cvte 面经 挂在hr
目录
8 redis里面定义key的时候,加入时间戳的时候,过期如何消除key的实现
9 如果消费者往消息队列放数据由于网络原因消息队列的ack没有收到,
消费者会重新发送,如何解决。如果消息队列发送到消费者的时候ack由于某些原因没有收到
13 mysql的数据结构,为什么是b+树,为什么不用其他数据结构来进行多路查询
16 用abc三个列作为索引 select * where b=1 and c=1 如何运行的
17 用abc三个列作为索引,where a=1 or group by c会不会走索引
18 用abc三个列作为索引 select b where c = 1 会不会用到辅助索引,用到怎么样 不用的又怎么样
19 两个int数 比如 5,6 求出二进制中对应位置全是1出现的个数
1 线程池
在一个应用程序中,我们需要多次使用线程,也就意味着我们需要多次创建并销毁线程。而创建并销毁线程的过程中势必会消耗内存。而在Java中,内存资源是及其宝贵的,所以就提出了线程池的概念。
线程池:java中开辟出了一种管理线程的概念,这个概念叫做线程池,从概念以及应用场景中,我们可以看出,线程池的好处,就是可以方便的管理线程,也可以减少内存的消耗。那么我们应该如何创建一个线程池呢,Java中已经提供了创建线程池的一个类:Executor。而我们创建时,一般使用它的子类:ThreadPoolExecutor。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
这是其中最重要的一个构造方法,这个方法决定了创建出来的线程池的各种属性,下面依靠一张图来更好的理解线程池和这几个参数。
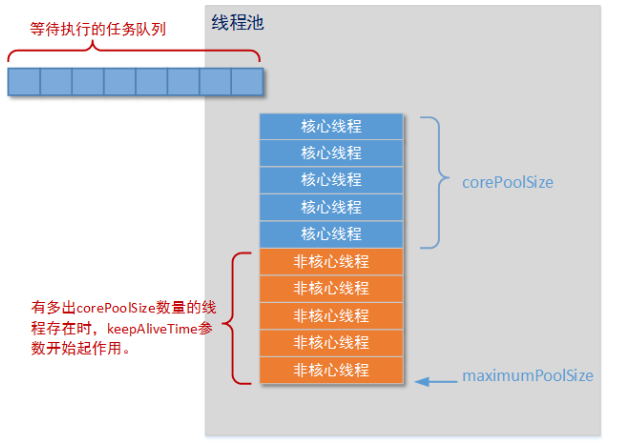
由图中我们可以看出,线程池中的corePoolSize就是线程池中的核心线程数量,这几个核心线程在没有用的时候也不会被回收,maximumPoolSize就是线程池中可以容纳的最大线程的数量,而 keepAliveTime就是线程池中除了核心线程之外的其他的最长可以保留的事件,因为在线程池中,除了核心线程 即使在无任务的情况下也不能被清除,其余的都是由存活时间的,意思就是非核心线程可以保留的最长的空闲时间,而util就是计算这个时间的一个单位,workQueue就是等待队列 ,任务可以储存在任务队列中等待被执行,执行的是FIFIO(先进先出)原则。threadFactory就是创建线程的线程工厂,最后一个handler是一种拒绝策略,我们可以在任务满了之后拒绝执行某些任务。
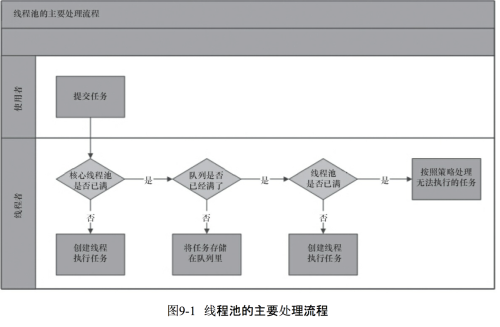
由图我们可以看出任务进来是首先进行判断,判断核心线程是否处于空闲状态,如果不是,核心线程就先执行任务,如果核心线程已满则判断任务队列是否有地方存放该任务,如果有就将任务保存到任务队列中,等待执行,如果满了就判断最大可容纳的线程数,如果超出这个数量就创建非核心线程执行任务,如果超出了,就调用handler实现拒绝策略。
handler的拒绝策略:
有四种:第一种AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
第二种DisCardPolicy:不执行新任务,也不抛出异常
第三种DisCardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
第四种CallerRunsPolicy:直接调用execute来执行当前任务
四种常见的线程池:
CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要是创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。
SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。
SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的场景。
FixedThreadPool:定长的线程池,有核心线程的核心线程即为最大的线程数量,没有非核心线程。
2 单例模式(如何用内部类实现)
public class Singleton
{
private Singleton(){}
statc{
System.out.println("This is astatic code block!");
}
private static class SingletonHandler{
private static Singleton singleton = new Singleton();
static{
System.out.println("this is innerClass'static code block");
}
}
public static Singleton getInstance(){
return SingletonHandler.singleton;
}
public static void display(){
System.out.println("This is display!");
}
}
public class SingletonTest
{
private SingletonTest(){}
static class MyThread extends Thread {
@Override
public void run()
{
super.run();
System.out.println("Thread running_"+Singleton.getInstance());
}
}
public static void main(String[] args)
{
MyThread th1 = new MyThread();
MyThread th2 = new MyThread();
MyThread th3 = new MyThread();
/*@1
th1.start();
th2.start();
th3.start();
*/
/*@2
Singleton.display();
*/
}
}
2. 运行结果及解释
情况一(注释 @1代码,注释 @2的代码)
//运行结果 为空解释:外部类和内部类都没有加载
情况二(执行 @1代码)
//运行结果
This's static code block!
