推荐系统中图神经网络应用(二)序列(会话)推荐
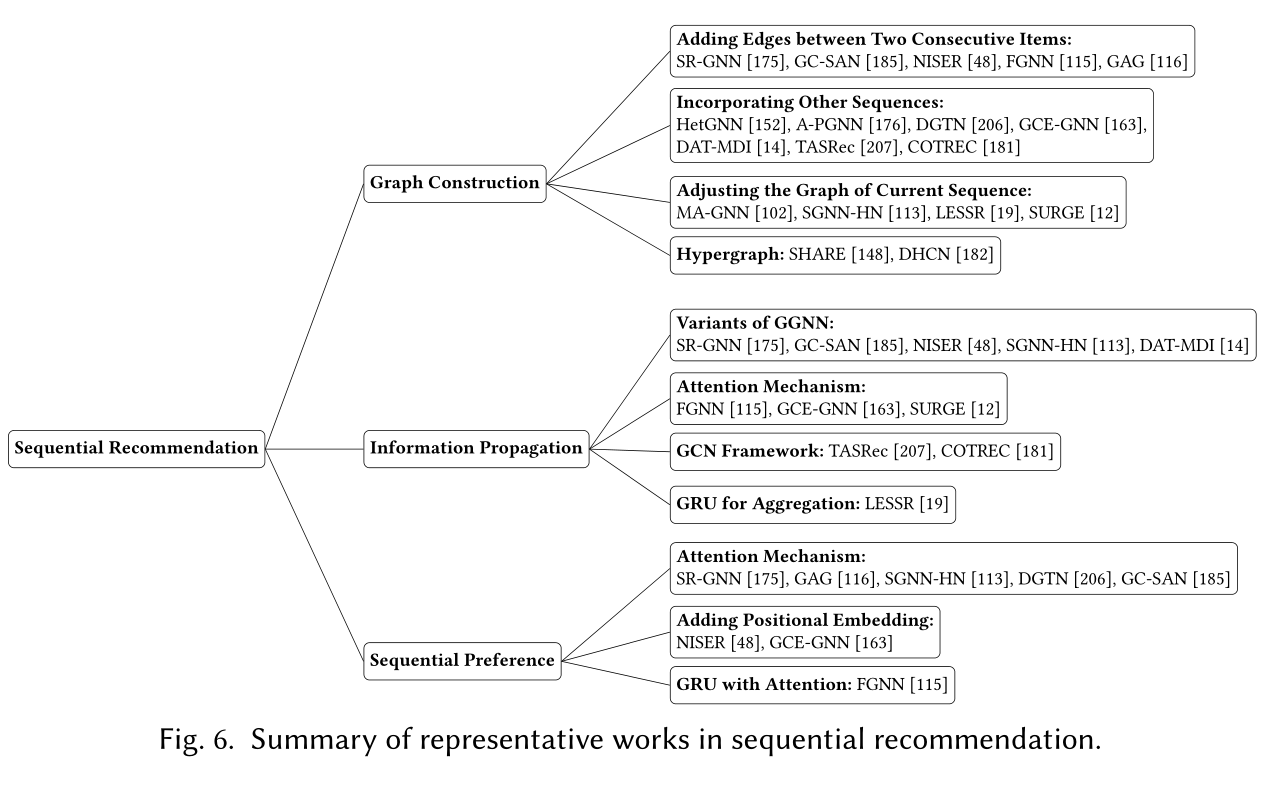
图序列推荐是从用户交互的连续物品中挖掘用户的行为模式,它将原始的物品序列构建为图的形式,并通过添加节点、边、融合其他序列以及添加超边的方法增强图的表达。
图序列推荐目前存在三个待解决的问题:
-
图结构
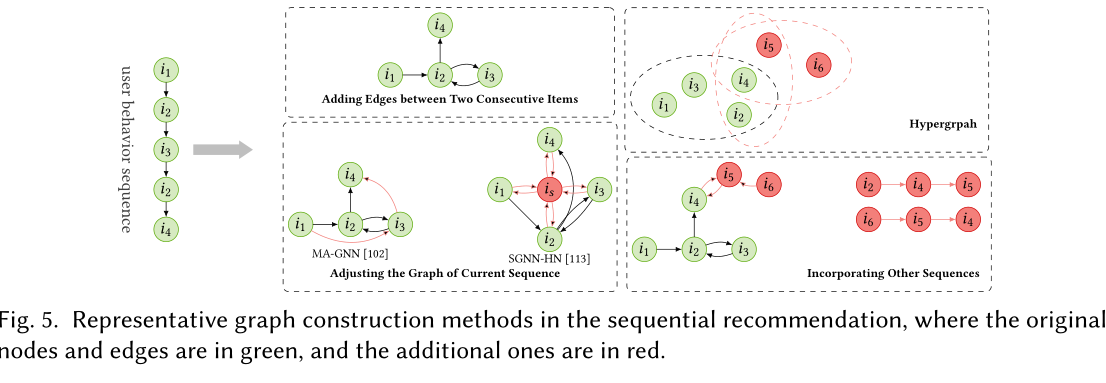
- 目前数据集中用户的行为序列长度普遍偏短(5左右),如果只是在序列的物品之间添加节点来构建图将会限制图中的信息并难以利用GNN在图数据学习上的优势。最近的工作针对这一问题有两种主流的做法:
- 利用额外的序列丰富物品序列长度。
- [152]HetGNN/2020利用所有行为序列,以行为类别在物品之间构建边。
- [176]A-PGNN/2019是将用户历史序列与当前序列结合以丰富项目间连接。
- [163]GCE-GNN/2020和[14]DAT-MDI/2021利用了所有会话中的序列来帮助学习当前序列的行为模式,这利用了局部上下文和全局上下文。
- [207]TASRec/2021相对于GCE-GNN和DAT-MDI而言给最近的序列更高的权重,而不是将所有的序列一视同仁。
- [206]DGTN/2020只将相似的序列添加到当前的序列中
- 另外一种主流做法是对当前序列的图结构进行调整。
- [102]MA-GNN/2020认为当前节点会影响之后的节点,因此抽取了当前节点之后的三个节点,并在这些节点之间添加边连接。
- 考虑到只对序列中邻近的物品添加边不能捕获距离较远物品的关系,[113]SGNN-HN/2020引入了虚拟的‘star’节点作为中心节点,其它的所有节点都与‘star’节点相连接。而‘star’节点的向量则代表了整个序列的特征。而其余节点也可以在不直接与其它节点相连接的情况下获得其它节点的信息。
- [19]LESSR/2020则认为现有的图构造方法忽略了邻居之间的顺序关系,因而在长期依赖信息的获取能力方面有所欠缺。LESSR对于同一个序列构建了两种图结构,一种严格区分了节点之间的先后顺序。另一种则允许图内存在short-cut的路径。
