招银网络java软开面经
目录
HashMap,HashTable,ConcurrentHashmap区别,底层源码
如何使得浏览器加载请求可以稳定打到后台而不使用浏览器缓存(请求中加一个随机值参数)
spring事务写在哪一部分,为什么不写在DAO,Controller层
一面:
多态实现
多态的概念:同一操作作用于不同对象,可以有不同的解释,有不同的执行结果,这就是多态,简单来说就是:父类的引用指向子类对象。下面先看一段代码
1 package polymorphism;
2
3 class Dance {
4 public void play(){
5 System.out.println("Dance.play");
6 }
7 public void play(int i){
8 System.out.println("Dance.play" + i);
9 }
10 }
11
12 class Latin extends Dance {
13 public void play(){
14 System.out.println("Latin.play");
15 }
16 public void play(char c){
17 System.out.println("Latin.play" + c);
18 }
19 }
20 class Jazz extends Dance {
21 public void play(){
22 System.out.println("Jazz.play");
23 }
24 public void play(double d){
25 System.out.println("Jazz.play" + d);
26 }
27 }
28 public class Test {
29 public void perform(Dance dance){
30 dance.play();
31 }
32 public static void main(String[] args){
33 new Test().perform(new Latin()); // Upcasting
34 }
35 }
执行结果:Latin.play。这个时候你可能会发现perform()方法里面并没有类似“if 参数类型 = Dance/Latin”这样的判断,其实这就是多态的特性,它消除了类型之间的耦合关系,令我们可以把一个对象不当做它所属的特定类型来对待,而是当做其基类的类型来对待。因为上面的Test代码完全可以这么写:
1 public class Test {
2 public void perform(Latin dance){
3 dance.play();
4 }
5 public void perform(Jazz dance){
6 dance.play();
7 }
8 public static void main(String[] args){
9 new Test().perform(new Latin()); // Upcasting
10 }
11 }
但是这样你会发现,如果增加更多新的类似perform()或者自Dance导出的新类,就会增加大量的工作,而通过比较就会知道第一处代码会占优势,这正是多态的优点所在,它改善了代码的组织结构和可读性,同时保证了可扩展性。那么到底JVM是怎么指向Latin类中play()的呢?为了解决这个问题,JAVA使用了后期绑定的概念。当向对象发送消息时,在编译阶段,编译器只保证被调用方法的存在,并对调用参数和返回类型进行检查,但是并不知道将被执行的确切代码,被调用的代码直到运行时才能确定。拿上面代码为例,JAVA在执行后期绑定时,JVM会从方法区中的Latin方法表中取到Latin对象的直接地址,这就是真正执行结果为什么是Latin.play的原因,在解释方法表之前,我们先了解一下绑定的概念。
将一个方法调用同一个方法主体关联起来被称作绑定,JAVA中分为前期绑定和后期绑定(动态绑定或运行时绑定),在程序执行之前进行绑定(由编译器和连接程序实现)叫做前期绑定,因为在编译阶段被调用方法的直接地址就已经存储在方法所属类的常量池中了,程序执行时直接调用,具体解释请看最后参考资料地址。后期绑定含义就是在程序运行时根据对象的类型进行绑定,想实现后期绑定,就必须具有某种机制,以便在运行时能判断对象的类型,从而找到对应的方法,简言之就是必须在对象中安置某种“类型信”,JAVA中除了static方法、final方法(private方法属于)之外,其他的方法都是后期绑定。后期绑定会涉及到JVM管理下的一个重要的数据结构——方法表,方法表以数组的形式记录当前类及其所有父类的可见方法字节码在内存中的直接地址。
动态绑定具体的调用过程为:
1.首先会找到被调用方法所属类的全限定名
2.在此类的方法表中寻找被调用方法,如果找到,会将方法表中此方法的索引项记录到常量池中(这个过程叫常量池解析),如果没有,编译失败。
3.根据具体实例化的对象找到方法区中此对象的方法表,再找到方法表中的被调用方法,最后通过直接地址找到字节码所在的内存空间。
生产者消费者手写
方法一:
- package ProduceConsumer;
- import java.util.ArrayList;
- public class Produce {
- public Object object;
- public ArrayList<Integer> list;//用list存放生产之后的数据,最大容量为1
- public Produce(Object object,ArrayList<Integer> list ){
- this.object = object;
- this.list = list;
- }
- public void produce() {
- synchronized (object) {
- /*只有list为空时才会去进行生产操作*/
- try {
- while(!list.isEmpty()){
- System.out.println("生产者"+Thread.currentThread().getName()+" waiting");
- object.wait();
- }
- int value = 9999;
- list.add(value);
- System.out.println("生产者"+Thread.currentThread().getName()+" Runnable");
- object.notifyAll();//然后去唤醒因object调用wait方法处于阻塞状态的线程
- }catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
[java] view plain copy
- package ProduceConsumer;
- import java.util.ArrayList;
- public class Consumer {
- public Object object;
- public ArrayList<Integer> list;//用list存放生产之后的数据,最大容量为1
- public Consumer(Object object,ArrayList<Integer> list ){
- this.object = object;
- this.list = list;
- }
- public void consmer() {
- synchronized (object) {
- try {
- /*只有list不为空时才会去进行消费操作*/
- while(list.isEmpty()){
- System.out.println("消费者"+Thread.currentThread().getName()+" waiting");
- object.wait();
- }
- list.clear();
- System.out.println("消费者"+Thread.currentThread().getName()+" Runnable");
- object.notifyAll();//然后去唤醒因object调用wait方法处于阻塞状态的线程
- }catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
[java] view plain copy
- package ProduceConsumer;
- public class ProduceThread extends Thread {
- private Produce p;
- public ProduceThread(Produce p){
- this.p = p;
- }
- @Override
- public void run() {
- while (true) {
- p.produce();
- }
- }
- }
[java] view plain copy
- package ProduceConsumer;
- public class ConsumeThread extends Thread {
- private Consumer c;
- public ConsumeThread(Consumer c){
- this.c = c;
- }
- @Override
- public void run() {
- while (true) {
- c.consmer();
- }
- }
- }
[java] view plain copy
- package ProduceConsumer;
- import java.util.ArrayList;
- public class Main {
- public static void main(String[] args) {
- Object object = new Object();
- ArrayList<Integer> list = new ArrayList<Integer>();
- Produce p = new Produce(object, list);
- Consumer c = new Consumer(object, list);
- ProduceThread[] pt = new ProduceThread[2];
- ConsumeThread[] ct = new ConsumeThread[2];
- for(int i=0;i<2;i++){
- pt[i] = new ProduceThread(p);
- pt[i].setName("生产者 "+(i+1));
- ct[i] = new ConsumeThread(c);
- ct[i].setName("消费者"+(i+1));
- pt[i].start();
- ct[i].start();
- }
- }
- }
方法二:
[java] view plain copy
- package ProduceConsumer2;
- import java.util.ArrayList;
- public class MyService {
- public ArrayList<Integer> list = new ArrayList<Integer>();//用list存放生产之后的数据,最大容量为1
- synchronized public void produce() {
- try {
- /*只有list为空时才会去进行生产操作*/
- while(!list.isEmpty()){
- System.out.println("生产者"+Thread.currentThread().getName()+" waiting");
- this.wait();
- }
- int value = 9999;
- list.add(value);
- System.out.println("生产者"+Thread.currentThread().getName()+" Runnable");
- this.notifyAll();//然后去唤醒因object调用wait方法处于阻塞状态的线程
- }catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- synchronized public void consmer() {
- try {
- /*只有list不为空时才会去进行消费操作*/
- while(list.isEmpty()){
- System.out.println("消费者"+Thread.currentThread().getName()+" waiting");
