美团点评西安站凉面筋
原链接:https://www.nowcoder.com/discuss/113872
目录
多线程的使用场景(这块答的不好,扯到数据库插入上了,答非所问了)
项目中用的设计模式,我说单例模式、适配器模式,然后问单例模式特点,为什么使用单例模式
画一下项目中模块划分(这儿应该是要求展示后台逻辑,我画了流程逻辑他说不是这个意思)
项目中插入大量数据,当达到很大量的时候怎么保证插入效率(这块没准备到)
项目中如果有人做提交结果作弊怎么检测应对(这块没想好,他的意思是要对问题有全面的分析,从检测方法到处理方法到成本收益分析……)
代码实现提取URL中传的参数和值,保存键值对
URL可分为三类。即 无参数,有一个参数,有多个参数。
http://www.jiangxiaobai.com
http://www.jiangxiaobai.com?name=xiaobai
http://www.jiangxiaobai.com?name=xiaobai&age=17参数跟在字符"?"之后,参数之间用“&”隔开,参数名和值则用“=”连接。
解决方法如下:
1、判断URL中是否含有字符“?”。无,则结束并提示不包含参数和对应值;有,获取参数和对应值部分再进行拆分。
url.indexOf("?")>-1 //判断是否含有字符“?”;
2、获取参数和对应值部分
var paraStr=url.split("?")[1];注:url.split: https://blog.csdn.net/strawqqhat/article/details/88422207
3、结合字符"&"将各个参数分离
paraItems=paraStr.split("&");4、遍历步骤三的结果,对每一项进行拆分,得到参数和对应值,最后以键值对的形式存放。
通过window.locatiion获取当前页面URL,window.location.search获取以“?”开头的参数名和对应值拼接而成的字符串。
var url="www.baidu.com?name=baibai"
function getPara(url){
if(url.indexOf("?")?-1){
var result=[];
var paraStr=url.split("?")[1];
var paraItems=paraStr.split("&");
for(var i=0;i<paraItems.length;i++){
var paraKey=paraItems[i].split("=")[0];
var paraValue=paraItems[i].split("=")[1];
result.push({
key:paraKey,
value:paraValue;
})
}
console.log(result);
}else{
console.log("该URL中不含参数");
}
}
代码实现N的平方根,不考虑四舍五入取平方根
注:二分法和迭代
首先是二分法
#define eps 0.00001
float SqrtByDichotomy(float n)
{
if(n<0){
return -1.0;
}else{
float low,up,mid,last;
low=0,up=(n>1?n:1);
mid=(low+up)/2;
do{
if(mid*mid>n)
up=mid;
else
low=mid;
last=mid;
mid=(up+low)/2;
}while(fabsf(mid-last)>eps);
return mid;
}
}接下来是迭代法
double Sqr(double){
double x=a,y=0.0;
while(fabs(x-y)>0.00001){
y=x;
x=0.5*(x+a/x);
}
return x;
}
Java的集合有哪些,HashMap原理
https://blog.csdn.net/strawqqhat/article/details/88425952
HashMap是线程安全的吗,怎么让他线程安全
HashMap 不是线程安全的,往往在 写程序时需要通过一些方法来回避,其实JDK原生的提供了两种方法让HashMap支持线程安全。
方法一:通过Collections.synchronizedMap()返回一个新的Map,这个新的Map就是线程安全的。这个要求大家习惯基于接口编程,因为返回的并不是HashMap,而是一个Map的实现。
方法二:重新改写了HashMap,具体的可以查看java.util.concurrent.ConcurrentHashMap。这个方法比方法一有了很大的改进。
下面对这两种方法从各个角度进行分析和比较。
实现原理;锁机制的不同;如何得到/释放锁;优缺点
1、实现原理
方法一原理:通过Collections.synchronizedMap()来封装所有不安全的HashMap方法,就连toString,hashCode都进行了封装。封装的关键点有两处:1)使用了经典的synchronized来进行互斥;2)使用了代理模式new了一个新的类,这个类同样实现了Map接口。
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable{
