CVTE Java后台电话一面
目录
项目中遇到的问题,然后我说了几个,他貌似不感兴趣,然后问了我内存溢出遇到过没有
对Java的集合类了解哪一些,回答了Collection和Map这两个以及他们的子类,扯到hashMap
在什么情况下使用过hashMap,对hashmap的底层结构可以说一下吗
hashMap是线程安全的吗,回答不是,然后又扯到ConcurrentHashMap,然后问ConcurrentHashMap的细节
问数据库,回答学的mysql,问有几种引擎,回答有好几种,主要就两种
学习Java多久了
使用Java做过什么东西
项目中遇到的问题,然后我说了几个,他貌似不感兴趣,然后问了我内存溢出遇到过没有
Servlet的生命周期
Servlet生命周期
加载和实例化Servlet
我们来看一下Tomcat是如何加载的:
1. 如果已配置自动装入选项,则在启动时自动载入。
2. 在服务器启动时,客户机首次向Servlet发出请求。
3. 重新装入Servlet时。
当启动Servlet容器时,容器首先查找一个配置文件web.xml,这个文件中记录了可以提供服务的Servlet。每个Servlet被指定一个Servlet名,也就是这个Servlet实际对应的Java的完整class文件名。Servlet容器会为每个自动装入选项的Servlet创建一个实例。所以,每个Servlet类必须有一个公共的无参数的构造器。
初始化
当Servlet被实例化后,Servlet容器将调用每个Servlet的init方法来实例化每个实例,执行完init方法之后,Servlet处于“已初始化”状态。所以说,一旦Servlet被实例化,那么必将调用init方法。通过Servlet在启动后不立即初始化,而是收到请求后进行。在web.xml文件中用<load-on-statup> ...... </load-on-statup>对Servlet进行预先初始化。
初始化失败后,执行init()方法抛出ServletException异常,Servlet对象将会被垃圾回收器回收,当客户端第一次访问服务器时加载Servlet实现类,创建对象并执行初始化方法。
请求处理
Servlet 被初始化以后,就处于能响应请求的就绪状态。每个对Servlet 的请求由一个Servlet Request 对象代表。Servlet 给客户端的响应由一个Servlet Response对象代表。对于到达客户机的请求,服务器创建特定于请求的一个“请求”对象和一个“响应”对象。调用service方法,这个方法可以调用其他方法来处理请求。
Service方法会在服务器被访问时调用,Servlet对象的生命周期中service方法可能被多次调用,由于web-server启动后,服务器中公开的部分资源将处于网络中,当网络中的不同主机(客户端)并发访问服务器中的同一资源,服务器将开设多个线程处理不同的请求,多线程同时处理同一对象时,有可能出现数据并发访问的错误。
另外注意,多线程难免同时处理同一变量时(如:对同一文件进行写操作),且有读写操作时,必须考虑是否加上同步,同步添加时,不要添加范围过大,有可能使程序变为纯粹的单线程,大大削弱了系统性能;只需要做到多个线程安全的访问相同的对象就可以了。
卸载Servlet
当服务器不再需要Servlet实例或重新装入时,会调用destroy方法,使用这个方法,Servlet可以释放掉所有在init方法申请的资源。一个Servlet实例一旦终止,就不允许再次被调用,只能等待被卸载。
Servlet一旦终止,Servlet实例即可被垃圾回收,处于“卸载”状态,如果Servlet容器被关闭,Servlet也会被卸载,一个Servlet实例只能初始化一次,但可以创建多个相同的Servlet实例。如相同的Servlet可以在根据不同的配置参数连接不同的数据库时创建多个实例。
session和cookie的区别
二者的定义:
当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cookie 会帮你在网站上所打的文字或是一些选择,都纪录下来。当下次你再光临同一个网站,WEB 服务器会先看看有没有它上次留下的 Cookie 资料,有的话,就会依据 Cookie里的内容来判断使用者,送出特定的网页内容给你。 Cookie 的使用很普遍,许多有提供个人化服务的网站,都是利用 Cookie来辨认使用者,以方便送出使用者量身定做的内容,像是 Web 接口的免费 email 网站,都要用到 Cookie。
具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案,同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上它还有其他选择。
cookie机制。正统的cookie分发是通过扩展HTTP协议来实现的,服务器通过在HTTP的响应头中加上一行特殊的指示以提示浏览器按照指示生成相应的cookie。然而纯粹的客户端脚本如JavaScript或者VBScript也可以生成cookie。而cookie的使用是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器。
cookie的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成cookie的作用范围。若不设置过期时间,则表示这个cookie的生命期为浏览器会话期间,关闭浏览器窗口,cookie就消失。这种生命期为浏览器会话期的cookie被称为会话cookie。
会话cookie一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。若设置了过期时间,浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie仍然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存里的cookie,不同的浏览器有不同的处理方式。
