
2023-01-16 经过 TypeScript 整理重写后,正式将监控系统的脚本开源,命名为 shin-monitor。
一、存储
在将数据传送到后台之前,已经做了一轮清洗工作,如果有需要还可以再做一次清洗。
日志表如下所示,自增的 id 直接偷懒使用了 bigint,没有采用分表等其他技术。
CREATE TABLE `web_monitor` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `project` varchar(45) COLLATE utf8mb4_bin NOT NULL COMMENT '项目名称', `project_subdir` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '项目的子目录,game项目下会有很多活动,放置在各个子目录中', `digit` int(11) NOT NULL DEFAULT '1' COMMENT '出现次数', `message` text COLLATE utf8mb4_bin NOT NULL COMMENT '聚合信息', `ua` varchar(600) COLLATE utf8mb4_bin NOT NULL COMMENT '代理信息', `key` varchar(45) COLLATE utf8mb4_bin NOT NULL COMMENT '去重用的标记', `category` varchar(45) COLLATE utf8mb4_bin NOT NULL COMMENT '日志类型', `source` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'SourceMap映射文件的地址', `ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP, `identity` varchar(30) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '身份,用于连贯日志上下文', `day` int(11) DEFAULT NULL COMMENT '格式化的天(冗余字段),用于排序,20210322', `hour` tinyint(2) DEFAULT NULL COMMENT '格式化的小时(冗余字段),用于分组,11', `minute` tinyint(2) DEFAULT NULL COMMENT '格式化的分钟(冗余字段),用于分组,20', `message_status` int(11) DEFAULT NULL COMMENT 'message中的通信状态码', `message_path` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'message通信中的 path', `message_type` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'message中的类别字段', `message_code` int(11) DEFAULT NULL COMMENT '提取接口响应中的code值', `referer` varchar(300) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '来源地址', `os_name` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '操作系统名称', `os_version` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '操作系统版本', `app_version` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '客户端版本', `ip` varchar(200) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'IP地址', `country` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '国家', `province` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '省份', `city` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '城市', `isp` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '网络运营商', `author` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '页面维护人员', `fingerprint` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '浏览器指纹,用于计算 UV', PRIMARY KEY (`id`), KEY `idx_key_category_project_identity` (`key`,`category`,`project`,`identity`), KEY `idx_category_project_identity` (`category`,`project`,`identity`), KEY `index_ctime` (`ctime`), KEY `idx_category_ctime` (`category`,`ctime`), KEY `idx_category_project_ctime` (`category`,`project`,`ctime`), KEY `idx_messagepath` (`message_path`), KEY `idx_category_messagetype_ctime` (`category`,`message_type`,`ctime`), KEY `idx_messagestatus_day_project_messagepath` (`message_status`,`day`,`project`,`message_path`), KEY `idx_identity` (`identity`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='前端监控日志'
2023-05-08 在表中增加 referer 字段。
2023-05-16 在表中增加 os_name、os_version、app_version 和 ip 四个字段,用于做错误日志的分析。
2023-06-07 在表中增加 country、province、city 和 isp 四个字段,存储 IP 解析后的信息,包括国家、省份、城市和网络运营商。
IP 解析可以选择付费服务,得到的结果比较准确,并且还能保持更新。或者选择开源的离线 IP 库,虽然精度不高,但是免费。
2023-06-20 在表中增加 author 字段,记录页面维护人员。
2023-07-10 在表中增加 fingerprint 字段,存储浏览器指纹。
2023-09-25 在表中增加 message_code 字段,提取接口响应中的code或status属性,用于分析接口的业务逻辑是否正常。
为了绘制用户的行为轨迹,对 identity 的增加了一个索引。
在正式上线后,遇到了几次慢查询,阿里云给出了相关索引建议,后面就直接加上了,效果立竿见影。
1)堆栈压缩
对于数据量很大的公司,像下面这样的堆栈内容消耗的存储空间是非常可观的,因此有必要做一次压缩。
例如将重复的内容提取出来,用简短的标识进行替代,把 URL 被替换成了 # 和数字组成的标识等。
{ "type": "runtime", "lineno": 1, "colno": 100, "desc": "Uncaught Error: Cannot find module \"./paramPathMap\" at http://localhost:8000/umi.js:248565:7", "stack": "Error: Cannot find module \"./paramPathMap\" at Object.<anonymous> (http://localhost:8000/umi.js:248565:7) at __webpack_require__ (http://localhost:8000/umi.js:679:30) at fn (http://localhost:8000/umi.js:89:20) at Object.<anonymous> (http://localhost:8000/umi.js:247749:77) at __webpack_require__ (http://localhost:8000/umi.js:679:30) at fn (http://localhost:8000/umi.js:89:20) at Object.<anonymous> (http://localhost:8000/umi.js:60008:18) at __webpack_require__ (http://localhost:8000/umi.js:679:30) at fn (http://localhost:8000/umi.js:89:20) at render (http://localhost:8000/umi.js:73018:200) at Object.<anonymous> (http://localhost:8000/umi.js:73021:1) at __webpack_require__ (http://localhost:8000/umi.js:679:30) at fn (http://localhost:8000/umi.js:89:20) at Object.<anonymous> (http://localhost:8000/umi.js:72970:18) at __webpack_require__ (http://localhost:8000/umi.js:679:30) at http://localhost:8000/umi.js:725:39 at http://localhost:8000/umi.js:728:10" }
考虑到我所在公司的数据量不会很大,人力资源也比较紧张,为了尽快上线,所以没有使用压缩,后期有时间了再来优化。
2)去除重复
虽然没有做压缩,但是对于相同的日志还是做了一次去重操作。
去重规则也很简单,就是将项目 token、日志类别和日志内容拼接成一段字符串,再用MD5加密,下面是 Node.js 代码。
2022-01-17 在去重规则中增加 identity,因为发现之前的去重规则可能会影响用户的行为轨迹,有些日志我需要单独记录。
const key = crypto.createHash("md5").update(identity + token + category + message).digest("hex");
将 key 作为条件判断数据库中是否存在这条记录,若存在就给 digit 字段加一。