This's innerClass's static code block
Thread running_com.singleton.Singleton@4f19c297
Thread running_com.singleton.Singleton@4f19c297
Thread running_com.singleton.Singleton@4f19c297解释: 外部类Singleton和内部类SingletonHandler都加载了,因为他们的静态代码块加载了
情况三(注释 @1代码,执行 @2的代码)
//运行结果
This's static code block!
This's display!解释:外部类加载了,而内部类没有加载,因为加载了类,就一定会执行静态代码块
3. 结论
终上实验:内部类SingletonHandler只有在getInstance()方法第一次调用的时候才会被加载(实现了延迟加载效果),而且其加载过程是线程安全的(实现线程安全)。内部类加载的时候只实例化了一次instance
3 spring中用到的设计模式
spring中常用的设计模式达到九种,我们举例说明:
第一种:简单工厂
又叫做静态工厂方法(StaticFactory Method)模式,但不属于23种GOF设计模式之一。
简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。如下配置,就是在 HelloItxxz 类中创建一个 itxxzBean。
<beans>
<bean id="singletonBean" class="com.itxxz.HelloItxxz">
<constructor-arg>
<value>Hello! 这是singletonBean!value>
</constructor-arg>
</ bean>
<bean id="itxxzBean" class="com.itxxz.HelloItxxz"
singleton="false">
<constructor-arg>
<value>Hello! 这是itxxzBean! value>
</constructor-arg>
</bean>
</beans>
第二种:工厂方法(Factory Method)
通常由应用程序直接使用new创建新的对象,为了将对象的创建和使用相分离,采用工厂模式,即应用程序将对象的创建及初始化职责交给工厂对象。
一般情况下,应用程序有自己的工厂对象来创建bean.如果将应用程序自己的工厂对象交给Spring管理,那么Spring管理的就不是普通的bean,而是工厂Bean。
螃蟹就以工厂方法中的静态方法为例讲解一下:
import java.util.Random;
public class StaticFactoryBean {
public static Integer createRandom() {
return new Integer(new Random().nextInt());
}
}
建一个config.xm配置文件,将其纳入Spring容器来管理,需要通过factory-method指定静态方法名称
<bean id="random"
class="example.chapter3.StaticFactoryBean" factory-method="createRandom" //createRandom方法必须是static的,才能找到 scope="prototype"
/>
测试:
public static void main(String[] args) {
//调用getBean()时,返回随机数.如果没有指定factory-method,会返回StaticFactoryBean的实例,即返回工厂Bean的实例 XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource("config.xml")); System.out.println("我是IT学习者创建的实例:"+factory.getBean("random").toString());
}
第三种:单例模式(Singleton)
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没有从构造器级别去控制单例,这是因为spring管理的是是任意的java对象。
核心提示点:Spring下默认的bean均为singleton,可以通过singleton=“true|false” 或者 scope=“?”来指定
第四种:适配器(Adapter)
在Spring的Aop中,使用的Advice(通知)来增强被代理类的功能。Spring实现这一AOP功能的原理就使用代理模式(1、JDK动态代理。2、CGLib字节码生成技术代理。)对类进行方法级别的切面增强,即,生成被代理类的代理类, 并在代理类的方法前,设置拦截器,通过执行拦截器重的内容增强了代理方法的功能,实现的面向切面编程。
Adapter类接口:Target
public interface AdvisorAdapter {
boolean supportsAdvice(Advice advice);
MethodInterceptor getInterceptor(Advisor advisor);
} MethodBeforeAdviceAdapter类,Adapter
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable {
public boolean supportsAdvice(Advice advice) {
return (advice instanceof MethodBeforeAdvice);
}
public MethodInterceptor getInterceptor(Advisor advisor) {
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
return new MethodBeforeAdviceInterceptor(advice);
}
}
第五种:包装器(Decorator)
在我们的项目中遇到这样一个问题:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。我们以往在spring和hibernate框架中总是配置一个数据源,因而sessionFactory的dataSource属性总是指向这个数据源并且恒定不变,所有DAO在使用sessionFactory的时候都是通过这个数据源访问数据库。但是现在,由于项目的需要,我们的DAO在访问sessionFactory的时候都不得不在多个数据源中不断切换,问题就出现了:如何让sessionFactory在执行数据持久化的时候,根据客户的需求能够动态切换不同的数据源?我们能不能在spring的框架下通过少量修改得到解决?是否有什么设计模式可以利用呢?