- this.wait();
- }
- list.clear();
- System.out.println("消费者"+Thread.currentThread().getName()+" Runnable");
- this.notifyAll();//然后去唤醒因object调用wait方法处于阻塞状态的线程
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
[java] view plain copy
- package ProduceConsumer2;
- public class ProduceThread extends Thread {
- private MyService p;
- public ProduceThread(MyService p){
- this.p = p;
- }
- @Override
- public void run() {
- while (true) {
- p.produce();
- }
- }
- }
[java] view plain copy
- package ProduceConsumer2;
- public class ConsumeThread extends Thread {
- private MyService c;
- public ConsumeThread(MyService c){
- this.c = c;
- }
- @Override
- public void run() {
- while (true) {
- c.consmer();
- }
- }
- }
用Lock和Condition实现
[java] view plain copy
- package ConditionProduceConsumer;
- import java.util.concurrent.locks.Condition;
- import java.util.concurrent.locks.ReentrantLock;
- public class MyService {
- private ReentrantLock lock = new ReentrantLock();
- private Condition condition = lock.newCondition();
- private boolean hasValue = false;
- public void produce() {
- lock.lock();
- try {
- /*只有list为空时才会去进行生产操作*/
- while(hasValue == true){
- System.out.println("生产者"+Thread.currentThread().getName()+" waiting");
- condition.await();
- }
- hasValue = true;
- System.out.println("生产者"+Thread.currentThread().getName()+" Runnable");
- condition.signalAll();//然后去唤醒因object调用wait方法处于阻塞状态的线程
- } catch (InterruptedException e) {
- e.printStackTrace();
- }finally{
- lock.unlock();
- }
- }
- public void consmer() {
- lock.lock();
- try {
- /*只有list为空时才会去进行生产操作*/
- while(hasValue == false){
- System.out.println("消费者"+Thread.currentThread().getName()+" waiting");
- condition.await();
- }
- hasValue = false;
- System.out.println("消费者"+Thread.currentThread().getName()+" Runnable");
- condition.signalAll();//然后去唤醒因object调用wait方法处于阻塞状态的线程
- } catch (InterruptedException e) {
- e.printStackTrace();
- }finally{
- lock.unlock();
- }
- }
- }
[java] view plain copy
- package ConditionProduceConsumer;
- public class ProduceThread extends Thread {
- private MyService p;
- public ProduceThread(MyService p){
- this.p = p;
- }
- @Override
- public void run() {
- while (true) {
- p.produce();
- }
- }
- }
[java] view plain copy
- package ConditionProduceConsumer;
- public class ConsumeThread extends Thread {
- private MyService c;
- public ConsumeThread(MyService c){
- this.c = c;
- }
- @Override
- public void run() {
- while (true) {
- c.consmer();
- }
- }
- }
[java] view plain copy
- package ConditionProduceConsumer;
- public class Main {
- public static void main(String[] args) {
- MyService service = new MyService();
- ProduceThread[] pt = new ProduceThread[2];
- ConsumeThread[] ct = new ConsumeThread[2];
- for(int i=0;i<1;i++){
- pt[i] = new ProduceThread(service);
- pt[i].setName("Condition 生产者 "+(i+1));
- ct[i] = new ConsumeThread(service);
- ct[i].setName("Condition 消费者"+(i+1));
- pt[i].start();
- ct[i].start();
- }
- }
- }
SQL查询语句手写
1. 用一条SQL 语句 查询出每门课都大于80 分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
A: select distinct name from table where name not in (select distinct name from table where fenshu<=80)
select name from table group by name having min(fenshu)>80
2. 学生表 如下:
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
删除除了自动编号不同, 其他都相同的学生冗余信息
A: delete tablename where 自动编号 not in(select min( 自动编号) from tablename group by 学号, 姓名, 课程编号, 课程名称, 分数)
3. 一个叫 team 的表,里面只有一个字段name, 一共有4 条纪录,分别是a,b,c,d, 对应四个球对,现在四个球对进行比赛,用一条sql 语句显示所有可能的比赛组合.
你先按你自己的想法做一下,看结果有我的这个简单吗?
答:select a.name, b.name
from team a, team b
where a.name < b.name
4. 请用SQL 语句实现:从TestDB 数据表中查询出所有月份的发生额都比101 科目相应月份的发生额高的科目。请注意:TestDB 中有很多科目,都有1 -12 月份的发生额。
AccID :科目代码,Occmonth :发生额月份,DebitOccur :发生额。
数据库名:JcyAudit ,数据集:Select * from TestDB
答:select a.*
from TestDB a
,(select Occmonth,max(DebitOccur) Debit101ccur from TestDB where AccID='101' group by Occmonth) b
where a.Occmonth=b.Occmonth and a.DebitOccur>b.Debit101ccur
************************************************************************************
5. 面试题:怎么把这样一个表儿
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
答案一、
select year,
(select amount from aaa m where month=1 and m.year=aaa.year) as m1,
(select amount from aaa m where month=2 and m.year=aaa.year) as m2,
(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
(select amount from aaa m where month=4 and m.year=aaa.year) as m4
from aaa group by year
*******************************************************************************
6. 说明:复制表( 只复制结构, 源表名:a 新表名:b)
SQL: select * into b from a where 1<>1 (where1=1,拷贝表结构和数据内容)
ORACLE:create table b
As
Select * from a where 1=2
[<>(不等于)(SQL Server Compact)
比较两个表达式。 当使用此运算符比较非空表达式时,如果左操作数不等于右操作数,则结果为 TRUE。 否则,结果为 FALSE。]
7. 说明:拷贝表( 拷贝数据, 源表名:a 目标表名:b)
SQL: insert into b(a, b, c) select d,e,f from a;
8. 说明:显示文章、提交人和最后回复时间
SQL: select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
9. 说明:外连接查询( 表名1 :a 表名2 :b)
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUTER JOIN b ON a.a = b.c
ORACLE :select a.a, a.b, a.c, b.c, b.d, b.f from a ,b
where a.a = b.c(+)
10. 说明:日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f 开始时间,getdate())>5
11. 说明:两张关联表,删除主表中已经在副表中没有的信息
SQL:
Delete from info where not exists (select * from infobz where info.infid=infobz.infid )
*******************************************************************************
12. 有两个表A 和B ,均有key 和value 两个字段,如果B 的key 在A 中也有,就把B 的value 换为A 中对应的value
这道题的SQL 语句怎么写?