在正式上线后,每秒会有几百几千次的请求发送过来。
每次在添加日志时还要做这层判断,就一度将数据库阻塞掉。因为每次在做 key 判断时要全表查询一次,旧的查询还没执行完,新的就来了。
为了解决此问题,就加上了一个基于 Redis 的队列:Kue,将判断、更新和插入的逻辑封装到一个任务中,异步执行。注意,目前此库已经不维护了,首页上推荐了替代品:Bull。
再加上索引,双重保障后,现在接收日志时未出现问题。
3)行为记录
2022-12-21 除了监控信息外,还会将错误发生时的行为记录保存起来,以便排查。
CREATE TABLE `web_monitor_record` ( `id` INT NOT NULL AUTO_INCREMENT, `monitor_id` BIGINT NOT NULL COMMENT '监控日志的ID', `record` MEDIUMTEXT NOT NULL COMMENT '回放信息,包括各类元素和DOM操作记录', `ctime` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE INDEX `monitor_id_UNIQUE` (`monitor_id` ASC)) DEFAULT CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin COMMENT = '直播监控回放';
record 字段使用的是 MEDIUMTEXT 类型,可存储 16M 的信息。
二、分析
目前的分析部分也比较简单,只包括一个监控看板、趋势分析、日志列表和定时任务等。
1)监控看板
在监控看板中包含今日数据和往期趋势折线图,本来想用 EChart.js 作图,不过后面集成时出了点问题,并且该库比较大,要500KB以上,于是换了另一个更小的库:Chart.js,只有60KB。
今日数据有今日和昨日的日志总数、错误总数和影响人数,通信、事件、打印和跳转等总数。

其中错误总数会按照 category:"error" 的 sum(digit) 来求和,而影响人数只会按照记录的个数来计算。
今日的数量是实时计算的,在使用中发现查询特别慢,要好几分钟才能得到结果,于是为几个判断条件中的字段加了个二级索引后(例如为 ctime 和 category 加索引),就能缩短到几秒钟响应。
ALTER TABLE `web_monitor` ADD INDEX `idx_category_ctime` (`category`, `ctime`); SELECT count(*) AS `count` FROM `web_monitor` WHERE (`ctime` >= '2021-03-25 16:00:00' AND `ctime` < '2021-03-26 16:00:00') AND `category` = 'ajax';
在往期趋势中,会展示错误、500、502 和 504 错误、日志总数折线图,这些数据会被保存在一张额外的统计表中,这样就不必每次实时计算了。折线的颜色值取自 AntDesign。
计算了一下出现 504 的通信占全部的 0.2%,接下来需要将这个比例再往下降。

在看板中,展示的错误日志每天在七八千左右,为了减少到几百甚至更低的范围,可采取的措施有:
- 过滤掉无意义的错误,例如SyntaxError: Unexpected token ',',该错误占了 55%~60% 左右。
- 优化页面和接口逻辑,504通信错误占了25%~30% 左右。
- 将这两个大头错误搞定,再针对性优化剩下的错误,就能将错误控制目标范围内。
从日志中可以查看到具体的接口路径,然后就能对其进行针对性的优化。
例如有一张活动页面,在进行一个操作时会请求两个接口,并且每个接口各自发送 3 次通信,这样会很容易发生 504 错误(每天大约有1500个这样的请求),因此需要改造该逻辑。
首先是给其中一张表加索引,然后是将两个接口合并成一个,并且每次返回 20 条以上的数据,这样就不用频繁的发起请求了。
经过改造后,每日的 504 请求从 1500 个左右降低到 200 个左右,减少了整整 7.5 倍,效果立竿见影,大部分的 504 集中在 22 点到 0 点之间,这段时间的活跃度比较高。
还有一个令人意外的发现,那就是监控日志的量每天也减少了 50W 条。
2021年9月,在监控看板中新增了504的接口统计查询,可以倒序看到每个504接口出现的次数,便于我们主动排查问题。
2022年3月,在监控看板中新增错误数量的统计查询,可以倒序看到每个错误出现的次数,也是为了便于我们主动排查问题而添加的。
2022年4月,在监控看板中留意到了打印总数,每天大约有17W条记录,而其中很大一部分都是遗留的调试数据,线上其实并不需要,所以很有必要剔除掉。
2)日志列表
在日志列表中会包含几个过滤条件:编号、关键字、日期范围、项目、日志类型和身份标识等。
如果输入了关键字,那么会在监控日志搜索结果列表中为其着色,这样更便于查看,用正则加字符串的 replace() 方法配合实现的。
在数据量上去后,当对内容(MYSQL 中的类型是 TEXT)进行模糊查询时,查询非常慢,用 EXPLAIN 分析SQL语句时,发现在做全表查询。
经过一番搜索后,发现了全文索引(match against 语法),在 5.7.6 之前的 MYSQL 不支持中文检索,好在大部分情况要搜索的内容都是英文字符。
SELECT * FROM `web_monitor` WHERE MATCH(message) AGAINST('+*test*' IN BOOLEAN MODE)
在建完这个索引后,表的容量增加了 3G 多,当前表中包含 1400W 条数据。
CREATE FULLTEXT INDEX ft_message ON web_monitor(message)
有时候还是需要模糊匹配的,所以想了下加个下拉选项,来手动命令后台使用哪种方式的查询,但如果是模糊匹配,必须选择日期来缩小查找范围。
其实后面在将数据导入 ElasticSearch 后,就可以非常快速的模糊查询了,也不需要特地选择检索方式或时间范围。

