Python+Google Hacking+百度搜索引擎进行信息搜集
记录一下在用python爬取百度链接中遇到的坑:

1.获取百度搜索页面中的域名URL
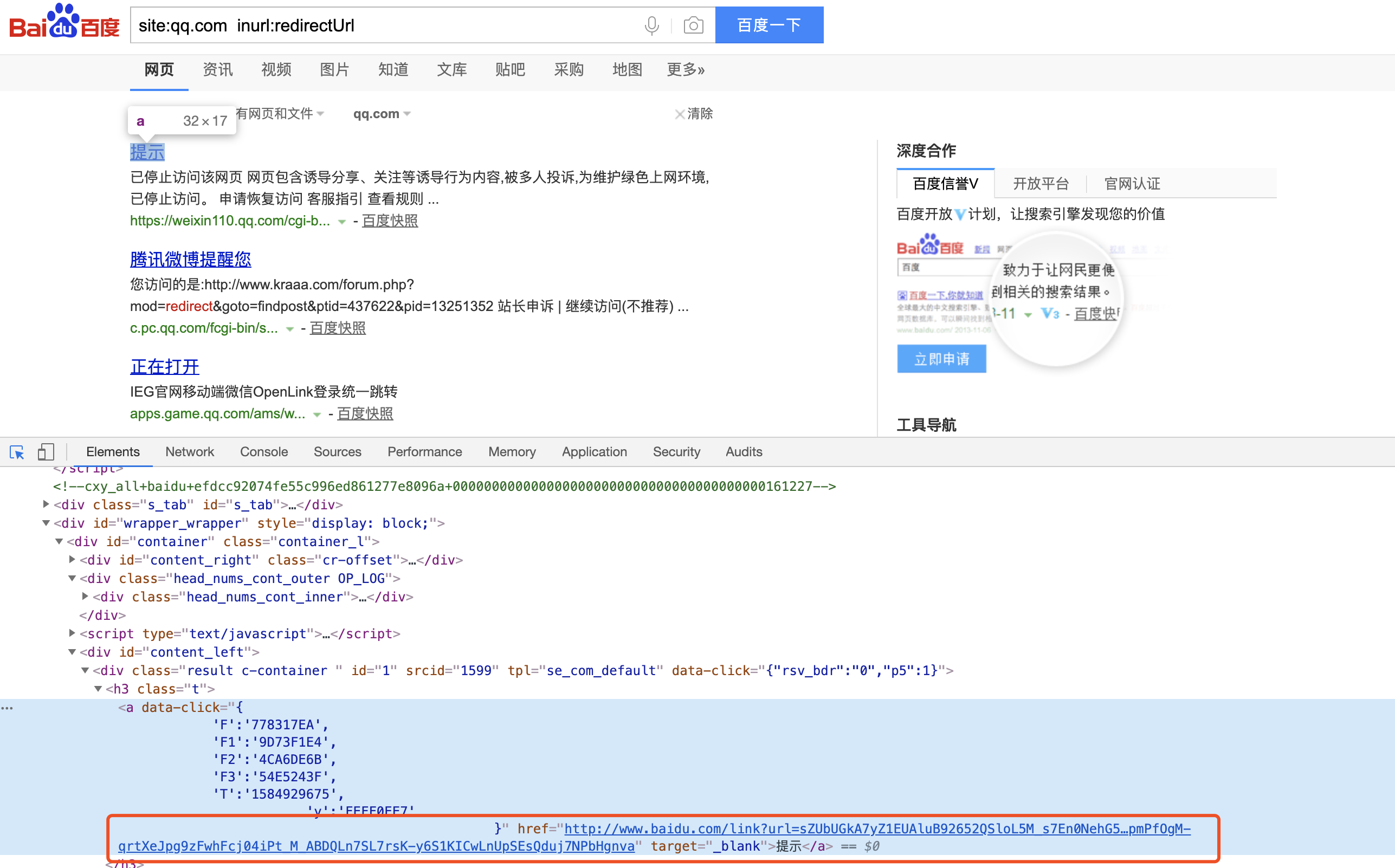
BeautifulSoup获取a标签中href属性后,链接为百度url,利用request