南京小米二面 全程58分钟
目录
2.tcp的拥塞控制怎么实现的;ps:感觉小米的面试必问tcp
5.学的是java是吧,那么你把java的object类有哪些方法都说一下。
8.你知道的集合都讲一下。9.哪个集合可以实现stack,queue,deque(linkedlist)
1.tcp了解吗,说一下滑动窗口。
PAR效率低(超时重传)。优化此缺点,比如我让发送的每一个包都有一个id,接收端必须对每一个包进行确认,这样设备一次多发送几个片段而不必等待ACK,同时接收端也要告诉它能够收多少,这样发送端发起来也有个限制。当然还需要保证顺序性,不要乱序,对于乱序的状况,我们可以允许等待一定情况下的乱序,不如说先缓存提前到的数据,然后去等待需要的数据,如果一定时间没来就drop掉,来保证顺序性。
在TCP/IP协议栈中,滑动窗口的引入可以解决此问题,先来看从概念上数据分为哪些类
1. Sent and Acknowledged:这些数据表示已经发送成功并已经被确认的数据,比如图中的前31个bytes,这些数据其实的位置是在窗口之外了,因为窗口内顺序最低的被确认之后,要移除窗口,实际上是窗口进行合拢,同时打开接收新的带发送的数据
2. Send But Not Yet Acknowledged:这部分数据称为发送但没有被确认,数据被发送出去,没有收到接收端的ACK,认为并没有完成发送,这个属于窗口内的数据。
3. Not Sent,Recipient Ready to Receive:这部分是尽快发送的数据,这部分数据已经被加载到缓存中,也就是窗口中了,等待发送,其实这个窗口是完全有接收方告知的,接收方告知还是能够接受这些包,所以发送方需要尽快的发送这些包
4. Not Sent,Recipient Not Ready to Receive: 这些数据属于未发送,同时接收端也不允许发送的,因为这些数据已经超出了发送端所接收的范围
对于接收端也是有一个接收窗口的,类似发送端,接收端的数据有3个分类,因为接收端并不需要等待ACK所以它没有类似的接收并确认了的分类,情况如下
1. Received and ACK Not Send to Process:这部分数据属于接收了数据但是还没有被上层的应用程序接收,也是被缓存在窗口内
2. Received Not ACK: 已经接收,但是还没有回复ACK,这些包可能输属于Delay ACK的范畴了
3. Not Received:有空位,还没有被接收的数据。
发送窗口和可用窗口
对于发送方来讲,窗口内的包括两部分,就是发送窗口(已经发送了,但是没有收到ACK),可用窗口,接收端允许发送但是没有发送的那部分称为可用窗口。
1. Send Window : 20个bytes 这部分值是有接收方在三次握手的时候进行通告的,同时在接收过程中也不断的通告可以发送的窗口大小,来进行适应
2. Window Already Sent: 已经发送的数据,但是并没有收到ACK。
滑动窗口原理:TCP并不是每一个报文段都会回复ACK的,可能会对两个报文段发送一个ACK,也可能会对多个报文段发送一个ACK,比如说发送方有1/2/3 3个报文段,先发送了2,3两个报文段但是接收方期望收到1报文段,这个时候2,3也将被丢弃,如果报文1来了,那么会发送一个ACK对这三个报文进行一次确认。
举一个例子来说明一下滑动窗口的原理:
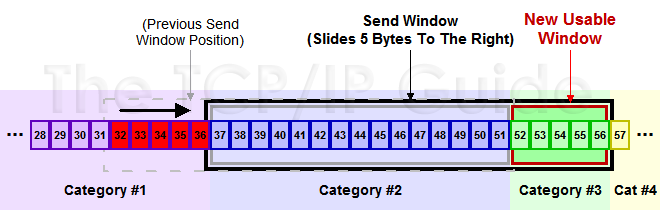
1. 假设32~45 这些数据,是上层Application发送给TCP的,TCP将其分成四个Segment来发往internet
2. seg1 32~34 seg2 35~36 seg3 37~41 seg4 42~45 这四个片段,依次发送出去,此时假设接收端之接收到了seg1 seg2 seg4
3. 此时接收端的行为是回复一个ACK包说明已经接收到了32~36的数据,并将seg4进行缓存(保证顺序,产生一个保存seg3 的hole)
4. 发送端收到ACK之后,就会将32~36的数据包从发送并没有确认切到发送已经确认,提出窗口,这个时候窗口向右移动
5. 假设接收端通告的Window Size仍然不变,此时窗口右移,产生一些新的空位,这些是接收端允许发送的范畴
6. 对于丢失的seg3,如果超过一定时间,TCP就会重新传送(重传机制),重传成功会seg3 seg4一块被确认,不成功,seg4也将被丢弃
就是不断重复着上述的过程,随着窗口不断滑动,将真个数据流发送到接收端,实际上接收端的Window Size通告也是会变化的,接收端根据这个值来确定何时及发送多少数据,从对数据流进行流控。原理图如下图所示:
滑动窗口动态调整
主要是根据接收端的接收情况,动态去调整Window Size,然后来控制发送端的数据流量
1. 客户端不断快速发送数据,服务器接收相对较慢,看下实验的结果
a. 包175,发送ACK携带WIN = 384,告知客户端,现在只能接收384个字节
b. 包176,客户端果真只发送了384个字节,Wireshark也比较智能,也宣告TCP Window Full
c. 包177,服务器回复一个ACK,并通告窗口为0,说明接收方已经收到所有数据,并保存到缓冲区,但是这个时候应用程序并没有接收这些数据,导致缓冲区没有更多的空间,故通告窗口为0, 这也就是所谓的零窗口,零窗口期间,发送方停止发送数据
d. 客户端察觉到窗口为0,则不再发送数据给接收方
e. 包178,接收方发送一个窗口通告,告知发送方已经有接收数据的能力了,可以发送数据包了
f. 包179,收到窗口通告之后,就发送缓冲区内的数据了.