2022-11-16 新增日期选择快捷按钮,可快速填充今天、昨天和前天的时间范围。
2023-01-09 新增快捷按钮,当点击列表中的身份时,可以自动填充查询条件中的身份文本框,并且取消对类别的选择。
之前在分析奔溃原因时,就会手动将身份信息复制到文本框中,再手动取消类别,比较影响操作体验,所以才设计了这个快捷按钮。
2024-05-16 在条件中增加来源地址,因为接口日志的 message_path 字段保存的是接口地址中的路径,而不是来源地址的路径。
所以当知道来源地址,想要查询相关接口,就可以使用此条件。

2023-09-19 在查询按钮附近,增加受影响的人数,但只有当查询错误记录时,才会做分析。
2023-10-30 在日志列表的详情弹框中增加一栏:受影响的用户列表,其中第一列是指纹,第二列是数量,便于找出当前最受影响的用户。
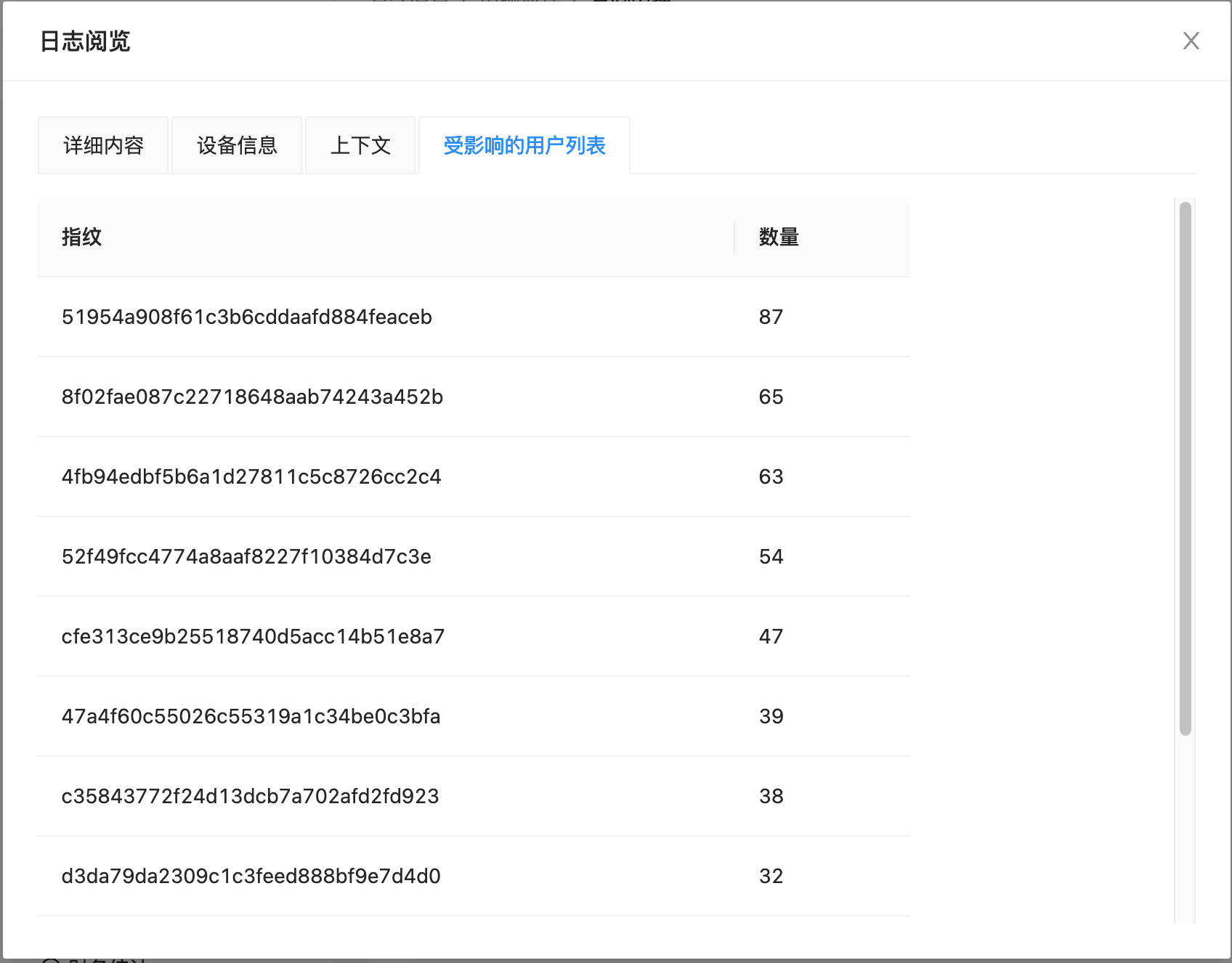
在实际使用时,又发现缺张能直观展示峰值的图表,例如我想知道在哪个时间段某个特定错误的数量最多,于是又加了个按钮和柱状图,支持跨天计算。

