

ComicEnhancerPro 系列教程十七:二值化图像去毛刺
作者:马健
邮箱:stronghorse_mj@hotmail.com
主页:http://www.comicer.com/stronghorse/
发布:2017.07.23
教程十七:二值化图像去毛刺
在灰度图像处理成纯黑白(二值化)图像以后,经常出现的一个问题是轮廓边缘出现毛刺。如下面这个图像:
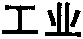
为了看得更清楚,放大到800%并加网格线:
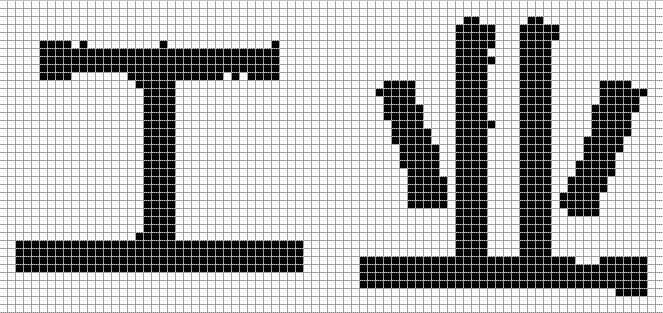
可以看出在“工”字的上面一横中,上边缘有几个突出点,下边缘有两个凹陷点,而在“业”字左侧竖条中有突出点,下面一横中有凹陷点。
产生毛刺的原因是:在扫描或拍摄所生成的原始图像中,轮廓边缘像素点的值其实是介于“白”与“黑”之间的“灰”,所以整个边缘看起来很光滑、不生硬,但变成纯黑白后,像素点非黑即白,不再有中间灰,所以总有那么几个点可能就因为值稍微差了一点,就与周围的不一样了。 具体可以参见本系列教程“后记”中“常见问题之二:扫描图像中的黑、白、灰”部分。
所以解决的办法就是:
- 让模糊来得更猛烈一些吧!如果模糊得更均匀一些,这种毛刺现象其实会更少一点。所以在本系列教程的其它部分给出的处理参数中,经常会看到在选择纯黑白后,用高斯模糊来消毛刺。另外对图像进行放大也会拉出一些模糊空间,一方面可以减轻毛刺,另一方面可以避免转成纯黑白图像后出现笔画粘连——所以我一直觉得在 针对扫描书籍的图像处理教程中,如果只提二值化却不提放大,就是在骗鬼。
- 用数字图像处理中的形态学方法识别孤立点、凹陷点,然后去除或填平。
在ScanTailor(以下简称ST)中用的就是第2种方法,在CEP v4.13中被引进:在“色彩设置”界面中如果在“色彩数”中选择“纯黑白”,再勾选“边缘去毛刺”,即可使用这种方法。
这种方法的原理是:
- 先总结常见的边缘毛刺形状(孤立点或凹陷点)及修正方法(去除或填平),并以字符串的形式定义成模板。
- 用形态学中的击中-击不中变换(Hit-Miss Transform),在整张图像中查找能与模板匹配的像素点,然后按照模板对像素进行去除或填充。
在ST中总结出来的模板共有6个,分别是:
| 1 | 2 | 3 | 4 | 5 | 6 |
| "XXX" " - " " " |
"X ?" "X " "X- " "X- " "X " "X ?" |
"X ?" "X ?" "X " "X- " "X- " "X- " "X " "X ?" "X ?" |
"XX?" "XX?" "XX " "X+ " "X+ " "X+ " "XX " "XX?" "XX?" |
"XX?" "XX " "X+ " "X+ " "XX " "XX?" |
" " "X+X" "XXX" |
在模板中共有5种符号:X表示黑点,空格表示白点,问号表示黑点白点均可,减号表示去除点,加号表示填充点。所以上表中的前3个模板就表示如果在一排黑点外有孤立点,则孤立点应去除,如上面示例图中“工”字上面一横中的几个孤立点;后3个模板则表示如果黑点中间有凹陷点,则应该进行填充,如上面示例图中“业”字底下一横中的几个凹陷点。
在ST中,每个模板会在上、下、左、右4个方向分别匹配,以模板1为例,其实在内部会扩充为以下4个模板进行匹配:
| "XXX" " - " " " |
" " " - " "XXX" |
"X " "X- " "X " |
" X" " -X" " X" |
因此6个模板其实内部要匹配24次,在图像较大时就会显得很慢,这也是我平时更喜欢用模糊来进行平滑的原因:CEP中的高斯模糊还是很快的。
整个处理过程的核心是在图像中查找模板的所有匹配点,即需要去除、填充的点,用的是击中-击不中变换(Hit-Miss Transform)。在我看过的教科书中包括ST的源代码本身,都是用腐蚀、膨胀等形态学基本操作的组合来实现这个变换,但我个人认为多次双循环会拖累代码的整体执行速度,所以在实现时我是按照这个变换最原始的定义实现的,一次双循环周游整个图像就找出所有匹配点,速度比ST略快,但内存消耗比ST大。
上面示例图用CEP去除毛刺后的效果: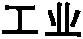
放大到800%并加网格线的效果: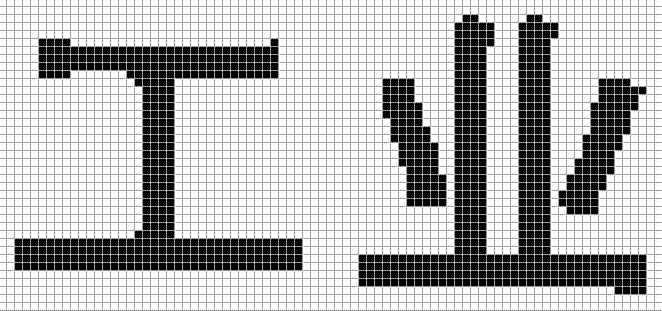
可以看出,横线、竖线上的孤立点都被去除,凹陷点也被填平,文字看起来干净了许多。