2.tcp的拥塞控制怎么实现的;ps:感觉小米的面试必问tcp
拥塞的标志:重传计时器超时,接收到三个重复确认
慢开始与拥塞避免:
慢开始不是指cwnd的增长速度慢,而是指TCP开始发送设置cwnd=1;
思路:不要一开始发送大量的数据,先探测一下网络的拥塞程度,也就是说由小到大逐渐增加拥塞窗口的大小。这个用报文段的个数的拥塞窗口大小举例说明慢开始算法,实时拥塞窗口大小是以字节为单位的。如下图:
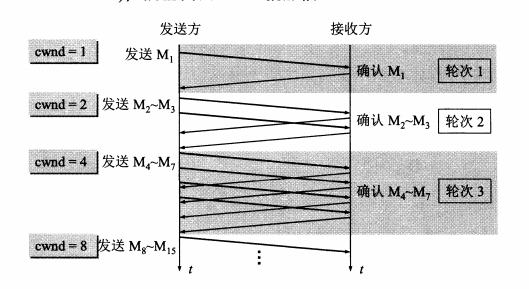
为了防止cwnd增长过大引起网络阻塞,设置一个慢开始门限(ssthresh状态变量),当cnwd<ssthresh,使用慢开始算法,cnwd=ssthresh 均可,cnwd》ssthresh使用拥塞避免算法。
拥塞避免:拥塞避免并非完全能够避免拥塞,是说在拥塞避免阶段将拥塞窗口控制为按线性规律增长,使网络比较不容易出现拥塞。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理),就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法。
快重传与快恢复:
快重传:快重传要求接收方在收到一个失效的报文段后就立即发出重复确认(为的是是发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。由于不需要等待设置的重传计时器到期,能尽早重传未被确认的报文段,能提高整个网络的吞吐量。
快恢复:采用快恢复算法时,慢开始只在TCP建立时和网络出现超时时才使用;当发送方连续收到三个重复确认时,就执行“乘法减小算法”,把ssthresh门限减半。但是接下去并不执行慢开始算法。 考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。
3.操作系统的内存是怎么分配的
常见的内存分配算法及优缺点如下:
a、首次适应算法。使用该算法进行内存分配时,从空闲分区链首开始查找,直至找到一个能满足其大小需求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。
该算法倾向于使用内存中低地址部分的空闲分区,在高地址部分的空闲分区非常少被利用,从而保留了高地址部分的大空闲区。显然为以后到达的大作业分配大的内存空间创造了条件。缺点在于低址部分不断被划分,留下许多难以利用、非常小的空闲区,而每次查找又都从低址部分开始,这无疑会增加查找的开销。
b、循环首次适应算法。该算法是由首次适应算法演变而成的。在为进程分配内存空间时,不再每次从链首开始查找,而是从上次找到的空闲分区开始查找,直至找到一个能满足需求的空闲分区,并从中划出一块来分给作业。该算法能使空闲中的内存分区分布得更加均匀,但将会缺乏大的空闲分区。
c、最佳适应算法。该算法总是把既能满足需求,又是最小的空闲分区分配给作业。
为了加速查找,该算法需求将所有的空闲区按其大小排序后,以递增顺序形成一个空白链。这样每次找到的第一个满足需求的空闲区,必然是最优的。孤立地看,该算法似乎是最优的,但事实上并不一定。因为每次分配后剩余的空间一定是最小的,在存储器中将留下许多难以利用的小空闲区。同时每次分配后必须重新排序,这也带来了一定的开销。
d、最差适应算法。最差适应算法中,该算法按大小递减的顺序形成空闲区链,分配时直接从空闲区链的第一个空闲分区中分配(不能满足需要则不分配)。非常显然,如果第一个空闲分区不能满足,那么再没有空闲分区能满足需要。这种分配方法初看起来不太合理,但他也有非常强的直观吸引力:在大空闲区中放入程式后,剩下的空闲区常常也非常大,于是还能装下一个较大的新程式。
最坏适应算法和最佳适应算法的排序正好相反,他的队列指针总是指向最大的空闲区,在进行分配时,总是从最大的空闲区开始查寻。
该算法克服了最佳适应算法留下的许多小的碎片的不足,但保留大的空闲区的可能性减小了,而且空闲区回收也和最佳适应算法相同复杂。
4.进程和线程分别讲一下
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程
5.学的是java是吧,那么你把java的object类有哪些方法都说一下。
基本描述:
(1)Object类位于java.lang包中,java.lang包包含着Java最基础和核心的类,在编译时会自动导入;
(2)Object类是所有Java类的祖先。每个类都使用 Object 作为超类。所有对象(包括数组)都实现这个类的方法。可以使用类型为Object的变量指向任意类型的对象
Object的主要方法介绍:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
hashCode()方法:
hash值:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
情景:考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)。
大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值。实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。
重写hashCode()方法的基本规则:
· 在程序运行过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
· 当两个对象通过equals()方法比较返回true时,则两个对象的hashCode()方法返回相等的值。
· 对象用作equals()方法比较标准的Field,都应该用来计算hashCode值。
Object本地实现的hashCode()方法计算的值是底层代码的实现,采用多种计算参数,返回的并不一定是对象的(虚拟)内存地址,具体取决于运行时库和JVM的具体实现。
|
1 2 3 |
|
equals()方法:比较两个对象是否相等
我们知道所有的对象都拥有标识(内存地址)和状态(数据),同时“==”比较两个对象的的内存地址,所以说使用Object的equals()方法是比较两个对象的内存地址是否相等,即若object1.equals(object2)为true,则表示equals1和equals2实际上是引用同一个对象。虽然有时候Object的equals()方法可以满足我们一些基本的要求,但是我们必须要清楚我们很大部分时间都是进行两个对象的比较,这个时候Object的equals()方法就不可以了,实际上JDK中,String、Math等封装类都对equals()方法进行了重写。
|
1 |
|
clone()方法:快速创建一个已有对象的副本
第一:Object类的clone()方法是一个native方法,native方法的效率一般来说都是远高于Java中的非native方法。这也解释了为什么要用Object中clone()方法而不是先new一个类,然后把原始对象中的信息复制到新对象中,虽然这也实现了clone功能。