2022-12-06 在阅读了相关数据分析的书籍后,了解到对于上面描述分布情况,更适合用直方图(各个柱子之间没有空隙)展示。
身份标识可以查询到某个用户的一系列操作,更容易锁定错误发生时的情境。
每次查询列表时,在后台就会通过Source Map文件映射位置,注意,必须得有列号才能还原,并且需要安装 source-map 库。
const sourceMap = require("source-map");
/**
* 读取指定的Source-Map文件
*/
function readSourceMap(filePath) {
let parsedData = null;
try {
parsedData = fs.readFileSync(filePath, "utf8");
parsedData = JSON.parse(parsedData);
} catch (e) {
logger.info(`sourceMap:error`);
}
return parsedData;
}
/**
* 处理映射逻辑
*/
async function getSourceMap(row) {
// 拼接映射文件的地址
const filePath = path.resolve(
__dirname,
config.get("sourceMapPath"),
process.env.NODE_ENV + "-" + row.project + "/" + row.source
);
let { message } = row;
message = JSON.parse(message);
// 不存在行号或列号
if (!message.lineno || !message.colno) {
return row;
}
// 打包后的sourceMap文件
const rawSourceMap = readSourceMap(filePath);
if (!rawSourceMap) {
return row;
}
const errorPos = {
line: message.lineno,
column: message.colno
};
// 过传入打包后的代码位置来查询源代码的位置
const consumer = await new sourceMap.SourceMapConsumer(rawSourceMap);
// 获取出错代码在哪一个源文件及其对应位置
const originalPosition = consumer.originalPositionFor({
line: errorPos.line,
column: errorPos.column
});
// 根据源文件名寻找对应源文件
const sourceIndex = consumer.sources.findIndex(
(item) => item === originalPosition.source
);
const sourceCode = consumer.sourcesContent[sourceIndex];
if (sourceCode) {
row.sourceInfo = {
code: sourceCode,
lineno: originalPosition.line,
path: originalPosition.source
};
}
// 销毁,否则会报内存访问超出范围
consumer.destroy();
return row;
}
点击详情,就能在弹框中查看到代码具体位置了,编码着色采用了 highlight.js。
而每行代码的行号使用了一个扩展的 highlight-line-numbers.js,柔和的淡红色的色值是 #FFECEC。

图中还有个上下文的 tab,这是一个很有用的功能,可以查询到当前这条记录前面和后面的所有日志。
本以为万事大吉,但是没想到在检索时用模糊查询,直接将数据库跑挂了。
无奈,从服务器上将日志数据拉下来,导入本地数据库中,在本地做查询优化,2000W条数据倒了整整两个小时。
和数据组的同事沟通后,他们说可以引入 ElasticSearch 做检索功能。当他们看到我的 message 字段中的内容时,他们建议我先做关键字优化。
就是将我比较关心的内容放到单独的字段中,提升命中率,而将一些可变的或不重要的数据再放到另一个字段中,单纯的做存储。
例如通信内容中,我比较关心的是 url 和 status,那么就将它们抽取出来,并且去除无关紧要的信息(例如错误的 stack、通信的 headers)给 message 字段瘦身,最多的能减少三分之二以上。
{ "type": "GET", "url": "/api/monitor/list?category=error&category=script&msg=", "status": 200, "endBytes": "0.15KB", "interval": "22.07ms", "network": { "bandwidth": 0, "type": "3G" }, }
最后决定报表统计的逻辑仍然用 MySQL,而检索改成 ElasticSearch,由大数据组的同事提供接口,我们这边传数据给他们。
而之前的检索方式也可以弃用了,MySQL中存储的日志数据也从 14 天减少到 7 天。
在使用过程中遇到了几个问题:
- 没有将所有的数据传递到ES库中,丢失了将近33%的数据,后面排查发现有些数据传递到了预发环境,而预发环境中有个参数没配置导致无法推送。
- 在检索时,返回的列表会漏几条记录,在一个可视化操作界面中输入查询条件可以得到连续的数据。经过排查发现,可能是在后台查询时,由于异步队列的原因,那几条数据还未推送,这样的话就会得不到那几条记录,导致不连续。
通过日志列表中的通信和点击事件,可以计算出业务方日常工作的耗时,这个值可以作为指标,来验证对业务优化后,前后的对比,这样的量化能让大家知道自己工作给业务方带来了多少提升。
3)定时任务
每天的凌晨4点,统计昨天的日志信息,保存到 web_monitor_statis 表中。
CREATE TABLE `web_monitor_statis` ( `id` int(11) NOT NULL AUTO_INCREMENT, `date` int(11) NOT NULL COMMENT '日期,格式为20210318,一天只存一条记录', `statis` text COLLATE utf8mb4_bin NOT NULL COMMENT '以JSON格式保存的统计信息', PRIMARY KEY (`id`), UNIQUE KEY `date_UNIQUE` (`date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='前端监控日志统计信息表';
在 statis 字段中,保存的是一段JSON数据,类似于下面这样,key 值是项目的 token。
{ "backend-app": {
allCount: 0, errorCount: 1, errorSum: 1, error500Count: 0, error502Count: 0, error504Count: 1, ajaxCount: 20, consoleCount: 0, eventCount: 0, redirectCount: 0 } }
还有个定时任务会在每天的凌晨3点,将一周前的数据清除(web_monitor 和 web_monitor_record),并将三周前的 map 文件删除。
之所以有个时间差是为了避免一周内的数据中还有需要引用两周前的 map 文件,当然这个时间差还可以更久。
注意,MySQL中表的数据通过 delete 命令删除,如果使用的是 InnoDB 存储引擎,那么是不会释放磁盘空间的,需要执行 optimize 语句,例如:
optimize table `web_monitor`
原先每日的数据量在180W左右,每条数据在 800B 左右,每天占用空间 1.3G 左右。
后面优化了请求量,过滤掉重复和无意义的请求后(例如后台每次都要发的身份验证的请求、活动页面的埋点请求等),每天的日志量控制在 100W 左右。
而在经过上述活动的504优化后,请求量降到了 50W 左右,优化效果很喜人。
保存 map 文件的空间在100G,应该是妥妥够的。
在未来会将监控拓展到小程序,并且会加上告警机制,在合适的时候用邮件、飞书、微信或短信等方式通知相关人员,后面还有很多扩展可做。
叙述的比较简单,但过程还说蛮艰辛的,修修补补,加起来的代码大概有4、5千行的样子。
2023-09-07 完善每天的指标通知,根据 Nginx 访问日志和性能日志计算得到,这块的内容不是通过前端日志而来的,但是对于日常的监控却也很重要。
原先的飞书通知只会包含总的 SLA(5XX 请求的占比) 和慢响应,以及白屏和首屏占比。
Web核心指标 20230825 SLA: 99.99936% SLA数量: 12 慢响应数量: 1394 慢响应比率: 12.36095‰ 白屏1秒内比率: 90.18% 首屏1秒内比率: 72.81%
每次要看细节还得打开看板后台,在手机都不好操作,还得开启电脑。
于是做了一轮优化,将 SLA 分为对内的后台,对外的国内业务和海外业务,慢响应增加国内和海外的业务数量占比。
白屏也区分了国内和海外,因为公司对海外用户的体验也比较重视。经过优化后,就能了解每天的趋势,只有在必要时,才去打开后台查看指标细节。
Web核心指标 20231031 整体SLA: 99.99953% 整体SLA数量: 7 整体后台SLA: 99.99804% 整体后台SLA数量: 3 整体业务SLA: 99.99967% 整体业务SLA数量: 4 海外SLA: 100.00000% 海外SLA数量: 0 整体慢响应数量: 1567 整体慢响应比率: 18.43965‰ 整体业务慢响应比率: 1.59287‰ 海外慢响应比率: 2.86041‰ 白屏1秒内比率: 90.95% 首屏1秒内比率: 78.87% 白屏时间>2秒数量: 1950 海外白屏时间>2秒数量: 412
4)服务迁移
在使用时发现监控日志的服务比较占用CPU和内存,于是将其单独抽取做来,独立部署。
经过这波操作后,整体的504错误,从 800 多渐渐降到了 100 左右。其中有一半的请求是埋点通信,业务请求降到了有史以来的最低点。
但CPU和内存并没有按预期下降,这部分涉及到了一次详细的内存泄漏的摸查过程,在下文会详细分析。
5)飞书告警
首先需要注册飞书开放平台,并创建应用。
然后在开放平台找到凭证,记录 app_id 和 app_secret。