首先想到在spring的applicationContext中配置所有的dataSource。这些dataSource可能是各种不同类型的,比如不同的数据库:Oracle、SQL Server、MySQL等,也可能是不同的数据源:比如apache 提供的org.apache.commons.dbcp.BasicDataSource、spring提供的org.springframework.jndi.JndiObjectFactoryBean等。然后sessionFactory根据客户的每次请求,将dataSource属性设置成不同的数据源,以到达切换数据源的目的。
spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。基本上都是动态地给一个对象添加一些额外的职责。
第六种:代理(Proxy)
为其他对象提供一种代理以控制对这个对象的访问。 从结构上来看和Decorator模式类似,但Proxy是控制,更像是一种对功能的限制,而Decorator是增加职责。
spring的Proxy模式在aop中有体现,比如JdkDynamicAopProxy和Cglib2AopProxy。
第七种:观察者(Observer)
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
spring中Observer模式常用的地方是listener的实现。如ApplicationListener。
第八种:策略(Strategy)
定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
spring中在实例化对象的时候用到Strategy模式
在SimpleInstantiationStrategy中有如下代码说明了策略模式的使用情况: 
第九种:模板方法(Template Method)
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。Template Method使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
Template Method模式一般是需要继承的。这里想要探讨另一种对Template Method的理解。spring中的JdbcTemplate,在用这个类时并不想去继承这个类,因为这个类的方法太多,但是我们还是想用到JdbcTemplate已有的稳定的、公用的数据库连接,那么我们怎么办呢?我们可以把变化的东西抽出来作为一个参数传入JdbcTemplate的方法中。但是变化的东西是一段代码,而且这段代码会用到JdbcTemplate中的变量。怎么办?那我们就用回调对象吧。在这个回调对象中定义一个操纵JdbcTemplate中变量的方法,我们去实现这个方法,就把变化的东西集中到这里了。然后我们再传入这个回调对象到JdbcTemplate,从而完成了调用。这可能是Template Method不需要继承的另一种实现方式吧。
以下是一个具体的例子:
JdbcTemplate中的execute方法 
JdbcTemplate执行execute方法 
4 spring的aop原理,类别,区别常用哪一个
AOP:即面向切面编程。是对OOP(面向对象编程)的一种补充,专门用于处理一些具有横切性质的服务。常常用于日志输出,安全控制等。
上面说到是对OOP的一种补充,具体补充的是什么呢?考虑一种情况,如果我们需要在所有方法执行前打印一句日志,按照OOP的处理思想,我们需要在每个业务方法开始时加入一些语句,但是我们辛辛苦苦加完以后,如果又要求在这句日志打印后再打印一句,那是不是又要加一遍?这时候你一定会想到在某个类中编写一个日志打印方法,该方法执行这些日志打印操作,然后在每个业务方法执行之前加入这句语句调用,这就是面向对象编程思想。但是如果我们要求在业务方法结束时在打印一些日志呢,是不是还要去每个业务方法结束时加一遍?这样始终不是办法,而且我们总是在改业务方法,在业务方法里面掺杂了太多的其他操作,侵入性太高。
这时AOP就起到作用了,我们可以编写一个切面类(Aspect),在其中的方法中编写横切逻辑(如打印日志),然后通过配置或者注解的方式来声明该横切逻辑起作用的位置。
实现技术:
AOP(这里的AOP指的是面向切面编程思想,而不是Spring AOP)主要的的实现技术主要有Spring AOP和AspectJ。
1、AspectJ的底层技术。
AspectJ的底层技术是静态代理,即用一种AspectJ支持的特定语言编写切面,通过一个命令来编译,生成一个新的代理类,该代理类增强了业务类,这是在编译时增强,相对于下面说的运行时增强,编译时增强的性能更好。
2、Spring AOP
Spring AOP采用的是动态代理,在运行期间对业务方法进行增强,所以不会生成新类,对于动态代理技术,Spring AOP提供了对JDK动态代理的支持以及CGLib的支持。
JDK动态代理只能为接口创建动态代理实例,而不能对类创建动态代理。需要获得被目标类的接口信息(应用Java的反射技术),生成一个实现了代理接口的动态代理类(字节码),再通过反射机制获得动态代理类的构造函数,利用构造函数生成动态代理类的实例对象,在调用具体方法前调用invokeHandler方法来处理。
CGLib动态代理需要依赖asm包,把被代理对象类的class文件加载进来,修改其字节码生成子类。
但是Spring AOP基于注解配置的情况下,需要依赖于AspectJ包的标准注解,但是不需要额外的编译以及AspectJ的织入器,而基于XML配置不需要。
5 redis可以存储的类型
String 类型操作
string是redis最基本的类型,而且string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象