session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。 当程序需要为某个客户端的请求创建一个session时,服务器首先检查这个客户端的请求里是否已包含了一个session标识(称为session id),如果已包含则说明以前已经为此客户端创建过session,服务器就按照session id把这个session检索出来使用(检索不到,会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存。保存这个session id的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发送给服务器。一般这个cookie的名字都是类似于SEEESIONID。但cookie可以被人为的禁止,则必须有其他机制以便在cookie被禁止时仍然能够把session id传递回服务器。
经常被使用的一种技术叫做URL重写,就是把session id直接附加在URL路径的后面。还有一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把session id传递回服务器。比如:
<form name="testform" action="/xxx">
<input type="hidden" name="jsessionid" value="ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764">
<input type="text">
</form>
实际上这种技术可以简单的用对action应用URL重写来代替。
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能, 考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
对Java的集合类了解哪一些,回答了Collection和Map这两个以及他们的子类,扯到hashMap
在什么情况下使用过hashMap,对hashmap的底层结构可以说一下吗
1. HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
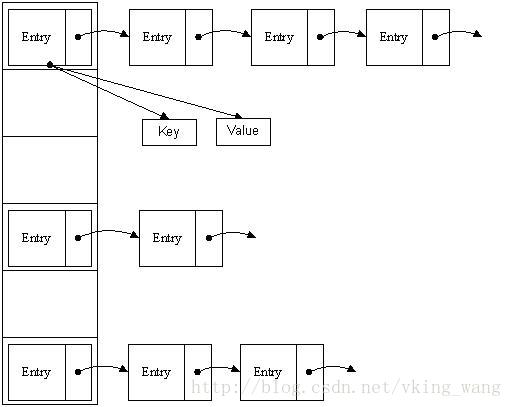
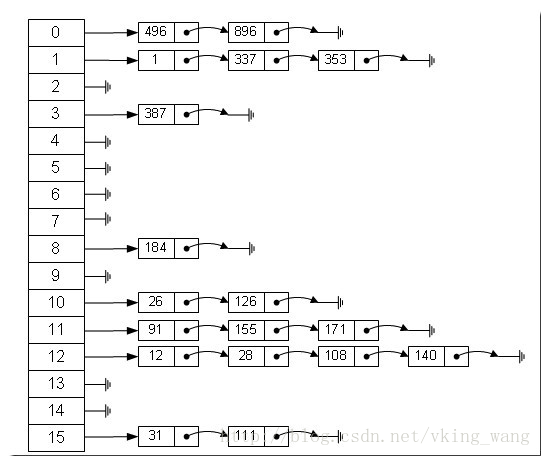
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
2. HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1)put
疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。
2)get
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
3)null key的存取
null key总是存放在Entry[]数组的第一个元素。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
4)确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%。
这意味着数组下标相同,并不表示hashCode相同。
5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
hashMap是线程安全的吗,回答不是,然后又扯到ConcurrentHashMap,然后问ConcurrentHashMap的细节
ConcurrentHashMap是Java 5中支持高并发、高吞吐量的线程安全HashMap实现。在这之前我对ConcurrentHashMap只有一些肤浅的理解,仅知道它采用了多个锁,大概也足够了。但是在经过一次惨痛的面试经历之后,我觉得必须深入研究它的实现。面试中被问到读是否要加锁,因为读写会发生冲突,我说必须要加锁,我和面试官也因此发生了冲突,结果可想而知。还是闲话少说,通过仔细阅读源代码,现在总算理解ConcurrentHashMap实现机制了,其实现之精巧,令人叹服,与大家共享之。
实现原理
锁分离 (Lock Stripping)
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。不变性在多线程编程占有很重要的地位,下面还要谈到。
Java代码 ![]()
- /**
- * The segments, each of which is a specialized hash table
- */
- final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,其结构如下所示:
Java代码 ![]()
- static final class HashEntry<K,V> {
- final K key;
- final int hash;
- volatile V value;
- final HashEntry<K,V> next;
- }
可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。这在讲解删除操作时还会详述。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。
其它
为了加快定位段以及段中hash槽的速度,每个段hash槽的的个数都是2^n,这使得通过位运算就可以定位段和段中hash槽的位置。当并发级别为默认值16时,也就是段的个数,hash值的高4位决定分配在哪个段中。但是我们也不要忘记《算法导论》给我们的教训:hash槽的的个数不应该是2^n,这可能导致hash槽分配不均,这需要对hash值重新再hash一次。(这段似乎有点多余了![]() )
)
这是重新hash的算法,还比较复杂,我也懒得去理解了。
Java代码 ![]()
- private static int hash(int h) {
- // Spread bits to regularize both segment and index locations,
- // using variant of single-word Wang/Jenkins hash.