update b set b.value=(select a.value from a where a.key=b.key) where b.id in(select b.id from b,a where b.key=a.key);
***************************************************************************
13. 高级sql 面试题
原表:
courseid coursename score
-------------------------------------
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
-------------------------------------
为了便于阅读, 查询此表后的结果显式如下( 及格分数为60):
courseid coursename score mark
---------------------------------------------------
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
---------------------------------------------------
写出此查询语句
select courseid, coursename ,score ,decode (sign(score-60),-1,'fail','pass') as mark from course
完全正确
SQL> desc course_v
Name Null? Type
----------------------------------------- -------- ----------------------------
COURSEID NUMBER
COURSENAME VARCHAR2(10)
SCORE NUMBER
SQL> select * from course_v;
COURSEID COURSENAME SCORE
---------- ---------- ----------
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
SQL> select courseid, coursename ,score ,decode(sign(score-60),-1,'fail','pass') as mark from course_v;
COURSEID COURSENAME SCORE MARK
---------- ---------- ---------- ----
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
SQL面试题(1)
create table testtable1
(
id int IDENTITY,
department varchar(12)
)
select * from testtable1
insert into testtable1 values('设计')
insert into testtable1 values('市场')
insert into testtable1 values('售后')
/*
结果
id department
1 设计
2 市场
3 售后
*/
create table testtable2
(
id int IDENTITY,
dptID int,
name varchar(12)
)
insert into testtable2 values(1,'张三')
insert into testtable2 values(1,'李四')
insert into testtable2 values(2,'王五')
insert into testtable2 values(3,'彭六')
insert into testtable2 values(4,'陈七')
/*
用一条SQL语句,怎么显示如下结果
id dptID department name
1 1 设计 张三
2 1 设计 李四
3 2 市场 王五
4 3 售后 彭六
5 4 黑人 陈七
*/
答案:
SELECT testtable2.* , ISNULL(department,'黑人')
FROM testtable1 right join testtable2 on testtable2.dptID = testtable1.ID
也做出来了可比这方法稍复杂。
sql面试题(2)
有表A,结构如下:
A: p_ID p_Num s_id
1 10 01
1 12 02
2 8 01
3 11 01
3 8 03
其中:p_ID为产品ID,p_Num为产品库存量,s_id为仓库ID。请用SQL语句实现将上表中的数据合并,合并后的数据为:
p_ID s1_id s2_id s3_id
1 10 12 0
2 8 0 0
3 11 0 8
其中:s1_id为仓库1的库存量,s2_id为仓库2的库存量,s3_id为仓库3的库存量。如果该产品在某仓库中无库存量,那么就是0代替。
结果:
select p_id ,
sum(case when s_id=1 then p_num else 0 end) as s1_id
,sum(case when s_id=2 then p_num else 0 end) as s2_id
,sum(case when s_id=3 then p_num else 0 end) as s3_id
from myPro group by p_id
SQL面试题(3)
1 .触发器的作用?
答:触发器是一中特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
2 。什么是存储过程?用什么来调用?
答:存储过程是一个预编译的 SQL 语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次 SQL ,使用存储过程比单纯 SQL 语句执行要快。可以用一个命令对象来调用存储过程。
3 。索引的作用?和它的优点缺点是什么?
答:索引就一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者是多个列。缺点是它减慢了数据录入的速度,同时也增加了数据库的尺寸大小。
3 。什么是内存泄漏?
答:一般我们所说的内存泄漏指的是堆内存的泄漏。堆内存是程序从堆中为其分配的,大小任意的,使用完后要显示释放内存。当应用程序用关键字 new 等创建对象时,就从堆中为它分配一块内存,使用完后程序调用 free 或者 delete 释放该内存,否则就说该内存就不能被使用,我们就说该内存被泄漏了。
4 。维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?
答:我是这样做的,尽可能使用约束,如 check, 主键,外键,非空字段等来约束,这样做效率最高,也最方便。其次是使用触发器,这种方法可以保证,无论什么业务系统访问数据库都可以保证数据的完整新和一致性。最后考虑的是自写业务逻辑,但这样做麻烦,编程复杂,效率低下。
5 。什么是事务?什么是锁?
答:事务就是被绑定在一起作为一个逻辑工作单元的 SQL 语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。要将有组语句作为事务考虑,就需要通过 ACID 测试,即原子性,一致性,隔离性和持久性。
锁:在所以的 DBMS 中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。
6 。什么叫视图?游标是什么?
答:视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
7。为管理业务培训信息,建立3个表:
S(S#,SN,SD,SA)S#,SN,SD,SA分别代表学号,学员姓名,所属单位,学员年龄
C(C#,CN)C#,CN分别代表课程编号,课程名称
SC(S#,C#,G) S#,C#,G分别代表学号,所选的课程编号,学习成绩
(1)使用标准SQL嵌套语句查询选修课程名称为’税收基础’的学员学号和姓名?
答案:select s# ,sn from s where S# in(select S# from c,sc where c.c#=sc.c# and cn=’税收基础’)
(2) 使用标准SQL嵌套语句查询选修课程编号为’C2’的学员姓名和所属单位?
答:select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’
(3) 使用标准SQL嵌套语句查询不选修课程编号为’C5’的学员姓名和所属单位?
答:select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
(4)查询选修了课程的学员人数
答:select 学员人数=count(distinct s#) from sc
(5) 查询选修课程超过5门的学员学号和所属单位?
答:select sn,sd from s where s# in(select s# from sc group by s# having count(distinct c#)>5)
SQL面试题(4)
1.查询A(ID,Name)表中第31至40条记录,ID作为主键可能是不是连续增长的列,完整的查询语句如下:
select top 10 * from A where ID >(select max(ID) from (select top 30 ID from A order by A ) T) order by A
2.查询表A中存在ID重复三次以上的记录,完整的查询语句如下:
select * from(select count(ID) as count from table group by ID)T where T.count>3
SQL面试题(5)
在面试应聘的SQL Server数据库开发人员时,我运用了一套标准的基准技术问题。下面这些问题是我觉得能够真正有助于淘汰不合格应聘者的问题。它们按照从易到难的顺序排列。当你问到关于主键和外键的问题时,后面的问题都十分有难度,因为答案可能会更难解释和说明,尤其是在面试的情形下。
你能向我简要叙述一下SQL Server 2000中使用的一些数据库对象吗?
你希望听到的答案包括这样一些对象:表格、视图、用户定义的函数,以及存储过程;如果他们还能够提到像触发器这样的对象就更好了。如果应聘者不能回答这个基本的问题,那么这不是一个好兆头。
NULL是什么意思?
NULL(空)这个值是数据库世界里一个非常难缠的东西,所以有不少应聘者会在这个问题上跌跟头您也不要觉得意外。
NULL这个值表示UNKNOWN(未知):它不表示“”(空字符串)。假设您的SQL Server数据库里有ANSI_NULLS,当然在默认情况下会有,对NULL这个值的任何比较都会生产一个NULL值。您不能把任何值与一个 UNKNOWN值进行比较,并在逻辑上希望获得一个答案。您必须使用IS NULL操作符。
什么是索引?SQL Server 2000里有什么类型的索引?
任何有经验的数据库开发人员都应该能够很轻易地回答这个问题。一些经验不太多的开发人员能够回答这个问题,但是有些地方会说不清楚。
简单地说,索引是一个数据结构,用来快速访问数据库表格或者视图里的数据。在SQL Server里,它们有两种形式:聚集索引和非聚集索引。聚集索引在索引的叶级保存数据。这意味着不论聚集索引里有表格的哪个(或哪些)字段,这些字段都会按顺序被保存在表格。由于存在这种排序,所以每个表格只会有一个聚集索引。非聚集索引在索引的叶级有一个行标识符。这个行标识符是一个指向磁盘上数据的指针。它允许每个表格有多个非聚集索引。
什么是主键?什么是外键?
主键是表格里的(一个或多个)字段,只用来定义表格里的行;主键里的值总是唯一的。外键是一个用来建立两个表格之间关系的约束。这种关系一般都涉及一个表格里的主键字段与另外一个表格(尽管可能是同一个表格)里的一系列相连的字段。那么这些相连的字段就是外键。
什么是触发器?SQL Server 2000有什么不同类型的触发器?
让未来的数据库开发人员知道可用的触发器类型以及如何实现它们是非常有益的。
触发器是一种专用类型的存储过程,它被捆绑到SQL Server 2000的表格或者视图上。在SQL Server 2000里,有INSTEAD-OF和AFTER两种触发器。INSTEAD-OF触发器是替代数据操控语言(Data Manipulation Language,DML)语句对表格执行语句的存储过程。例如,如果我有一个用于TableA的INSTEAD-OF-UPDATE触发器,同时对这个表格执行一个更新语句,那么INSTEAD-OF-UPDATE触发器里的代码会执行,而不是我执行的更新语句则不会执行操作。
AFTER触发器要在DML语句在数据库里使用之后才执行。这些类型的触发器对于监视发生在数据库表格里的数据变化十分好用。
您如何确一个带有名为Fld1字段的TableB表格里只具有Fld1字段里的那些值,而这些值同时在名为TableA的表格的Fld1字段里?