//use serialVersionUID from JDK 1.2.2 for interoperability
private static final long serialVersionUID = 1989273814489L;
private final Map<K,V> m;//Backing Map;
final Object mutex;//Object on which to synchronize;
SynchronizedMap(Map<K,V> m){
if(m == null)throw new NullPointerException();
this.m = m;
mutex = this;
}
SynchronizedMap(Map<K,V> m,Object mutex){
this.m = m;
this.mutex = mutex;
}
public int size(){
synchronized(mutex){return m.size();}
}
//节省空间,删除了大量的类似代码
public String toString(){
synchronized(mutex) {return m.toString();}
}
private void writeObject(ObjectOutputStream s)throws IOException{
synchronized(mutex){s.defaultWriteObject();}
}
}方法二原理:重新写了HashMap,比较大的改变有如下几点:使用了新的锁机制(可以理解为乐观锁),把HashMap进行了拆分,拆分成了多个独立的块,这样在高并发情况下减少了锁冲突的可能。
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
2、锁机制的不同
方法一使用的是synchronized方法,是一种悲观锁,在进入之前需要获得锁,确保独享当前对象,然后作相应的修改、读取。
方法二使用的是乐观锁,只有在需要修改对象时,比较和之前的值是否被人修改了,如果被其他线程修改了那么就返回失败。锁的实现,使用的是NonfairSync.这个特性要确保修改的原子性,互斥性,无法在JDK这个级别得到解决,JDK在此次需要调用JNI方法,而JNI则调用CAS指令来确保原子性和互斥性。
当如果多个线程恰好操作到ConcurrentHashMap同一个segment上面,那么只会有一个线程得到运行,其他的线程会被LockSupport.park(),稍后执行完成后,会自动挑选一个线程来执行LockSupport.unpark().
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
3、如何得到/释放锁
得到锁:
方法一:在HashMap上面,synchronized锁住的是对象(不是Class),所以第一个申请的得到锁,其他线程将进入阻塞,等待唤醒。
方法二:检查AbstractQueuedSynchronized,state,如果为0则得到锁,或者申请者已经得到锁则也能再次得到锁,并且state也加一。
释放锁:
都是得到锁的逆操作,并且使用正确,二种方法都是自动选取一个队列中的线程得到锁以获得CPU资源。
4、优缺点
方法一:
优点:代码实现十分简答,一看就懂;
缺点:从锁的角度来看,方法一直接使用了锁住方法,基本上是锁住了尽可能大的代码块,性能会比较差。
方法二:
优点:需要互斥的代码段比较少,性能会比较好。ConcurrentHashMap把整个Map切分成了多个块,发生锁碰撞的几率大大降低,性能会比较好。
缺点:代码实现稍微复杂些。
ArrayList和LinkedList
ArrayList和Vector使用了数组的实现,可以认为ArrayList或者Vector封装了对内部数组的操作,比如向数组中添加,删除,插入新的元素或者数据的扩展和重定向。
LinkedList使用了循环双向链表数据结构。与基于数组ArrayList相比,这是两种截然不同的实现技术,这也决定了它们将适用于完全不同的工作场景。
LinkedList链表由一系列表项连接而成。一个表项总是包含3个部分:元素内容,前驱表和后驱表,如图所示:

在下图展示了一个包含3个元素的LinkedList的各个表项间的连接关系。在JDK的实现中,无论LikedList是否为空,链表内部都有一个header表项,它既表示链表的开始,也表示链表的结尾。表项header的后驱表项便是链表中第一个元素,表项header的前驱表项便是链表中最后一个元素。

下面以增加和删除元素为例比较ArrayList和LinkedList的不同之处:
(1)增加元素到列表尾端:
在ArrayList中增加元素到队列尾端的代码如下:
public boolean add(E e){
ensureCapacity(size+1);//确保内部数组有足够的空间
elementData[size++]=e;//将元素加入到数组的末尾,完成添加
return true;
}
ArrayList中add()方法的性能决定于ensureCapacity()方法。ensureCapacity()的实现如下:

public vod ensureCapacity(int minCapacity){
modCount++;