$redis->set('key','TK');
$redis->set('number','1');
$redis->setex('key',5,'TK'); //设置有效期为5秒的键值
$redis->psetex('key',5000,'TK'); //设置有效期为5000毫秒(同5秒)的键值
$redis->setnx('key','XK'); //若键值存在返回false 不存在返回true
$redis->delete('key'); 删除键值 可以传入数组 array('key1','key2')删除多个键
$redis->getSet('key','XK'); //将键key的值设置为XK, 并返回这个键值原来的值TK
$ret = $redis->multi() //批量事务处理,不保证处理数据的原子性
->set('key1', 'val1')
->get('key1')
->setnx('key', 'val2')
->get('key2')
->exec();
$redis->watch('key'); // 监控键key 是否被其他客户端修改
如果KEY在调用watch()和exec()之间被修改,exec失败
function f($redis, $chan, $msg) { //频道订阅
switch($chan) {
case 'chan-1':
echo $msg;
break;
case 'chan-2':
echo $msg;
break;
case 'chan-2':
echo $msg;
break;
}
}
$redis->subscribe(array('chan-1', 'chan-2', 'chan-3'), 'f'); // subscribe to 3 chans
$redis->publish('chan-1', 'hello, world!'); // send message.
$redis->exists('key'); //验证键是否存在,存在返回true
$redis->incr('number'); //键值加1
$redis->incrby('number',-10); //键值加减10
$redis->incrByFloat('number', +/- 1.5); //键值加减小数
$redis->decr('number'); // 键值减1
$redis->decrBy('number',10); // 键值减10
$mget = $redis->mget(array('number','key')); // 批量获取键值,返回一个数组
$redis->mset(array('key0' => 'value0', 'key1' => 'value1')); // 批量设置键值
$redis->msetnx(array('key0' => 'value0', 'key1' => 'value1'));
// 批量设置键值,类似将setnx()方法批量操作
$redis->append('key', '-Smudge'); //原键值TK,将值追加到键值后面,键值为TK-Smudge
$redis->getRange('key', 0, 5); // 键值截取从0位置开始到5位置结束
$redis->getRange('key', -6, -1); // 字符串截取从-6(倒数第6位置)开始到-1(倒数第1位置)结束
$redis->setRange('key', 0, 'Smudge');
// 键值中替换字符串,0表示从0位置开始
有多少个字符替换多少位置,其中汉字占2个位置
$redis->strlen('key'); //键值长度
$redis->getBit('key');
$redis->setBit('key');
list链表操作
$redis->delete('list-key'); // 删除链表
$redis->lPush('list-key', 'A'); //插入链表头部/左侧,返回链表长度
$redis->rPush('list-key', 'B'); //插入链表尾部/右侧,返回链表长度
$redis->lPushx('list-key', 'C');
// 插入链表头部/左侧,链表不存在返回0,存在即插入成功,返回当前链表长度
$redis->rPushx('list-key', 'C');
// 插入链表尾部/右侧,链表不存在返回0,存在即插入成功,返回当前链表长度
$redis->lPop('list-key'); //返回LIST顶部(左侧)的VALUE ,后入先出(栈)
$redis->rPop('list-key'); //返回LIST尾部(右侧)的VALUE ,先入先出(队列)
$redis->blPop();
$redis->brPop();
$redis->lSize('list-key');
// 如果是链表则返回链表长度,空链表返回0
若不是链表或者不为空,则返回false ,判断非链表 " === false "
$redis->lGet('list-key',-1); // 通过索引获取链表元素 0获取左侧一个 -1获取最后一个
$redis->lSet('list-key', 0, 'X'); //0位置元素替换为 X
$redis->lRange('list-key', 0, 3);
//链表截取 从0开始 3位置结束 ,结束位置为-1 获取开始位置之后的全部
$redis->lTrim('list-key', 0, 1); // 截取链表(不可逆) 从0索引开始 1索引结束
$redis->lRem('list-key', 'C', 2); //链表从左开始删除元素2个C
$redis->lInsert('list-key', Redis::BEFORE, 'C', 'X');
// 在C元素前面插入X , Redis::AfTER(表示后面插入)