接着在应用功能中,启用机器人,由机器人来发送告警。

再获取 tenant_access_token(需要 app_id 和 app_secret),最后通过另一个接口发送消息。
2023-07-12 增加告警的定时任务,第一期先只监控运行时、图像和白屏三类错误。
在分析过往发生事故的日志后,得出每半小时,在一个页面中有上述一类的错误数量超过 10 个就发送告警。
ctime 配置开始和结束时间,message_type 声明错误类型,message_path 是页面路径。
SELECT `message`, `message_path`, `author`, count(*) AS `count` FROM `web_monitor` WHERE (`ctime` >= '2023-07-12 06:00:00' AND `ctime` <= '2023-07-12 06:30:00') AND `category` = 'error' AND `message_type` = 'runtime' GROUP BY `message_path` HAVING `count` >= 10
2023-09-08 在开启告警后,发现很多都是 image 类型的告警,但打开图像地址,又都能正常,很多时候与网络和代理有关,导致无法访问图像。
所以我们的告警会收到大量的“误报”(误报率在 46% 左右),虽然的确是发生了错误,但这些告警对于我们监控页面的健康趋势,价值并不大。
有时候还会干扰我们的判断,因为有些图像地址看着是正常的,但实际上是无法访问的。
对图像的告警规则做了一次优化,借助 Node.js 自带的 https 库,访问图像的地址,包一层 Promise,方便使用 async/await 语法。
/** * 读取图像请求状态码,判断图像是否存在 */ async requestImg(src) { return new Promise((resolve) => { https.get(src, (response) => { resolve(response.statusCode); }); }); }
而对于 HTTP 的图像请求,以及 webp 的图像错误都会放行,不会过滤掉,这类会判断为异常。
const filterList = []; for (const item of list) { const message = JSON.parse(item.message); const src = message.desc.src; // 对于http请求、webp图像、html地址,直接作为错误处理 if (src.indexOf("https:") === -1 || src.indexOf(".webp") >= 0 || src.indexOf('.html') >=0 ) { filterList.push(item); continue; } const code = await this.requestImg(src); // 过滤掉正常的图像请求 if (code === 200) continue; filterList.push(item); } list = filterList;
截止 2025 年 10 月,iOS 系统已经发布了更新的版本(如18、26),再加之国内用户通常有较快的系统升级习惯。因此,iOS 14 在当前的市场份额已经非常低,于是就去掉了 webp 的错误放行。
三、错误分析
2023-05-19 在调研了市面上的几款监控系统的功能后,决定在已有的页面中对错误展开进一步的分析。
新增的三个功能,都采用抽屉式的交互,从屏幕右侧边缘滑出浮层面板。
1)行为轨迹
这是一个成熟的监控系统必备的功能,了解用户的行为轨迹,可以为解决问题提供众多的线索。
在数据库表中有一个 identity 字段,作为用户的唯一标识,将其作为查询条件,就能得到一组日志。
SELECT * FROM `web_monitor` WHERE `identity` = 'xxxx'
将得到的日志,根据类型进行不同的渲染,并且提供不同颜色的 icon 便于识别,如下图所示。