- h += (h << 15) ^ 0xffffcd7d;
- h ^= (h >>> 10);
- h += (h << 3);
- h ^= (h >>> 6);
- h += (h << 2) + (h << 14);
- return h ^ (h >>> 16);
- }
这是定位段的方法:
Java代码 ![]()
- final Segment<K,V> segmentFor(int hash) {
- return segments[(hash >>> segmentShift) & segmentMask];
- }
数据结构
关于Hash表的基础数据结构,这里不想做过多的探讨。Hash表的一个很重要方面就是如何解决hash冲突,ConcurrentHashMap和HashMap使用相同的方式,都是将hash值相同的节点放在一个hash链中。与HashMap不同的是,ConcurrentHashMap使用多个子Hash表,也就是段(Segment)。下面是ConcurrentHashMap的数据成员:
Java代码 ![]()
- public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
- implements ConcurrentMap<K, V>, Serializable {
- /**
- * Mask value for indexing into segments. The upper bits of a
- * key's hash code are used to choose the segment.
- */
- final int segmentMask;
- /**
- * Shift value for indexing within segments.
- */
- final int segmentShift;
- /**
- * The segments, each of which is a specialized hash table
- */
- final Segment<K,V>[] segments;
- }
所有的成员都是final的,其中segmentMask和segmentShift主要是为了定位段,参见上面的segmentFor方法。
每个Segment相当于一个子Hash表,它的数据成员如下:
Java代码 ![]()
- static final class Segment<K,V> extends ReentrantLock implements Serializable {
- private static final long serialVersionUID = 2249069246763182397L;
- /**
- * The number of elements in this segment's region.
- */
- transient volatile int count;
- /**
- * Number of updates that alter the size of the table. This is
- * used during bulk-read methods to make sure they see a
- * consistent snapshot: If modCounts change during a traversal
- * of segments computing size or checking containsValue, then
- * we might have an inconsistent view of state so (usually)
- * must retry.
- */
- transient int modCount;
- /**
- * The table is rehashed when its size exceeds this threshold.
- * (The value of this field is always <tt>(int)(capacity *
- * loadFactor)</tt>.)
- */
- transient int threshold;
- /**
- * The per-segment table.
- */
- transient volatile HashEntry<K,V>[] table;
- /**
- * The load factor for the hash table. Even though this value
- * is same for all segments, it is replicated to avoid needing
- * links to outer object.
- * @serial
- */
- final float loadFactor;
- }
count用来统计该段数据的个数,它是volatile,它用来协调修改和读取操作,以保证读取操作能够读取到几乎最新的修改。协调方式是这样的,每次修改操作做了结构上的改变,如增加/删除节点(修改节点的值不算结构上的改变),都要写count值,每次读取操作开始都要读取count的值。这利用了Java 5中对volatile语义的增强,对同一个volatile变量的写和读存在happens-before关系。modCount统计段结构改变的次数,主要是为了检测对多个段进行遍历过程中某个段是否发生改变,在讲述跨段操作时会还会详述。threashold用来表示需要进行rehash的界限值。table数组存储段中节点,每个数组元素是个hash链,用HashEntry表示。table也是volatile,这使得能够读取到最新的table值而不需要同步。loadFactor表示负载因子。
实现细节
修改操作
先来看下删除操作remove(key)。
Java代码 ![]()
- public V remove(Object key) {
- hash = hash(key.hashCode());
- return segmentFor(hash).remove(key, hash, null);
- }
整个操作是先定位到段,然后委托给段的remove操作。当多个删除操作并发进行时,只要它们所在的段不相同,它们就可以同时进行。下面是Segment的remove方法实现:
Java代码 ![]()
- V remove(Object key, int hash, Object value) {
- lock();
- try {
- int c = count - 1;
- HashEntry<K,V>[] tab = table;
- int index = hash & (tab.length - 1);
- HashEntry<K,V> first = tab[index];
- HashEntry<K,V> e = first;
- while (e != null && (e.hash != hash || !key.equals(e.key)))
- e = e.next;
- V oldValue = null;
- if (e != null) {
- V v = e.value;
- if (value == null || value.equals(v)) {
- oldValue = v;
- // All entries following removed node can stay
- // in list, but all preceding ones need to be
- // cloned.