链表不存在则插入失败 返回0 若元素不存在返回-1
$redis->rpoplpush('list-key', 'list-key2');
//从源LIST的最后弹出一个元素
并且把这个元素从目标LIST的顶部(左侧)压入目标LIST。
$redis->brpoplpush();
//rpoplpush的阻塞版本,这个版本有第三个参数用于设置阻塞时间
即如果源LIST为空,那么可以阻塞监听timeout的时间,如果有元素了则执行操作。
Set集合类型
set无序集合 不允许出现重复的元素 服务端可以实现多个 集合操作
$redis->sMembers('key'); //获取容器key中所有元素
$redis->sAdd('key' , 'TK');
// (从左侧插入,最后插入的元素在0位置),集合中已经存在TK 则返回false
不存在添加成功 返回true
$redis->sRem('key' , 'TK'); // 移除容器中的TK
$redis->sMove('key','key1','TK'); //将容易key中的元素TK 移动到容器key1 操作成功返回TRUE
$redis->sIsMember('key','TK'); //检查VALUE是否是SET容器中的成员
$redis->sCard('key'); //返回SET容器的成员数
$redis->sPop('key'); //随机返回容器中一个元素,并移除该元素
$redis->sRandMember('key');//随机返回容器中一个元素,不移除该元素
$redis->sInter('key','key1');
// 返回两个集合的交集 没有交集返回一个空数组,若参数只有一个集合,则返回集合对应的完整的数组
$redis->sInterStore('store','key','key1'); //将集合key和集合key1的交集 存入容器store 成功返回1
$redis->sUnion('key','key1'); //集合key和集合key1的并集 注意即使多个集合有相同元素 只保留一个
$redis->sUnionStore('store','key','key1');
//集合key和集合key1的并集保存在集合store中, 注意即使多个集合有相同元素 只保留一个
$redis->sDiff('key','key1','key2'); //返回数组,该数组元素是存在于key集合而不存在于集合key1 key2
Zset数据类型
**(stored set) 和 set 一样是字符串的集合,不同的是每个元素都会关联一个 double 类型的 score
redis的list类型其实就是一个每个子元素都是string类型的双向链表。**
$redis->zAdd('tkey', 1, 'A');
// 插入集合tkey中,A元素关联一个分数,插入成功返回1
同时集合元素不可以重复, 如果元素已经存在返回 0
$redis->zRange('tkey',0,-1); // 获取集合元素,从0位置 到 -1 位置
$redis->zRange('tkey',0,-1, true);
// 获取集合元素,从0位置 到 -1 位置, 返回一个关联数组 带分数
array([A] => 0.01,[B] => 0.02,[D] => 0.03) 其中小数来自zAdd方法第二个参数
$redis->zDelete('tkey', 'B'); // 移除集合tkey中元素B 成功返回1 失败返回 0
$redis->zRevRange('tkey', 0, -1); // 获取集合元素,从0位置 到 -1 位置,数组按照score降序处理
$redis->zRevRange('tkey', 0, -1,true);
// 获取集合元素,从0位置 到 -1 位置,数组按照score降序处理 返回score关联数组
$redis->zRangeByScore('tkey', 0, 0.2,array('withscores' => true));
//获取几个tkey中score在区间[0,0.2]元素 ,score由低到高排序,
元素具有相同的score,那么会按照字典顺序排列 , withscores 控制返回关联数组
$redis->zRangeByScore('tkey', 0.1, 0.36, array('withscores' => TRUE, 'limit' => array(0, 1)));
//其中limit中 0和1 表示取符合条件集合中 从0位置开始,向后扫描1个 返回关联数组
$redis->zCount('tkey', 2, 10); // 获取tkey中score在区间[2, 10]元素的个数
$redis->zRemRangeByScore('tkey', 1, 3); // 移除tkey中score在区间[1, 3](含边界)的元素
$redis->zRemRangeByRank('tkey', 0, 1);
//默认元素score是递增的,移除tkey中元素 从0开始到-1位置结束
$redis->zSize('tkey'); //返回存储在key对应的有序集合中的元素的个数
$redis->zScore('tkey', 'A'); // 返回集合tkey中元素A的score值
$redis->zRank('tkey', 'A');
// 返回集合tkey中元素A的索引值
z集合中元素按照score从低到高进行排列 ,即最低的score index索引为0
$redis->zIncrBy('tkey', 2.5, 'A'); // 将集合tkey中元素A的score值 加 2.5
$redis->zUnion('union', array('tkey', 'tkey1'));
// 将集合tkey和集合tkey1元素合并于集合union , 并且新集合中元素不能重复