int oldCapacity=elementData.length;
if(minCapacity>oldCapacity){ //如果数组容量不足,进行扩容
Object[] oldData=elementData;
int newCapacity=(oldCapacity*3)/2+1; //扩容到原始容量的1.5倍
if(newCapacitty<minCapacity) //如果新容量小于最小需要的容量,则使用最小
//需要的容量大小
newCapacity=minCapacity ; //进行扩容的数组复制
elementData=Arrays.copyof(elementData,newCapacity);
}
}
可以看到,只要ArrayList的当前容量足够大,add()操作的效率非常高的。只有当ArrayList对容量的需求超出当前数组大小时,才需要进行扩容。扩容的过程中,会进行大量的数组复制操作。而数组复制时,最终将调用System.arraycopy()方法,因此add()操作的效率还是相当高的。
LinkedList 的add()操作实现如下,它也将任意元素增加到队列的尾端:
public boolean add(E e){
addBefore(e,header);//将元素增加到header的前面
return true;
}
其中addBefore()的方法实现如下:
private Entry<E> addBefore(E e,Entry<E> entry){
Entry<E> newEntry = new Entry<E>(e,entry,entry.previous);
newEntry.provious.next=newEntry;
newEntry.next.previous=newEntry;
size++;
modCount++;
return newEntry;
}
可见,LinkeList由于使用了链表的结构,因此不需要维护容量的大小。从这点上说,它比ArrayList有一定的性能优势,然而,每次的元素增加都需要新建一个Entry对象,并进行更多的赋值操作。在频繁的系统调用中,对性能会产生一定的影响。
(2)增加元素到列表任意位置
除了提供元素到List的尾端,List接口还提供了在任意位置插入元素的方法:void add(int index,E element);
由于实现的不同,ArrayList和LinkedList在这个方法上存在一定的性能差异,由于ArrayList是基于数组实现的,而数组是一块连续的内存空间,如果在数组的任意位置插入元素,必然导致在该位置后的所有元素需要重新排列,因此,其效率相对会比较低。
以下代码是ArrayList中的实现:
public void add(int index,E element){
if(index>size||index<0)
throw new IndexOutOfBoundsException(
"Index:"+index+",size: "+size);
ensureCapacity(size+1);
System.arraycopy(elementData,index,elementData,index+1,size-index);
elementData[index] = element;
size++;
}
可以看到每次插入操作,都会进行一次数组复制。而这个操作在增加元素到List尾端的时候是不存在的,大量的数组重组操作会导致系统性能低下。并且插入元素在List中的位置越是靠前,数组重组的开销也越大。
而LinkedList此时显示了优势:
public void add(int index,E element){
addBefore(element,(index==size?header:entry(index)));
}
可见,对LinkedList来说,在List的尾端插入数据与在任意位置插入数据是一样的,不会因为插入的位置靠前而导致插入的方法性能降低。
(3)删除任意位置元素
对于元素的删除,List接口提供了在任意位置删除元素的方法:
public E remove(int index);
对ArrayList来说,remove()方法和add()方法是雷同的。在任意位置移除元素后,都要进行数组的重组。ArrayList的实现如下:
public E remove(int index){
RangeCheck(index);
modCount++;
E oldValue=(E) elementData[index];
int numMoved=size-index-1;
if(numMoved>0)
System.arraycopy(elementData,index+1,elementData,index,numMoved);
elementData[--size]=null;
return oldValue;
}
可以看到,在ArrayList的每一次有效的元素删除操作后,都要进行数组的重组。并且删除的位置越靠前,数组重组时的开销越大。
public E remove(int index){
return remove(entry(index));
}
private Entry<E> entry(int index){
if(index<0 || index>=size)