这个与关系相关的问题有两个可能的答案。第一个答案(而且是您希望听到的答案)是使用外键限制。外键限制用来维护引用的完整性。它被用来确保表格里的字段只保存有已经在不同的(或者相同的)表格里的另一个字段里定义了的值。这个字段就是候选键(通常是另外一个表格的主键)。
另外一种答案是触发器。触发器可以被用来保证以另外一种方式实现与限制相同的作用,但是它非常难设置与维护,而且性能一般都很糟糕。由于这个原因,微软建议开发人员使用外键限制而不是触发器来维护引用的完整性。
对一个投入使用的在线事务处理表格有过多索引需要有什么样的性能考虑?
你正在寻找进行与数据操控有关的应聘人员。对一个表格的索引越多,数据库引擎用来更新、插入或者删除数据所需要的时间就越多,因为在数据操控发生的时候索引也必须要维护。
你可以用什么来确保表格里的字段只接受特定范围里的值?
这个问题可以用多种方式来回答,但是只有一个答案是“好”答案。您希望听到的回答是Check限制,它在数据库表格里被定义,用来限制输入该列的值。
触发器也可以被用来限制数据库表格里的字段能够接受的值,但是这种办法要求触发器在表格里被定义,这可能会在某些情况下影响到性能。因此,微软建议使用Check限制而不是其他的方式来限制域的完整性。
如果应聘者能够正确地回答这个问题,那么他的机会就非常大了,因为这表明他们具有使用存储过程的经验。
返回参数总是由存储过程返回,它用来表示存储过程是成功还是失败。返回参数总是INT数据类型。
OUTPUT参数明确要求由开发人员来指定,它可以返回其他类型的数据,例如字符型和数值型的值。(可以用作输出参数的数据类型是有一些限制的。)您可以在一个存储过程里使用多个OUTPUT参数,而您只能够使用一个返回参数。
什么是相关子查询?如何使用这些查询?
经验更加丰富的开发人员将能够准确地描述这种类型的查询。
相关子查询是一种包含子查询的特殊类型的查询。查询里包含的子查询会真正请求外部查询的值,从而形成一个类似于循环的状况。
SQL面试题(6)
原表:
courseid coursename score
-------------------------------------
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
-------------------------------------
为了便于阅读,查询此表后的结果显式如下(及格分数为60):
courseid coursename score mark
---------------------------------------------------
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
---------------------------------------------------
写出此查询语句
ORACLE : select courseid, coursename ,score ,decode(sign(score-60),-1,'fail','pass') as mark from course
(DECODE函数是ORACLE PL/SQL是功能强大的函数之一,目前还只有ORACLE公司的SQL提供了此函数)
(SQL: select courseid, coursename ,score ,(case when score<60 then 'fail' else 'pass' end) as mark from course )
Mybatis批量查询手写
我的需求是查出每个球队中的助攻数最多的球员信息。
最开始使用配置的sql是:
<select id="selectMaxAssistListByTeamId" resultMap="BaseResultMap" parameterType="java.util.List" >
select
<include refid="Base_Column_List" />
from tab_player
where team_id in
<foreach collection="list" item="item" index="index" separator="," open="(" close=")">
#{item,jdbcType=VARCHAR}
</foreach>
Order By assist desc limit 1
</select>
这个SQL只能查出一条记录,显然不合逻辑。应该把order by移进foreach,一起循环:
<select id="selectMaxAssistListByTeamId" resultMap="BaseResultMap" parameterType="java.util.List" >
select
<include refid="Base_Column_List" />
from tab_player
where
<foreach collection="list" item="item" index="index" separator="," >
team_id = #{item,jdbcType=VARCHAR} Order By assist desc limit 1
</foreach>
</select>
还是不行,报错:...Exception:Undeclared variable:team_id.
百度无结果,都是用的in,显然不合我的要求,应该把in换掉。想了想,其实tab_player这个表里team_id
都是关联自tab_team这个表的team_id,用in的话不但是多此一举并且插叙速度还很慢。
应该继续改进第二个sql
换个思维:
用union!把separator的逗号改成UNION,并且要用括号()把sql包起来,不然报错:Incorrect usage of UNION and ORDER BY.
<select id="selectMaxAssistListByTeamId" resultMap="BaseResultMap" parameterType="java.util.List" >
<foreach collection="list" item="item" index="index" separator="UNION" >
(select
<include refid="Base_Column_List" />
from tab_xsj_player
where
team_id = #{item,jdbcType=VARCHAR} Order By assist desc limit 1)
</foreach>
</select>
本方法用的是union,有用in能查出来的请献出你的想法大家共同学习!
HashMap,HashTable,ConcurrentHashmap区别,底层源码
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
HashMap的初始值还要考虑加载因子:
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
程序猿可以根据实际情况来调整“负载极限”值。
ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞时,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
Hashtable是线程安全的,它的方法是同步的,可以直接用在多线程环境中。而HashMap则不是线程安全的,在多线程环境中,需要手动实现同步机制。
Hashtable与HashMap另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
先看一下简单的类图:

从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
内存泄漏的情况有哪些
内存泄漏定义:一个不再被程序使用的对象或变量还在内存中占有存储空间。
由于java的JVM引入了垃圾回收机制,垃圾回收器会自动回收不再使用的对象,了解JVM回收机制的都知道JVM是使用引用计数法和可达性分析算法来判断对象是否是不再使用的对象,本质都是判断一个对象是否还被引用。那么对于这种情况下,由于代码的实现不同就会出现很多种内存泄漏问题(让JVM误以为此对象还在引用中,无法回收,造成内存泄漏)。
1、静态集合类,如HashMap、LinkedList等等。如果这些容器为静态的,那么它们的生命周期与程序一致,则容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏。简单而言,长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象不再使用,但是因为长生命周期对象持有它的引用而导致不能被回收。
2、各种连接,如数据库连接、网络连接和IO连接等。在对数据库进行操作的过程中,首先需要建立与数据库的连接,当不再使用时,需要调用close方法来释放与数据库的连接。只有连接被关闭后,垃圾回收器才会回收对应的对象。否则,如果在访问数据库的过程中,对Connection、Statement或ResultSet不显性地关闭,将会造成大量的对象无法被回收,从而引起内存泄漏。
3、变量不合理的作用域。一般而言,一个变量的定义的作用范围大于其使用范围,很有可能会造成内存泄漏。另一方面,如果没有及时地把对象设置为null,很有可能导致内存泄漏的发生。
public class UsingRandom {
private String msg;
public void receiveMsg(){
readFromNet();// 从网络中接受数据保存到msg中
saveDB();// 把msg保存到数据库中
}
}