返回新集合的元素个数, 如果元素A在tkey和tkey1都存在,则合并后的元素A的score相加
$redis->zUnion('ko2', array('k1', 'k2'), array(5, 2));
// 集合k1和集合k2并集于k02 ,array(5,1)中元素的个数与子集合对应,然后 5 对应k1
k1每个元素score都要乘以5 ,同理1对应k2,k2每个元素score乘以1
然后元素按照递增排序,默认相同的元素score(SUM)相加
$redis->zUnion('ko2', array('k1', 'k2'), array(10, 2),'MAX');
// 各个子集乘以因子之后,元素按照递增排序,相同的元素的score取最大值(MAX)
也可以设置MIN 取最小值
$redis->zInter('ko1', array('k1', 'k2'));
// 集合k1和集合k2取交集于k01 ,且按照score值递增排序
如果集合元素相同,则新集合中的元素的score值相加
$redis->zInter('ko1', array('k1', 'k2'), array(5, 1));
//集合k1和集合k2取交集于k01 ,array(5,1)中元素的个数与子集合对应,然后 5 对应k1
k1每个元素score都要乘以5 ,同理1对应k2,k2每个元素score乘以1
,然后元素score按照递增排序,默认相同的元素score(SUM)相加
$redis->zInter('ko1', array('k1', 'k2'), array(5, 1),'MAX');
// 各个子集乘以因子之后,元素score按照递增排序,相同的元素score取最大值(MAX)
也可以设置MIN 取最小值
Hash数据类型
redis hash是一个string类型的field和value的映射表.它的添加,删除操作都是O(1)(平均).hash特别适合用于存储对象。
$redis->hSet('h', 'name', 'TK'); // 在h表中 添加name字段 value为TK
$redis->hSetNx('h', 'name', 'TK');
// 在h表中 添加name字段 value为TK 如果字段name的value存在返回false 否则返回 true
$redis->hGet('h', 'name'); // 获取h表中name字段value
$redis->hLen('h'); // 获取h表长度即字段的个数
$redis->hDel('h','email'); // 删除h表中email 字段
$redis->hKeys('h'); // 获取h表中所有字段
$redis->hVals('h'); // 获取h表中所有字段value
$redis->hGetAll('h'); // 获取h表中所有字段和value 返回一个关联数组(字段为键值)
$redis->hExists('h', 'email'); //判断email 字段是否存在与表h 不存在返回false
$redis->hSet('h', 'age', 28);
$redis->hIncrBy('h', 'age', -2);
// 设置h表中age字段value加(-2) 如果value是个非数值 则返回false 否则,返回操作后的value
$redis->hIncrByFloat('h', 'age', -0.33);
// 设置h表中age字段value加(-2.6) 如果value是个非数值 则返回false 否则
返回操作后的value(小数点保留15位)
$redis->hMset('h', array('score' => '80', 'salary' => 2000)); // 表h 批量设置字段和value
$redis->hMGet('h', array('score','salary')); // 表h 批量获取字段的value
6 redis的sortset底层实现原理
https://blog.csdn.net/linyu19872008/article/details/72403962
7 redis里面的定时清理key如何实现的
用Redis时,有用到EXPIRE、PEXPIRE、SETEX之类命令去设置key的过期时间。从2.8版开始可以去做简单的定时器服务。
过期策略有三种:立即过期、定时过期、访问过期(惰性过期)。看源码可以发现Redis并没有采用立即过期的策略,而是采用定时过期和访问过期混合方式。使用立即过期的话,Linux环境下在Redis进程里会有很多timerfd,在几十万个key这种数量级开始,对CPU是很大的负担。
在redis.h文件里有redisDb结构体
typedef struct redisDb{
dict *dict;
dict *rxpires;
......
}expiires这属性是存放当前db有过期时间的键,使用hash数据表结构。
定期删除策略:
代码在redis.c的activeExpireCycle函数,需要穿个type参数,用以区分使用“快速模式”还是正常模式。在正常模式下会遍历每个编号下的库,然后最多随机获取20个带过期时间的key(20是ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP的默认值),倘若key太多则直接return了。接着调用redis.c/activeEcpireCycleTryExpire函数尝试去删除它,能删除成功则再发送expired的pub通知给订阅者即可。定期删除的定时时长是100ms。
惰性过期:
代码分布在所有读写命令里,如set、get、TTL、SADD、HGET等。每次调用这些命令的实际执行前都会调用db.c/ecpireIfNeeded函数来删除过期键,在删除之前也会发送expired的pub通知。
EXPIRE/PEXPIRE/SETEX的作用?