直接访问默认会直接进行跳转,无法获取所需域名
此时需要将requests的allow_redirects属性设置为False,禁止进行跳转,requests默认会进行跳转
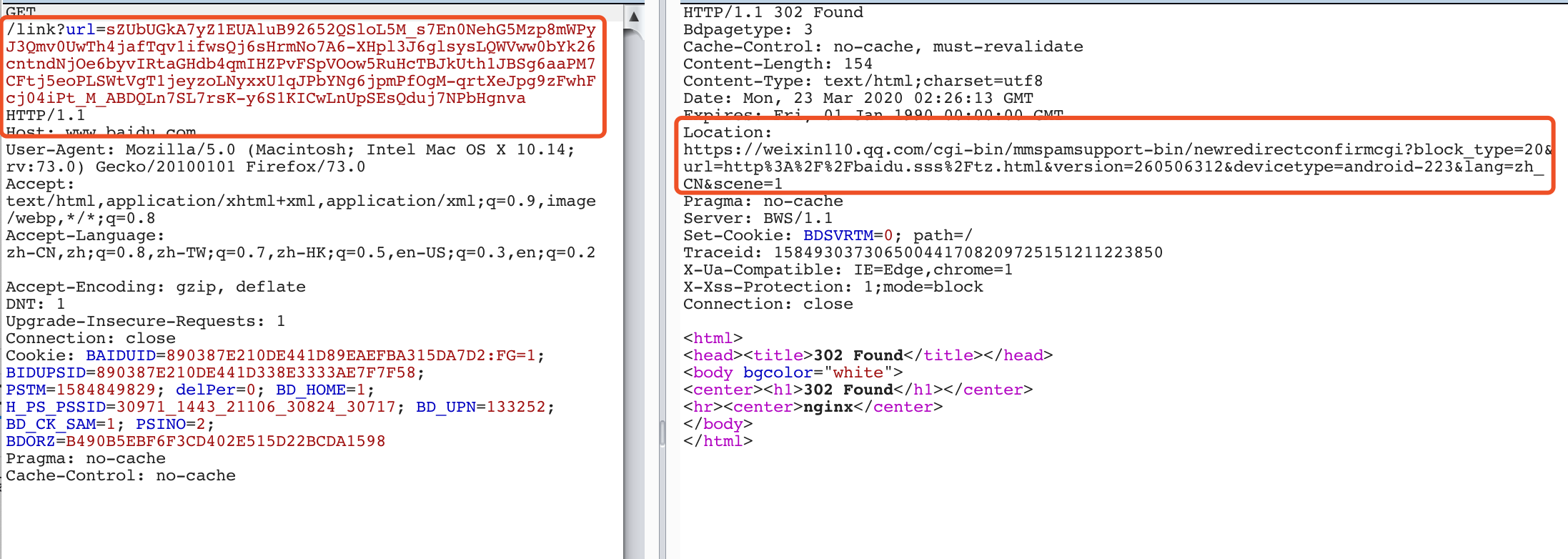
再使用.headers['Location']获取最后链接:final_url = baidu_url.headers['Location']
2.百度中的链接返回不统一
获取到实际域名链接后,发现还有一些奇怪的东西

访问后发现非site搜集域名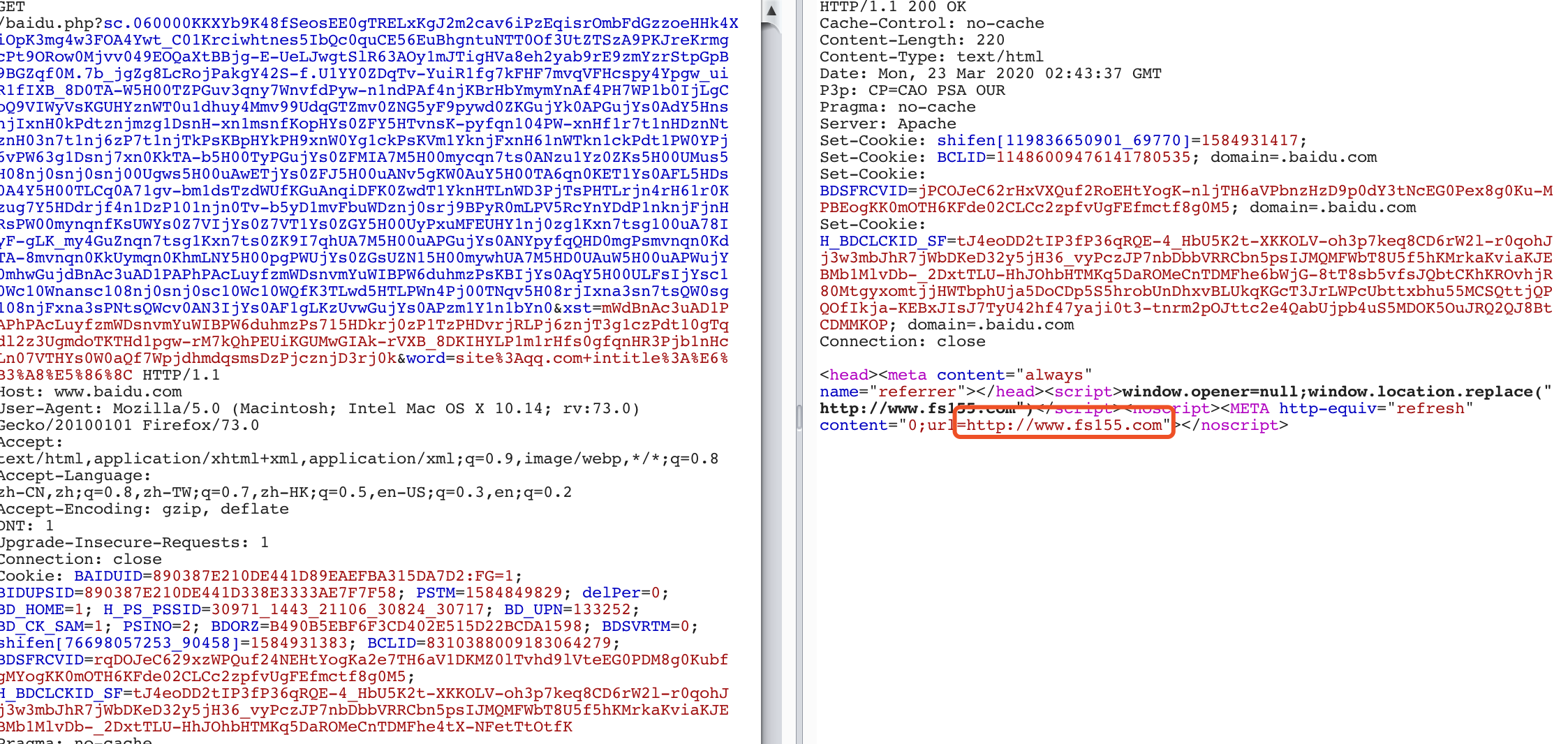
突然想到,很有可能是百度的广告