时间轴被分为两部分,左边有时间、日志子类型和日志 ID,右边是日志的关键信息。
起初并没有做分页,因为考虑到 H5 页面以活动为主,所以日志不会很多。
但是后面发现在管理后台中,一个用户会存在巨量的日志,因此在渲染时,直接将页面搞奔溃了,无响应。
为此,马上设计了分页查询,默认是一页 50 条。
2)错误趋势
选取了常用的三类错误,运行时、图像和奔溃,主要是对本周和上周的数据对比,如下图所示。
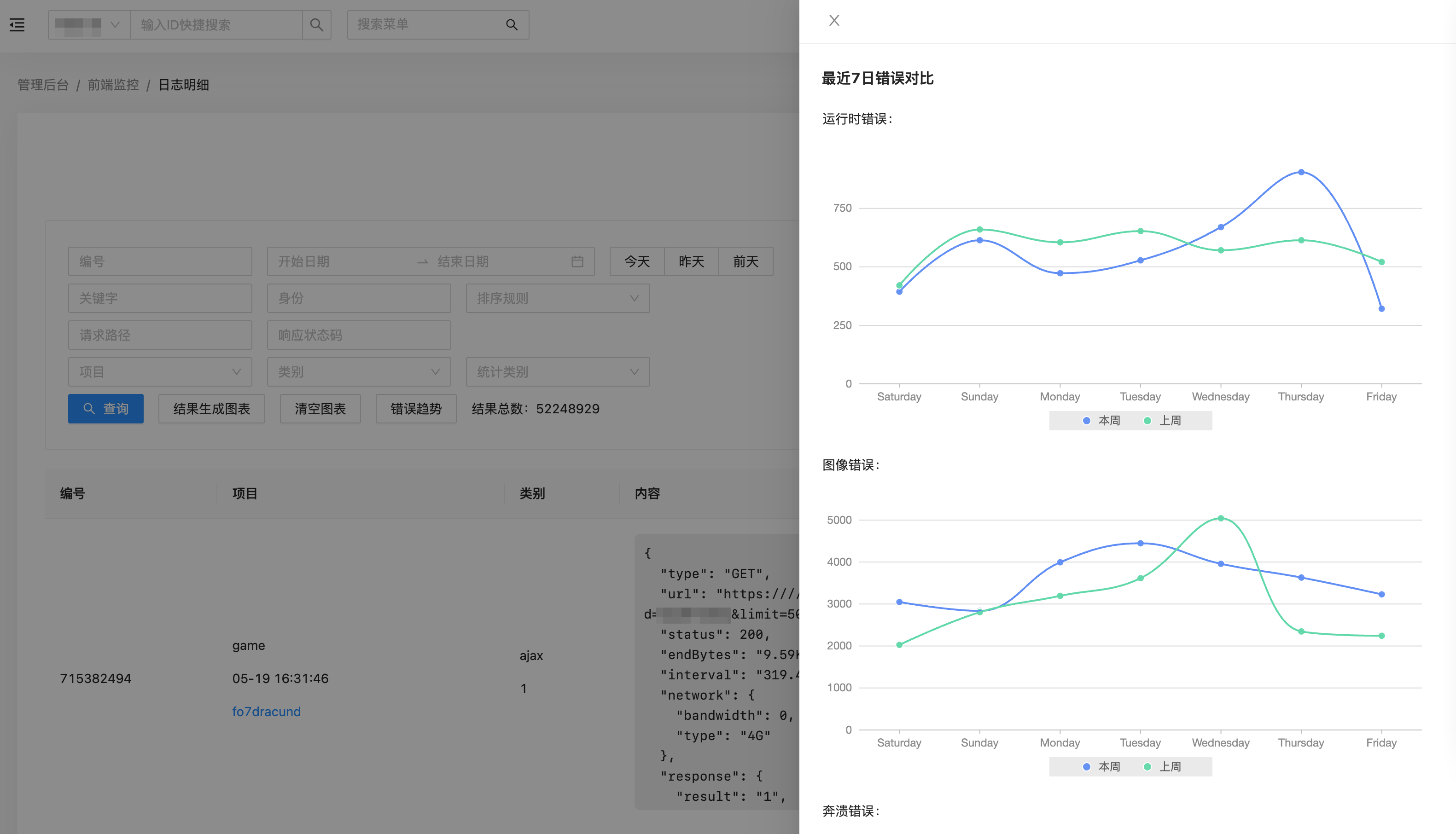