如上面这个伪代码,通过readFromNet方法把接受的消息保存在变量msg中,然后调用saveDB方法把msg的内容保存到数据库中,此时msg已经就没用了,由于msg的生命周期与对象的生命周期相同,此时msg还不能回收,因此造成了内存泄漏。
实际上这个msg变量可以放在receiveMsg方法内部,当方法使用完,那么msg的生命周期也就结束,此时就可以回收了。还有一种方法,在使用完msg后,把msg设置为null,这样垃圾回收器也会回收msg的内存空间。
4、内部类持有外部类,如果一个外部类的实例对象的方法返回了一个内部类的实例对象,这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持有外部类的实例对象,这个外部类对象将不会被垃圾回收,这也会造成内存泄露。
5、改变哈希值,当一个对象被存储进HashSet集合中以后,就不能修改这个对象中的那些参与计算哈希值的字段了,否则,对象修改后的哈希值与最初存储进HashSet集合中时的哈希值就不同了,在这种情况下,即使在contains方法使用该对象的当前引用作为的参数去HashSet集合中检索对象,也将返回找不到对象的结果,这也会导致无法从HashSet集合中单独删除当前对象,造成内存泄露
classpath,path的区别
1、 path是系统用来指定可执行文件的完整路径,即使不在path中设置JDK的路径也可执行Java文件,但必须把完整的路径写出来,如C:\Program Files\Java\jdk1.6.0_10\bin\javac TheClass.java。path是用来搜索所执行的可执行文件路径的,如果执行的可执行文件不在当前目录下,那就会依次搜索path中设置的路径;而java的各种操作命令是在其安装路径中的bin目录下。所以在path中设置了JDK的安装目录后就不用再把java文件的完整路径写出来了,它会自动去path中设置的路径中去找;
2、 classpath是指定你在程序中所使用的类(.class)文件所在的位置,就如在引入一个类时:import javax.swing.JTable这句话是告诉编译器要引入javax.swing这个包下的JTable类,而classpath就是告诉编译器该到哪里去找到这个类(前提是你在classpath中设置了这个类的路径)。如果你想要编译在当前目录下找,就加上“.”,如:.;C:\Program Files\Java\jdk\,这样编译器就会到当前目录和C:\Program Files\Java\jdk\去找javax.swing.JTable这个类;还提下:大多数人都是用Eclipse写程序,不设classpath也没关系,因为Eclipse有相关的配置;
JVM运行过程
一、JVM的体系结构
类装载系统
1、定位和导入二进制class文件
2、验证导入类的正确性
3、为类分配初始化内存
4、帮助解析符号引用
执行引擎
执行包在装载类的方法中的指令,也就是方法
运行区数据
虚拟机会在整个计算机内存中开辟一块内存存储JVM需要用到的对象,变量等,运行区数据有分很多小区,分别为:方法区,虚拟机栈,本地方法栈,堆,程序计数器。
GC
垃圾回收器,是负责回收内存中无用的对象,就是这些对象没有任何引用了,它就会被视为垃圾,也就会被删除。
二、类在JVM的执行流程
那么类在JVM的执行流程是怎么做的呢?共有三步:加载、链接和初始化。
加载
JVM将java类的二进制形式加载到内存中,并将他缓存在内存中,以便后面使用,如果没有找到指定的类就会抛出异常classNotFound,进程在这里结束。没有错误就继续在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区域数据的访问入口。
链接
这个阶段做三件事:验证、准备和解析(可选)。
验证是JVM根据java语言和JVM的语义要求检查这个二进制形式。例如,如果篡改经过编译后的类文件,那么这个类文件可能就不能使用了。
准备是指准备要执行的指定的类,准备阶段为变量分配内存并设置静态变量的初始化。在这个阶段分配的仅为类的变量(static修饰的变量),而不包括类的实例变量。对非final的变量,JVM会将其设置成“零值”,而不是其赋值语句的值:
public static int num = 8;
那么在这个阶段,num的值为0,而不是8。 final修饰的类变量将会赋值成真实的值。
解析是检查指定的类是否引用了其他的类/接口,是否能找到和加载其他的类/接口。这些检查将针对被引用的类/接口递归进行,JVM的实施也可以在后面阶段执行解析,即正在执行的代码真正要使用被引用的类/接口的时候。
初始化
在这最后一步中,JVM用赋值或者缺省值将静态变量初始化,初始化发生在执行main方法之前。在指定的类初始化前,会先初始化它的父类,此外,在初始化父类时,父类的父类也要这样初始化。这个过程是递归进行的。
简而言之,整个流程是将类存进内存中,检查类的对应调用的类和接口是否可正常使用,再对类进行初始化的过程。
类在JVM执行流程
三、Java代码编译和执行的整个过程
Java代码编译是由Java源码编译器来完成,流程图如下所示:
Java字节码的执行是由JVM执行引擎来完成,流程图如下所示:
四、总结
Java虚拟机的生命周期 一个运行中的Java虚拟机有着一个清晰的任务:执行Java程序。
程序开始执行时他才运行,程序结束时他就停止。你在同一台机器上运行三个程序,就会有三个运行中的Java虚拟机。
Java虚拟机总是开始于一个main()方法,这个方法必须是公有、返回void、直接受一个字符串数组。在程序执行时,你必须给Java虚拟机指明这个包换main()方法的类名。 Main()方法是程序的起点,他被执行的线程初始化为程序的初始线程。程序中其他的线程都由他来启动。
Java中的线程分为两种:守护线程(daemon)和普通线程(non-daemon)。守护线程是Java虚拟机自己使用的线程,比如负责垃圾收集的线程就是一个守护线程。当然,你也可 以把自己的程序设置为守护线程。包含Main()方法的初始线程不是守护线程。
只要Java虚拟机中还有普通的线程在执行,Java虚拟机就不会停止。如果有足够的权限,你可以调用exit()方法终止程序。
GC机制讲一讲
随着程序的运行,内存中的实例对象、变量等占据的内存越来越多,如果不及时进行回收,会降低程序运行效率,甚至引发系统异常。
在上面介绍的五个内存区域中,有3个是不需要进行垃圾回收的:本地方法栈、程序计数器、虚拟机栈。因为他们的生命周期是和线程同步的,随着线程的销毁,他们占用的内存会自动释放。所以,只有方法区和堆区需要进行垃圾回收,回收的对象就是那些不存在任何引用的对象。
3.1 查找算法
经典的引用计数算法,每个对象添加到引用计数器,每被引用一次,计数器+1,失去引用,计数器-1,当计数器在一段时间内为0时,即认为该对象可以被回收了。但是这个算法有个明显的缺陷:当两个对象相互引用,但是二者都已经没有作用时,理应把它们都回收,但是由于它们相互引用,不符合垃圾回收的条件,所以就导致无法处理掉这一块内存区域。因此,Sun的JVM并没有采用这种算法,而是采用一个叫——根搜索算法,如图:
基本思想是:从一个叫GC Roots的根节点出发,向下搜索,如果一个对象不能达到GC Roots的时候,说明该对象不再被引用,可以被回收。如上图中的Object5、Object6、Object7,虽然它们三个依然相互引用,但是它们其实已经没有作用了,这样就解决了引用计数算法的缺陷。
补充概念,在JDK1.2之后引入了四个概念:强引用、软引用、弱引用、虚引用。
强引用:new出来的对象都是强引用,GC无论如何都不会回收,即使抛出OOM异常。
软引用:只有当JVM内存不足时才会被回收。
弱引用:只要GC,就会立马回收,不管内存是否充足。
虚引用:可以忽略不计,JVM完全不会在乎虚引用,你可以理解为它是来凑数的,凑够”四大天王”。它唯一的作用就是做一些跟踪记录,辅助finalize函数的使用。
最后总结,什么样的类需要被回收:
a.该类的所有实例都已经被回收;
b.加载该类的ClassLoad已经被回收;
c.该类对应的反射类java.lang.Class对象没有被任何地方引用。
3.2 内存分区
内存主要被分为三块:新生代(Youn Generation)、旧生代(Old Generation)、持久代(Permanent Generation)。三代的特点不同,造就了他们使用的GC算法不同,新生代适合生命周期较短,快速创建和销毁的对象,旧生代适合生命周期较长的对象,持久代在Sun Hotpot虚拟机中就是指方法区(有些JVM根本就没有持久代这一说法)。
新生代(Youn Generation):大致分为Eden区和Survivor区,Survivor区又分为大小相同的两部分:FromSpace和ToSpace。新建的对象都是从新生代分配内存,Eden区不足的时候,会把存活的对象转移到Survivor区。当新生代进行垃圾回收时会出发Minor GC(也称作Youn GC)。
旧生代(Old Generation):旧生代用于存放新生代多次回收依然存活的对象,如缓存对象。当旧生代满了的时候就需要对旧生代进行回收,旧生代的垃圾回收称作Major GC(也称作Full GC)。
持久代(Permanent Generation):在Sun 的JVM中就是方法区的意思,尽管大多数JVM没有这一代。
3.3 GC算法
常见的GC算法:复制、标记-清除和标记-压缩
复制:复制算法采用的方式为从根集合进行扫描,将存活的对象移动到一块空闲的区域,如图所示:
当存活的对象较少时,复制算法会比较高效(新生代的Eden区就是采用这种算法),其带来的成本是需要一块额外的空闲空间和对象的移动。
标记-清除:该算法采用的方式是从跟集合开始扫描,对存活的对象进行标记,标记完毕后,再扫描整个空间中未被标记的对象,并进行清除。标记和清除的过程如下:
上图中蓝色部分是有被引用的对象,褐色部分是没有被引用的对象。在Marking阶段,需要进行全盘扫描,这个过程是比较耗时的。
清除阶段清理的是没有被引用的对象,存活的对象被保留。
标记-清除动作不需要移动对象,且仅对不存活的对象进行清理,在空间中存活对象较多的时候,效率较高,但由于只是清除,没有重新整理,因此会造成内存碎片。
标记-压缩:该算法与标记-清除算法类似,都是先对存活的对象进行标记,但是在清除后会把活的对象向左端空闲空间移动,然后再更新其引用对象的指针,如下图所示
由于进行了移动规整动作,该算法避免了标记-清除的碎片问题,但由于需要进行移动,因此成本也增加了。(该算法适用于旧生代)
四、垃圾收集器
在JVM中,GC是由垃圾回收器来执行,所以,在实际应用场景中,我们需要选择合适的垃圾收集器,下面我们介绍一下垃圾收集器。
4.1 串行收集器(Serial GC)
Serial GC是最古老也是最基本的收集器,但是现在依然广泛使用,JAVA SE5和JAVA SE6中客户端虚拟机采用的默认配置。比较适合于只有一个处理器的系统。在串行处理器中minor和major GC过程都是用一个线程进行回收的。它的最大特点是在进行垃圾回收时,需要对所有正在执行的线程暂停(stop the world),对于有些应用是难以接受的,但是如果应用的实时性要求不是那么高,只要停顿的时间控制在N毫秒之内,大多数应用还是可以接受的,而且事实上,它并没有让我们失望,几十毫秒的停顿,对于我们客户机是完全可以接受的,该收集器适用于单CPU、新生代空间较小且对暂停时间要求不是特别高的应用上,是client级别的默认GC方式。
4.2 ParNew GC
基本和Serial GC一样,但本质区别是加入了多线程机制,提高了效率,这样它就可以被用于服务端上(server),同时它可以与CMS GC配合,所以,更加有理由将他用于server端。
4.3 Parallel Scavenge GC
在整个扫描和复制过程采用多线程的方式进行,适用于多CPU、对暂停时间要求较短的应用,是server级别的默认GC方式。
4.4 CMS (Concurrent Mark Sweep)收集器
该收集器的目标是解决Serial GC停顿的问题,以达到最短回收时间。常见的B/S架构的应用就适合这种收集器,因为其高并发、高响应的特点,CMS是基于标记-清楚算法实现的。
CMS收集器的优点:并发收集、低停顿,但远没有达到完美;
CMS收集器的缺点:
a.CMS收集器对CPU资源非常敏感,在并发阶段虽然不会导致用户停顿,但是会占用CPU资源而导致应用程序变慢,总吞吐量下降。
b.CMS收集器无法处理浮动垃圾,可能出现“Concurrnet Mode Failure”,失败而导致另一次的Full GC。
c.CMS收集器是基于标记-清除算法的实现,因此也会产生碎片。
4.5 G1收集器
相比CMS收集器有不少改进,首先,基于标记-压缩算法,不会产生内存碎片,其次可以比较精确的控制停顿。
4.6 Serial Old收集器
Serial Old是Serial收集器的老年代版本,它同样使用一个单线程执行收集,使用“标记-整理”算法。主要使用在Client模式下的虚拟机。
4.7 Parallel Old收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。
4.8 RTSJ垃圾收集器
RTSJ垃圾收集器,用于Java实时编程。
五、总结
深入理解JVM的内存模型和GC机制有助于帮助我们编写高性能代码和提供代码优化的思路与方向。
线程池,阻塞队列
- 线程池
3种常用的线程池:
- newSIngleThreadExecutor(创建一个单线程)
- newFixedThreadPool(创建固定大小的线程池)
- newCacheThreadPool(创建一个可缓存的线程池)如果线程池的大小超过了处理任务所需的线程,那么就会回收部分空闲(60s不执行任务)的线程,当任务数增加时,此线程又可以添加新的线程来处理任务。
创建线程:使用Executors类提供的几个静态方法来创建线程池。
构造器的各个核心参数的含义:
corePoolsize:核心池大小
maxPoolSize:线程池最大线程数
关闭线程:
shutdown()和shutdownNow()是用来关闭线程的
- 阻塞队列:
对一个队列满了之后进行如队列(阻塞)
对一个队列空了之后进行出队列(阻塞)
用于消费者(取队列中元素的线程)生成者(往队列中添加元素的线程)
- ArrayblockingQueue:有界,锁是没有分离的,即生产者和消费者是同一把锁;进行put和take操作,公用同一个锁对象。也就是说put和take无法并行执行
- DelayQueue:按元素过期时间进行排序(DelayQueue=BlockingQueue+PriorityQueue+Delayed)
- LinkedBlockingQueue:对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,一次来提高整个队列的并发性能。
- PriorityBlockingQueue:无界,可以插入空对象(插入对象必须实现Comparable接口)
- SynchronousQueue:无界无缓存,不存储元素,它的size()方法总是返回0。每个线程插入操作必须等待另一个线程的插入操作。
- 死锁:
互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。
请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。
非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。
循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。
二面:
http ,https区别
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
一、HTTP和HTTPS的基本概念
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
二、HTTP与HTTPS有什么区别?
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
三、HTTPS的工作原理
我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议。
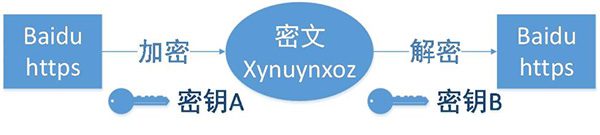
客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。
(1)客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
(2)Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
(3)客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
(4)客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
(5)Web服务器利用自己的私钥解密出会话密钥。
(6)Web服务器利用会话密钥加密与客户端之间的通信。

四、HTTPS的优点
尽管HTTPS并非绝对安全,掌握根证书的机构、掌握加密算法的组织同样可以进行中间人形式的攻击,但HTTPS仍是现行架构下最安全的解决方案,主要有以下几个好处:
(1)使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
(2)HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
(3)HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
(4)谷歌曾在2014年8月份调整搜索引擎算法,并称“比起同等HTTP网站,采用HTTPS加密的网站在搜索结果中的排名将会更高”。
五、HTTPS的缺点
虽然说HTTPS有很大的优势,但其相对来说,还是存在不足之处的:
(1)HTTPS协议握手阶段比较费时,会使页面的加载时间延长近50%,增加10%到20%的耗电;
(2)HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗,甚至已有的安全措施也会因此而受到影响;
(3)SSL证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用。
(4)SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
(5)HTTPS协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
六、http切换到HTTPS
如果需要将网站从http切换到https到底该如何实现呢?
这里需要将页面中所有的链接,例如js,css,图片等等链接都由http改为https。例如:http://www.baidu.com改为https://www.baidu.com
BTW,这里虽然将http切换为了https,还是建议保留http。所以我们在切换的时候可以做http和https的兼容,具体实现方式是,去掉页面链接中的http头部,这样可以自动匹配http头和https头。例如:将http://www.baidu.com改为//www.baidu.com。然后当用户从http的入口进入访问页面时,页面就是http,如果用户是从https的入口进入访问页面,页面即使https的。
分布式dubbo讲一下了解
1. 什么是Dubbo?