那就需要筛选出包含baidu.php?的链接去剔除掉
a="baidu.php?"
b="url"
if a in b:来进行筛选
3.百度安全验证绕过
当在百度搜索链接中加入pn页码参数时,便会直接出现百度安全验证(第一次访问就会出现,并不存在请求频繁)

但发现当手动在浏览器去百度进行site语法请求时,并不会出现百度安全验证码,猜想应该是有在HTTP请求头或者参数中漏掉一些参数
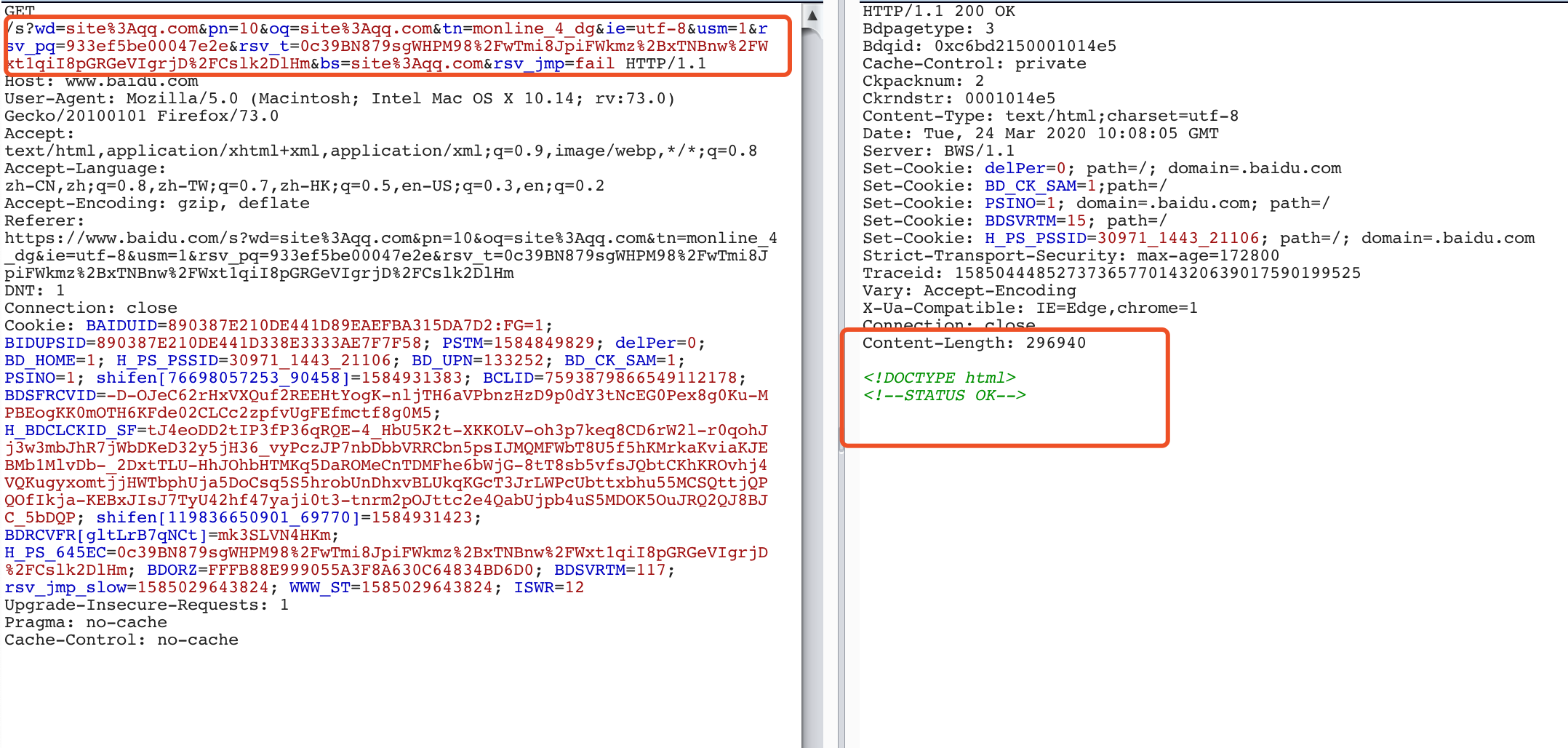
对HTTP请求参数进行一系列不可描述的操作之后,发现还需要"bs"、"rsv_jmp"两个参数
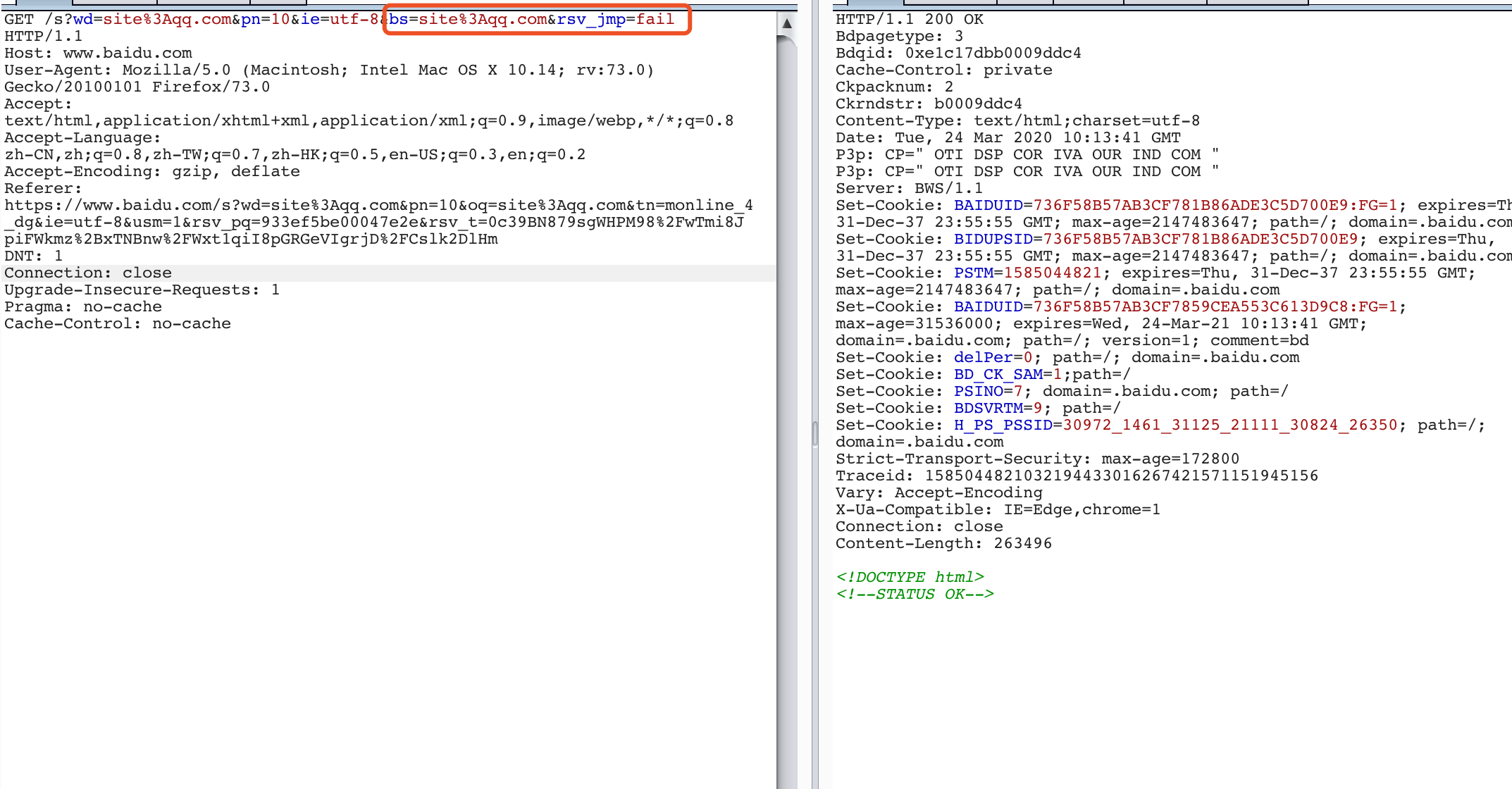