throw new IndexOutBoundsException("Index:"+index+",size:"+size);
Entry<E> e= header;
if(index<(size>>1)){//要删除的元素位于前半段
for(int i=0;i<=index;i++)
e=e.next;
}else{
for(int i=size;i>index;i--)
e=e.previous;
}
return e;
}
在LinkedList的实现中,首先要通过循环找到要删除的元素。如果要删除的位置处于List的前半段,则从前往后找;若其位置处于后半段,则从后往前找。因此无论要删除较为靠前或者靠后的元素都是非常高效的;但要移除List中间的元素却几乎要遍历完半个List,在List拥有大量元素的情况下,效率很低。
(4)容量参数
容量参数是ArrayList和Vector等基于数组的List的特有性能参数。它表示初始化的数组大小。当ArrayList所存储的元素数量超过其已有大小时。它便会进行扩容,数组的扩容会导致整个数组进行一次内存复制。因此合理的数组大小有助于减少数组扩容的次数,从而提高系统性能。
public ArrayList(){
this(10);
}
public ArrayList (int initialCapacity){
super();
if(initialCapacity<0)
throw new IllegalArgumentException("Illegal Capacity:"+initialCapacity)
this.elementData=new Object[initialCapacity];
}
ArrayList提供了一个可以制定初始数组大小的构造函数:
public ArrayList(int initialCapacity)
现以构造一个拥有100万元素的List为例,当使用默认初始化大小时,其消耗的相对时间为125ms左右,当直接制定数组大小为100万时,构造相同的ArrayList仅相对耗时16ms。
(5)遍历列表
遍历列表操作是最常用的列表操作之一,在JDK1.5之后,至少有3中常用的列表遍历方式:forEach操作,迭代器和for循环。
String tmp;
long start=System.currentTimeMills(); //ForEach
for(String s:list){
tmp=s;
}
System.out.println("foreach spend:"+(System.currentTimeMills()-start));
start = System.currentTimeMills();
for(Iterator<String> it=list.iterator();it.hasNext();){
tmp=it.next();
}
System.out.println("Iterator spend;"+(System.currentTimeMills()-start));
start=System.currentTimeMills();
int size=;list.size();
for(int i=0;i<size;i++){
tmp=list.get(i);
}
System.out.println("for spend;"+(System.currentTimeMills()-start));
构造一个拥有100万数据的ArrayList和等价的LinkedList,使用以上代码进行测试,测试结果的相对耗时如下表所示: 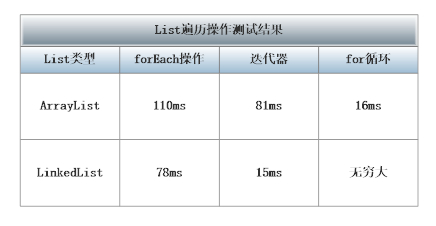
可以看到,最简便的ForEach循环并没有很好的性能表现,综合性能不如普通的迭代器,而是用for循环通过随机访问遍历列表时,ArrayList表项很好,但是LinkedList的表现却无法让人接受,甚至没有办法等待程序的结束。这是因为对LinkedList进行随机访问时,总会进行一次列表的遍历操作。性能非常差,应避免使用。
String、StringBuffer
Java中的String,StringBuilder,StringBuffer三者的区别
最近在学习Java的时候,遇到了这样一个问题,就是String,StringBuilder以及StringBuffer这三个类之间有什么区别呢,自己从网上搜索了一些资料,有所了解了之后在这里整理一下,便于大家观看,也便于加深自己学习过程中对这些知识点的记忆,如果哪里有误,恳请指正。
这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面。
- 首先说运行速度,或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String最慢的原因:
String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但后两者的对象是变量,是可以更改的。以下面一段代码为例:
1 String str="abc"; 2 System.out.println(str); 3 str=str+"de"; 4 System.out.println(str);
