MongoDB入门到精通
一、MongoDB再入门
认识文档数据库MongoDB
MongoDB是一个以JSON为数据模型的文档数据库.
主要特点: 建模为可选,JSON数据模型比较适合开发者,横向扩展可以支撑很大数据量和并发.
版本变迁: 0.x起步阶段; 1.x支持复制集合分片集; 2.x更丰富的数据库功能; 3.xWireTiger和周边生态环境; 4.x分布式事务支持
MongoDB基本操作
查询:
find
db.col.find({"year":1975})
db.col.find({"year":1989,"title":"Bat"})
db.col.fiind({$or: [{"year":1987}, {"title":"bat"}]})
db.col.find({"title": /^Ba/})
|
a=1 |
{a:1} |
|
a<>1 |
{a: {$ne:1}} |
|
a>1 |
{a: {$gt:1}} |
|
a>=1 |
{a: {$gte:1}} |
|
a<1 |
{a:{$lt:1}} |
|
a<=1 |
{a:{$lte:1}} |
|
a=1 AND b=1 |
{a:1, b:1} |
|
a=1 OR b=1 |
{$or: [{a:1}, {b:1}]} |
|
a IS NULL |
{a: {$exist: false}} |
|
a IN {1, 2, 3} |
{a: {$in: [1, 2, ,3]}} |
|
a NOT IN {1,2,3} |
{a: {$nin: [1, 2, 3]}} |
查询子字段
db.col.find({"from.country": "China"})
搜索数组
db.col.find({color: "red"}) // 数据color字段是数组
搜索数组中的对象
db.col.find({"filming.city": "Rome"}) // 数据filming是对象数组,对象中有city字段
db.col.find({"filming": {$elemMatch: {"city":"Beijing"},{"country":"China"}}}) //$elemMatch表示子对象满足多个条件
控制返回字段
db.col.find({"cat":"ab"}, {"_id":0, "title": 1}) //返回字段title,不要_id
删除文档
remove
db.col.remove({}) //删除所有文档
更新文档
updateOne,始终只更新第一条
updateMany,匹配多少条就跟更新多少条
db.col.updateOne({name: 'apple'}, {$set: {from: "China"}}) //没有会新建字段
updateOne/updateMany方法要求更新条件部分必须具有以下之一,否则报错:
$set/$unset
$push/$pushAll/$pop
$pull/$pullAll
$addToSet
$set/$unset:增加/删除数据
$push: 增加一个对象到数组底部
$pushAll: 增加多个对象到数组底部
$pop: 从数组底部删除一个对象
$pull: 如果匹配指定的值,从数组中删除相应的对象
$pullAll: 如果匹配任意的值,从数据中删除相应的对象
$addToSet: 如果不存在则增加一个值到数组
聚合查询
MongoDB聚合框架(Aggregation FrameWork)是一个计算框架,聚合框架相当于SQL中的GROUP BY/LEFT OUTER JOIN/AS等
聚合运算基本格式:
pipeLine = [$stage1, $stage2, ... $stageN];
db.col.aggregate(
pipeLine,
{ options }
);
常见步骤:
|
步骤 |
作用 |
SQL等价运算符 |
|
$match |
过滤 |
WHERE |
|
$project |
投影 |
AS |
|
$sort |
排序 |
ORDER BY |
|
$group |
分组 |
GROUP BY |
|
$skip/$limit |
结果限制 |
SKIP/LIMIT |
|
$lookup |
左外连接 |
LEFT OUTER JOIN |
特有步骤:
|
步骤 |
作用 |
举例 |
|
$unwind |
展开数组 |
db.col.aggregate([{$unwind: '$score'}]) |
|
$bucket |
分桶统计 |
db.col.aggregate([ $bucket: { groupBy: "$price", boundaries: [0, 10, 20, 30], default: "Other", output: {"count": {$sum: 1}} } ]) db.col.aggregate([ $facet: { price: { $bucket: {...} }, year: { $bucket: {...} } } ]) |
MQL与SQL对比
|
SQL |
MQL |
|
SELECT first_name as `名`, last_name as `姓` FROM Users WHERE GENDER="男" SKIP 100 LIMIT 20 |
db.users.aggregate([ {$match: {gender: "男"}}, {$skip: 100}, {$limit: 20}, {$project: { '名': '$first_name', '姓': '$last_name' }} ]); |
|
SELECT DEPARTMENT, COUNT(NULL) as EMP_QTY FROM Users WHERE GENDER="女" GROUP BY DEPARTMENT HAVING COUNT(*) < 10 // 女性小于10人的部门 |
db.users.aggregate([ {$match: {gender: '女'}}, {$group: { _id: '$DEPARTMENT', //分组字段值 emp_qty: {$sum: 1} //字段求和,每次加1 }}, {$match: {emp_qty: {$lt: 10}}} //求和后数量 ]); |
使用示例:
- 求总销售额
db.orders.aggregate([
{
$group: {
_id: null,
total: {$sum: "$total"}
}
}
])
// 结果 {"_id": null, "total": NumberDecimal("4401968")}
- 查询1月1号到3月31号,已完成订单,总金额和数量
db.orders.aggregate([
// 匹配条件
{
$match: {status: 'completed', orderDate: {$gte: ISODate("2019-01-01"), $lt: ISODate("2019-04-01")}}
},
// 聚合订单总金额、总运费、总数量
{
$group: {
_id: null,
total: {$sum: "$total"},
shippingFee: {$sum: "$shippingFee"},
count: {$sum: 1}
}
},
{
$project: {
//计算总金额
grandTotal: {$add: ["$total", "$shippingFee"]},
count: 1, //显示
_id: 0 //不显示
}