第二:Object类中的 clone()方法被protected修饰符修饰。这也意味着如果要应用 clone()方 法,必须继承Object类。
第三:Object.clone()方法返回一个Object对象。我们必须进行强制类型转换才能得到我们需要的类型。
克隆的步骤:1:创建一个对象; 2:将原有对象的数据导入到新创建的数据中。
clone方法首先会判对象是否实现了Cloneable接口,若无则抛出CloneNotSupportedException, 最后会调用internalClone. intervalClone是一个native方法,一般来说native方法的执行效率高于非native方法。
|
1 2 3 4 5 6 7 8 |
|
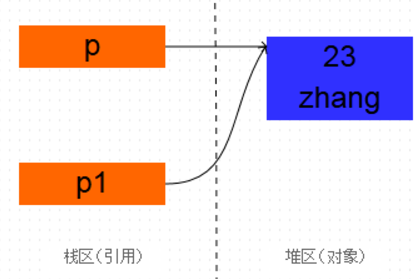
可已看出,打印的地址值是相同的,既然地址都是相同的,那么肯定是同一个对象。p和p1只是引用而已,他们都指向了一个相同的对象Person(23, "zhang") 。 可以把这种现象叫做引用的复制。
|
1 2 3 4 5 6 7 8 |
|
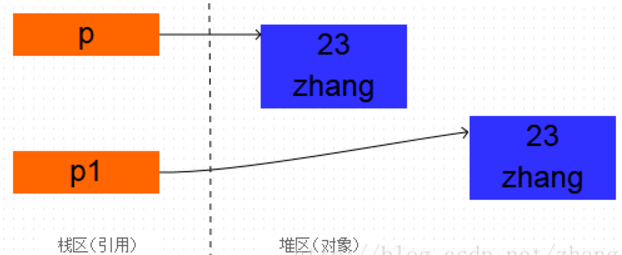
从打印结果可以看出,两个对象的地址是不同的,也就是说创建了新的对象, 而不是把原对象的地址赋给了一个新的引用变量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
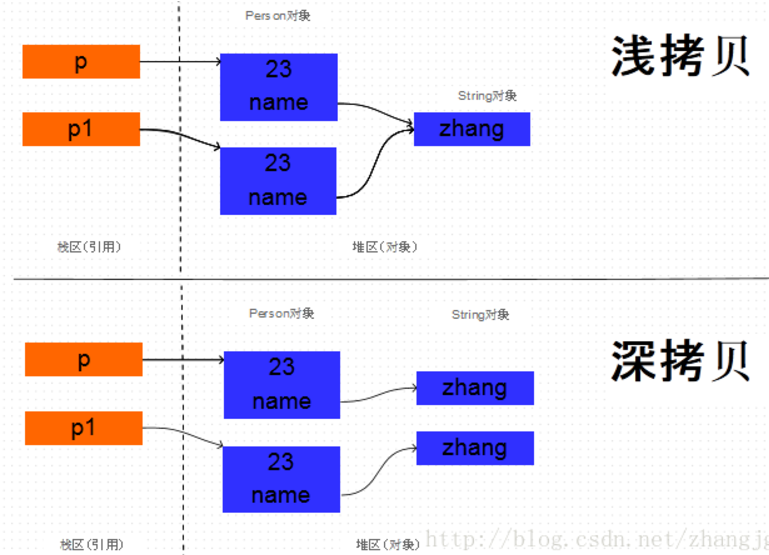
由于age是基本数据类型, 那么对它的拷贝没有什么疑议,直接将一个4字节的整数值拷贝过来就行。但是name是String类型的, 它只是一个引用, 指向一个真正的String对象,那么对它的拷贝有两种方式: 直接将源对象中的name的引用值拷贝给新对象的name字段, 或者是根据原Person对象中的name指向的字符串对象创建一个新的相同的字符串对象,将这个新字符串对象的引用赋给新拷贝的Person对象的name字段。这两种拷贝方式分别叫做浅拷贝和深拷贝。
通过下面代码进行验证。如果两个Person对象的name的地址值相同, 说明两个对象的name都指向同一个String对象, 也就是浅拷贝, 而如果两个对象的name的地址值不同, 那么就说明指向不同的String对象, 也就是在拷贝Person对象的时候, 同时拷贝了name引用的String对象, 也就是深拷贝。
|
1 2 3 4 5 6 7 8 9 |
|
对于对象的浅拷贝和深拷贝还有更深的细节,可以参考:详解Java中的clone方法 -- 原型模式
|
1 2 3 |
|
toString()方法:toString 方法会返回一个“以文本方式表示”此对象的字符串。结果应是一个简明但易于读懂的信息表达式。建议所有子类都重写此方法。
Object 类的 toString 方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和此对象哈希码的无符号十六进制表示组成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
|
1 |
|
finalize()方法:垃圾回收器准备释放内存的时候,会先调用finalize()。
(1). 对象不一定会被回收。
(2).垃圾回收不是析构函数。
(3).垃圾回收只与内存有关。
(4).垃圾回收和finalize()都是靠不住的,只要JVM还没有快到耗尽内存的地步,它是不会浪费时间进行垃圾回收的。
6.线程的lock锁了解吗?讲一下
一 Lock接口
1.1 Lock接口简介
锁是用于通过多个线程控制对共享资源的访问的工具。通常,锁提供对共享资源的独占访问:一次只能有一个线程可以获取锁,并且对共享资源的所有访问都要求首先获取锁。 但是,一些锁可能允许并发访问共享资源,如ReadWriteLock的读写锁。
在Lock接口出现之前,Java程序是靠synchronized关键字实现锁功能的。JDK1.5之后并发包中新增了Lock接口以及相关实现类来实现锁功能。
虽然synchronized方法和语句的范围机制使得使用监视器锁更容易编程,并且有助于避免涉及锁的许多常见编程错误,但是有时您需要以更灵活的方式处理锁。例如,用于遍历并发访问的数据结构的一些算法需要使用“手动”或“链锁定”:您获取节点A的锁定,然后获取节点B,然后释放A并获取C,然后释放B并获得D等。在这种场景中synchronized关键字就不那么容易实现了,使用Lock接口容易很多。
Lock接口的实现类:
ReentrantLock , ReentrantReadWriteLock.ReadLock , ReentrantReadWriteLock.WriteLock
1.2 Lock的简单使用
Lock lock=new ReentrantLock();
lock.lock();
try{
}finally{
lock.unlock();
}
因为Lock是接口所以使用时要结合它的实现类,另外在finall语句块中释放锁的目的是保证获取到锁之后,最终能够被释放。
注意: 最好不要把获取锁的过程写在try语句块中,因为如果在获取锁时发生了异常,异常抛出的同时也会导致锁无法被释放。
1.3 Lock接口的特性和常见方法
Lock接口提供的synchronized关键字不具备的主要特性:
特性 描述
尝试非阻塞地获取锁 当前线程尝试获取锁,如果这一时刻锁没有被其他线程获取到,则成功获取并持有锁
能被中断地获取锁 获取到锁的线程能够响应中断,当获取到锁的线程被中断时,中断异常将会被抛出,同时锁会被释放
超时获取锁 在指定的截止时间之前获取锁, 超过截止时间后仍旧无法获取则返回
Lock接口基本的方法:
方法名称 描述
void lock() 获得锁。如果锁不可用,则当前线程将被禁用以进行线程调度,并处于休眠状态,直到获取锁。
void lockInterruptibly() 获取锁,如果可用并立即返回。如果锁不可用,那么当前线程将被禁用以进行线程调度,并且处于休眠状态,和lock()方法不同的是在锁的获取中可以中断当前线程(相应中断)。
Condition newCondition() 获取等待通知组件,该组件和当前的锁绑定,当前线程只有获得了锁,才能调用该组件的wait()方法,而调用后,当前线程将释放锁。
boolean tryLock() 只有在调用时才可以获得锁。如果可用,则获取锁定,并立即返回值为true;如果锁不可用,则此方法将立即返回值为false 。
boolean tryLock(long time, TimeUnit unit) 超时获取锁,当前线程在一下三种情况下会返回: 1. 当前线程在超时时间内获得了锁;2.当前线程在超时时间内被中断;3.超时时间结束,返回false.