如果运行这段代码会发现先输出“abc”,然后又输出“abcde”,好像是str这个对象被更改了,其实,这只是一种假象罢了,JVM对于这几行代码是这样处理的,首先创建一个String对象str,并把“abc”赋值给str,然后在第三行中,其实JVM又创建了一个新的对象也名为str,然后再把原来的str的值和“de”加起来再赋值给新的str,而原来的str就会被JVM的垃圾回收机制(GC)给回收掉了,所以,str实际上并没有被更改,也就是前面说的String对象一旦创建之后就不可更改了。所以,Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程,所以执行速度很慢。
而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。
另外,有时候我们会这样对字符串进行赋值
1 String str="abc"+"de";
2 StringBuilder stringBuilder=new StringBuilder().append("abc").append("de");
3 System.out.println(str);
4 System.out.println(stringBuilder.toString());
这样输出结果也是“abcde”和“abcde”,但是String的速度却比StringBuilder的反应速度要快很多,这是因为第1行中的操作和
String str="abcde";
是完全一样的,所以会很快,而如果写成下面这种形式
1 String str1="abc"; 2 String str2="de"; 3 String str=str1+str2;
那么JVM就会像上面说的那样,不断的创建、回收对象来进行这个操作了。速度就会很慢。
2. 再来说线程安全
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
3. 总结一下
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
多线程的使用场景(这块答的不好,扯到数据库插入上了,答非所问了)
- 常见的浏览器、Web服务(现在写的web是中间件帮你完成了线程的控制),web处理请求,各种专用服务器(如游戏服务器)
- servlet多线程
- FTP下载,多线程操作文件
- 数据库用到的多线程
- 分布式计算
- tomcat,tomcat内部采用多线程,上百个客户端访问同一个WEB应用,tomcat接入后就是把后续的处理扔给一个新的线程来处理,这个新的线程最后调用我们的servlet程序,比如doGet或者dpPost方法
- 后台任务:如定时向大量(100W以上)的用户发送邮件;定期更新配置文件、任务调度(如quartz),一些监控用于定期信息采集
- 自动作业处理:比如定期备份日志、定期备份数据库
- 异步处理:如发微博、记录日志
- 页面异步处理:比如大批量数据的核对工作(有10万个手机号码,核对哪些是已有用户)
- 数据库的数据分析(待分析的数据太多),数据迁移
- 多步骤的任务处理,可根据步骤特征选用不同个数和特征的线程来协作处理,多任务的分割,由一个主线程分割给多个线程完成
- desktop应用开发,一个费时的计算开个线程,前台加个进度条显示
- swing编程
你理解的接口和抽象类的区别
接口和抽象类的区别?
接口(interface)和抽象类(abstract class)是支持抽象类定义的两种机制。
接口是公开的,不能有私有的方法或变量,接口中的所有方法都没有方法体,通过关键字interface实现。
抽象类是可以有私有方法或私有变量的,通过把类或者类中的方法声明为abstract来表示一个类是抽象类,被声明为抽象的方法不能包含方法体。子类实现方法必须含有相同的或者更低的访问级别(public->protected->private)。抽象类的子类为父类中所有抽象方法的具体实现,否则也是抽象类。
接口可以被看作是抽象类的变体,接口中所有的方法都是抽象的,可以通过接口来间接的实现多重继承。接口中的成员变量都是static final类型,由于抽象类可以包含部分方法的实现,所以,在一些场合下抽象类比接口更有优势。
相同点:
(1)都不能被实例化
(2)接口的实现类或抽象类的子类都只有实现了接口或抽象类中的方法后才能实例化。
不同点:
(1)接口只有定义,不能有方法的实现,而抽象类可以有定义与实现,方法可在抽象类中实现。
(2)实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。
(3)接口强调特定功能的实现,而抽象类强调所属关系。
(4)接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。
(5)接口被用于常用的功能,便于日后维护和添加删除,而抽象类更倾向于充当公共类的角色,不适用于日后重新对立面的代码修改。功能需要累积时用抽象类,不需要累积时用接口。
Java反射的理解
什么是JVM,Java的虚拟机,java之所以能跨平台就是因为这个东西,你可以理解成一个进程,程序,只不过他的作用是用来跑你的代码的。上图是java的内存模型,我们关注的点,一个方法区,一个栈,一个堆,初学的时候老师不深入的话只告诉你java的内存分为堆和栈,易懂点吧!