未添加这两个参数时,还存在验证,未获得任何返回数据
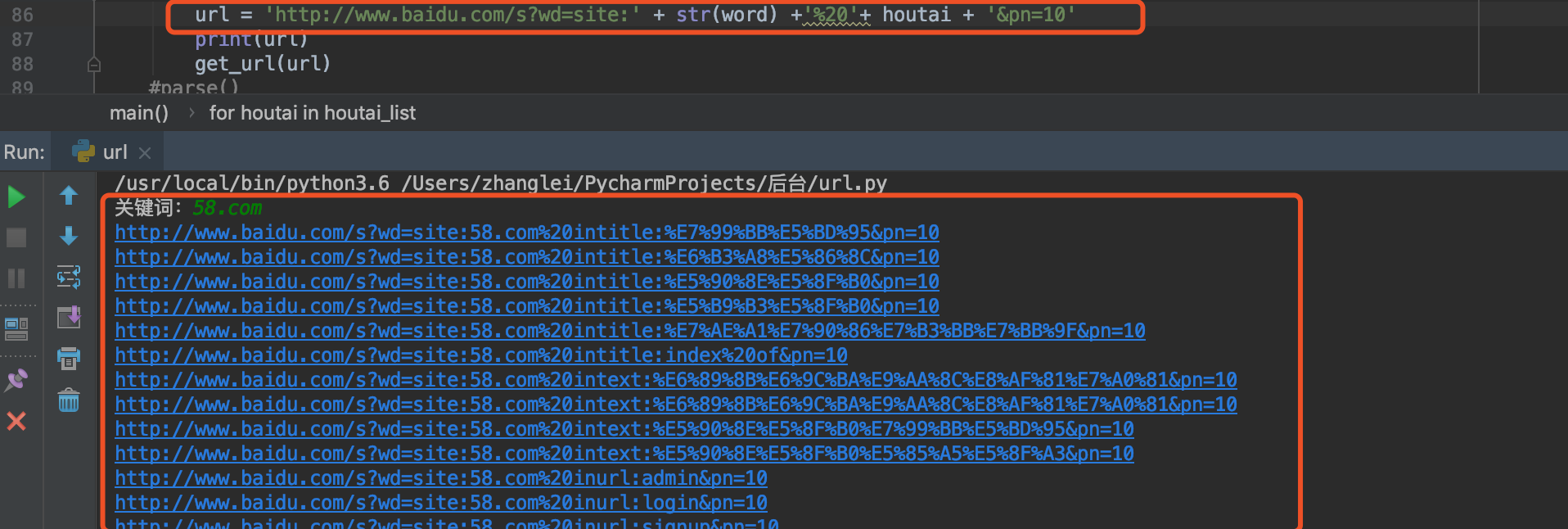
添加之后,已成功获取url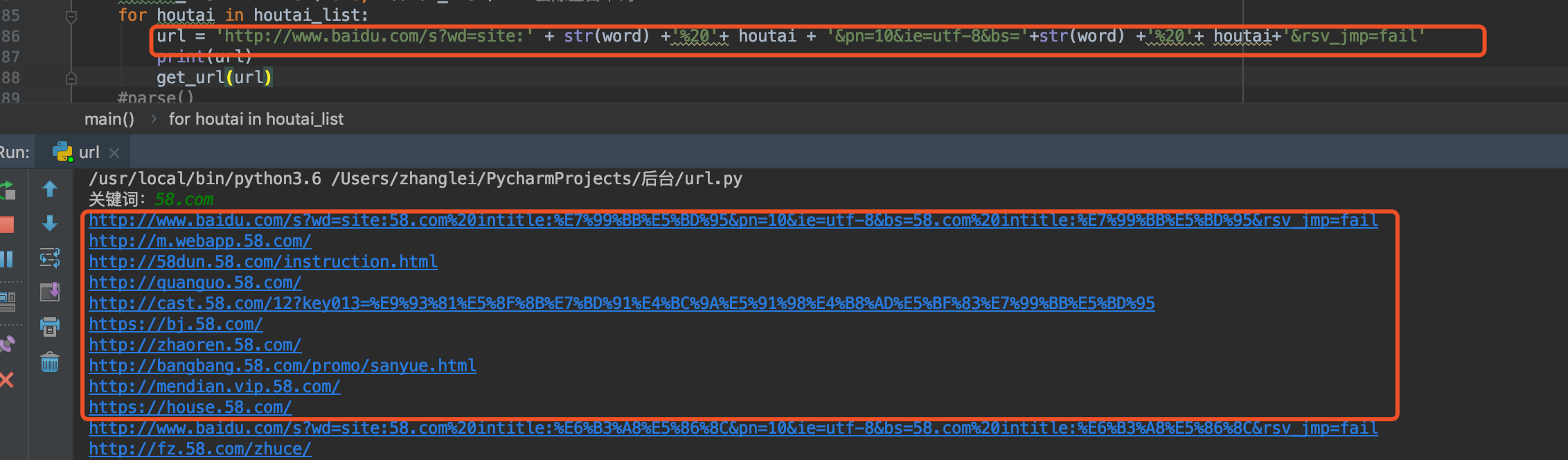
4.获取查询的总页数并去进行遍历
没找到获取总页面的接口,每次请求最多显示10个页面链接,获取之后的还需要去动态进行交互点击