官网:http://dubbo.io/,DUBBO是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及作为SOA服务治理的方案,它是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点。<目前的dubbo社区已停止维护和更新>,它的核心功能包括:
- #remoting:远程通讯基础,提供对多种NIO框架抽象封装,包括“同步转异步”和“请求-响应”模式的信息交换方式。
- #cluster: 服务框架核心,提供基于接口方法的远程过程调用,包括多协议支持,并提供软负载均衡和容错机制的集群支持。
-
#registry: 服务注册中心,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
2. dubbo是如何使用来提供服务的?

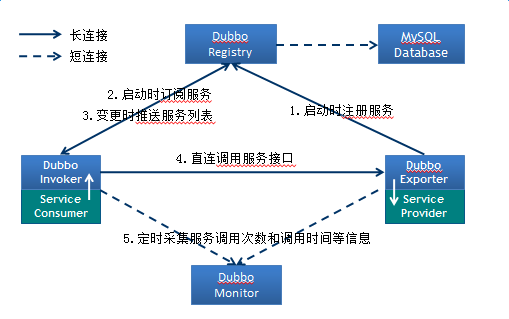
web应用架构的发展,从单一的ORM架构(一个应用,将所有功能部署在一起,减少部署的节点和成本)到MVC架构(拆分出互相不相干的几个应用),再从MVC框架到RPC框架(将业务中的核心业务抽取出来,做为独立的服务,渐渐形成服务中心),从RPC架构到SOA架构(增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率)。
Dubbo有自己的服务中心,写好的服务可以注册到服务中心,客户端从服务中心寻找服务,然后再到相应的服务提供者机器获取服务。通过服务中心可以实现集群、负载均衡、高可用(容错) 等重要功能。服务中心一般使用zookeeper实现,也有redis和其他一些方式。以使用zookeeper作为服务中心为例,服务提供者启动后会在zookeeper的/dubbo节点下创建提供的服务节点,包含服务提供者ip、port等信息。服务提供者关闭时会从zookeeper中移除对应的服务。服务使用者会从注册中心zookeeper中寻找服务,同一个服务可能会有多个提供者,Dubbo会帮我们找到合适的服务提供者。
3. dubbo是如何做集群容错的?
当服务调用失败时(比如响应超时),根据我们的业务不同,可以使用不同的策略来应对这种失败。比如我们调用的服务是一个查询服务,不会修改数据库,那么可以给该服务设置容错方式为failover <失败重试方式>,当调用失败时,自动切换到其他服务提供者去调用,当失败次数超过指定重试次数,那么就抛出错误。如果服务是更新数据的服务,那就不能使用失败重试的方式了, 因为这样可能产生数据重复修改的问题,比如调用提供者A的插入用户方法,但是该方法业务逻辑复杂,执行过程很慢,导致响应超时,那么此时如果再去调用另外一个服务提供者的插入用户方法,将会又重复插入同一个用户。对于这种类型的服务,可以使用容错方式为failfast,如果第一次调用失败,立即报错,不需要重试。
另外还有下面几种容错类型,failsafe 出现错误,直接忽略,不重试也不报错; failback 失败后不报错,会将该失败请求,定时重发,适合消息通知类型的服务。forking,并行调用多个服务器,只要在某一台提供者上面成功,那么方法返回,适合实时性要求较高的查询服务,但是要牺牲性能。因为每台服务器会做同一个操作;broadcast 广播调用所有服务提供者,逐个调用,任意一台报错则报错。适合与更新每台提供者上面的缓存,这种类型的服务。
案例:我们在点我吧的APP消息推送就是采用的failback方式,点我吧的短信通知则采用的是failover方式。
4. dubbo是如何做负载均衡的?{几种负载均衡的策略}
当同一个服务有多个提供者在提供服务时, 客户端如何正确的选择提供者实现负载均衡dubbo也给我们提供了几种方案:random,随机选提供者,并可以给提供者设置权重;roundrobin,轮询选择提供者,leastactive,最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。consistenthash 一致性hash,相同参数的请求发到同一台机器上。
关于一致性hash的几点学习,我们知道普通的哈希算法在散列的时候,可能产生间隔,并不能使数据均与分布开来。一致性哈希算法正是基于哈希算法的缺点所引入的解决方案。一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。接下来主要讲解一下一致性哈希算法是如何设计的:

如上图所示,是环形的hash空间,按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。我们把数据通过hash算法处理后映射到环上,现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。Hash(object1) = key1;Hash(object2) = key2;Hash(object3) = key3;Hash(object4) = key4;
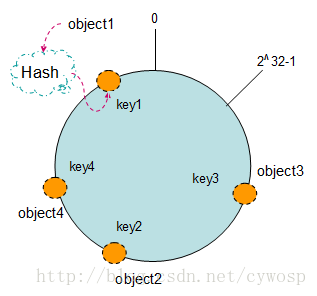
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会照成大量的对象存储位置失效,这样就大大的不满足单调性了。下面来分析一下一致性哈希算法是如何处理的?它通过按顺时针迁移的规则,首先保证其它对象还保持原有的存储位置。当通过节点的添加和删除的时候,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
5. dubbo的多协议方式?
dubbo提供了多种协议给用户选择,如dubbo、hessian、rmi 。并可为每个服务指定不同的传输协议,粒度可以细化到方法,不同服务在性能上适用不同协议进行传输,比如大数据用短连接协议,小数据大并发用长连接协议。
使用Dubbo进行远程调用实现服务交互,它支持多种协议,如Hessian、HTTP、RMI、Memcached、Redis、Thrift等等。由于Dubbo将这些协议的实现进行了封装了,无论是服务端(开发服务)还是客户端(调用服务),都不需要关心协议的细节,只需要在配置中指定使用的协议即可,从而保证了服务提供方与服务消费方之间的透明。另外,如果我们使用Dubbo的服务注册中心组件,这样服务提供方将服务发布到注册的中心,只是将服务的名称暴露给外部,而服务消费方只需要知道注册中心和服务提供方提供的服务名称,就能够透明地调用服务,后面我们会看到具体提供服务和消费服务的配置内容,使得双方之间交互的透明化。

如图所示的应用场景,服务方提供一个搜索服务,对服务方来说,它基于SolrCloud构建了搜索服务,包含两个集群,ZooKeeper集群和Solr集群,然后在前端通过Nginx来进行反向代理,达到负载均衡的目的。服务消费方就是调用服务进行查询,给出查询条件。
基于上面的示例场景,我们打算使用ZooKeeper集群作为服务注册中心。注册中心会暴露给服务提供方和服务消费方,所以注册服务的时候,服务先提供方只需要提供Nginx的地址给注册中心,但是注册中心并不会把这个地址暴露给服务消费方。
1 public interface SolrSearchService {
2 String search(String collection, String q, ResponseType type, int start, int rows);
3 public enum ResponseType {JSON, XML}
4 }
其中,provider的服务设计:provider所发布的服务组件,包含了一个SolrCloud集群,在SolrCloud集群前端又加了一个反向代理层,使用Nginx来均衡负载。Provider的搜索服务系统,设计如下图所示:

如图所示,实际nginx中将请求直接转发到内部的Web Servers上,在这个过程中,使用ZooKeeper来进行协调:从多个分片(Shard)服务器上并行搜索,最后合并结果。一共配置了3台Solr服务器,因为SolrCloud集群中每一个节点都可以接收搜索请求,然后由整个集群去并行搜索。最后,我们要通过Dubbo服务框架来基于已有的系统来开发搜索服务,并通过Dubbo的注册中心来发布服务。首选需要实现服务接口,实现代码如下所示:

1 package org.shirdrn.platform.dubbo.service.rpc.server;
2
3 import java.io.IOException;
4 import java.util.HashMap;
5 import java.util.Map;
6
7 import org.apache.commons.logging.Log;
8 import org.apache.commons.logging.LogFactory;
9 import org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService;
10 import org.shirdrn.platform.dubbo.service.rpc.utils.QueryPostClient;
11 import org.springframework.context.support.ClassPathXmlApplicationContext;
12
13 public class SolrSearchServer implements SolrSearchService {
14
15 private static final Log LOG = LogFactory.getLog(SolrSearchServer.class);
16 private String baseUrl;
17 private final QueryPostClient postClient;
18 private static final Map<ResponseType, FormatHandler> handlers = new HashMap<ResponseType, FormatHandler>(0);
19 static {
20 handlers.put(ResponseType.XML, new FormatHandler() {
21 public String format() {
22 return "&wt=xml";