- 除了以上两种图构建的主流做法外,最近受超图在超对关系建模的优势启发,超图最近被用来捕获物品之间的高阶关系以及跨会话信息
- [148]SHARE/2021为每个会话构建一个超图,其中的超边由不同大小的滑动窗口定义。
- [182]DHCN/2021/将每个会话视为一个超边,然后将所有会话整合起来变为一个超图。
-
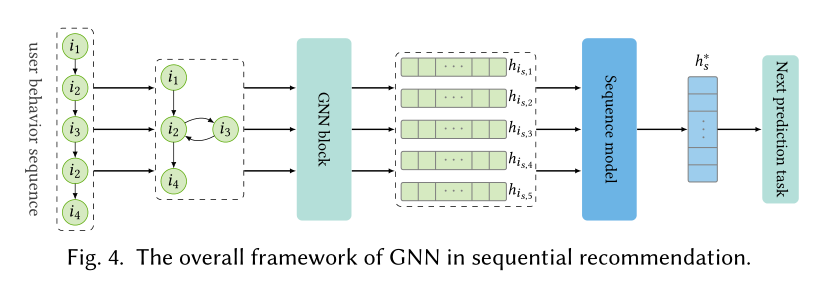
信息传递
- 对于一个构建好的图,怎么设计一个高效的信息传递机制来对序列进行建模是一个至关重要的问题。GGNN/2016是一个广泛被用于有向图的信息传递模型,它使用平均池化来对节点前、后的多个邻居节点进行信息聚合,然后使用GRU来整合邻居节点和中心节点信息。:\[\begin{equation} \begin{split} \mathbf{n}^{{\rm in}(l)}_{i_{s,t}} = \frac{1}{\lvert \mathcal{N^{{\rm in}}_{i_{s,t}}}\rvert} \sum_{j \in \mathcal{N}_{i_{s.t}}^{{\rm in}}}\mathbf{h}^{(l)}_j &, \mathbf{n}^{{\rm out}(l)}_{i_{s,t}} = \frac{1}{\lvert \mathcal{N^{{\rm out}}_{i_{s,t}}}\rvert} \sum_{j \in \mathcal{N}_{i_{s.t}}^{{\rm out}}}\mathbf{h}^{(l)}_j \\ \mathbf{n}^{(l)}_{i_{s,t}} = \mathbf{n}^{{\rm in}(l)}_{i_{s,t}} \oplus \mathbf{n}^{{{\rm out}}(l)} &, \mathbf{h}^{(l+1)}_{i_{s,t}} = \mathbf{GRU}(\mathbf{h}^{(l)}_{i_{s,t}},\mathbf{n}^{(l)}_{i_{s,t}}), \end{split} \end{equation} \]
