scrapy添加图片管道
1,首先,开启scrapy自带图片管道,在settings.py文件里加上如下代码:
ITEM_PIPELINES = {
'zhibo8.pipelines.Zhibo8Pipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 301 #开启图片管道
}
#获取当前项目路径
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
#设置图片保存路径
#IMAGES_STORE = '/www/crawl'
IMAGES_STORE = os.path.join(BASE_DIR,'images')
# 图片的下载地址 根据item中的字段来设置哪一个内容需要被下载
IMAGES_URLS_FIELD = 'image_urls'
2,在你的爬虫里添加相应的字段
#使用ImagesPipliene 下载图片时,需要使用image_urls字段,
# 一般是可迭代的列表list类型
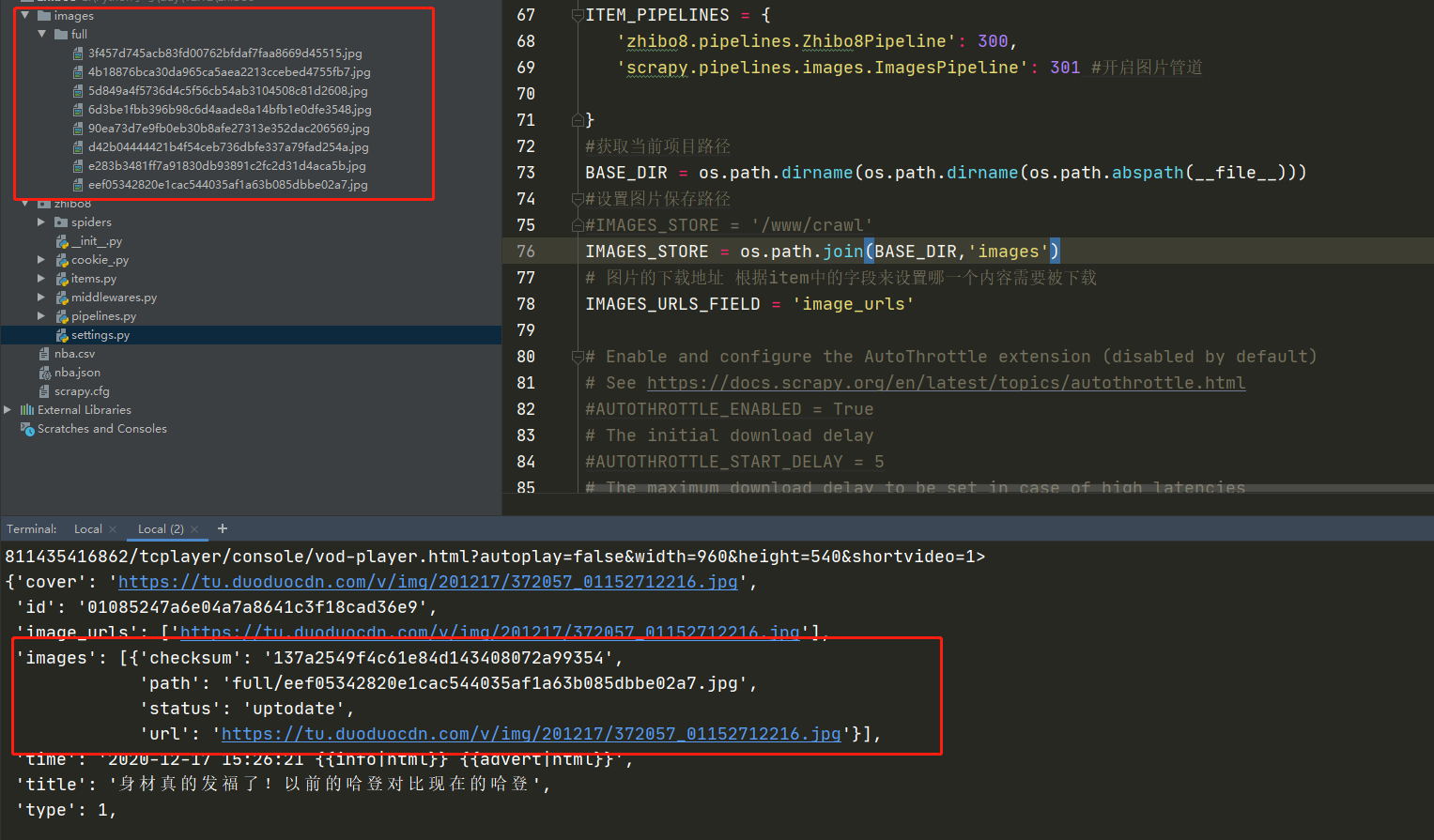
imageUrl = response.xpath('//*[@id="signals"]/div[1]/div[1]/img/@src').extract() #此处是你的xpath路径,根据自己情况修改
imageUrl[0] = 'https:'+imageUrl[0] #给图片地址加上完整链接
item['imageUrls'] = imageUrl
item['images'] = [] #下载图片之后,保存到本地的文件位置
3,运行项目
scrapy crawl 爬虫名 -o 文件名.json
4,如如所示:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~