23 }
24 });
25 handlers.put(ResponseType.JSON, new FormatHandler() {
26 public String format() {
27 return "&wt=json";
28 }
29 });
30 }
31 public SolrSearchServer() {
32 super();
33 postClient = QueryPostClient.newIndexingClient(null);
34 }
35 public void setBaseUrl(String baseUrl) {
36 this.baseUrl = baseUrl;
37 }
38 public String search(String collection, String q, ResponseType type,
39 int start, int rows) {
40 StringBuffer url = new StringBuffer();
url.append(baseUrl).append(collection).append("/select?").append(q);
url.append("&start=").append(start).append("&rows=").append(rows);
41 url.append(handlers.get(type).format());
42 LOG.info("[REQ] " + url.toString());
43 return postClient.request(url.toString());
44 }
45 interface FormatHandler {
46 String format();
47 }
48 public static void main(String[] args) throws IOException {
49 String config = SolrSearchServer.class.getPackage().getName().replace('.', '/') + "/search-provider.xml";
50 ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(config);
51 context.start();
52 System.in.read();
53 }
54 }
对应的Dubbo配置文件为search-provider.xml,内容如下所示:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd 4 http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd"> 5 <dubbo:application name="search-provider" /> 6 <dubbo:registry address="zookeeper://slave1:2188?backup=slave3:2188,slave4:2188" /> 7 <dubbo:protocol name="dubbo" port="20880" /> 8 <bean id="searchService" class="org.shirdrn.platform.dubbo.service.rpc.server.SolrSearchServer"> 9 <property name="baseUrl" value="http://nginx-lbserver/solr-cloud/" /> 10 </bean> 11 <dubbo:service interface="org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService" ref="searchService" /> 12 </beans>
上面,Dubbo服务注册中心指定ZooKeeper的地址:zookeeper://slave1:2188?backup=slave3:2188,slave4:2188,使用Dubbo协议。配置服务接口的时候,可以按照Spring的Bean的配置方式来配置,注入需要的内容,我们这里指定了搜索集群的Nginx反向代理地址http://nginx-lbserver/solr-cloud/。
6. dubbo的使用特点?
dubbo采用全Spring配置方式,透明化接入应用,对应用没有任何API侵入,只需用Spring加载Dubbo的配置即可,Dubbo基于Spring的Schema扩展进行加载。
7. 总结
dubbo是高性能的分布式服务框架,它提供了服务治理的解决方案。它适用于(公司内部)跨部门跨项目远程调用的场景,
dubbo稳定而高效,不仅支持大规模服务集群的动态扩展,平滑升级,而且支持load balance,fail over,支持服务质量分级管理,dubbo简化了服务配置,减少DB连接数。
dubbo可以做什么,dubbo是基于NIO和长连接的远程调用实现,dubbo提供的服务暴露和导入,对应用方的代码无侵入性,dubbo提供多协议支持,如RMI、Hessian、tbr等,dubbo提供了fail over机制,当某个provider出现异常后,会自动切换provider,dubbo提供了load balance机制,采用了权重+随机或轮询算法,服务列表动态更新,如步骤三。dubbo解决了服务治理问题,包括provider和consumer之间的匹配问题,dubbo提供了服务的注册和订阅功能,dubbo的灵活的路由规则设置,且支持服务列表动态推送功能,且提供了基于web的管理功能。
/*
* 使用Dubbo服务接口
*/
// 首先,在API包中定义服务接口,同时部署于Provider端和Consumer端
public interface HelloService {
public String sayHello();
}
// 其次,在服务端的Provider实现代码
public class HelloServiceImpl implements HelloService {
public String sayHello() {
return "Welcome to dubbo!";
}
}
// 配置:提供者暴露服务;消费者消费服务
/*provider端服务实现类*/
<bean id="helloService" class="com.alibaba.hello.impl.HelloServiceImpl" />
/*provider端暴露服务*/
<dubbo:service interface="com.alibaba.hello.HelloService" version="1.0.0" ref="helloService"/>
/*consumer端引入服务*/
<dubbo:reference id="helloService" interface="com.alibaba.hello.HelloService" version="1.0.0" />
/*consumer端使用服务*/
<bean id="xxxAction" class="com.alibaba.xxx.XxxAction" ><property name="helloService" ref="helloService" /></bean>
我们对dubbo的性能做出测试,如下:

项目介绍
非对称加密和对称加密
什么是对称加密技术?
对称加密采用了对称密码编码技术,它的特点是文件加密和解密使用相同的密钥加密
也就是密钥也可以用作解密密钥,这种方法在密码学中叫做对称加密算法,对称加密算法使用起来简单快捷,密钥较短,且破译困难,除了数据加密标准(DES),另一个对称密钥加密系统是国际数据加密算法(IDEA),它比DES的加密性好,而且对计算机功能要求也没有那么高
对称加密算法在电子商务交易过程中存在几个问题:
1、要求提供一条安全的渠道使通讯双方在首次通讯时协商一个共同的密钥。直接的面对面协商可能是不现实而且难于实施的,所以双方可能需要借助于邮件和电话等其它相对不够安全的手段来进行协商;
2、密钥的数目难于管理。因为对于每一个合作者都需要使用不同的密钥,很难适应开放社会中大量的信息交流;
3、对称加密算法一般不能提供信息完整性的鉴别。它无法验证发送者和接受者的身份;
4、对称密钥的管理和分发工作是一件具有潜在危险的和烦琐的过程。对称加密是基于共同保守秘密来实现的,采用对称加密技术的贸易双方必须保证采用的是相同的密钥,保证彼此密钥的交换是安全可靠的,同时还要设定防止密钥泄密和更改密钥的程序。
假设两个用户需要使用对称加密方法加密然后交换数据,则用户最少需要2个密钥并交换使用,如果企业内用户有n个,则整个企业共需要n×(n-1) 个密钥,密钥的生成和分发将成为企业信息部门的恶梦。
常见的对称加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES
什么是非对称加密技术
与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey)。
公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
非对称加密算法实现机密信息交换的基本过程是:甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;得到该公用密钥的乙方使用该密钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。甲方只能用其专用密钥解密由其公用密钥加密后的任何信息。
非对称加密的典型应用是数字签名。
常见的非对称加密算法有:RSA、ECC(移动设备用)、Diffie-Hellman、El Gamal、DSA(数字签名用)
Hash算法(摘要算法)
Hash算法特别的地方在于它是一种单向算法,用户可以通过hash算法对目标信息生成一段特定长度的唯一hash值,却不能通过这个hash值重新获得目标信息。因此Hash算法常用在不可还原的密码存储、信息完整性校验等。
常见的Hash算法有MD2、MD4、MD5、HAVAL、SHA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号