}
])
// 结果: {"count:": 5875, "grandTotal": NumberDecimal("2642423.00")}
Compass中使用聚合查询
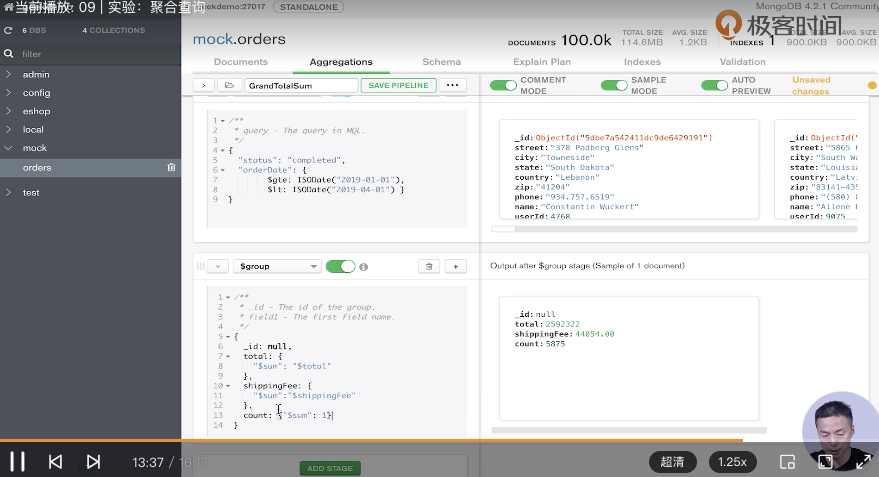
写完之后,可以点“...”,选择导出的语言,导出查询语句👍
复制集机制及原理
MongoDB复制集的主要意义在于实现服务高可用
它的实现依赖于两个功能:
数据写入时将数据迅速复制到另一个独立节点上
在接受写入的节点发生故障时自动选举出一个新的替代节点
复制集其他几个附件作用:
数据分发:将数据从一个区域复制到另一个区域,减少另一个地理区域的读延迟
读写分离:不同类型的压力分别在不同节点上执行
异地容灾:在数据中心故障时快速切换到异地
复制集结构
由3个及以上具有投票权到节点组成,包括:
一个主节点(PRIMARY): 接受写入操作和选举时投票
两个(或多个)从节点(SECONDARY):复制主节点上的新数据和选举投票
不推荐使用Arbiter(投票节点)
数据如何复制
当一个修改操作,无论是插入、更新或删除,到达主节点时,它对数据的操作将被记录下来,记录称为oplog;
从节点通过在主节点上打开一个tailable游标不断获取新进入主节点的oplog,并在自己的数据上回放,以此保持跟主节点的数据一致;
通过选举完成故障恢复
具有投票的节点之间俩俩互相发送心跳
当5次心跳未收到时判断为节点失联
如果失联的是主节点,从节点会发起选举,选出新节点;如果是从节点则不会产生新的选举
选举基于RAFT一致性算法,选举成功的必要条件是大多数投票节点存活
复制集最多可以由50个节点,但具有投票权的最多7个
搭建复制集
- 安装新版MongoDB,配置PATH变量,确保由10GB以上的硬盘空间
// centos7
// 官方文档 https://docs.mongodb.com/v4.2/tutorial/install-mongodb-on-red-hat-tarball/
sudo yum install libcurl openssl
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.18.tgz
tar -zxvf mongodb-linux-x86_64-rhel70-4.2.18.tgz
mv mongodb-linux-x86_64-rhel70-4.2.18 /usr/local/mongodb4
sudo cp /usr/local/mongodb4/bin/* /usr/local/bin/- 创建数据目录
$ mkdir -p /data/db{1,2,3}
- 准备配置文件
复制集的每个mongod进程应该位于不同的服务器,我们现在在一台机器上运行3个进程,因此要为它们各自配置:
不同的端口:28017/28018/28019
不同的数据目录:/data/db1,/data/db2,/data/db3
不同的日志文件路径:/data/db1/mongod.log,..
- 准备配置
https://cloud.tencent.com/developer/article/1195762
# /data/db1/mongod.conf:
systemLog:
destination: file
path: /data/db1/mongod.log
logAppend: true
storage:
dbPath: /data/db1
net:
port: 28017
processManagement:
fork: true
# /data/db2/mongod.conf:
systemLog:
destination: file
path: /data/db2/mongod.log
logAppend: true
storage:
dbPath: /data/db2
net:
port: 28018
processManagement:
fork: true
# /data/db3/mongod.conf:
systemLog:
destination: file
path: /data/db3/mongod.log
logAppend: true
storage:
dbPath: /data/db3
net:
port: 28019
processManagement:
fork: true
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/- 启动3个实例(此时彼此之间互不相干)
$ mongod -f /data/db1/mongod.conf
$ mongod -f /data/db2/mongod.conf
$ mongod -f /data/db3/mongod.conf
$ ps -ef | grep mongod- 配置复制集
$ mongo localhost:28017
> use admin
> db.createUser({user:"dba",pwd:"123456",roles:[{role:"root",db:"admin"},{role:"userAdminAnyDatabase",db:"admin"}]});
# 主从间的同步需要安全机制,所以需要先生成秘钥
openssl rand -base64 753 > /data/db1/keyfile
chmod 600 /data/db1/keyfile
# 拷贝yourKeyFile分别放到其他两台mongo服务器的数据存储路径下,也需要上面的600授权
# 每个配置文件加:
security:
authorization: enabled
keyFile: /data/db1/keyfile
replication:
replSetName: rs0
security:
authorization: enabled
keyFile: /data/db2/keyfile
replication:
replSetName: rs0
security:
authorization: enabled
keyFile: /data/db3/keyfile
replication:
replSetName: rs0
# 确认防火墙开放三个端口,重启各mongo, pkill mongod
# 重新连接后,由于开启了鉴权,所以需要认证
$ mongo localhost:28017
> use admin
> db.auth('dba','123456')
# 修改ip映射
vim /etc/hosts
127.0.0.1 mongodb0
127.0.0.1 mongodb1
127.0.0.1 mongodb2
# 输入配置
> rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "mongodb0:28017" },
{ _id: 1, host: "mongodb1:28018" }
]
})
> rs.status()
# 测试主从同步情况
$ mongo localhost:28017
> use admin
> db.auth('dba','123456')
use test
db.createUser({user:"testdba",pwd:"123456",roles:[{role:"dbOwner",db:"test"}]});
db.test.insert({id:1});
# 登录从库,查询是否有主库插入的数据
$ mongo localhost:28018