void unlock() 释放锁。
二 Lock接口的实现类:ReentrantLock
ReentrantLock和synchronized关键字一样可以用来实现线程之间的同步互斥,但是在功能是比synchronized关键字更强大而且更灵活。
ReentrantLock类常见方法:
构造方法:
方法名称 描述
ReentrantLock() 创建一个 ReentrantLock的实例。
ReentrantLock(boolean fair) 创建一个特定锁类型(公平锁/非公平锁)的ReentrantLock的实例
ReentrantLock类常见方法(Lock接口已有方法这里没加上):
方法名称 描述
int getHoldCount() 查询当前线程保持此锁定的个数,也就是调用lock()方法的次数。
protected Thread getOwner() 返回当前拥有此锁的线程,如果不拥有,则返回 null
protected Collection getQueuedThreads() 返回包含可能正在等待获取此锁的线程的集合
int getQueueLength() 返回等待获取此锁的线程数的估计。
protected Collection getWaitingThreads(Condition condition) 返回包含可能在与此锁相关联的给定条件下等待的线程的集合。
int getWaitQueueLength(Condition condition) 返回与此锁相关联的给定条件等待的线程数的估计。
boolean hasQueuedThread(Thread thread) 查询给定线程是否等待获取此锁。
boolean hasQueuedThreads() 查询是否有线程正在等待获取此锁。
boolean hasWaiters(Condition condition) 查询任何线程是否等待与此锁相关联的给定条件
boolean isFair() 如果此锁的公平设置为true,则返回 true 。
boolean isHeldByCurrentThread() 查询此锁是否由当前线程持有。
boolean isLocked() 查询此锁是否由任何线程持有。
2.1 第一个ReentrantLock程序
ReentrantLockTest.java
public class ReentrantLockTest {
public static void main(String[] args) {
MyService service = new MyService();
MyThread a1 = new MyThread(service);
MyThread a2 = new MyThread(service);
MyThread a3 = new MyThread(service);
MyThread a4 = new MyThread(service);
MyThread a5 = new MyThread(service);
a1.start();
a2.start();
a3.start();
a4.start();
a5.start();
}
static public class MyService {
private Lock lock = new ReentrantLock();
public void testMethod() {
lock.lock();
try {
for (int i = 0; i < 5; i++) {
System.out.println("ThreadName=" + Thread.currentThread().getName() + (" " + (i + 1)));
}
} finally {
lock.unlock();
}
}
}
static public class MyThread extends Thread {
private MyService service;
public MyThread(MyService service) {
super();
this.service = service;
}
@Override
public void run() {
service.testMethod();
}
}
}
从运行结果可以看出,当一个线程运行完毕后才把锁释放,其他线程才能执行,其他线程的执行顺序是不确定的。
2.2 Condition接口简介
我们通过之前的学习知道了:synchronized关键字与wait()和notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。
在使用notify/notifyAll()方法进行通知时,被通知的线程是有JVM选择的,使用ReentrantLock类结合Condition实例可以实现“选择性通知”,这个功能非常重要,而且是Condition接口默认提供的。
而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程
Condition接口的常见方法:
方法名称 描述
void await() 相当于Object类的wait方法
boolean await(long time, TimeUnit unit) 相当于Object类的wait(long timeout)方法
signal() 相当于Object类的notify方法
signalAll() 相当于Object类的notifyAll方法
2.3 使用Condition实现等待/通知机制
1. 使用单个Condition实例实现等待/通知机制:
UseSingleConditionWaitNotify.java
public class UseSingleConditionWaitNotify {
public static void main(String[] args) throws InterruptedException {
MyService service = new MyService();
ThreadA a = new ThreadA(service);
a.start();
Thread.sleep(3000);
service.signal();
}
static public class MyService {
private Lock lock = new ReentrantLock();
public Condition condition = lock.newCondition();
public void await() {
lock.lock();
try {
System.out.println(" await时间为" + System.currentTimeMillis());
condition.await();
System.out.println("这是condition.await()方法之后的语句,condition.signal()方法之后我才被执行");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void signal() throws InterruptedException {
lock.lock();
try {
System.out.println("signal时间为" + System.currentTimeMillis());
condition.signal();
Thread.sleep(3000);
System.out.println("这是condition.signal()方法之后的语句");
} finally {
lock.unlock();
}
}
}
static public class ThreadA extends Thread {
private MyService service;
public ThreadA(MyService service) {
super();
this.service = service;
}
@Override
public void run() {
service.await();
}
}
}
在使用wait/notify实现等待通知机制的时候我们知道必须执行完notify()方法所在的synchronized代码块后才释放锁。在这里也差不多,必须执行完signal所在的try语句块之后才释放锁,condition.await()后的语句才能被执行。
注意: 必须在condition.await()方法调用之前调用lock.lock()代码获得同步监视器,不然会报错。
2. 使用多个Condition实例实现等待/通知机制:
UseMoreConditionWaitNotify.java
public class UseMoreConditionWaitNotify {
public static void main(String[] args) throws InterruptedException {
MyserviceMoreCondition service = new MyserviceMoreCondition();
ThreadA a = new ThreadA(service);
a.setName("A");
a.start();
ThreadB b = new ThreadB(service);
b.setName("B");
b.start();
Thread.sleep(3000);
service.signalAll_A();
}
static public class ThreadA extends Thread {
private MyserviceMoreCondition service;
public ThreadA(MyserviceMoreCondition service) {
super();
this.service = service;
}
@Override
public void run() {
service.awaitA();
}
}
static public class ThreadB extends Thread {
private MyserviceMoreCondition service;
public ThreadB(MyserviceMoreCondition service) {
super();
this.service = service;
}
@Override
public void run() {
service.awaitB();
}
}
}
MyserviceMoreCondition.java
public class MyserviceMoreCondition {
private Lock lock = new ReentrantLock();
public Condition conditionA = lock.newCondition();
public Condition conditionB = lock.newCondition();
public void awaitA() {
lock.lock();
try {
System.out.println("begin awaitA时间为" + System.currentTimeMillis()
+ " ThreadName=" + Thread.currentThread().getName());
conditionA.await();
System.out.println(" end awaitA时间为" + System.currentTimeMillis()
+ " ThreadName=" + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void awaitB() {
lock.lock();
try {
System.out.println("begin awaitB时间为" + System.currentTimeMillis()
+ " ThreadName=" + Thread.currentThread().getName());
conditionB.await();
System.out.println(" end awaitB时间为" + System.currentTimeMillis()
+ " ThreadName=" + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void signalAll_A() {
lock.lock();
try {
System.out.println(" signalAll_A时间为" + System.currentTimeMillis()
+ " ThreadName=" + Thread.currentThread().getName());
conditionA.signalAll();
} finally {
lock.unlock();
}
}
public void signalAll_B() {
lock.lock();
try {
System.out.println(" signalAll_B时间为" + System.currentTimeMillis()