- ++modCount;
- HashEntry<K,V> newFirst = e.next;
- for (HashEntry<K,V> p = first; p != e; p = p.next)
- newFirst = new HashEntry<K,V>(p.key, p.hash,
- newFirst, p.value);
- tab[index] = newFirst;
- count = c; // write-volatile
- }
- }
- return oldValue;
- } finally {
- unlock();
- }
- }
整个操作是在持有段锁的情况下执行的,空白行之前的行主要是定位到要删除的节点e。接下来,如果不存在这个节点就直接返回null,否则就要将e前面的结点复制一遍,尾结点指向e的下一个结点。e后面的结点不需要复制,它们可以重用。下面是个示意图,我直接从这个网站 上复制的(画这样的图实在是太麻烦了,如果哪位有好的画图工具,可以推荐一下)。
删除元素之前:

删除元素3之后:

第二个图其实有点问题,复制的结点中应该是值为2的结点在前面,值为1的结点在后面,也就是刚好和原来结点顺序相反,还好这不影响我们的讨论。
整个remove实现并不复杂,但是需要注意如下几点。第一,当要删除的结点存在时,删除的最后一步操作要将count的值减一。这必须是最后一步操作,否则读取操作可能看不到之前对段所做的结构性修改。第二,remove执行的开始就将table赋给一个局部变量tab,这是因为table是volatile变量,读写volatile变量的开销很大。编译器也不能对volatile变量的读写做任何优化,直接多次访问非volatile实例变量没有多大影响,编译器会做相应优化。
接下来看put操作,同样地put操作也是委托给段的put方法。下面是段的put方法:
Java代码 ![]()
- V put(K key, int hash, V value, boolean onlyIfAbsent) {
- lock();
- try {
- int c = count;
- if (c++ > threshold) // ensure capacity
- rehash();
- HashEntry<K,V>[] tab = table;
- int index = hash & (tab.length - 1);
- HashEntry<K,V> first = tab[index];
- HashEntry<K,V> e = first;
- while (e != null && (e.hash != hash || !key.equals(e.key)))
- e = e.next;
- V oldValue;
- if (e != null) {
- oldValue = e.value;
- if (!onlyIfAbsent)
- e.value = value;
- }
- else {
- oldValue = null;
- ++modCount;
- tab[index] = new HashEntry<K,V>(key, hash, first, value);
- count = c; // write-volatile
- }
- return oldValue;
- } finally {
- unlock();
- }
- }
该方法也是在持有段锁的情况下执行的,首先判断是否需要rehash,需要就先rehash。接着是找是否存在同样一个key的结点,如果存在就直接替换这个结点的值。否则创建一个新的结点并添加到hash链的头部,这时一定要修改modCount和count的值,同样修改count的值一定要放在最后一步。put方法调用了rehash方法,reash方法实现得也很精巧,主要利用了table的大小为2^n,这里就不介绍了。
修改操作还有putAll和replace。putAll就是多次调用put方法,没什么好说的。replace甚至不用做结构上的更改,实现要比put和delete要简单得多,理解了put和delete,理解replace就不在话下了,这里也不介绍了。
获取操作
首先看下get操作,同样ConcurrentHashMap的get操作是直接委托给Segment的get方法,直接看Segment的get方法:
Java代码 ![]()
- V get(Object key, int hash) {
- if (count != 0) { // read-volatile
- HashEntry<K,V> e = getFirst(hash);
- while (e != null) {
- if (e.hash == hash && key.equals(e.key)) {
- V v = e.value;
- if (v != null)
- return v;
- return readValueUnderLock(e); // recheck
- }
- e = e.next;
- }
- }
- return null;
- }
get操作不需要锁。第一步是访问count变量,这是一个volatile变量,由于所有的修改操作在进行结构修改时都会在最后一步写count变量,通过这种机制保证get操作能够得到几乎最新的结构更新。对于非结构更新,也就是结点值的改变,由于HashEntry的value变量是volatile的,也能保证读取到最新的值。接下来就是对hash链进行遍历找到要获取的结点,如果没有找到,直接访回null。对hash链进行遍历不需要加锁的原因在于链指针next是final的。但是头指针却不是final的,这是通过getFirst(hash)方法返回,也就是存在table数组中的值。这使得getFirst(hash)可能返回过时的头结点,例如,当执行get方法时,刚执行完getFirst(hash)之后,另一个线程执行了删除操作并更新头结点,这就导致get方法中返回的头结点不是最新的。这是可以允许,通过对count变量的协调机制,get能读取到几乎最新的数据,虽然可能不是最新的。要得到最新的数据,只有采用完全的同步。
最后,如果找到了所求的结点,判断它的值如果非空就直接返回,否则在有锁的状态下再读一次。这似乎有些费解,理论上结点的值不可能为空,这是因为put的时候就进行了判断,如果为空就要抛NullPointerException。空值的唯一源头就是HashEntry中的默认值,因为HashEntry中的value不是final的,非同步读取有可能读取到空值。仔细看下put操作的语句:tab[index] = new HashEntry<K,V>(key, hash, first, value),在这条语句中,HashEntry构造函数中对value的赋值以及对tab[index]的赋值可能被重新排序,这就可能导致结点的值为空。这种情况应当很罕见,一旦发生这种情况,ConcurrentHashMap采取的方式是在持有锁的情况下再读一遍,这能够保证读到最新的值,并且一定不会为空值。
Java代码 ![]()
- V readValueUnderLock(HashEntry<K,V> e) {
- lock();
- try {
- return e.value;
- } finally {
- unlock();
- }
- }
另一个操作是containsKey,这个实现就要简单得多了,因为它不需要读取值:
Java代码 ![]()
- boolean containsKey(Object key, int hash) {
- if (count != 0) { // read-volatile
- HashEntry<K,V> e = getFirst(hash);
- while (e != null) {
- if (e.hash == hash && key.equals(e.key))
- return true;
- e = e.next;
- }
- }
- return false;
- }
跨段操作
有些操作需要涉及到多个段,比如说size(), containsValaue()。先来看下size()方法:
Java代码 ![]()
- public int size() {
- final Segment<K,V>[] segments = this.segments;
- long sum = 0;
- long check = 0;
- int[] mc = new int[segments.length];
- // Try a few times to get accurate count. On failure due to
- // continuous async changes in table, resort to locking.