use test
db.auth('testdba','123456');
# 允许读
rs.slaveOk();
db.test.find();
# 配置仲裁角色
$ mongo localhost:28017
> use admin
> db.auth('dba','123456')
# 加入仲裁角色
rs.addArb("mongodb2:28019")
rs.status()- 验证
MongoDB主节点进行写入
$ mongo localhost:28017
db.test.insert({a:1})
db.test.insert({a:2}) // 可以两个窗口,看写两条从库是否有新增
MongoDB从节点进行读
$ mongo localhost:28018
rs.slaveOk()
db.test.find()
- 鉴权见后面“安全最佳实践”
- 连接
mongodb://dba:123456@10.200.2.18:28017,10.200.2.18:28018/test?authSource=admin&replicaSet=rs0&readPreference=primaryPreferredMongoDB全家桶
|
mongod |
MongoDB数据库软件 |
|
mongo |
MongoDB命令行工具 |
|
mongos |
MongoDB路由进程,分片环境下使用 |
|
mongodump/mongorestore |
命令行数据库备份与恢复工具 |
|
mongoexport/mongoimport |
CSV/JSON导入与导出,主要用于不同系统间数据迁移 |
|
Compass |
MongoDB GUI管理工具 |
|
Ops Manager(企业版) |
MongoDB集群管理软件,分片集群备份 |
|
BI Connector(企业版) |
SQL解释器/BI套接件 |
|
MongoDB Charts(企业版) |
MongoDB可视化软件 |
|
Atlas(付费及免费) |
MongoDB云托管服务,包括永久免费云数据库 |
mongodump/mongorestore数据备份和恢复
mongodump -h 127.0.0.1:27017 -d test -c test //-d数据库 -c集合
mongorestore -h 127.0.0.1:27017 -d test -c test xxx.bson
二、从熟练到精通的开发之路
数据模型
数据模型是一组符号、文本组成的集合,用以准确表达信息,达到有效交流、沟通的目的
数据模型三要素:
- 实体 Entity
描述任务的主要数据集合:谁,什么,何时何地,为何,如何 - 属性 Attribute
描述实体的单个信息 - 关系 Relationship
描述实体与实体之间的数据规则,结构规则:1-N,N-1,N-N
JSON文档模型设计
- JOSN文档模型设计特点
|
关系数据库 |
JSON文档模型 |
|
|
模型设计层次 |
概念模型 物理模型 |
概念模型 逻辑模型 |
|
模型实体 |
表 |
集合 |
|
模型属性 |
列 |
字段 |
|
模型关系 |
关联关系,主外键 |
内嵌数组,引用字段 |
- 引用方式下的关联查询:
Contacts表:
name: "TJ Tang"
company: "TAA"
group_ids: [1, 2, 3..]
Groups表:
group_id: 1
name: "Friends"
语句:
db.contacts.aggregate([
{
$lookup:
{
from "groups",
localField: "group_id",
foreignField: "group_id",
as: "groups"
}
}
])
// $lookup 只支持left outer join, 关联的目标(from)不能是分片表
- 什么时候该使用引用方式?
内嵌文档太大,数MB或超过16MB
内嵌文档或数组元素会频繁修改
内嵌数组元素会持续增长并且没有封顶
设计模式套用(经验总结)
分桶设计
例如,存储10万架飞机,1年内的飞行数据,1分钟存一条,可以 60Events等于1小时数据存一个文档,
{
_id: "",
events: [
{
a: "",
t: ""
},
{
a: "",
t: ""
}
...
]
}
|
场景 |
痛点 |
设计模式的方案及优点 |
|
时序数据: 物联网、智慧城市、智慧交通 |
数据点采集频繁,数据量太多 |
利用文档内嵌数组,将一个时间段的数据聚合到一个文档里。 大量减少文档数量和索引占用空间 |
列转行
问题:大文档,很多字段,很多索引
{
title: "Dunkirk",
release_China: "2017/6/01",
release_USA: "2017/07/23",
release_UK: "2017/08/01"
}
=>
{
title: "Dunkirk",
releases: [
{ country: "China", date: "2017/6/01" },
{ country: "USA", date: "2018/6/01" },
{ country: "UK", date: "2019/6/01" }
]
}
索引:db.col.createIndex({"releases.country": 1, "releases.date": 1}) // 一个组合索引
|
场景 |
痛点 |
设计模式方案及优点 |
|
产品属性'color'、'size'、... 多语言(多国家)属性 |
文档中很多类似的字段 会用于组合查询搜索,需要很多索引 |
转化为数组,一个索引解决所有查询问题 |
加版本字段
问题:模型既然灵活了,如何管理文档不同版本?文档经历了多个版本,都有哪些字段,都是什么类型并不统一
解决方案:添加一个版本字段 schema_version: "2.0", 根据版本做规则处理
|
场景 |
痛点 |
设计模式方案及优点 |
|
任何有版本衍变的数据库 |
文档模型格式多,无法知道其合理性 升级时候需要更新太多文档 |
增加一个版本字段 快速过滤掉不需要升级的文档 升级时对不同版本的文档做不同的处理 |
近似计算
问题:
统计网页点击流量,每访问一个页面都会产生一次数据库计数更新操作,统计数据准确性并不十分重要
解决方案:每隔10(x)次写一次
实现:
if random(0, 9) == 0
increment by 10
|
场景 |
痛点 |
设计模式方案及优点 |
|
网页计数 各种结果不需要准确的排名 |
写入太频繁,消耗系统资源 |
间隔写入,每隔10次或者100次 大量减少写入需求 |
预聚合字段
问题:
业绩排名,游戏排名,商品统计等精确统计,比如热销榜、电影排名等
传统解决方法:通过聚合计算,痛点:消耗资源多,聚合计算时间长
解决方案:用预聚合字段
db.col.update({_id: 123}, {
$inc: {
quantity: -1,
daily_sales: 1,
weekly_sales: 1,
monthly_sales: 1
}
})
统计时用vlookup直接计算预聚合字段
|
场景 |
痛点 |
设计模式方案及优点 |
|
准确排名 排行榜 |
统计计算耗时,计算时机长 |
模型中直接增加统计字段 每次更新数据时同时更新统计字段 |
事务开发
writeConcern
writeConcern决定一个写操作落到多少个节点上才算成功,发起写操作的程序将阻塞到写操作到达指定到节点数为止.