-
GGNN对邻居的聚合是无差别的,这导致物品的先后顺序信息丢失。[19]LESSR/2020使用GRU来对节点的邻居节点进行聚合:
\[\mathbf{n}^{(l)}_{i_{s,t},k} = \mathbf{GRU}^{(l)}(\mathbf{n}^{(l)}_{i_{s,t},k-1}, \mathbf{h}^{(l)}_{i_{s,t},k}) \]其中\(k\)表示中心节点\(i\)的第\(k\)个邻居节点(以时间先后顺序排列)。
-
超图方面
-
DHCN使用了经典的超图神经网络[36]HGNN/2019,这个模型在信息传递过程中将所有节点的权重是不加区分的。而[148]SHARE/2021则在超边之间以及内部使用了两种注意力机制。
-
[176]A-PGNN以及[116]GAGA/2020隐式地引入了用户信息,用于增强邻居物品的表示。
-
- 对于一个构建好的图,怎么设计一个高效的信息传递机制来对序列进行建模是一个至关重要的问题。GGNN/2016是一个广泛被用于有向图的信息传递模型,它使用平均池化来对节点前、后的多个邻居节点进行信息聚合,然后使用GRU来整合邻居节点和中心节点信息。:
-
序列偏好
- [113,116,175,206]利用注意力机制计算序列中物品和最后一个物品的相似度作为权重,并将加权求和的向量表示作为全局偏好,以最后一个物品作为局部偏好,二者结合作为整体偏好表示(历史物品的注意力加权求和似乎更符合局部激活而不是全局偏好,可作为实验点)。
- [185]GC-SAN/2019在GNN获取的物品表示之上使用多个自注意力层来捕获物品间远距离依赖关系。
- 除了使用注意力机制来融合序列信息之外,序列表示也被显式地加入到融合过程中来。[48]NISER/2019和[163]GCE-GNN/2020加入了positional embedding位置信息,构建了position-aware的序列表示。
- [115]FGNN/2019在GRU中融入了注意力机制以平衡序列的顺序信息和灵活的迁移模式学习。