推荐系统中图神经网络应用(一)协同过滤
基于用户、物品的图协同过滤方法。
-
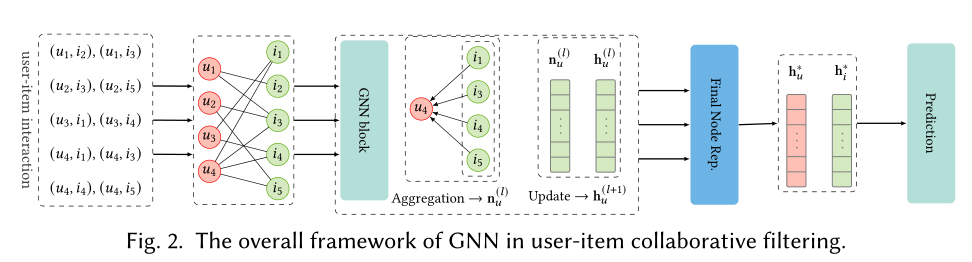
主要是从用户-物品交互的二部图出发,应用图学习方法,获得更好的用户或物品表示,用于后面的预测任务。
-
存在的问题:
-
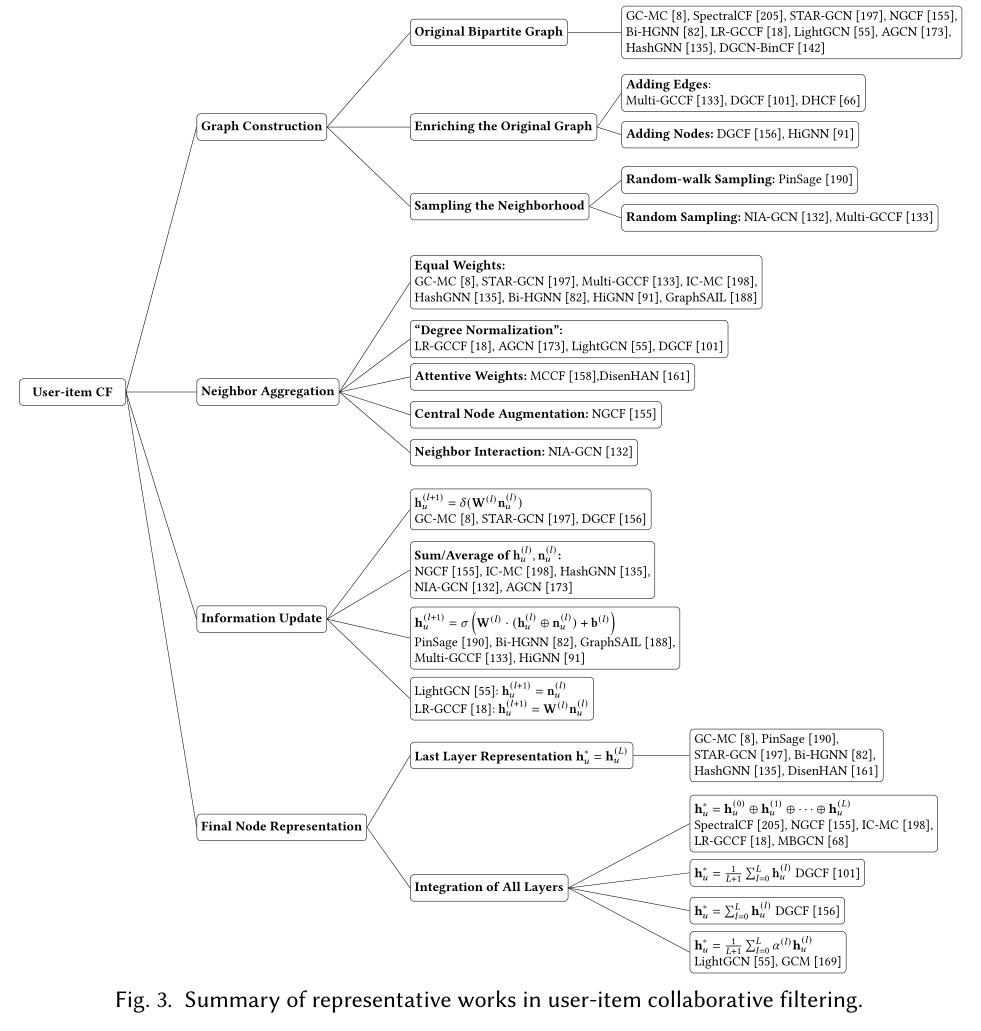
图结构。是直接使用包含用户以及物品两种类型节点的二部图还是构建同质图来进行学习,同时,考虑到计算的复杂度问题,如何对节点的邻居进行采样来更新节点或是使用节点的全部邻居来更新是一个问题。直接使用原始二部图带来节点表示学习的有效性和效率性两个问题。
-
对于有效性问题
-
Multi-GCCF和DGCF通过在二阶邻居之间添加边来获得用户-用户图与物品-物品图,这样可以显式地学习用户、物品内部的相似信息。
-
DFCF引入超边并构建用户、物品超图来捕获显式混合高阶相关性。
-
另一种策略是通过引入虚拟节点来丰富用户-物品交互信息。例如DGCF引入了虚拟意图节点,并将原始图分解为每个意图对应的子图,不同的子图对应不用的意图下的信息。HiGNN对节点进行聚类,并将聚类中心作为新节点,创建新的用户、物品图。
-
-
对于效率性问题
- 一般依赖于采样方法的设计。PinSage设计了一种随机游走的采样策略,这样那些并非中心节点直接邻居的节点也有可能被采样到,。而Multi-GCCF和NIA-GCN则随机从中心节点的邻居中选择一定数目的邻居。采样其实是在原始图信息和计算效率之间进行trade-off。
-
-
聚合邻居节点信息,平均、最大、最小池化或是使用注意力机制计算节点权重。
-
平均权重:
\[\mathbf{n}^{(l)}_u = \frac{1}{\lvert \mathcal{N}_u \rvert}\mathbf{W}^{(l)}\mathbf{h}^{(l)}_i. \] -
度归一化给节点分配权重:
\[\mathbf{n}^{(l)}_u = \sum_{i\in \mathcal{N}_u}\frac{1}{\sqrt{\lvert \mathcal{N}_u \rvert \lvert \mathcal{N}_i \rvert}}\mathbf{W}^{(l)}\mathbf{h}^{(l)}_i. \]这样对于自身有很多邻居的邻居节点,其权重将会降低。这种分配权重的做法依据的是图本身的结构,但是这样的做法忽略了节点之间的关系。
-
MCCF[158]和DisenHAN[107]使用注意力机制来给邻居节点分配权重。
-
-
节点信息更新。这一步骤的通用做法是拼接邻居节点和上一层时的中心节点,通过线性转换来获得新的中心节点表示:
\[\mathbf{h}^{(l+1)}_u = \sigma(\mathbf{W}^{(l)} \cdot (\mathbf{h}^{(l)}_u \oplus \mathbf{n}^{(l)}_u) + \mathbf{b}^{(l)}) \]不过,LightGCN[55]和LR-GCCF[18]发现非线性激活函数对性能的提升很少,因此他们去掉了非线性激活层,从而提高了效率甚至在性能上还得到了提升。
-
最终节点表示。是采用最后一层学习的结果最为节点的最终表示还是将各层学习的结果进行结合。最近的一些工作认为不同层的学习结果具有不同的信息通量,具体的,处在较低层的学习结果更能代表中心节点本身,而更高层的学习结果具有更多的邻居节点的信息。
-
总结:
-