writeConcern的w取值包括:
- 0 : 发起写操作,不关心是否成功;
- 1 ~ 集群最大数据节点数:写操作需要被复制到指定节点数才算成功;
- majority: 写操作需要被复制到大多数节点才算成功,建议用此参数
- all: 需要被复制到所有节点(万一节点故障了写操作就完不成了,所以不要这么设置)
writeConcern的j取值包括:
true: 写操作落到journal文件中才算成功
false: 写操作到达内存即算成功
writeConcern实验:
db.test.insert({count:1}, {writeConcern: { w: "majority", wtimeout: 3000 }})
应对重要数据应用{w: "majority"},普通数据可以应用{w:1}以确保最佳性能(默认的)
readPreference
readPreference决定使用哪一个节点来满足正在发起的读请求,可选值:
- primary: 只选择主节点
- primaryPreferred: 优先选择主节点,如果不可用则选择从节点
- secondary: 只选择从节点
- secondaryPreferred: 优先选择从节点,如果从节点不可用则选择主节点
- nearest: 选择最近的节点
readPreference配置:
- 通过MongoDB的连接串参数:mongodb://host1:27017,host2:27018,host3:27019/?replicaSet=rs&readPreference=primaryPreferred, replicaSet表示复制集是rs
- 通过MongoDB驱动程序API:MongoCollection.withReadPreference(ReadPreference readPref)
- Mongo Shell: db.collection.find({}).readPref("secondary")
场景举例:
- 用户下订单后马上将用户转到订单详情页->primary/primaryPreferred,因为此时从节点可能还没有复制到新订单;
- 用户查询自己下过的订单->secondary/secondaryPreferred,查询历史订单对时效性通常没太高要求;
- 生成报表->secondary,报表对时效要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响;
- 将用户上传的图片分发到全世界,让各地用户能够就近读取->nearest,每个地区的应用选择最近的节点读取数据;
readConcern
在readPreference选择了指定节点后,readConcern决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别。可选值:
- available:读取所有可用的数据
- local:读取所有可用且属于当前分片的数据,默认是local
- majority: 读取在大多数节点上提交完成的数据
- linearizable: 读取大多数节点确认过的数据,可线性化读取文档
- snapshot: 读取最近快照中的数据
如何实现安全的读写分离:
考虑如下场景:向主节点写入一条数据,立即从从节点读取这条数据,如何保证自己能够读到刚刚写入的数据?
使用 writeConcern + readConcern majority来解决
db.orders.insert({oid: 010, sku: "kiteboar"}, {writeConcern: {w: "majority"}})
db.orders.find({oid: 010}).readPref("secondary").readConcern("majority")
多文档事务
ACID
|
事务属性 |
支持程度 |
|
Atomocity原子性 |
单表单文档: 1.x就支持 复制集多表多行:4.0 分片集群多表多行:4.2 |
|
Consistency一致性 |
writeConcern, readConcern, 3.2 |
|
Isolation隔离性 |
readConcern, 3.2 |
|
Durability持久性 |
Journal and Replication |
Change Stream
Change Stream是MongoDB用于实现变更追踪的解决方案,类似与关系数据库的触发器,但原理不完全相同:
|
Change Stream |
触发器 |
|
|
触发方式 |
异步 |
同步(事务保证) |
|
触发位置 |
应用回调事件 |
数据库触发器 |
|
触发次数 |
每个订阅事件的客户端 |
1次(触发器) |
|
故障恢复 |
从上次断点重新触发 |
事务回滚 |
是基于oplog实现的,最终调用应用中定义的回调函数。
要求mongod.conf里replication的enableMajorityReadConcern为true
var cs = db.col.watch([{
$match: {
operationType: {
$in: ['insert', 'delete']
}
}
}])
MongoDB开发最佳实践
关于连接到MongoDB
连接对象MongoClient实例应该保证它单例,并在整个生命周期中都从它获取其他操作对象
建议总是在连接字符串中配置连接选项
连接到复制集,建议写上所有节点 mongodb://节点1,节点2,节点3.../database?
连接到分片集,mongodb://mongos1,mongos2,mongos3.../database?
常见连接字符串参数:
maxPoolSize: 连接池大小
maxWaitTime: 建议设置,自动杀掉太慢查询
writeConcern: 建议majority保证数据安全
readConcern: 对于数据一致性要求高的场景适当使用
关于查询及索引
数据多时每一个查询都必须要有对应的索引,否则会导致全表扫描慢查询影响其他操作
尽量使用覆盖索引Covered Indexes(索引表中就有所需字段,避免读数据文件)
使用projection来减少返回到客户端的文档的内容
关于写入
在update语句里只包括需要更新的字段
尽可能使用批量插入来提升写入性能
使用TTL自动过期日志类型的数据
关于文档结构
防止使用太长的字段名
防止使用太深的数组嵌套
不使用中文、标点符合字段名
尽可能不要使用count(),因为需要遍历完所有数据找到符合条件的文档才能得到结果
避免使用skip/limit形式的分页,替代方案:使用查询条件+唯一排序条件,例如:
dp.posts.find({}).sort({_id:1}).limit(20)
dp.posts.find({_id:{$gt: 第一页最后一个_id}}).sort({_id:1}).limit(20)
使用事务原则:尽量避免使用,模型设计先于事务,不使用过大事务,涉及事务文档尽量分布在一个分片
三、分片集群与高级运维之道
分片集群机制及原理
- MongoDB常见部署架构
20% 单机版(开发与测试),Primary
70% 复制集(高可用),Primary+Secondary+Secondary
10% 分片集群(横向扩展) Shard1(Primary+Secondary+Secondary) + Shard2() + ...ShardN()
- 为什么使用分片集群?