- for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
- check = 0;
- sum = 0;
- int mcsum = 0;
- for (int i = 0; i < segments.length; ++i) {
- sum += segments[i].count;
- mcsum += mc[i] = segments[i].modCount;
- }
- if (mcsum != 0) {
- for (int i = 0; i < segments.length; ++i) {
- check += segments[i].count;
- if (mc[i] != segments[i].modCount) {
- check = -1; // force retry
- break;
- }
- }
- }
- if (check == sum)
- break;
- }
- if (check != sum) { // Resort to locking all segments
- sum = 0;
- for (int i = 0; i < segments.length; ++i)
- segments[i].lock();
- for (int i = 0; i < segments.length; ++i)
- sum += segments[i].count;
- for (int i = 0; i < segments.length; ++i)
- segments[i].unlock();
- }
- if (sum > Integer.MAX_VALUE)
- return Integer.MAX_VALUE;
- else
- return (int)sum;
- }
size方法主要思路是先在没有锁的情况下对所有段大小求和,如果不能成功(这是因为遍历过程中可能有其它线程正在对已经遍历过的段进行结构性更新),最多执行RETRIES_BEFORE_LOCK次,如果还不成功就在持有所有段锁的情况下再对所有段大小求和。在没有锁的情况下主要是利用Segment中的modCount进行检测,在遍历过程中保存每个Segment的modCount,遍历完成之后再检测每个Segment的modCount有没有改变,如果有改变表示有其它线程正在对Segment进行结构性并发更新,需要重新计算。
其实这种方式是存在问题的,在第一个内层for循环中,在这两条语句sum += segments[i].count; mcsum += mc[i] = segments[i].modCount;之间,其它线程可能正在对Segment进行结构性的修改,导致segments[i].count和segments[i].modCount读取的数据并不一致。这可能使size()方法返回任何时候都不曾存在的大小,很奇怪javadoc居然没有明确标出这一点,可能是因为这个时间窗口太小了吧。size()的实现还有一点需要注意,必须要先segments[i].count,才能segments[i].modCount,这是因为segment[i].count是对volatile变量的访问,接下来segments[i].modCount才能得到几乎最新的值(前面我已经说了为什么只是“几乎”了)。这点在containsValue方法中得到了淋漓尽致的展现:
Java代码 ![]()
- public boolean containsValue(Object value) {
- if (value == null)
- throw new NullPointerException();
- // See explanation of modCount use above
- final Segment<K,V>[] segments = this.segments;
- int[] mc = new int[segments.length];
- // Try a few times without locking
- for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
- int sum = 0;
- int mcsum = 0;
- for (int i = 0; i < segments.length; ++i) {
- int c = segments[i].count;
- mcsum += mc[i] = segments[i].modCount;
- if (segments[i].containsValue(value))
- return true;
- }
- boolean cleanSweep = true;
- if (mcsum != 0) {
- for (int i = 0; i < segments.length; ++i) {
- int c = segments[i].count;
- if (mc[i] != segments[i].modCount) {
- cleanSweep = false;
- break;
- }
- }
- }
- if (cleanSweep)
- return false;
- }
- // Resort to locking all segments
- for (int i = 0; i < segments.length; ++i)
- segments[i].lock();
- boolean found = false;
- try {
- for (int i = 0; i < segments.length; ++i) {
- if (segments[i].containsValue(value)) {
- found = true;
- break;
- }
- }
- } finally {
- for (int i = 0; i < segments.length; ++i)
- segments[i].unlock();
- }
- return found;
- }
同样注意内层的第一个for循环,里面有语句int c = segments[i].count; 但是c却从来没有被使用过,即使如此,编译器也不能做优化将这条语句去掉,因为存在对volatile变量count的读取,这条语句存在的唯一目的就是保证segments[i].modCount读取到几乎最新的值。关于containsValue方法的其它部分就不分析了,它和size方法差不多。
跨段方法中还有一个isEmpty()方法,其实现比size()方法还要简单,也不介绍了。最后简单地介绍下迭代方法,如keySet(), values(), entrySet()方法,这些方法都返回相应的迭代器,所有迭代器都继承于Hash_Iterator类(提交时居然提醒我不能包含sh It,只得加了下划线),里实现了主要的方法。其结构是:
Java代码 ![]()
- abstract class Hash_Iterator{
- int nextSegmentIndex;
- int nextTableIndex;
- HashEntry<K,V>[] currentTable;
- HashEntry<K, V> nextEntry;
- HashEntry<K, V> lastReturned;
- }
nextSegmentIndex是段的索引,nextTableIndex是nextSegmentIndex对应段中中hash链的索引,currentTable是nextSegmentIndex对应段的table。调用next方法时主要是调用了advance方法:
Java代码 ![]()
- final void advance() {
- if (nextEntry != null && (nextEntry = nextEntry.next) != null)
- return;
- while (nextTableIndex >= 0) {
- if ( (nextEntry = currentTable[nextTableIndex--]) != null)
- return;
- }
- while (nextSegmentIndex >= 0) {
- Segment<K,V> seg = segments[nextSegmentIndex--];
- if (seg.count != 0) {
- currentTable = seg.table;
- for (int j = currentTable.length - 1; j >= 0; --j) {
- if ( (nextEntry = currentTable[j]) != null) {
- nextTableIndex = j - 1;
- return;
- }
- }
- }
- }
- }
不想再多介绍了,唯一需要注意的是跳到下一个段时,一定要先读取下一个段的count变量。
这种迭代方式的主要效果是不会抛出ConcurrentModificationException。一旦获取到下一个段的table,也就意味着这个段的头结点在迭代过程中就确定了,在迭代过程中就不能反映对这个段节点并发的删除和添加,对于节点的更新是能够反映的,因为节点的值是一个volatile变量。
问数据库,回答学的mysql,问有几种引擎,回答有好几种,主要就两种
(1):MyISAM存储引擎
不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
支持3种不同的存储格式,分别是:静态表;动态表;压缩表
静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)ps:在取数据的时候,默认会把字段后面的空格去掉,如果不注意会把数据本身带的空格也会忽略。
动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能
压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
(2)InnoDB存储引擎*
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
InnoDB存储引擎的特点:支持自动增长列,支持外键约束
(3):MEMORY存储引擎
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
Hash索引优点:
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
Hash索引缺点: 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
Memory类型的存储引擎主要用于哪些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果,。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
(4)MERGE存储引擎
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
索引有了解吗
板子之前做过2年web开发培训(入门?),获得挺多学生好评,这是蛮有成就感的一件事,准备花点时间根据当时的一些备课内容整理出一系列文章出来,希望能给更多人带来帮助,这是系列文章的第一篇
注:科普文章一篇,大牛绕道
索引是做什么的?
索引用于快速找出在某个列中有一特定值的行。不使用索引,MySQL必须从第1条记录开始然后读完整个表直到找出相关的行。
表越大,花费的时间越多。如果表中查询的列有一个索引,MySQL能快速到达一个位置去搜寻到数据文件的中间,没有必要看所有数据。
大多数MySQL索引(PRIMARY KEY、UNIQUE、INDEX和FULLTEXT)在B树中存储。只是空间列类型的索引使用R-树,并且MEMORY表还支持hash索引。
索引好复杂,我该怎么理解索引,有没一个更形象点的例子?
有,想象一下,你面前有本词典,数据就是书的正文内容,你就是那个cpu,而索引,则是书的目录
索引越多越好?
大多数情况下索引能大幅度提高查询效率,但:
- 数据的变更(增删改)都需要维护索引,因此更多的索引意味着更多的维护成本
- 更多的索引意味着也需要更多的空间 (一本100页的书,却有50页目录?)
- 过小的表,建索引可能会更慢哦 :) (读个2页的宣传手册,你还先去找目录?)
索引的字段类型问题
- text类型,也可建索引(需指定长度)
- myisam存储引擎索引键长度综合不能超过1000字节
- 用来筛选的值尽量保持和索引列同样的数据类型
like 不能用索引?
- 尽量减少like,但不是绝对不可用,”xxxx%” 是可以用到索引的,
想象一下,你在看一本成语词典,目录是按成语拼音顺序建立,查询需求是,你想找以 “一”字开头的成语(”一%“),和你想找包含一字的成语(“%一%”)
- 除了like,以下操作符也可用到索引:
<,<=,=,>,>=,BETWEEN,IN
<>,not in ,!=则不行
什么样的字段不适合建索引?
- 一般来说,列的值唯一性太小(如性别,类型什么的),不适合建索引(怎样叫太小?一半说来,同值的数据超过表的百分之15,那就没必要建索引了)
- 太长的列,可以选择只建立部分索引,(如:只取前十位做索引)
- 更新非常频繁的数据不适宜建索引(怎样叫非常?意会)
一次查询能用多个索引吗?
不能
多列查询该如何建索引?
一次查询只能用到一个索引,所以 首先枪毙 a,b各建索引方案
a还是b? 谁的区分度更高(同值的最少),建谁!
当然,联合索引也是个不错的方案,ab,还是ba,则同上,区分度高者,在前
联合索引的问题?
where a = “xxx” 可以使用 AB 联合索引
where b = “xxx” 则不可 (再想象一下,这是书的目录?)
所以,大多数情况下,有AB索引了,就可以不用在去建一个A索引了
哪些常见情况不能用索引?
- like “%xxx”
- not in , !=
- 对列进行函数运算的情况(如 where md5(password) = “xxxx”)
- WHERE index=1 OR A=10
- 存了数值的字符串类型字段(如手机号),查询时记得不要丢掉值的引号,否则无法用到该字段相关索引,反之则没关系
也即
select * from test where mobile = 13711112222;
可是无法用到mobile字段的索引的哦(如果mobile是char 或 varchar类型的话)
btw,千万不要尝试用int来存手机号(为什么?自己想!要不自己试试)
覆盖索引(Covering Indexes)拥有更高效率
索引包含了所需的全部值的话,就只select 他们,换言之,只select 需要用到的字段,如无必要,可尽量避免select *
NULL 的问题
NULL会导致索引形同虚设,所以在设计表结构时应避免NULL 的存在(用其他方式表达你想表达的NULL,比如 -1?)
