字符串匹配——朴素算法、KMP算法
字符串匹配(string match)是在实际工程中经常会碰到的问题,通常其输入是原字符串(String)和子串(又称模式,Pattern)组成,输出为子串在原字符串中的首次出现的位置。通常精确的字符串搜索算法包括朴素搜索算法,KMP, BM(Boyer Moore), sunday, robin-karp 以及 bitap。下面分析朴素搜索算法和KMP这两种方法并给出其实现。假设原字符T串长度N,子串P长度为M。
1.NAIVE—STRING—MATCHING.
朴素算法,该方法又称暴力搜索,也是最容易想到的方法。
预处理时间 O(0)
匹配时间复杂度O(N*M)
主要过程:从原字符串开始搜索,若出现不能匹配,则从原搜索位置+1继续。
代码如下:
-
void NAIVE_STRING_MATCHING(string T,string P) -
{ -
int n=T.size(); -
int m=P.size(); -
int i; -
for (int s=0;s<n-m;s++) -
{ -
for (i=0;i<m;i++) -
{ -
if (P[i]!=T[s+i]) -
{ -
break; -
} -
} -
if (i==m) -
{ -
cout<<"pattern occurs with shift "<<s<<endl; -
} -
} -
}
2.Knuth—Morris—Pratt算法
简称KMP算法,举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”?

许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。

这种算法不太容易理解,网上有很多解释,但读起来都很费劲。直到读到Jake Boxer的文章,我才真正理解这种算法。下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.

首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把”搜索位置”移到已经比较过的位置,重比一遍。
7.

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。KMP算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.

已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 – 对应的部分匹配值
因为 6 – 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 – 0,结果为 2,于是将搜索词向后移2位。
11.

因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 – 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 – 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
15.

“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
- ”A”的前缀和后缀都为空集,共有元素的长度为0;
- ”AB”的前缀为[A],后缀为[B],共有元素的长度为0;
- ”ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- ”ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- ”ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
- ”ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
- ”ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.

“部分匹配”的实质是,有时候,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。
KMP算法主要分为两个部分:
一、求子串P部分匹配值数组;
上面已经分析过,具体代码如下,其中pi指的是部分匹配数组;
-
void COMPUTE_PREIFX_FUNCTION(string P,vector<int>& pi) -
{ -
int m=P.size(); -
pi[0]=0; -
pi[1]=0; -
int k=0; -
for (int q=2;q<m;q++) -
{ -
while (k>0&&P[k+1]!=P[q]) -
{ -
k=pi[k]; -
} -
if (P[k+1]==P[q]) -
{ -
k=k+1; -
} -
pi[q]=k; -
} -
}
二、求字符匹配位置;
按上面分析给出如下代码,为了方便,我们给T,P前面分别增加一个字符“%”和“*”,这样字符串中的第i个字符在代码中的下标也为i,这样可以防止数组溢出,易于理解。
-
void KMP_MATCHER(string &T,string &P) -
{ -
T="%"+T; -
P="*"+P; -
int m=P.size(); -
vector<int> pi(m); -
int n=T.size(); -
COMPUTE_PREIFX_FUNCTION(P,pi); -
int q=0; -
int i; -
for (i=1;i<n;i++) -
{ -
while (q>0&&P[q+1]!=T[i]) -
{ -
q=pi[q]; -
} -
if (P[q+1]==T[i]) -
{ -
q=q+1; -
} -
if (q==m-1) -
{ -
cout<<"pattern occurs with shift "<<i-q<<endl; -
q=pi[q]; -
} -
} -
}
完整代码如下:
头文件:
-
#include <iostream> -
#include <string> -
#include <vector> -
using namespace std; -
void COMPUTE_PREIFX_FUNCTION(string P,vector<int>& pi); -
void KMP_MATCHER(string &T,string &P); -
void NAIVE_STRING_MATCHING(string T,string P);
main函数:
-
#include"head.h" -
void main() -
{ -
string T="BBC ABCDAB ABCDABCDABDEFABCDABDff"; -
string P="ABCDABD"; -
cout<<"NAIVE:"<<endl; -
NAIVE_STRING_MATCHING(T,P); -
cout<<"KMP:"<<endl; -
KMP_MATCHER(T,P); -
} -
void COMPUTE_PREIFX_FUNCTION(string P,vector<int>& pi) -
{ -
int m=P.size(); -
pi[0]=0; -
pi[1]=0; -
int k=0; -
for (int q=2;q<m;q++) -
{ -
while (k>0&&P[k+1]!=P[q]) -
{ -
k=pi[k]; -
} -
if (P[k+1]==P[q]) -
{ -
k=k+1; -
} -
pi[q]=k; -
} -
} -
void KMP_MATCHER(string &T,string &P) -
{ -
T="%"+T; -
P="*"+P; -
int m=P.size(); -
vector<int> pi(m); -
int n=T.size(); -
COMPUTE_PREIFX_FUNCTION(P,pi); -
int q=0; -
int i; -
for (i=1;i<n;i++) -
{ -
while (q>0&&P[q+1]!=T[i]) -
{ -
q=pi[q]; -
} -
if (P[q+1]==T[i]) -
{ -
q=q+1; -
} -
if (q==m-1) -
{ -
cout<<"pattern occurs with shift "<<i-q<<endl; -
q=pi[q]; -
} -
} -
} -
void NAIVE_STRING_MATCHING(string T,string P) -
{ -
int n=T.size(); -
int m=P.size(); -
int i; -
for (int s=0;s<n-m;s++) -
{ -
for (i=0;i<m;i++) -
{ -
if (P[i]!=T[s+i]) -
{ -
break; -
} -
} -
if (i==m) -
{ -
cout<<"pattern occurs with shift "<<s<<endl; -
} -
} -
}
运行结果如下:
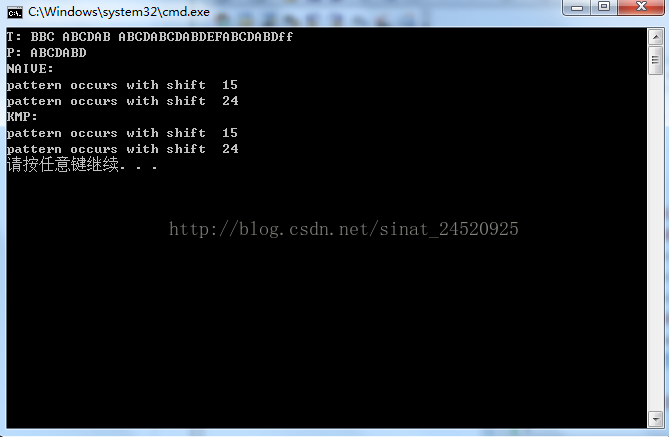
ABCDABD继BBC ABCDAB ABCDABCDABDEFABCDABDff第15个元素出现了一次,继第24个元素之后出现了一次。
本文代码参照算法导论第32章伪代码编写;
部分内容参考:http://blog.jobbole.com/39066/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号