+ " ThreadName=" + Thread.currentThread().getName());
conditionB.signalAll();
} finally {
lock.unlock();
}
}
}
只有A线程被唤醒了。
3. 使用Condition实现顺序执行
ConditionSeqExec.java
public class ConditionSeqExec {
volatile private static int nextPrintWho = 1;
private static ReentrantLock lock = new ReentrantLock();
final private static Condition conditionA = lock.newCondition();
final private static Condition conditionB = lock.newCondition();
final private static Condition conditionC = lock.newCondition();
public static void main(String[] args) {
Thread threadA = new Thread() {
public void run() {
try {
lock.lock();
while (nextPrintWho != 1) {
conditionA.await();
}
for (int i = 0; i < 3; i++) {
System.out.println("ThreadA " + (i + 1));
}
nextPrintWho = 2;
//通知conditionB实例的线程运行
conditionB.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
};
Thread threadB = new Thread() {
public void run() {
try {
lock.lock();
while (nextPrintWho != 2) {
conditionB.await();
}
for (int i = 0; i < 3; i++) {
System.out.println("ThreadB " + (i + 1));
}
nextPrintWho = 3;
//通知conditionC实例的线程运行
conditionC.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
};
Thread threadC = new Thread() {
public void run() {
try {
lock.lock();
while (nextPrintWho != 3) {
conditionC.await();
}
for (int i = 0; i < 3; i++) {
System.out.println("ThreadC " + (i + 1));
}
nextPrintWho = 1;
//通知conditionA实例的线程运行
conditionA.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
};
Thread[] aArray = new Thread[5];
Thread[] bArray = new Thread[5];
Thread[] cArray = new Thread[5];
for (int i = 0; i < 5; i++) {
aArray[i] = new Thread(threadA);
bArray[i] = new Thread(threadB);
cArray[i] = new Thread(threadC);
aArray[i].start();
bArray[i].start();
cArray[i].start();
}
}
}
通过代码很好理解,说简单就是在一个线程运行完之后通过condition.signal()/condition.signalAll()方法通知下一个特定的运行运行,就这样循环往复即可。
注意: 默认情况下ReentranLock类使用的是非公平锁
2.4 公平锁与非公平锁
Lock锁分为:公平锁 和 非公平锁。公平锁表示线程获取锁的顺序是按照线程加锁的顺序来分配的,即先来先得的FIFO先进先出顺序。而非公平锁就是一种获取锁的抢占机制,是随机获取锁的,和公平锁不一样的就是先来的不一定先的到锁,这样可能造成某些线程一直拿不到锁,结果也就是不公平的了。
FairorNofairLock.java
public class FairorNofairLock {
public static void main(String[] args) throws InterruptedException {
final Service service = new Service(true);//true为公平锁,false为非公平锁
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("★线程" + Thread.currentThread().getName()
+ "运行了");
service.serviceMethod();
}
};
Thread[] threadArray = new Thread[10];
for (int i = 0; i < 10; i++) {
threadArray[i] = new Thread(runnable);
}
for (int i = 0; i < 10; i++) {
threadArray[i].start();
}
}
static public class Service {
private ReentrantLock lock;
public Service(boolean isFair) {
super();
lock = new ReentrantLock(isFair);
}
public void serviceMethod() {
lock.lock();
try {
System.out.println("ThreadName=" + Thread.currentThread().getName()
+ "获得锁定");
} finally {
lock.unlock();
}
}
}
}
公平锁的运行结果是有序的。
把Service的参数修改为false则为非公平锁
final Service service = new Service(false);//true为公平锁,false为非公平锁
非公平锁的运行结果是无序的。
三 ReadWriteLock接口的实现类:ReentrantReadWriteLock
3.1 简介
我们刚刚接触到的ReentrantLock(排他锁)具有完全互斥排他的效果,即同一时刻只允许一个线程访问,这样做虽然虽然保证了实例变量的线程安全性,但效率非常低下。ReadWriteLock接口的实现类-ReentrantReadWriteLock读写锁就是为了解决这个问题。
读写锁维护了两个锁,一个是读操作相关的锁也成为共享锁,一个是写操作相关的锁 也称为排他锁。通过分离读锁和写锁,其并发性比一般排他锁有了很大提升。
多个读锁之间不互斥,读锁与写锁互斥,写锁与写锁互斥(只要出现写操作的过程就是互斥的。)。在没有线程Thread进行写入操作时,进行读取操作的多个Thread都可以获取读锁,而进行写入操作的Thread只有在获取写锁后才能进行写入操作。即多个Thread可以同时进行读取操作,但是同一时刻只允许一个Thread进行写入操作。
3.2 ReentrantReadWriteLock的特性与常见方法
ReentrantReadWriteLock的特性:
特性 说明
公平性选择 支持非公平(默认)和公平的锁获取方式,吞吐量上来看还是非公平优于公平
重进入 该锁支持重进入,以读写线程为例:读线程在获取了读锁之后,能够再次获取读锁。而写线程在获取了写锁之后能够再次获取写锁也能够同时获取读锁
锁降级 遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级称为读锁
ReentrantReadWriteLock常见方法:
构造方法
方法名称 描述
ReentrantReadWriteLock() 创建一个 ReentrantReadWriteLock()的实例
ReentrantReadWriteLock(boolean fair) 创建一个特定锁类型(公平锁/非公平锁)的ReentrantReadWriteLock的实例
常见方法:
和ReentrantLock类 类似这里就不列举了。
3.3 ReentrantReadWriteLock的使用
1. 读读共享
两个线程同时运行read方法,你会发现两个线程可以同时或者说是几乎同时运行lock()方法后面的代码,输出的两句话显示的时间一样。这样提高了程序的运行效率。
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public void read() {
try {
try {
lock.readLock().lock();
System.out.println("获得读锁" + Thread.currentThread().getName()
+ " " + System.currentTimeMillis());
Thread.sleep(10000);
} finally {
lock.readLock().unlock();
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
2. 写写互斥
把上面的代码的
lock.readLock().lock();
1
改为:
lock.writeLock().lock();
1
两个线程同时运行read方法,你会发现同一时间只允许一个线程执行lock()方法后面的代码
3. 读写互斥
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public void read() {
try {
try {
lock.readLock().lock();
System.out.println("获得读锁" + Thread.currentThread().getName()
+ " " + System.currentTimeMillis());
Thread.sleep(10000);
} finally {
lock.readLock().unlock();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void write() {
try {
try {
lock.writeLock().lock();
System.out.println("获得写锁" + Thread.currentThread().getName()
+ " " + System.currentTimeMillis());
Thread.sleep(10000);
} finally {
lock.writeLock().unlock();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
测试代码:
Service service = new Service();
ThreadA a = new ThreadA(service);
a.setName("A");
a.start();
Thread.sleep(1000);
ThreadB b = new ThreadB(service);
b.setName("B");
b.start();
运行两个使用同一个Service对象实例的线程a,b,线程a执行上面的read方法,线程b执行上面的write方法。你会发现同一时间只允许一个线程执行lock()方法后面的代码。记住:只要出现写操作的过程就是互斥的。
4. 写读互斥
和读写互斥类似,这里不用代码演示了。记住:只要出现写操作的过程就是互斥的。
7.lock能做到哪些synchronized做不到的,这里答的不是很好
Lock与synchronized的不同
二者都是可重入锁,那么为什么要有两个呢?既然存在,那么就一定是有意义的。synchronized是Java中的一个关键字,而Lock是Java1.5后在java.util.concurrent.locks包下提供的一种实现同步的方法,那么显然的,synchronized一定是有什么做不到的或者缺陷,才导致了Lock的诞生。
1.synchronized的缺点
1)当一个代码块被synchronized修饰的时候,一个线程获取到了锁,并且执行代码块,那么其他的线程需要等待正在使用的线程释放掉这个锁,那么释放锁的方法只有两种,一种是代码执行完毕自动释放,一种是发生异常以后jvm会让线程去释放锁。那么如果这个正在执行的线程遇到什么问题,比如等待IO或者调用sleep方法等等被阻塞了,无法释放锁,而这时候其他线程只能一直等待,将会特别影响效率。那么有没有一种办法让其他线程不必一直傻乎乎的等在这里吗?