如何查看索引信息,如何分析是否正确用到索引?
show index from tablename;
explain select ……;
关于explain,改天可以找个时间专门写一篇入门帖,在此之前,可以尝试 google
了解自己的系统,不要过早优化!
过早优化,一直是个非常讨厌而又时刻存在的问题,大多数时候就是因为不了解自己的系统,不知道自己系统真正的承载能力
比如:几千条数据的新闻表,每天几百几千次的正文搜索,大多数时候我们可以放心的去like,而不要又去建一套全文搜索什么的,毕竟cpu还是比人脑厉害太多
分享个小案例:
曾经有个朋友找板子,说:大师帮看看,公司网站打不开
板子笑了笑:大师可不敢当啊,待我看看再说
板子花了10分钟分析了下:中小型企业站,量不大(两三万pv每天),独立服务器,数据量不大(100M不到),应该不至于太慢
某个外包团队做的项目,年久失修,彻底改造?不现实!
于是,板子花了20分钟给可以加索引的字段都加上了索引,于是,世界安静了
朋友说:另外一个哥们说,优化至少得2w外包费,你只用30分钟,看来,大师你是当之无愧了,选个最好的餐馆吧
板子:那就来点西餐吧,常熟路地铁站肯德基等你!
数据库的三大范式
第一范式
1、每一列属性都是不可再分的属性值,确保每一列的原子性
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。


如果需求知道那个省那个市并按其分类,那么显然第一个表格是不容易满足需求的,也不符合第一范式。


显然第一个表结构不但不能满足足够多物品的要求,还会在物品少时产生冗余。也是不符合第一范式的。
第二范式
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。

一个人同时订几个房间,就会出来一个订单号多条数据,这样子联系人都是重复的,就会造成数据冗余。我们应该把他拆开来。


这样便实现啦一条数据做一件事,不掺杂复杂的关系逻辑。同时对表数据的更新维护也更易操作。
第三范式
数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号--> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话)
最后:
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
线程可以简单讲讲吗,然后问线程和线程之间如何进行通信
一,介绍
本总结我对于JAVA多线程中线程之间的通信方式的理解,主要以代码结合文字的方式来讨论线程间的通信,故摘抄了书中的一些示例代码。
二,线程间的通信方式
①同步
这里讲的同步是指多个线程通过synchronized关键字这种方式来实现线程间的通信。
参考示例:

public class MyObject {
synchronized public void methodA() {
//do something....
}
synchronized public void methodB() {
//do some other thing
}
}
public class ThreadA extends Thread {
private MyObject object;
//省略构造方法
@Override
public void run() {
super.run();
object.methodA();
}
}
public class ThreadB extends Thread {
private MyObject object;
//省略构造方法
@Override
public void run() {
super.run();
object.methodB();
}
}
public class Run {
public static void main(String[] args) {
MyObject object = new MyObject();
//线程A与线程B 持有的是同一个对象:object
ThreadA a = new ThreadA(object);
ThreadB b = new ThreadB(object);
a.start();
b.start();
}
}
由于线程A和线程B持有同一个MyObject类的对象object,尽管这两个线程需要调用不同的方法,但是它们是同步执行的,比如:线程B需要等待线程A执行完了methodA()方法之后,它才能执行methodB()方法。这样,线程A和线程B就实现了 通信。
这种方式,本质上就是“共享内存”式的通信。多个线程需要访问同一个共享变量,谁拿到了锁(获得了访问权限),谁就可以执行。
②while轮询的方式
代码如下:
1 import java.util.ArrayList;
2 import java.util.List;
3
4 public class MyList {
5
6 private List<String> list = new ArrayList<String>();
7 public void add() {
8 list.add("elements");
9 }
10 public int size() {
11 return list.size();
12 }
13 }
14
15 import mylist.MyList;
16
17 public class ThreadA extends Thread {
18
19 private MyList list;
20
21 public ThreadA(MyList list) {
22 super();
23 this.list = list;
24 }
25
26 @Override
27 public void run() {
28 try {
29 for (int i = 0; i < 10; i++) {
30 list.add();
31 System.out.println("添加了" + (i + 1) + "个元素");
32 Thread.sleep(1000);
33 }
34 } catch (InterruptedException e) {
35 e.printStackTrace();
36 }
37 }
38 }
39
40 import mylist.MyList;
41
42 public class ThreadB extends Thread {
43
44 private MyList list;
45
46 public ThreadB(MyList list) {
47 super();
48 this.list = list;
49 }
50
51 @Override
52 public void run() {
53 try {
54 while (true) {
55 if (list.size() == 5) {
56 System.out.println("==5, 线程b准备退出了");
57 throw new InterruptedException();
58 }
59 }
60 } catch (InterruptedException e) {
61 e.printStackTrace();
62 }
63 }
64 }
65
66 import mylist.MyList;
67 import extthread.ThreadA;
68 import extthread.ThreadB;
69
70 public class Test {
71
72 public static void main(String[] args) {
73 MyList service = new MyList();
74
75 ThreadA a = new ThreadA(service);
76 a.setName("A");
77 a.start();
78
79 ThreadB b = new ThreadB(service);
80 b.setName("B");
81 b.start();
82 }
83 }
在这种方式下,线程A不断地改变条件,线程ThreadB不停地通过while语句检测这个条件(list.size()==5)是否成立 ,从而实现了线程间的通信。但是这种方式会浪费CPU资源。之所以说它浪费资源,是因为JVM调度器将CPU交给线程B执行时,它没做啥“有用”的工作,只是在不断地测试 某个条件是否成立。就类似于现实生活中,某个人一直看着手机屏幕是否有电话来了,而不是: 在干别的事情,当有电话来时,响铃通知TA电话来了。关于线程的轮询的影响,可参考:JAVA多线程之当一个线程在执行死循环时会影响另外一个线程吗?