这几个命令的真正作用是设置过期时间,如EXPIRE命令的处理在db.c/expireCommand开始,然后将过期时间单位从秒转换成毫秒,接着判断是否存在从节点,最后传播删除了的expired key(pub del)。在主节点则设置过期时间,是在宏代码里去设置值(联合体结构),最后在pub expire的通知。
8 redis里面定义key的时候,加入时间戳的时候,过期如何消除key的实现
项目中有个接口要频繁调用查询数据库中的数据,为了降低数据库的压力,所以把一部分记录先缓存在redis中,对redis中的数据设置了期限。今天无意间发现一个问题,使用dbsize查询出来的数量,比实际缓存量要高一部分。用
redis-cli keys '*'|wc -l- 1
- 1
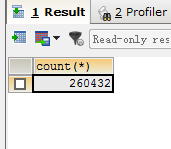
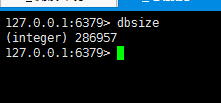
获取到的数据和实际情况是一样的。如下面两图:
对比发现,redis中key的总量为286957,比数据库中的264032高出了20000多个!为什么会这样呢?查找程序原因,并没有发现逻辑问题。查找redis相关资料,发现原来是redis对过期键处理机制导致的误差。
dbsize返回的是包含过期键的总数,所以造成了误差!结合查找的资料,拿来一起分享。
Redis对于过期键有三种清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
被动删除
只有key被操作时(如GET),REDIS才会被动检查该key是否过期,如果过期则删除之并且返回NIL。
1、这种删除策略对CPU是友好的,删除操作只有在不得不的情况下才会进行,不会对其他的expire key上浪费无谓的CPU时间。
2、但是这种策略对内存不友好,一个key已经过期,但是在它被操作之前不会被删除,仍然占据内存空间。如果有大量的过期键存在但是又很少被访问到,那会造成大量的内存空间浪费。expireIfNeeded(redisDb *db, robj *key)函数位于src/db.c。
但仅是这样是不够的,因为可能存在一些key永远不会被再次访问到,这些设置了过期时间的key也是需要在过期后被删除的,我们甚至可以将这种情况看作是一种内存泄露—-无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
主动删除
先说一下时间事件,对于持续运行的服务器来说, 服务器需要定期对自身的资源和状态进行必要的检查和整理, 从而让服务器维持在一个健康稳定的状态, 这类操作被统称为常规操作(cron job)
在 Redis 中, 常规操作由 redis.c/serverCron 实现, 它主要执行以下操作
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等。
- 清理数据库中的过期键值对。
- 对不合理的数据库进行大小调整。
- 关闭和清理连接失效的客户端。
- 尝试进行 AOF 或 RDB 持久化操作。
- 如果服务器是主节点的话,对附属节点进行定期同步。
- 如果处于集群模式的话,对集群进行定期同步和连接测试。
Redis 将 serverCron 作为时间事件来运行, 从而确保它每隔一段时间就会自动运行一次, 又因为 serverCron 需要在 Redis 服务器运行期间一直定期运行, 所以它是一个循环时间事件: serverCron 会一直定期执行,直到服务器关闭为止。
在 Redis 2.6 版本中, 程序规定 serverCron 每秒运行 10 次, 平均每 100 毫秒运行一次。 从 Redis 2.8 开始, 用户可以通过修改 hz选项来调整 serverCron 的每秒执行次数, 具体信息请参考 redis.conf 文件中关于 hz 选项的说明也叫定时删除,这里的“定期”指的是Redis定期触发的清理策略,由位于src/redis.c的activeExpireCycle(void)函数来完成。
serverCron是由redis的事件框架驱动的定位任务,这个定时任务中会调用activeExpireCycle函数,针对每个db在限制的时间REDIS_EXPIRELOOKUPS_TIME_LIMIT内迟可能多的删除过期key,之所以要限制时间是为了防止过长时间 的阻塞影响redis的正常运行。这种主动删除策略弥补了被动删除策略在内存上的不友好。
因此,Redis会周期性的随机测试一批设置了过期时间的key并进行处理。测试到的已过期的key将被删除。典型的方式为,Redis每秒做10次如下的步骤:
- 随机测试100个设置了过期时间的key
- 删除所有发现的已过期的key
- 若删除的key超过25个则重复步骤1
这是一个基于概率的简单算法,基本的假设是抽出的样本能够代表整个key空间,redis持续清理过期的数据直至将要过期的key的百分比降到了25%以下。这也意味着在任何给定的时刻已经过期但仍占据着内存空间的key的量最多为每秒的写操作量除以4.