2)当一个文件,同时被多个线程操作时,读操作和写操作会发生冲突,写操作和写操作会发生冲突,而读操作和读操作并不会冲突,但是如果我们用synchronized的话,会导致一个线程在读的时候,其他线程想要读的话只能等待,那么有什么办法能不锁读操作吗?
3)在使用synchronized时,我们无法得知线程是否成功获取到锁,那么有什么办法能知道是否获取到锁吗?
2.java.util.concurrent.locks包
1)Lock
Lock是一个接口,源码如下
1 public interface Lock {
2 void lock();
3 void lockInterruptibly() throws InterruptedException;
4 boolean tryLock();
5 boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
6 void unlock();
7 Condition newCondition();
8 }
ReentrantLock是Lock的一个实现类(另外两个实现类是ReentrantReadWriteLock类下的两个静态内部类:WriteLock和ReadLock),它的意思是可重入锁,可重入锁前面已经讲过了。ReentrantLock中提供了更多的一些方法。不过常用的就是Lock中的这些。
来看一下Lock接口这些方法的使用,lock()、tryLock()、tryLock(long time, TimeUnit unit)和lockInterruptibly()是用来获取锁的。unLock()方法是用来释放锁的。
这里有四个方法来获取锁,那么区别在哪里呢?
lock()使我们平时用的最多的,最用是用来获取锁,如果锁已经被其他线程获取,那么就等待。但是采用Lock必须要主动释放锁,所以我们一般在try{}catch{}块中处理然后在finally中释放锁,举个例子:
1 lock.lock();
2 try{
3 // 处理
4 }catch(Exception ex){
5 // 捕获异常
6 }finally{
7 // 释放锁
8 lock.unlock();
9 }
tryLock()是一个boolean类型的方法,当调用这个方法的时候,线程会去尝试获取锁,如果获取到的话会返回true,如果获取不到返回false,也就是说这个方法会立马返回一个结果,线程不会等待。
tryLock(long time, TimeUnit unit)是上面tryLock()方法的一个重载方法,加了两个参数,给定了等待的时间,如果在规定时间拿到锁返回true,如果拿不到返回false。这两个方法的一般用法和Lock类似。
1 if (lock.tryLock()) {
2 try{
3 // 处理
4 }catch(Exception ex){
5 // 捕获异常
6 }finally{
7 // 释放锁
8 lock.unlock();
9 }
10 }
lockInterruptibly()就比较特殊了,它表示可被中断的,意思就是,当尝试获取锁的时候,如果获取不到的话就会等待,但是,在等待的过程中它是可以响应中断的,也就是中断线程的等待过程。使用形式的话一样用try catch处理,就不贴代码了。
2)ReadWriteLock
ReadWriteLock也是一个接口,这个接口中只有两个方法,源码如下:
1 public interface ReadWriteLock {
2 Lock readLock();
3
4 Lock writeLock();
5 }这个接口的从字面就能看出来他的用途,读锁和写锁,这时候是不是想起了前面我写到的synchronized的第二条。
ReentrantReadWriteLock是ReadWriteLock的一个实现类,最常用到的也是获取读锁和获取写锁。下面看例子:
首先是使用synchronized的:
1 public class Main {
2 public static void main(String[] args) {
3 final Main m = new Main();
4
5 new Thread(){
6 public void run() {
7 m.read(Thread.currentThread());
8 };
9 }.start();
10
11 new Thread(){
12 public void run() {
13 m.read(Thread.currentThread());
14 };
15 }.start();
16 }
17
18 public synchronized void read(Thread thread) {
19 long startTime = System.currentTimeMillis();
20 while(System.currentTimeMillis() - startTime <= 1) {
21 System.out.println(thread.getName()+"线程在进行读操作");
22 }
23 System.out.println(thread.getName()+"线程完成读操作");
24 }
25 }
这段代码的执行结果是在一个线程打印出完成读操作后,另一条线程才会开始进行读操作。
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程完成读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程完成读操作
下面看如果用ReadWriteLock:
1 public class Main {
2 public static void main(String[] args) {
3 private ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
4 final Main m = new Main();
5
6 new Thread(){
7 public void run() {
8 m.read(Thread.currentThread());
9 };
10 }.start();
11
12 new Thread(){
13 public void run() {
14 m.read(Thread.currentThread());
15 };
16 }.start();
17 }
18
19 public void read(Thread thread) {
20 readWriteLock.readLock().lock();
21 try {
22 long startTime = System.currentTimeMillis();
23 while(System.currentTimeMillis() - startTime <= 1) {
24 System.out.println(thread.getName()+"线程在进行读操作");
25 }
26 System.out.println(thread.getName()+"线程完成读操作");
27 } finally {
28 readWriteLock.unlock();
29 }
30 }
31 }
只是把之前的synchronized换成了ReadWriteLock,但是输出结果却是两个线程在一起进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程在进行读操作
Thread-1线程在进行读操作
Thread-0线程完成读操作
Thread-1线程完成读操作
这个结果可以看到两个线程同时进行读操作,效率大大的提升了。但是要注意的是,如果一个线程获取了读锁,那么另外的线程想要获取写锁则需要等待释放;而如果一个线程已经获取了写锁,则另外的线程想获取读锁或写锁都需要等待写锁被释放。
总结一下二者:
1.synchronized是Java的关键字,是内置特性,而Lock是一个接口,可以用它来实现同步。
2.synchronized同步的时候,其中一条线程用完会自动释放锁,而Lock需要手动释放,如果不手动释放,可能会造成死锁。
3.使用synchronized如果其中一个线程不释放锁,那么其他需要获取锁的线程会一直等待下去,知道使用完释放或者出现异常,而Lock可以使用可以响应中断的锁或者使用规定等待时间的锁
4.synchronized无法得知是否获取到锁,而Lcok可以做到。
5.用ReadWriteLock可以提高多个线程进行读操作的效率。
所以综上所述,在两种锁的选择上,当线程对于资源的竞争不激烈的时候,效率差不太多,但是当大量线程同时竞争的时候,Lock的性能会远高于synchronized。
8.你知道的集合都讲一下。
9.哪个集合可以实现stack,queue,deque(linkedlist)