这种方式还存在另外一个问题:
轮询的条件的可见性问题,关于内存可见性问题,可参考:JAVA多线程之volatile 与 synchronized 的比较中的第一点“一,volatile关键字的可见性”
线程都是先把变量读取到本地线程栈空间,然后再去再去修改的本地变量。因此,如果线程B每次都在取本地的 条件变量,那么尽管另外一个线程已经改变了轮询的条件,它也察觉不到,这样也会造成死循环。
③wait/notify机制
代码如下:
1 import java.util.ArrayList;
2 import java.util.List;
3
4 public class MyList {
5
6 private static List<String> list = new ArrayList<String>();
7
8 public static void add() {
9 list.add("anyString");
10 }
11
12 public static int size() {
13 return list.size();
14 }
15 }
16
17
18 public class ThreadA extends Thread {
19
20 private Object lock;
21
22 public ThreadA(Object lock) {
23 super();
24 this.lock = lock;
25 }
26
27 @Override
28 public void run() {
29 try {
30 synchronized (lock) {
31 if (MyList.size() != 5) {
32 System.out.println("wait begin "
33 + System.currentTimeMillis());
34 lock.wait();
35 System.out.println("wait end "
36 + System.currentTimeMillis());
37 }
38 }
39 } catch (InterruptedException e) {
40 e.printStackTrace();
41 }
42 }
43 }
44
45
46 public class ThreadB extends Thread {
47 private Object lock;
48
49 public ThreadB(Object lock) {
50 super();
51 this.lock = lock;
52 }
53
54 @Override
55 public void run() {
56 try {
57 synchronized (lock) {
58 for (int i = 0; i < 10; i++) {
59 MyList.add();
60 if (MyList.size() == 5) {
61 lock.notify();
62 System.out.println("已经发出了通知");
63 }
64 System.out.println("添加了" + (i + 1) + "个元素!");
65 Thread.sleep(1000);
66 }
67 }
68 } catch (InterruptedException e) {
69 e.printStackTrace();
70 }
71 }
72 }
73
74 public class Run {
75
76 public static void main(String[] args) {
77
78 try {
79 Object lock = new Object();
80
81 ThreadA a = new ThreadA(lock);
82 a.start();
83
84 Thread.sleep(50);
85
86 ThreadB b = new ThreadB(lock);
87 b.start();
88 } catch (InterruptedException e) {
89 e.printStackTrace();
90 }
91 }
92 }
线程A要等待某个条件满足时(list.size()==5),才执行操作。线程B则向list中添加元素,改变list 的size。
A,B之间如何通信的呢?也就是说,线程A如何知道 list.size() 已经为5了呢?
这里用到了Object类的 wait() 和 notify() 方法。
当条件未满足时(list.size() !=5),线程A调用wait() 放弃CPU,并进入阻塞状态。---不像②while轮询那样占用CPU
当条件满足时,线程B调用 notify()通知 线程A,所谓通知线程A,就是唤醒线程A,并让它进入可运行状态。
这种方式的一个好处就是CPU的利用率提高了。
但是也有一些缺点:比如,线程B先执行,一下子添加了5个元素并调用了notify()发送了通知,而此时线程A还执行;当线程A执行并调用wait()时,那它永远就不可能被唤醒了。因为,线程B已经发了通知了,以后不再发通知了。这说明:通知过早,会打乱程序的执行逻辑。
④管道通信就是使用java.io.PipedInputStream 和 java.io.PipedOutputStream进行通信
具体就不介绍了。分布式系统中说的两种通信机制:共享内存机制和消息通信机制。感觉前面的①中的synchronized关键字和②中的while轮询 “属于” 共享内存机制,由于是轮询的条件使用了volatile关键字修饰时,这就表示它们通过判断这个“共享的条件变量“是否改变了,来实现进程间的交流。
而管道通信,更像消息传递机制,也就是说:通过管道,将一个线程中的消息发送给另一个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号