数据容量日益增大,访问性能日渐降低
新品上线火爆,为支持更多的并发用户
单库已有10TB数据,恢复需要1-2天,如何加速
地理分布数据
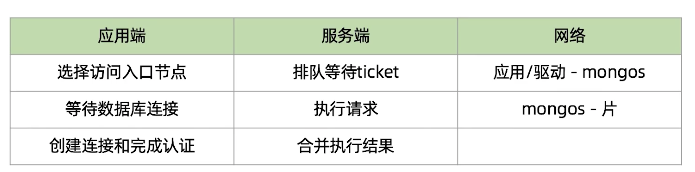
- 分片集群解剖:路由节点mongos
提供集群单一入口,转发应用端请求,选择合适数据节点进行读写,合并多个数据节点的返回
无状态,建议至少两个
- 分片集群解剖:配置节点mongod
提供集群元数据存储,分片数据分布的映射
- 分片集群解剖:数据节点mongod
以复制集为单位,横向扩展,最大1024分片,分片之间数据不重复,所有分片在一起才可完整工作
- 分片集群特点
应用全透明,无特殊处理;
数组自动均衡;
动态扩容,无须下线;
提供三种分片方式:
- 基于范围:片键范围查询性能好,优化读;数据分布可能不均匀,容易有热点
- 基于哈希:数据分布均匀,写优化,适用于日志、物联网等高并发;范围查询效率地
- 自定义Zone:分片打标签对应不用地域
- 分片大小
关于数据:数据量不超过3TB,尽可能保持在2TB一个片
关于索引:常用索引必须容纳进内存
MongoDB监控最佳实践
- 常用的监控工具及手段
MongoDB Ops Manager
Percona
Grafana等监控平台
- 如何获取监控数据
db.serverStatus():
connections: 关于连接数
locks: 使用锁的情况
network: 网络使用情况
opcounters: CRUD的执行次数统计
repl:复制集配置信息
wiredTiger: wirdTiger执行情况
mem:内存使用
metrics: 一些性能指标统计
db.isMaster()
mongostats命令行工具
备份与恢复
- 方案
方案一:延迟节点备份,延迟从节点当前状态+定量重复oplog
方案二:全量备份加oplog
全量备份: mongodump/复制数据库文件(暂时db.fsyncLock一个从节点处理)/文件系统快照(数据文件和Journal必须在同一个卷上)
- 实操
mongodump --host locahost:27017 --oplog
结果:当前目录下生成目录 dump/admin、test、oplog.bson,admin与test是俩数据库,oplog是dump进行过程中的oplog即增量数据
mongorestore --host localhost:27017 --oplogReplay
结果:会把oplog.bson也回放进去(mongo有幂等性,所有可以重复回放执行)
MongoDB安全最佳实践
安全架构
用户认证方式:用户名+密码;证书方式;等
MongoDB鉴权:
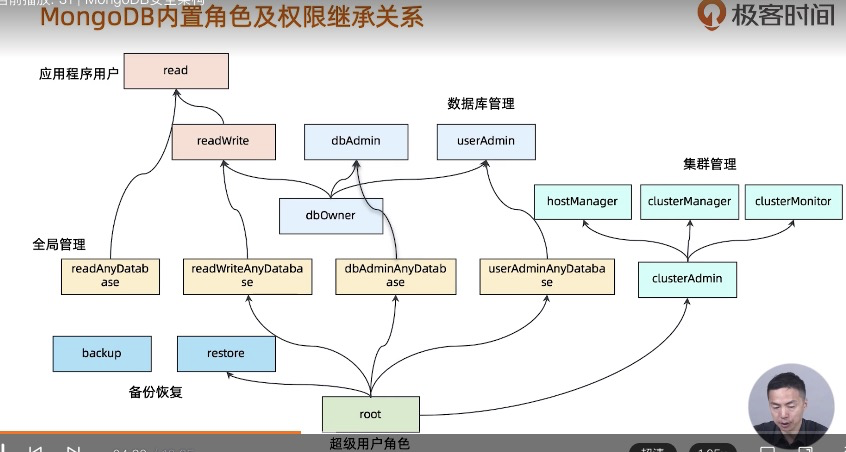
加密和审计
安全最佳实践


- 示例
启用认证:
命令行方式'--auth'参数或者配置文件在security下加"authorization: enabled"
mongod --auth --port 27017 --dbpath /data/db
创建超级用户:
启用鉴权后,可以无密码登录,但只能创建用户:
mongo
>use admin
>db.createUser({user:"superuser",pwd:"123456",roles:[{role:"root", db:"admin"}]})
然后安全登录,查看认证机制
mongo -u superuser -p 123456 --authenticationDatabase admin
use admin
db.runCommand({getParameter: 1, authenticationMechanisms: 1})
从数据库中查看用户
db.sysyem.users.find()
创建读写用户:
use admin
db.createUser({user:"writer", pwd:"abc123", roles:[{role: "readWrite", db:"test"}]})
创建只读用户:
use admin
db.createUser({user:"reader", pwd:"abc123", roles:[{role: "read", db:"test"}]})
MongoDB索引机制
- 术语:
Covered Query(查询覆盖):所需要的字段都在索引中,不再需要从数据页加载数据。
IXSCAN/COLLSCAN - 索引扫描/全表扫描(集合扫描)
Big O Notation - 时间复杂度,是线性增长、是指数、log增长等
Query Shape - 查询形状
Index Prefix - 索引前缀,可复用
Selectivity - 过滤性,把过滤掉数据多的优先键索引
B+树:基于B树,子节点数量可以超过2个(多叉树),数据(索引)存储在叶子节点 https://segmentfault.com/a/1190000020416577
B树工作过程复制,本质上是一个有序的数据结构,我们可以用数组来理解它。
假设索引为{a:1}: 数据增加/删除时始终保持索引字段有序-> [1] -> [1, 20] -> [1, 10, 20]
数组插入效率太低,但B树可以高效实现,在有序结构上实施二分查找,可时间O(log2(n))高效搜索
explain():
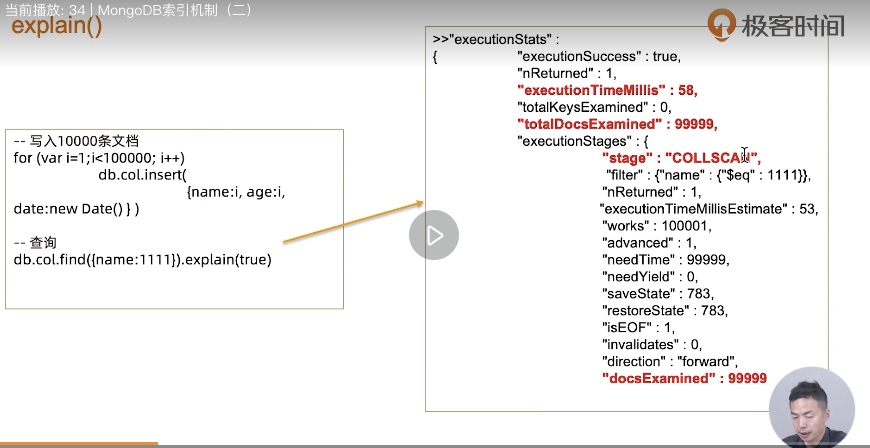