stack:java集合框架中没有stack接口,仅仅有Java早期遗留下来的一个stack类。
Deque stack = new ArrayDeque();
public Stack extends Vector
因为集成自Vector,所以Stack类时同步的,效率不高。官方一般建议使用ArrayDeque代替Stack、Java.util.Stack
Queue接口:简单介绍几个方法的区别
offer,add区别:一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。这时新的offer方法就可以起作用了。他不是对调用add()方法抛出一个unchecked异常,而只是得到由offer()返回的 false。
poll,remove异常:remove()和poll()方法都是从队列中删除第一个元素。remove()的行为与Collection接口的版本类似,但是新的poll方法在用空集合调用时不是抛出异常,只是返回null。因此新的方法更适合容易出现异常条件的情况。
peek,element区别:element()和peek()用于在队列的头部查询元素。与remove()方法类似,在队列为空时,element()抛出一个异常,而peek()返回null。
Deque接口:是Queue的子接口。Deque有两个比较重要的类:ArrayDeque和LinkedList.建议使用栈时,用ArrayDequed的push和pop方法,使用队列时使用ArrayDeque的add和remove方法。
优先队列PriorityQueue:
如果不提供Comparator的话,优先队列中元素默认按自然顺序排列,也就是数字默认是小的在队列头,字符串则按字典序排列。
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
public class Main {
private String name;
private int population;
public Main(String name, int population)
{
this.name = name;
this.population = population;
}
public String getName()
{
return this.name;
}
public int getPopulation()
{
return this.population;
}
public String toString()
{
return getName() + " - " + getPopulation();
}
public static void main(String args[])
{
Comparator<Main> OrderIsdn = new Comparator<Main>(){
@Override
public int compare(Main o1, Main o2) {
int numbera = o1.getPopulation();
int numberb = o2.getPopulation();
return Integer.compare(numbera, numberb);
}
};
Queue<Main> priorityQueue = new PriorityQueue<Main>(11,OrderIsdn);
Main t1 = new Main("t1",1);
Main t3 = new Main("t3",3);
Main t2 = new Main("t2",2);
Main t4 = new Main("t4",0);
priorityQueue.add(t1);
priorityQueue.add(t3);
priorityQueue.add(t2);
priorityQueue.add(t4);
System.out.println(priorityQueue.poll().toString());
}
}
结果 t4 - 0
10数据库的触发器说一下
转载至:https://www.cnblogs.com/zyshi/p/6618839.html#_label3
(个人总结:下面内容已经验证了,代码实例没有问题。触发器只是用在特定的场合,一般情况下,我们还是在代码中处理,因为同一个业务逻辑中,如果代码和sql中都有业务逻辑,那么后期维护将很麻烦,所以要根据实际情况来选择,看是否合适。
触发器就是写在数据库中的一个脚本sql,当数据库某一个字段发生改变的时候,触发一个或多条sql语句,同时让多张表的数据同步。比如我们有的表中存放了部门名称,那么当我们部门名称发生改变的时候,我们应该调用触发器同时去修改存放了“部门名称”这个冗余字段。)
什么是触发器
简单的说,就是一张表发生了某件事(插入、删除、更新操作),然后自动触发了预先编写好的若干条SQL语句的执行;
特点及作用
特点:触发事件的操作和触发器里的SQL语句是一个事务操作,具有原子性,要么全部执行,要么都不执行;
作用:保证数据的完整性,起到约束的作用;
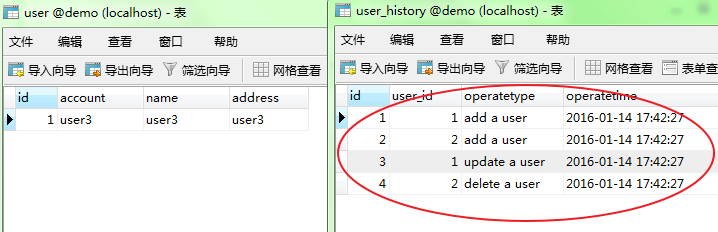
接下来将创建user和user_history表,以及三个触发器tri_insert_user、tri_update_user、tri_delete_user,分别对应user表的增、删、改三件事;
- 创建user表;
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
- 创建对user表操作历史表;
DROP TABLE IF EXISTS `user_history`;
CREATE TABLE `user_history` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`operatetype` varchar(200) NOT NULL,
`operatetime` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 创建user表插入事件对应的触发器tri_insert_user;
几点说明:
DELIMITER:改变输入的结束符,默认情况下输入结束符是分号;,这里把它改成了两个分号;;,这样做的目的是把多条含分号的语句做个封装,全部输入完之后一起执行,而不是一遇到默认的分号结束符就自动执行;
new:当触发插入和更新事件时可用,指向的是被操作的记录
old: 当触发删除和更新事件时可用,指向的是被操作的记录
DROP TRIGGER IF EXISTS `tri_insert_user`;
DELIMITER ;;
CREATE TRIGGER `tri_insert_user` AFTER INSERT ON `user` FOR EACH ROW begin
INSERT INTO user_history(user_id, operatetype, operatetime) VALUES (new.id, 'add a user', now());
end
;;
DELIMITER ;
- 创建user表更新事件对应的触发器tri_update_user;
DROP TRIGGER IF EXISTS `tri_update_user`;
DELIMITER ;;
CREATE TRIGGER `tri_update_user` AFTER UPDATE ON `user` FOR EACH ROW begin
INSERT INTO user_history(user_id,operatetype, operatetime) VALUES (new.id, 'update a user', now());
end
;;
DELIMITER ;
- 创建user表删除事件对应的触发器tri_delete_user;
DROP TRIGGER IF EXISTS `tri_delete_user`;
DELIMITER ;;
CREATE TRIGGER `tri_delete_user` AFTER DELETE ON `user` FOR EACH ROW begin
INSERT INTO user_history(user_id, operatetype, operatetime) VALUES (old.id, 'delete a user', now());
end
;;
DELIMITER ;
- 至此,全部表及触发器创建完成,开始验证结果,分别做插入、修改、删除事件,执行以下语句,观察user_history是否自动产生操作记录;
INSERT INTO user(account, name, address) VALUES ('user1', 'user1', 'user1');