假如你写了一段代码:Object o=new Object(); 运行起来后
首先JVM会启动,你的代码会编译成一个.class文件,然后被类加载器加载进jvm的内存中,你的类Object加载到方法区中,创建了Object类的class对象到堆中,注意这个不是new出来的对象,而是类的类型对象,每个类只有一个class对象,作为方法区类的数据结构的接口。jvm创建对象前,会先检查类是否加载,寻找类对应的class对象,若加载好,则为你的对象分配内存,初始化也就是代码:new Object()。
上面的流程就是你自己写好的代码扔给jvm去跑,跑完就over了,jvm关闭,你的程序也停止了。
上面的程序对象是自己new的,程序相当于写死了给jvm去跑。假如一个服务器上突然遇到某个请求哦要用到某个类,哎呀但没加载进jvm,是不是要停下来自己写段代码,new一下,哦启动一下服务器。
反射是什么呢?当我们的程序在运行时,需要动态的加载一些类这些类可能之前用不到所以不用加载到jvm,而是在运行时根据需要才加载,这样的好处对于服务器来说不言而喻,
举个例子我们的项目底层有时是用mysql,有时用oracle,需要动态地根据实际情况加载驱动类,这个时候反射就有用了,假设 com.java.dbtest.myqlConnection,com.java.dbtest.oracleConnection这两个类我们要用,这时候我们的程序就写得比较动态化,通过Class tc = Class.forName("com.java.dbtest.TestConnection");通过类的全类名让jvm在服务器中找到并加载这个类,而如果是oracle则传入的参数就变成另一个了。这时候就可以看到反射的好处了,这个动态性就体现出java的特性了!举多个例子,大家如果接触过spring,会发现当你配置各种各样的bean时,是以配置文件的形式配置的,你需要用到哪些bean就配哪些,spring容器就会根据你的需求去动态加载,你的程序就能健壮地运行。
实例说明反射是如何起作用的
首先准备两个很简单的业务类
package reflection;
public class Service1{
public void doService1(){
System.out.println("业务方法1")
}
}
1
2
3
4
5
6
package reflection;
public class Service2{
public void doService2(){
System.out.println("业务方法2")
}
}
1
2
3
4
5
6
非反射的方式 切换 不同的业务方法
package reflection;
public class Test{
public static void main(String[] args){
// new Service1().doService1();
new Service2().doService2();
}
}
1
2
3
4
5
6
7
当需要从第一个业务方法切换到第二个业务方法的时候,使用非反射方式,必须修改代码,并且重新编译运行,才可以达到效果
反射方式
使用反射方式,首先准备一个配置文件,就叫做spring.txt吧, 放在src目录下。 里面存放的是类的名称,和要调用的方法名。在测试类Test中,首先取出类名称和方法名,然后通过反射去调用这个方法。当需要从调用第一个业务方法,切换到调用第二个业务方法的时候,不需要修改一行代码,也不需要重新编译,只需要修改配置文件spring.txt,再运行即可。
spring.txt
class = reflection.Service1
method = doService1
1
2
3
package com.java.test;
import java.io.File;
import java.io.FileInputStream;
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
import java.util.Properties;
public class Test {
public static void main(String[] args) throws Exception {
File springConfigFile = new File("spring.txt");
Properties springConfig = new Properties();
springConfig.load(new FileInputStream(springConfigFile));
String className = (String)springConfig.get("class");
String methodName = (String) springConfig.get("method");
// 根据类名名称创建类对象
Class clazz = Class.forName(className);
// 根据方法名称获取方法
Method method = clazz.getMethod(methodName);
// 获取构造器
Constructor c = clazz.getConstructor();
// 根据构造器,构造出方法
Object service = c.newInstance();
// 调用对象的指定方法
method.invoke(service);
}
}
使用这个例子,可以较好得理解反射的一个应用场景。
这也是Spring框架的最基本的原理,只是它做的更丰富,安全,健壮
Linux进程管理相关命令(这块答得不好我说现查现用。。)
https://www.cnblogs.com/skyofbitbit/p/3651749.html
