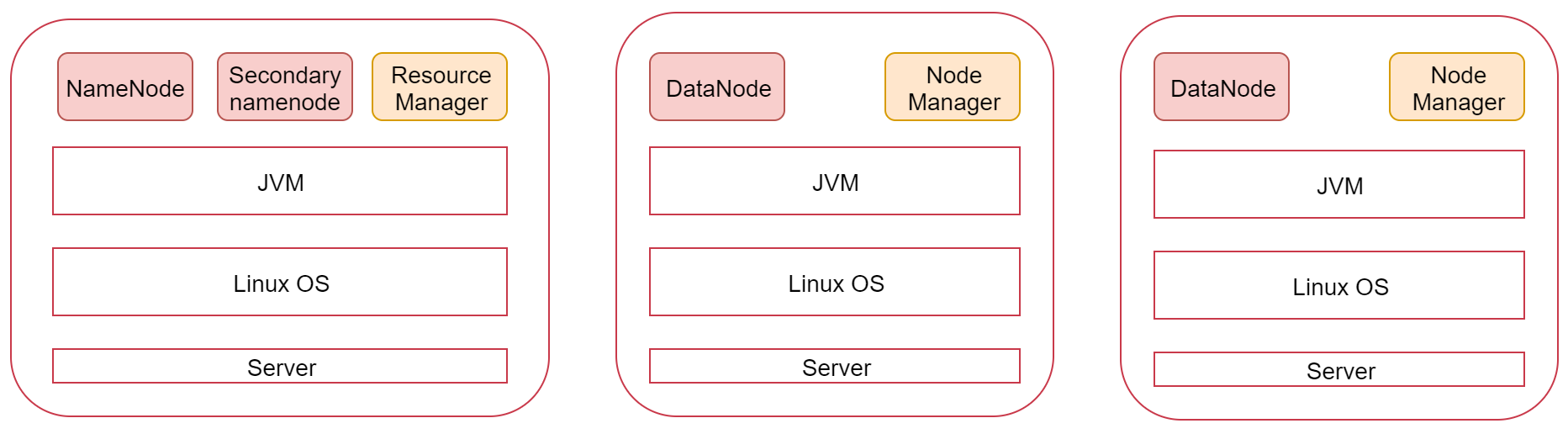
这张图代表是一台Linux机器,也可以称为是一个节点,上面安装的有JDK环境
最上面的是Hadoop集群会启动的进程,其中NameNode、SecondaryNameNode、DataNode是HDFS服务的进程,ResourceManager、NodeManager是YARN服务的进程,MapRedcue在这里没有进程,因为它是一个计算框架,等Hadoop集群安装好了以后MapReduce程序可以在上面执行。
这里我们下载3.2.0版本,具体下载路径
修改Hadoop相关配置文件
主要修改下面这几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
都在etc/hadoop下
修改 hadoop-env.sh 文件
export JAVA_HOME=/root/test_hadoop/jdk8
export HADOOP_LOG_DIR=/root/test_hadoop/logs
添加到文件最后,注意创建logs目录
修改 core-site.xml 文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/test_hadoop/tmp</value>
</property>
</configuration>
fs.defaultFS 属性中的主机名需要和你配置的主机名保持一致,注意创建tmp目录,注意bigdata01不能改为ip地址,修改了之后NameNode进程不能启动,具体原因未知。
修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
把hdfs中文件副本的数量设置为1,因为现在伪分布集群只有一个节点
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
设置mapreduce使用的资源调度框架
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
设置yarn上支持运行的服务和环境变量白名单
修改workers
设置集群中从节点的主机名信息,在这里就一台集群,所以就填写bigdata01即可。
配置文件到这就修改好了,但是还不能直接启动,因为Hadoop中的HDFS是一个分布式的文件系统,文件系统在使用之前是需要先格式化的,就类似我们买一块新的磁盘,在安装系统之前需要先格式化才可以使用。
格式化HDFS
/root/test_hadoop/hadoop3.2/bin/hdfs namenode -format
如果能看到successfully formatted这条信息就说明格式化成功了。如果提示错误,一般都是因为配置文件的问题,当然需要根据具体的报错信息去分析问题。
注意:格式化操作只能执行一次,如果格式化的时候失败了,可以修改配置文件后再执行格式化,如果格式化成功了就不能再重复执行了,否则集群就会出现问题。
如果确实需要重复执行,那么需要把tmp目录中的内容全部删除,再执行格式化
启动伪分布集群
sbin/start-all.sh
执行的时候发现有很多ERROR信息,提示缺少HDFS和YARN的一些用户信息。
解决方案如下:修改sbin目录下的start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改sbin目录下的start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
再启动集群
验证集群进程信息
jps查看集群进程信息
4560 NodeManager
4405 ResourceManager
4149 SecondaryNameNode
3754 NameNode
4893 Jps
3902 DataNode
说明集群是正常启动的,还可以通过web界面来验证集群服务是否正常
HDFS web界面:http://xxx:9870
YARN web界面:http://xxx:8088
停止集群