Redis-3.0.0中的默认值是10,代表每秒钟调用10次后台任务。
除了主动淘汰的频率外,Redis对每次淘汰任务执行的最大时长也有一个限定,这样保证了每次主动淘汰不会过多阻塞应用请求,以下是这个限定计算公式:
-
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* CPU max % for keys collection */ -
... -
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
hz调大将会提高Redis主动淘汰的频率,如果你的Redis存储中包含很多冷数据占用内存过大的话,可以考虑将这个值调大,但Redis作者建议这个值不要超过100。我们实际线上将这个值调大到100,观察到CPU会增加2%左右,但对冷数据的内存释放速度确实有明显的提高(通过观察keyspace个数和used_memory大小)。
可以看出timelimit和server.hz是一个倒数的关系,也就是说hz配置越大,timelimit就越小。换句话说是每秒钟期望的主动淘汰频率越高,则每次淘汰最长占用时间就越短。这里每秒钟的最长淘汰占用时间是固定的250ms(1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/100),而淘汰频率和每次淘汰的最长时间是通过hz参数控制的。
从以上的分析看,当redis中的过期key比率没有超过25%之前,提高hz可以明显提高扫描key的最小个数。假设hz为10,则一秒内最少扫描200个key(一秒调用10次*每次最少随机取出20个key),如果hz改为100,则一秒内最少扫描2000个key;另一方面,如果过期key比率超过25%,则扫描key的个数无上限,但是cpu时间每秒钟最多占用250ms。
当REDIS运行在主从模式时,只有主结点才会执行上述这两种过期删除策略,然后把删除操作”del key”同步到从结点。
maxmemory
当前已用内存超过maxmemory限定时,触发主动清理策略
- volatile-lru:只对设置了过期时间的key进行LRU(默认值)
- allkeys-lru : 删除lru算法的key
- volatile-random:随机删除即将过期key
- allkeys-random:随机删除
- volatile-ttl : 删除即将过期的
- noeviction : 永不过期,返回错误
当mem_used内存已经超过maxmemory的设定,对于所有的读写请求,都会触发redis.c/freeMemoryIfNeeded(void)函数以清理超出的内存。注意这个清理过程是阻塞的,直到清理出足够的内存空间。所以如果在达到maxmemory并且调用方还在不断写入的情况下,可能会反复触发主动清理策略,导致请求会有一定的延迟。
清理时会根据用户配置的maxmemory-policy来做适当的清理(一般是LRU或TTL),这里的LRU或TTL策略并不是针对redis的所有key,而是以配置文件中的maxmemory-samples个key作为样本池进行抽样清理。
maxmemory-samples在redis-3.0.0中的默认配置为5,如果增加,会提高LRU或TTL的精准度,redis作者测试的结果是当这个配置为10时已经非常接近全量LRU的精准度了,并且增加maxmemory-samples会导致在主动清理时消耗更多的CPU时间,建议:
- 尽量不要触发maxmemory,最好在mem_used内存占用达到maxmemory的一定比例后,需要考虑调大hz以加快淘汰,或者进行集群扩容。
- 如果能够控制住内存,则可以不用修改maxmemory-samples配置;如果Redis本身就作为LRU cache服务(这种服务一般长时间处于maxmemory状态,由Redis自动做LRU淘汰),可以适当调大maxmemory-samples。
这里提一句,实际上redis根本就不会准确的将整个数据库中最久未被使用的键删除,而是每次从数据库中随机取5个键并删除这5个键里最久未被使用的键。上面提到的所有的随机的操作实际上都是这样的,这个5可以用过redis的配置文件中的maxmemeory-samples参数配置。
Replication link和AOF文件中的过期处理
为了获得正确的行为而不至于导致一致性问题,当一个key过期时DEL操作将被记录在AOF文件并传递到所有相关的slave。也即过期删除操作统一在master实例中进行并向下传递,而不是各salve各自掌控。这样一来便不会出现数据不一致的情形。当slave连接到master后并不能立即清理已过期的key(需要等待由master传递过来的DEL操作),slave仍需对数据集中的过期状态进行管理维护以便于在slave被提升为master会能像master一样独立的进行过期处理。
8 如何保持200万条数据的实时排名前10名(缓存)
9 如果消费者往消息队列放数据由于网络原因消息队列的ack没有收到,
消费者会重新发送,如何解决。如果消息队列发送到消费者的时候ack由于某些原因没有收到
如何解决消费者重复收到数据的情况
10 volatile关键字作用,底层如何实现的
11 mysql的引擎以及区别
12 mysql的锁
13 mysql的数据结构,为什么是b+树,为什么不用其他数据结构来进行多路查询
14 mysql的辅助索引
15 mysql的联合索引
16 用abc三个列作为索引 select * where b=1 and c=1 如何运行的
17 用abc三个列作为索引,where a=1 or group by c会不会走索引
18 用abc三个列作为索引 select b where c = 1 会不会用到辅助索引,用到怎么样 不用的又怎么样
19 两个int数 比如 5,6 求出二进制中对应位置全是1出现的个数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号