项目中用的设计模式,我说单例模式、适配器模式,然后问单例模式特点,为什么使用单例模式
画一下项目中模块划分(这儿应该是要求展示后台逻辑,我画了流程逻辑他说不是这个意思)
项目中插入大量数据,当达到很大量的时候怎么保证插入效率(这块没准备到)
使用jdbc向数据库插入100000条记录,分别使用statement,PreparedStatement,及PreparedStatement+批处理3种方式进行测试:
-
public void exec(Connection conn){ -
try { -
//开始时间 -
Long beginTime = System.currentTimeMillis(); -
//设置手动提交 -
conn.setAutoCommit(false); -
Statement st = conn.createStatement(); -
for(int i=0;i<100000;i++){ -
String sql="insert into t1(id) values ("+i+")"; -
st.executeUpdate(sql); -
} -
//结束时间 -
Long endTime = System.currentTimeMillis(); -
System.out.println("st:"+(endTime-beginTime)/1000+"秒");//计算时间 -
st.close(); -
conn.close(); -
} catch (SQLException e) { -
e.printStackTrace(); -
} -
}
//2.使用PreparedStatement对象
-
public void exec2(Connection conn){ -
try { -
Long beginTime = System.currentTimeMillis(); -
conn.setAutoCommit(false);//手动提交 -
PreparedStatement pst = conn.prepareStatement("insert into t1(id) values (?)"); -
for(int i=0;i<100000;i++){ -
pst.setInt(1, i); -
pst.execute(); -
} -
conn.commit(); -
Long endTime = System.currentTimeMillis(); -
System.out.println("pst:"+(endTime-beginTime)/1000+"秒");//计算时间 -
pst.close(); -
conn.close(); -
} catch (SQLException e) { -
e.printStackTrace(); -
} -
}
//3.使用PreparedStatement + 批处理
-
public void exec3(Connection conn){ -
try { -
conn.setAutoCommit(false); -
Long beginTime = System.currentTimeMillis(); -
//构造预处理statement -
PreparedStatement pst = conn.prepareStatement("insert into t1(id) values (?)"); -
//1万次循环 -
for(int i=1;i<=100000;i++){ -
pst.setInt(1, i); -
pst.addBatch(); -
//每1000次提交一次 -
if(i%1000==0){//可以设置不同的大小;如50,100,500,1000等等 -
pst.executeBatch(); -
conn.commit(); -
pst.clearBatch(); -
} -
} -
Long endTime = System.currentTimeMillis(); -
System.out.println("pst+batch:"+(endTime-beginTime)/1000+"秒"); -
pst.close(); -
conn.close(); -
} catch (SQLException e) { -
e.printStackTrace(); -
} -
}
在Oracle 10g中测试,结果:
1.使用statement 耗时142秒;
2.使用PreparedStatement 耗时56秒;
3.使用PreparedStatement + 批处理耗时:
a.50条插入一次,耗时5秒;
b.100条插入一次,耗时2秒;
c.1000条以上插入一次,耗时1秒;
通过以上可以得出结论,在使用jdbc大批量插入数据时,明显使用第三种方式(PreparedStatement + 批处理)性能更优。
-------------------------------------------------------------------------------------------------------------------------------
- 普通方式处理大量数据的insert时,处理速度相当慢。
- */
- PreparedStatement ps = null;
- //循环10000次
- for(int i = 0; i < 100000; i++) {
- ps = con.prepareStatement(sql);
- ps.executeUpdate();
- }
- 方法二:通过addBatch()的方式,将数据缓存在对象里面,通过最后执行executeBatch();方法提交,因此速度会快很多!