如果修改了集群的配置文件或者是其它原因要停止集群,可以使用下面命令
sbin/stop-all.sh
分布式集群安装
架构
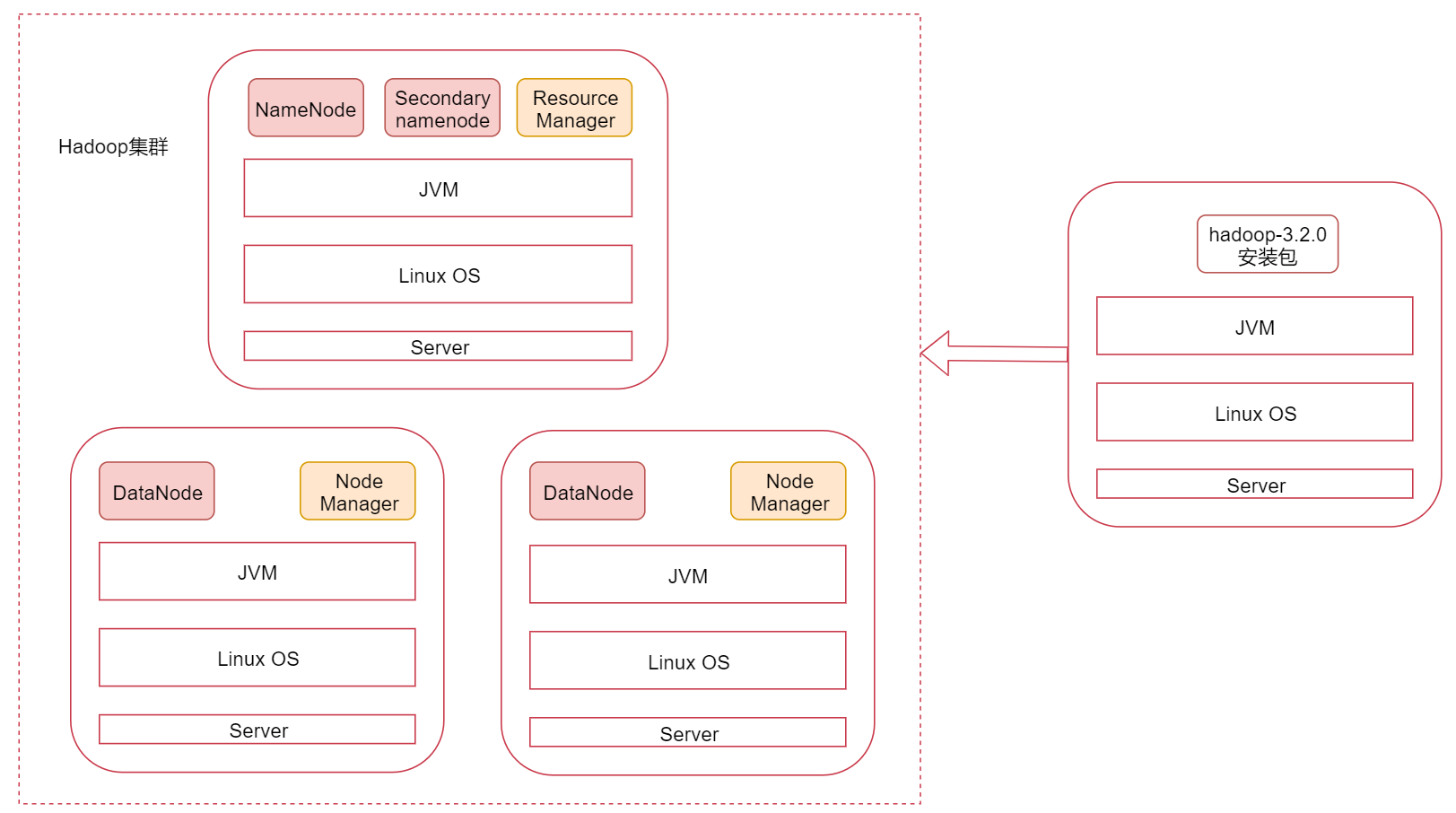
图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
不同节点上面启动的进程默认是不一样的。
环境准备
bigdata01 ip1
bigdata02 ip2
bigdata03 ip3
针对这三台机器的hostname、JDK这些基础环境的配置步骤在这里就不再记录了,具体步骤参考上面。
配置/etc/hosts
因为需要在主节点远程连接两个从节点,所以需要让主节点能够识别从节点的主机名,使用主机名远程访问,默认情况下只能使用ip远程访问,想要使用主机名远程访问的话需要在节点的/etc/hosts文件中配置对应机器的ip和主机名信息。
在bigdata01的/etc/hosts文件中配置下面信息,最好把当前节点信息也配置到里面,这样这个文件中的内容就通用了,可以直接拷贝到另外两个从节点
ip1 bigdata01
ip2 bigdata02
ip3 bigdata03
集群节点之间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集群的稳定性,甚至导致集群出问题。
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步,默认是没有ntpdate命令的,需要使用yum在线安装,执行命令 yum install -y ntpdate
建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次,然后在bigdata02和bigdata03节点上配置时间同步
SSH免密码登录完善
注意:针对免密码登录,目前只实现了自己免密码登录自己,最终需要实现主机点可以免密码登录到所有节点,所以还需要完善免密码登录操作。将公钥信息拷贝到两个从节点
scp ~/.ssh/authorized_keys bigdata02:~/
然后在bigdata02和bigdata03上执行
cat ~/authorized_keys >> ~/.ssh/authorized_keys
验证一下效果,在bigdata01节点上使用ssh远程连接两个从节点,如果不需要输入密码就表示是成功的,此时主机点可以免密码登录到所有节点。没有必要实现从节点之间互相免密码登录,因为在启动集群的时候只有主节点需要远程连接其它节点。
修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
</configuration>
把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点,还有secondaryNamenode进程所在的节点信息
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
</configuration>
注意,针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
修改workers文件
bigdata02
bigdata03
增加所有从节点的主机名,一个一行
总结
由于服务器资源不足,这种方式的集群安装没有实际操作。上面的配置都是和伪分布有区别的,相同的配置就没有写。
Hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的
建议在业务机器上安装Hadoop,只需要保证业务机器上的Hadoop的配置和集群中的配置保持一致即可,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点
Hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机器配置为hadoop集群的客户端节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号