观察两条曲线,可以更直观的判断优化前后是否有效,Sunday、Tuesday 这些单词都是直接通过日期库计算得出的。
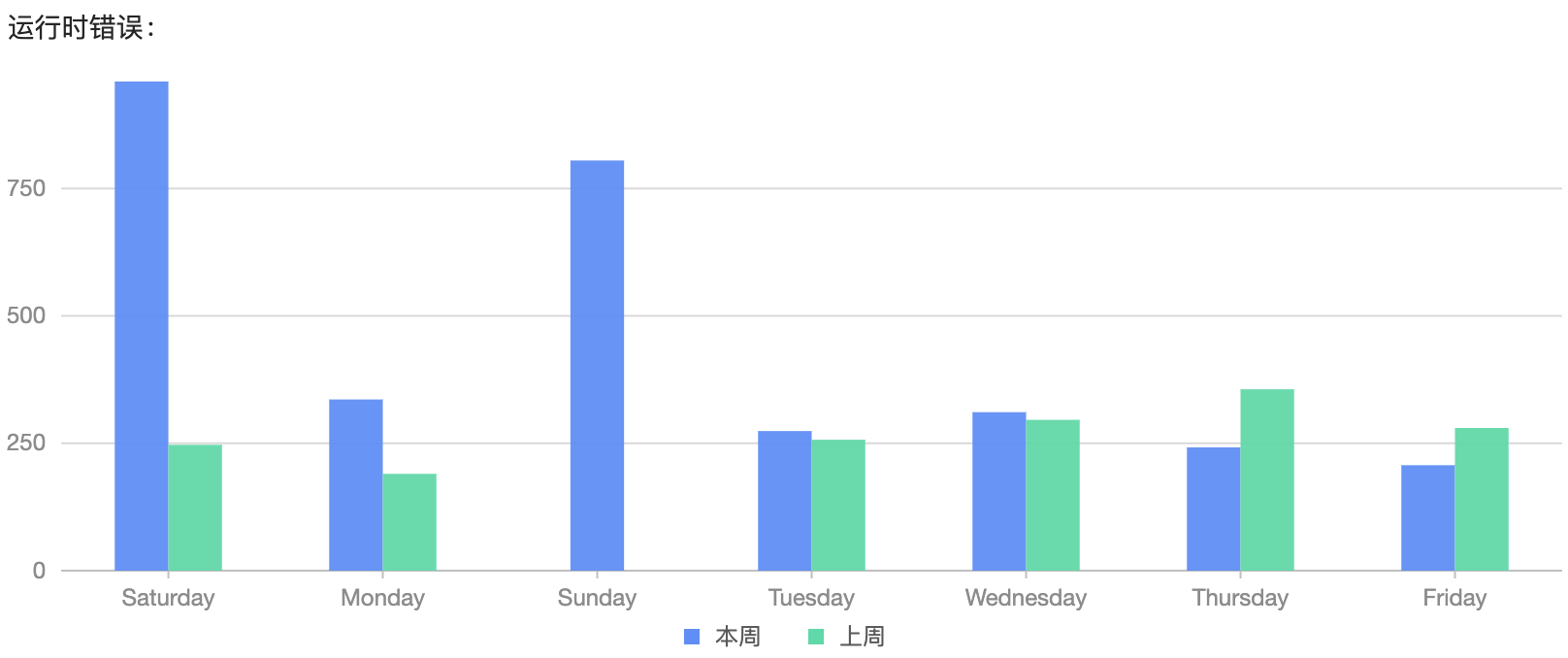
2023-07-14 将两条曲线转换成分组柱状图,可以更清晰的对两周的错误进行差异对比。
2023-06-20 增加各类错误的趋势图,因为图像类错误比较多,所以为了避免影响其它错误的曲线,没有将其统计进来。
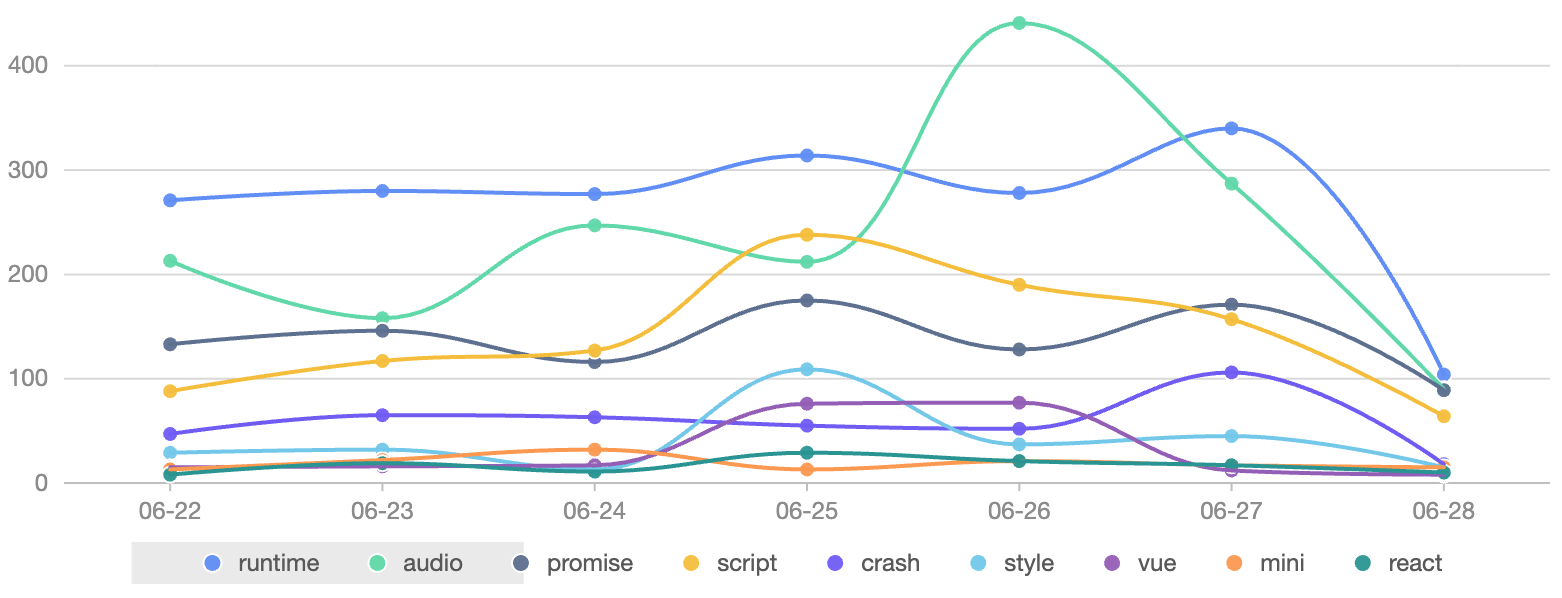
2023-07-14 将各类错误的趋势图改成了分组柱状图,相比曲线图,更容易观察变化。