- */
- PreparedStatement ps = con.prepareStatement(sql);
- for(int i = 0; i < 100000; i++) {
- ps.setString(1, "1");
- ps.setString(2, "2");
- ps.addBatch();
- }
- ps.executeBatch();
项目中从数据库的海量数据中做查询,如何优化查询提升速度
项目中如果有人做提交结果作弊怎么检测应对(这块没想好,他的意思是要对问题有全面的分析,从检测方法到处理方法到成本收益分析……)
在参与实际项目中,当 MySQL 表的数据量达到百万级时,普通的 SQL 查询效率呈直线下降,而且如果 where 中的查询条件较多时,其查询速度无法容忍。想想可知,假如我们查询淘宝的一个订单详情,如果查询时间高达几十秒,这么高的查询延时,任何用户都会抓狂。因此如何提高 SQL 语句查询效率,显得十分重要。
查询速度慢的原因
1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
2、I/O 吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足
5、网络速度慢
6、查询出的数据量过大(可采用多次查询,其他的方法降低数据量)
7、锁或者死锁(这是查询慢最常见的问题,是程序设计的缺陷)
8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列
10、查询语句不好,没有优化
30 种 SQL 查询语句的优化方法:
1、应尽量避免在 where 子句中使用 != 或者 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
2、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
|
1 |
select id from t where num is null; |
可以在 num 上设置默认值 0 ,确保表中 num 列没有 null 值,然后这样查询:
|
1 |
select id from t where num = 0; |
3、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
4、尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
|
1 |
select id from t where num = 10 or num = 20; |
可以这样查询:
|
1 2 3 |
select id from t where num = 10 union all select id from t where num = 20; |
5、下面的查询也将导致全表扫描:(不能前置百分号)
|
1 |
select id from t where name like '%abc%'; |
若要提高效率,可以考虑全文检索。
6、in 和 not in 也要慎用,否则会导致全表扫描,如:
|
1 |
select id from t where num in(1, 2, 3); |
对于连续的数值,能用 between 就不要用 in 了:
|
1 |
select id from t where num between 1 and 3; |
|
1 2 3 4 5 |
select xx,phone FROM send a JOIN ( select '13891030091' phone union select '13992085916' ………… UNION SELECT '13619100234' ) b on a.Phone=b.phone --替代下面 很多数据隔开的时候 in('13891030091','13992085916','13619100234'…………) |
7、如果在 where 子句中使用参数,也会导致全表扫描。因为 SQL 只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择到运行时;它必须在编译时进行选择。然而,如果在编译时简历访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
|
1 |
select id from t where num = @num; |
可以改为强制查询使用索引:
|
1 |
select id from t with(index(索引名)) where num = @num; |
8、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
|
1 |
select id from t where num/2 = 100; |
应改为:
|
1 |
select id from t where num = 100 * 2; |
9、应尽量避免在 where 子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
|
1 2 |
select id from t where substring(name, 1, 3) = ’abc’–name; //以abc开头的id select id from t where datediff(day,createdate,’2005-11-30′) = 0–’2005-11-30′; //生成的id |
应改为:
|
1 2 |
select id from t where name like ‘abc%’ select id from t where createdate >= ’2005-11-30′ and createdate < ’2005-12-1′; |
10、不要在 where 子句中的 “=” 左边进行函数,算术运算或者其他表达式运算,否则系统将可能无法正确使用索引。
11、在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12、不要些一些没有意义的查询,如需要生成一个空表结构:
|
1 |
select col1,col2 into #t from t where 1=0; |
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
|
1 |
create table #t(…) |
13、很多时候用 exists 代替 in 是一个好的选择:
|
1 |
select num from a where num in(select num from b); |
用下面的语句替换:
|
1 |
select num from a where exists(select 1 from b where num=a.num); |
14、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
16、应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18、尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19、任何地方都不要使用 select * from t ,用具体的字段列表代替 *,不要返回用不到的任何字段。
20、尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21、避免频繁创建和删除临时表,以减少系统表资源的消耗。
22、临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
23、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先 create table,然后 insert。
24、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26、使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27、与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28、在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
30、尽量避免大事务操作,提高系统并发能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号