INSERT INTO user(account, name, address) VALUES ('user2', 'user2', 'user2');
UPDATE user SET name = 'user3', account = 'user3', address='user3' where name='user1';
DELETE FROM `user` where name = 'user2';- 观察结果user表和user_history表的结果,操作记录已产生,说明触发器工作正常;
增加程序的复杂度,有些业务逻辑在代码中处理,有些业务逻辑用触发器处理,会使后期维护变得困难;
11数据库索引说一下
前言
索引是对数据库表中的一列或多列的值,进行排序的一种结构 ,使用索引可以快速访问数据库表中的特定信息,是加快数据库查询的技术。通俗理解,数据库索引就是现实生活中字典的索引。
索引的优缺点
- 优点:
索引可以避免全表扫描;
创建系统唯一性索引,可以保证每一行数据的唯一性;
大大提高数据检索的速度;
加快表与表之间的链接,特别是具有主、外键关系的表;
在针对使用order by和groupby子句进行数据检索时,可以显著地减少分组和排序的时间;
- 缺点:
创建和维护索引是需要耗费时间的,这种时间会随着数据量的增加而增加;
索引需要占用物理空间,除了数据表占用数据空间外,每一个索引还要占用一定的物理空间,如果要建立聚集索引,那么需要的空间就会更大;
当表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度;
创建索引的建议
没必要给每个列都创建索引,创建太多的索引反而会影响性能。因此在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能了创建索引。下面列出一些经验总结的建议:
- 应该创建索引的列:
在经常需要搜索的列,也就是Select后跟的列;
在主键的列上;
在经常使用连接外键的列上;
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常使用Where子句中的列创建索引,加快条件的判断速度;
- 不应该创建索引的列:
查询中很少使用得列不应该创建索引。创建的话有些得不偿失;
对于那些只有很少数据值得列也不需要创建索引,因为,这些列的取值很少,例如员工表中的性别列,一般都是bit类型,它有两个值0和1,但是它并不是唯一的,每行都有,索引在搜索的时候会搜索所有的0或1的行,造成搜索范围变大,所以增加索引并不能明显的加快检索速度;
对于text、image、varchar(max)和bit数据类型的列不应该增加索引,这是因为,这些列值的数据量要么量相当大,要么取值很少;
当修改性能远远大于检索性能的时候,不应该创建索引。从上面索引的缺点知道,修改性能和检索性能是互相矛盾的。当增加索引时,就会提高检索性能,但会降低修改性能。当减少索引时,就会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引;
索引的类型
根据索引的顺序与数据表的物理顺序是否相同,可以把索引分成两种类型:一种是数据表的物理顺序与索引顺序相同的聚集索引,另一种是数据表的物理顺序与索引顺序不同的非聚集索引。
- 使用聚集索引和非聚集索引的建议:
每个表只能有一个聚集索引,因为表中数据的物理顺序是唯一的
在创建任何非聚集索引之前先创建聚集索引,这是因为聚集索引改变了表中行的物理顺序,数据行按照一定的顺序排列,并且自动维护这个顺序。
聚集索引的平均大小大约是数据表的5%,但是,实际的聚集索引的大小 常常根据索引列的大小而变化,因此一定要保证有足够的空间来创建聚集索引
数据库索引原理
想要更好的使用索引就得明白索引在数据库中的结构是怎样的?在数据库中怎么存储的?这里将以SQL Server为例讲解。
在SQL Server系统中,可管理的最小空间单元就是页,一个页是8KB字节的物理空间,在数据文件中全部是分隔成这样的页。在插入数据的时候,数据按照时间顺服放置在数据也上。一般来说,放置数据的顺序和数据本身的逻辑关系之间是没有任何联系的。另外,因为数据是连续存放的,所以还存在一页写不下,再写到下页的情况,这叫做页分解。
表和索引都是以页为单位存储的,这些表页和索引页又包含在一个或多个分区中。分区是用户定义的数据组织的单元。默认情况下,表或索引只有一个分区,其中包含所有的表页和索引页。该分区驻留在单个文件组中。
当表或索引使用多个分区时,数据将被水平分区,以便根据指定的列将行组映射到各个分区。分区可以放在数据库中的一个或多个文件组中。对数据进行查询 或更新时,表或索引将视为单个逻辑实体。如下图所示

SQL Server表使用两种方法来组织分区中的数据页:B-Tree和堆。先来说一下堆
堆
简单来说,堆就是不含聚集索引的表,表中的数据没有任何顺序。平常我们表的数据在没建立索引之前都是存储在堆上的。(注意,这里的堆不同于.NET CLR上的堆)
默认情况下,一个堆有一个分区。当堆有多个分区时,每个分区有一个堆结构,其中包含该特定分区的数据。例如,如果一个堆有四个分区,则有四个堆结构,每一个分区都有一个堆结构。
根据堆中的数据类型,每个堆结构将有一个或多个分配单元来存储和管理特定分区的数据。每个堆中的每个分区至少有一个IN_ROW_DATA分配单元。如果堆中包含大型对象(LOB)列,则该堆得每个分区还将有一个LOB_DATA分配单元。如果堆中包含超过8060字节大小限制的可变长列,则该堆得每个分区还将有一个ROW_OVERFLOW_DATA分配单元。
SQL Server 使用 IAM 页在堆中移动。堆内的数据页和行没有任何特定的顺序,也不链接在一起。 数据页之间唯一的逻辑连接是记录在 IAM 页内的信息。可以通过扫描 IAM 页对堆进行表扫描或串行读操作来找到容纳该堆的页的扩展盘区。因为 IAM 按扩展盘区在数据文件内存在的顺序表示它们,所以这意味着串行堆扫描连续沿每个文件进行。使用 IAM 页设置扫描顺序还意味着堆中的行一般不按照插入的顺序返回。
下图说明 SQL Server 数据库引擎 如何使用 IAM 页检索具有单个分区的堆中的数据行。

B-Tree
聚集索引和非聚集索引都是用B-Tree来创建的,索引 B -Tree中的每一页称为一个索引节点。B-Tree的顶端节点称为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。
聚集索引
聚集索引包括索引页和数据页,索引页存放索引和下一层的指针,数据页用于存放数据,叶节点包含数据页,根节点和中间级节点包含索引页。每级索引页均被链接在双向链接列表中。在聚集索引中,数据值得顺序总是按照升序排列的。
下图显式了聚集索引单个分区中的结构。

非聚集索引
非聚集索引与聚集索引具有相同的 B-tree结构,它们之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集键的顺序排序和存储。
- 非聚集索引的叶层是由索引页而不是由数据页组成。
既可以使用聚集索引来为表或视图定义非聚集索引,也可以根据堆来定义非聚集索引。非聚集索引中的每个索引行都包含非聚集键值和行定位符。此定位符指向聚集索引或堆中包含该键值的数据行。
下图说明了单个分区中的非聚集索引结构。

索引的特征
索引有两个特征,即唯一性索引和复合索引。
唯一性索引保证在索引列中的全部数据时唯一的,不会包含重复数据。如果表中已经有一个主键约束或者唯一性约束,那么当创建表或者修改表时,SQL Server自动创建唯一性索引。不过千万不要将创建唯一性索引当成保证数据唯一的方法,而应该创建主键约束或唯一性约束来保证。
复合索引就是一个索引创建在两个列或者多个列上。在搜索时,当两个或者多个列作为一个关键值时,最好在这些列上创建符合索引。
索引与全文索引
全文索引与普通的索引不同。普通的索引时以B-Tree结构来维护的,而全文索引是一种特殊类型的基于标记的功能性索引,是由SQL Server全文引擎服务创建和维护的。主要用来提高对大量文本数据搜索的性能。
总结
聚集索引就是一本书的目录,这个目录上会写 第几章在哪一页,第几节在哪一页,这些都是固定的,你每次去看都一样,这个目录就影响了你要查找的内容的具体位置,比如第101页,也就是比如你要找select语句的章节,那么就是比如第5章的第2节,就是专门讲的select语句的写法。
而非聚集索引,就是书后面的索引,翻开书的最后的索引,你就能看到 select 这个关键字,出现在了 这个关键字:第100页,第108页,第200页,第202页等等,这样方便当你要找一个关键字的时候,迅速的找到相关的页面。
12代码题: 有两个整数a 和b a可以 1 -1 和*2 求把a变成b的最小次数 。用bfs 队列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号