2023-06-28 增加各种类型的排行榜,可更方便的获悉哪些页面的这类错误比较多,明确优化对象后,就能优先尽快解决。

对通信也做了一个榜单,便于对请求做优化,例如删除一个请求、多个请求合并成一个等。
以及根据身份也做了一个错误榜单,分析哪些用户遇到的错误比较多,其实也是在缩小范围,更准确的进行优化。
3)错误详情
在错误详情中,包含基本的信息,有 IP、浏览器、操作系统等信息,以及错误的相关信息,包括最近出现、首次出现、Android、iOS 等错误数量,如下所示。

注意,这些数量的统计范围是 2 个月,因为我这边只保留 2 个月的日志,这些日志存储在 ElasticSearch 中。
下面是一条查询 Android 系统相同错误数量的 SQL 语句,我在 MySQL 只保留了 7 天的数据,总数据量在 5000 多万条 。
SELECT COUNT(*) FROM `web_monitor` WHERE `message` LIKE "%Uncaught TypeError: Cannot read property 'id' of null at https://www.xxx.me/game/js/operation54.773abd8e.js:1:69175%" and `category` = 'error' and `message_type` = 'runtime' and `os_name` = 'Android' and `message_path` = 'game/operation54.html';
虽然使用了模糊查询,但是因为错误日志的数据量不大,并且加足了过滤条件,所以查询速度并不慢。
另一个分析手段是错误覆盖,包括操作系统和客户端版本的覆盖,用饼图的方式展现,如下图所示。
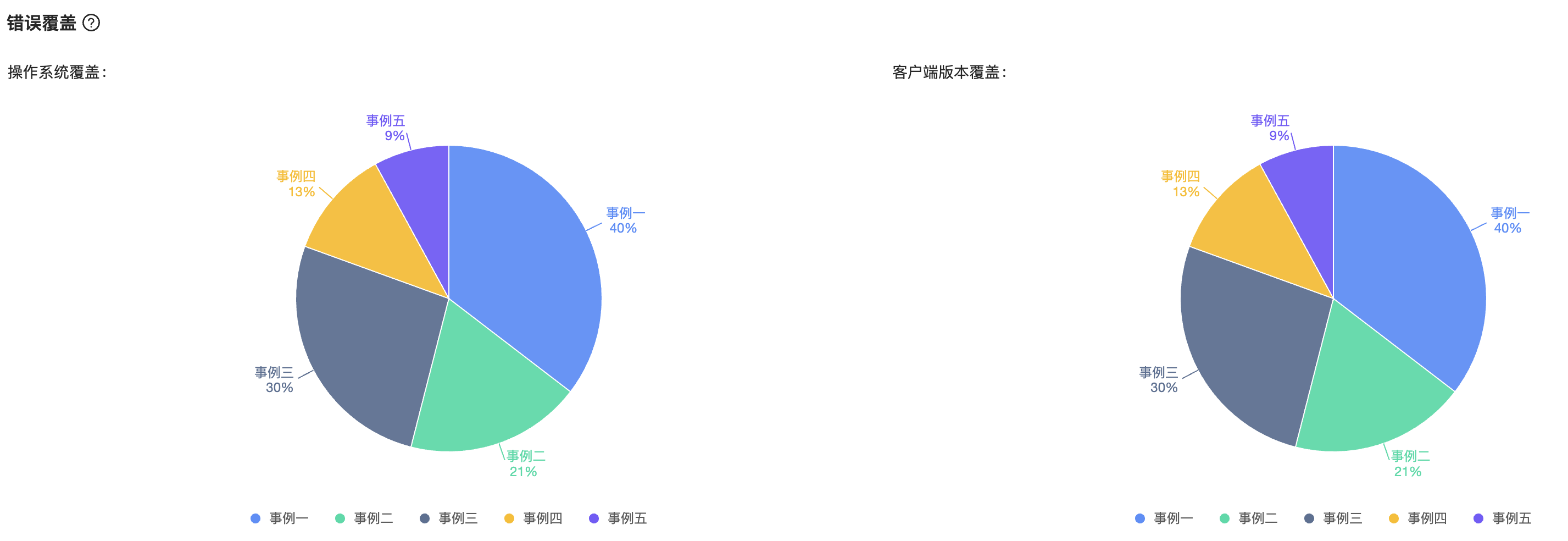
依据表中的 os_name、os_version、app_version 三个字段可以计算出操作系统和客户端版本的数量。
最后还会用柱状图呈现最近 7 天和最近 30 天的错误发生的趋势,如下图所示。

关于错误,有的系统可以将其作为一个任务分配给某个人,然后在解决后更新错误状态。
2024-03-28 在错误详情中增加错误区域,在各个省市自治区中标注错误数量,显示分布情况,颜色越深,错误越多。

先下载中国地图坐标的 JSON 数据,并修改成模块化语法,存储到 geoJson.js 文件中,如下所示。
export default { type: 'FeatureCollection', features: [{ type: 'Feature', properties: { adcode: 110000, name: '北京', center: [116.405285, 39.904989], centroid: [116.41995, 40.18994], childrenNum: 16, level: 'province', parent: { adcode: 100000 }, subFeatureIndex: 0, acroutes: [100000], }, ... }] }
省市自治区的名称可做修改,例如北京市改成北京,然后基于 ECharts 5.X 版本生成地图。
下面是简化的初始化代码,option 变量以及其它配置内容都比较多,直接省略了,可参考此处。
import * as echarts from 'echarts'; // 导入地图数据 import geoJson from '../data/geoJson.js'; const mapName = 'china'; // 注册可用地图 echarts.registerMap(mapName, { geoJSON: geoJson }); // 初始化 const myCharts = echarts.init(document.getElementById('map'), null, { renderer: 'svg' }); myCharts.setOption(option);
4)维护人员
在后台中已经搜集到了线上的各类错误,但是组内的成员并不会定期去查看各自维护的页面错误情况。
思考了一段时间后,想到记录各个页面的维护人员,将他们的名字保存到日志中。
然后根据人员统计成错误折线图或错误排行榜,这样就可以用图表的方式督促维护人员尽快修复现有问题,并且还能观察错误趋势。

再就是将各个人员的错误数每天定时推送到飞书或钉钉上,每天提醒一下大家有空就去优化和修复问题。
2023-06-20 发现折线图并不能很好的对比错误趋势,于是改成了分组柱状图。
每种颜色代表某一名维护人员,谁的错误上升异常,可以非常明显的观察到。

2023-10-17 增加各维护人员的页面错误数量榜单,就是让维护人员可以看到错误数量比较多的页面。
对这些页面做重点优化,以及排查数量比较多的原因,进行针对性的修复。

2024-05-15 发现当团队成员离职时,原先的维护人员配置就需要修改,而当前是写在各个页面中,改动比较繁琐。
未来推荐将维护人员与页面地址的映射关系保存到服务端的接口中,若有人离职,只需要在此处做改动即可。
参考:
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号