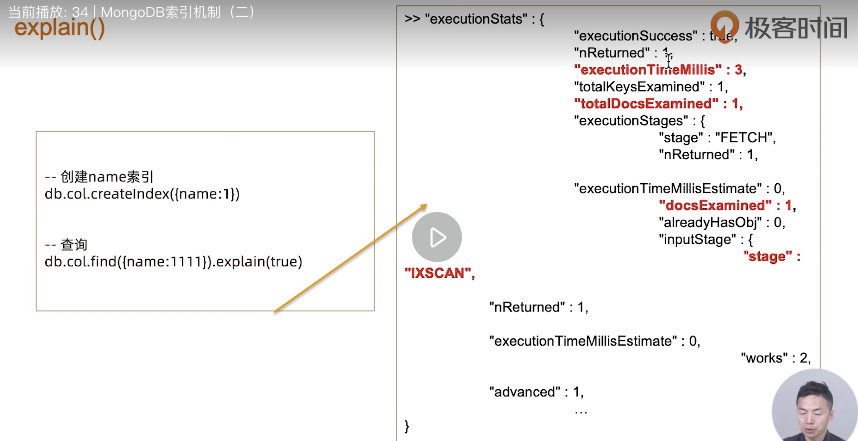
- 索引类型
单键索引
组合索引
多值索引(在数组里)
地理位置索引
全文索引
TTL索引
部分索引(满足条件的键索引,比如大于几)
哈希索引
- 组合索引
组合索引最佳方式: ESR原则(同样适用于ES、ER)
精确(Equal)匹配的字段放最前面
排序(Sort)条件放中间(不用最后在内存排序)
范围(Range)匹配的字段放最后面
db.members.find({ gender:"F", age: {$gte: 18} }).sort({"join_date": 1})
正确的索引:{gender: 1, join_date: 1, age: 1}
- 全文索引(小es)
比如创建索引db.col.createIndex({'content': "text"}),text类型的索引,
查询时会从所有text类型的索引中查,db.col.find({$text: {$search: "cup coffee like"}})
- 后台创建索引
db.col.createIndex({city: 1}, {background: true})
MongoDB读写性能诊断
- 性能瓶颈总结
- 性能诊断工具
- 默认安装的命令行工具:mongostat
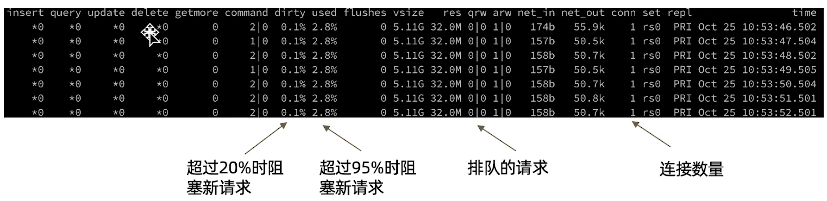
dirty: 数据更新了在缓存中了还没有刷盘,超过20%时阻塞新请求
used: 分配给mongodb的内存多少被使用,超过80%会开始自动清理,超过95%时阻塞新请求
qrw: 排队的请求
conn: 连接数量
- mongotop

- mongod日志
日志中会记录执行超过100ms的查询及其执行计划
- mtools
安装:pip install mtools
mplotqueries 日志文件:将所有慢查询通过图表呈现;
mloginfo --queries 日志文件:总结出所有慢查询模式和出现次数等
搭建两地三中心集群
略
MongoDB上线及升级
- 上线前:环境检查
tcp_keepalive_time调整为120秒,避免一些网络问题;
ulimit -n, 避免打开文件句柄不足;
关闭atime,提高数据文件访问效率;
禁用NUMA,否则在某些情况下会引发突发大量swap交换;
禁用Transparent Huge Page,否则会影响数据库效率;
- 上线后:性能监控、定期监控检查
- MongoDB版本发布规律:小版本可以直接升,大版本需要检查兼容性,不能直接3.2->4.2需要3.2->3.4->3.6->4.0->4.2,因为复制集只允许相邻版本共存
- 单机升级:停止->备份数据库目录->安装新版本Binaries->启动
- 复制集升级:滚动升级,参考单击升级步骤->升级从节点->主从切换->升级新从节点->切换FCV(db.adminCommand({setFeatureCompatibilityVersion: "4.2"}))
- 分片集群升级:禁用均衡器->升级config(参考升级复制集,不要切FCV)->升级分片(同上)->轮流升mongos->启用均衡器->切换FCV
四、企业架构师进阶执法
MongoDB应用场景和选型
- MongoDB数据库定位
OLTP数据库
原则上Oracle和Mysql能做的都能做
优点:横向扩展能力、灵活模型(适合迭代开发)、JSON数据结构(适合微服务/REST API)
场景:
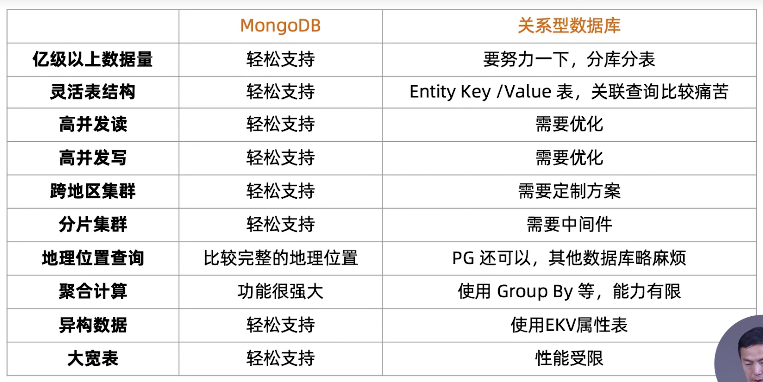








关系型数据库迁移
略
ORM:Object Relational Mapping 转换关系型到POJO对象模型
mongoDB不需要ORM,但是可以有ODM,Object Document Model,像mongoose,spring data
MongoDB+Spark实时大数据
- Spark
通用、快速,大规模数据处理引擎, 全内存计算、可横向扩展
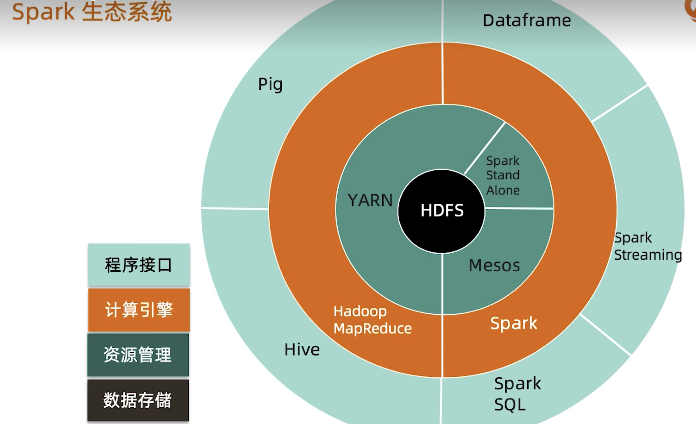
与MongoDB结合:替换HDFS
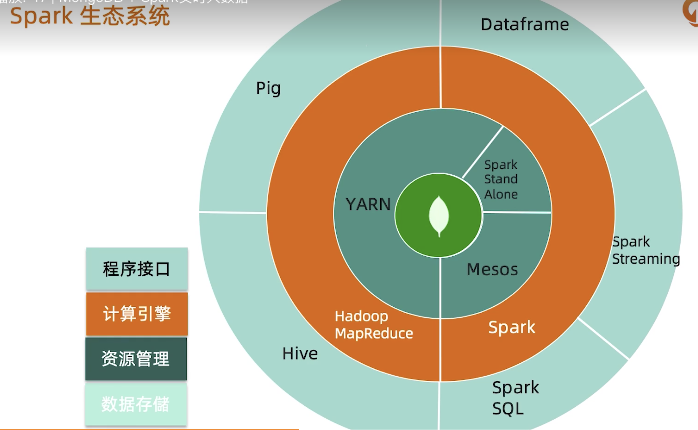
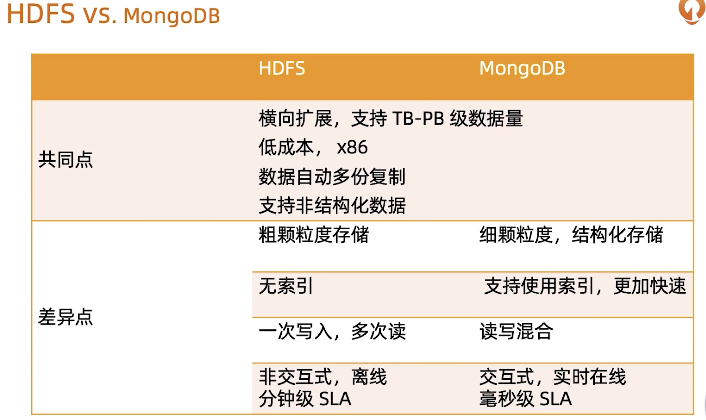
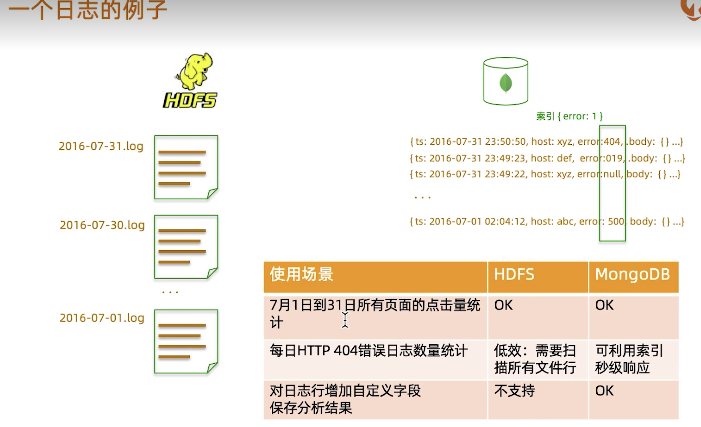
- Spark连接MongoDB
使用Mongodb的Spark Connector
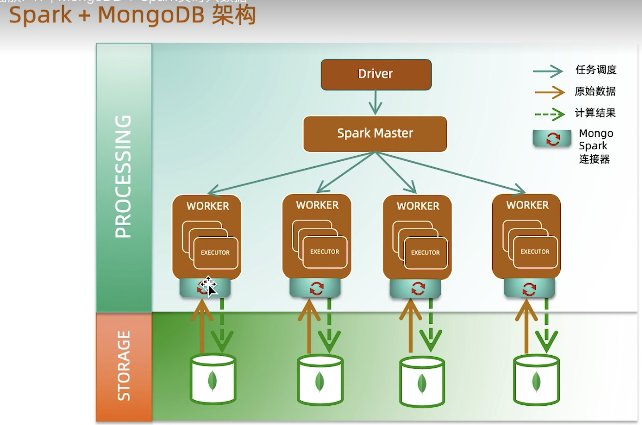
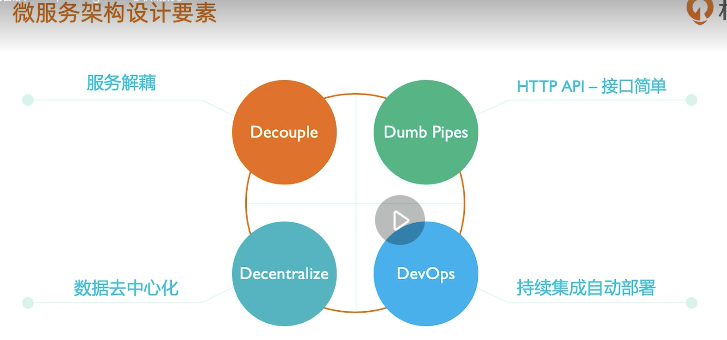
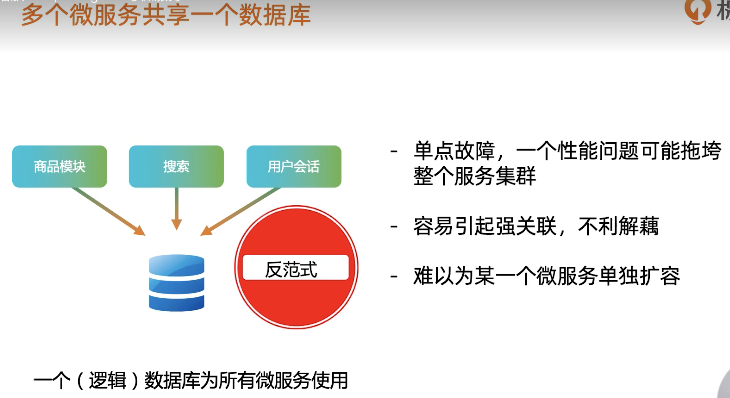
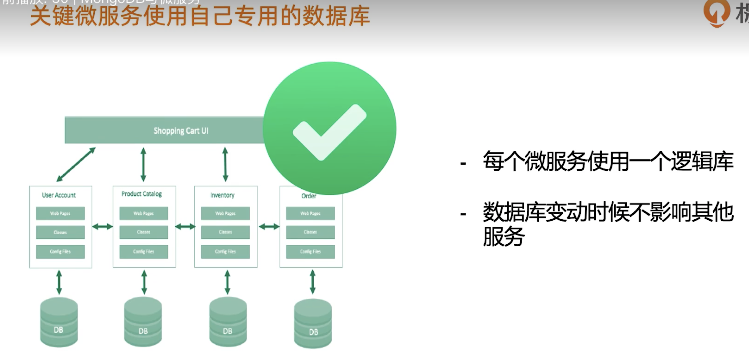
MongoDB与微服务
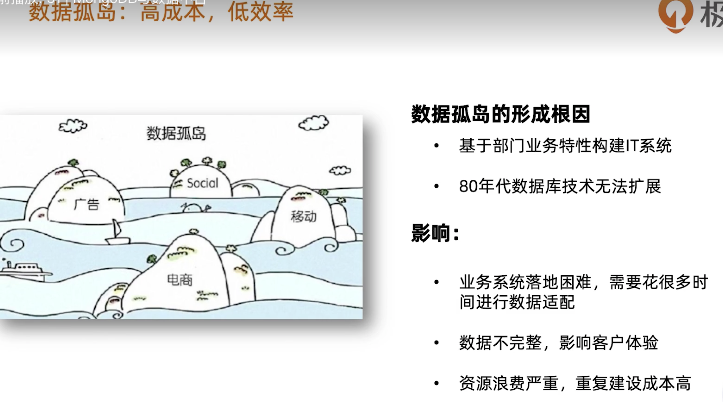
MongoDB与数据中台
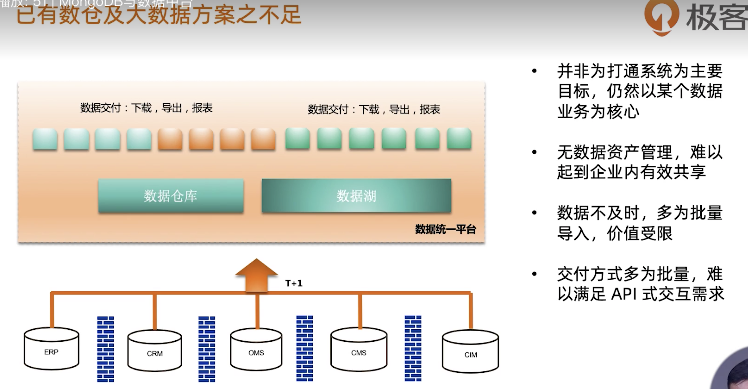
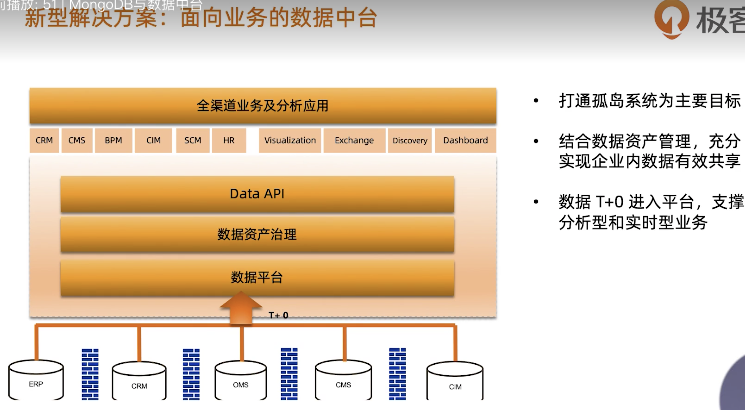
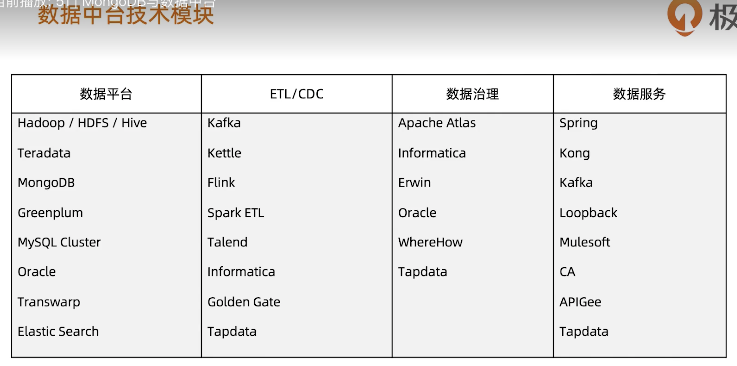


 浙公网安备 33010602011771号
浙公网安备 33010602011771号