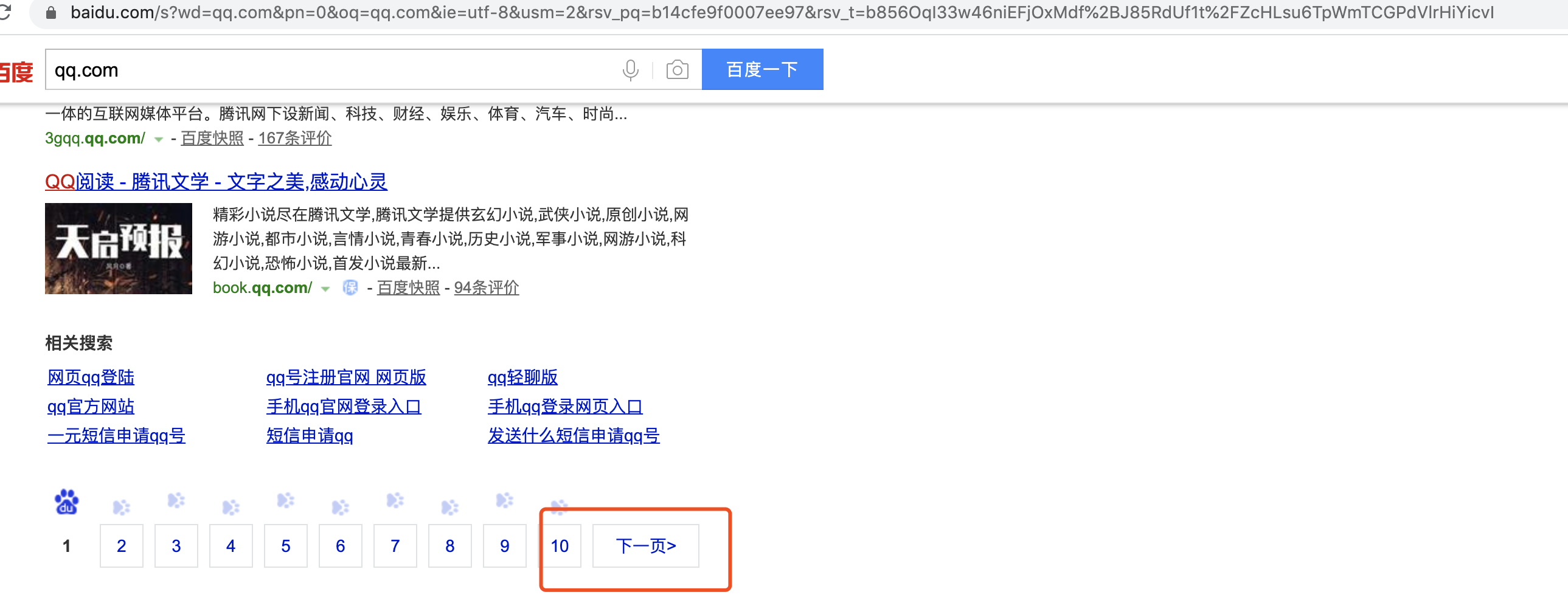
网上也没找到好办法,最后决定采用while循环,来固定遍历前N个页面
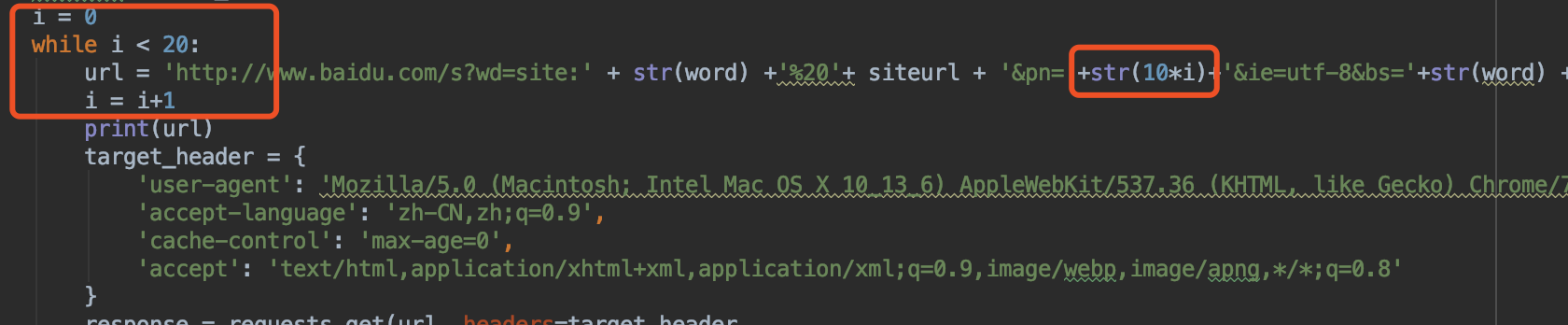
当tagh3长度值为0时直接跳出break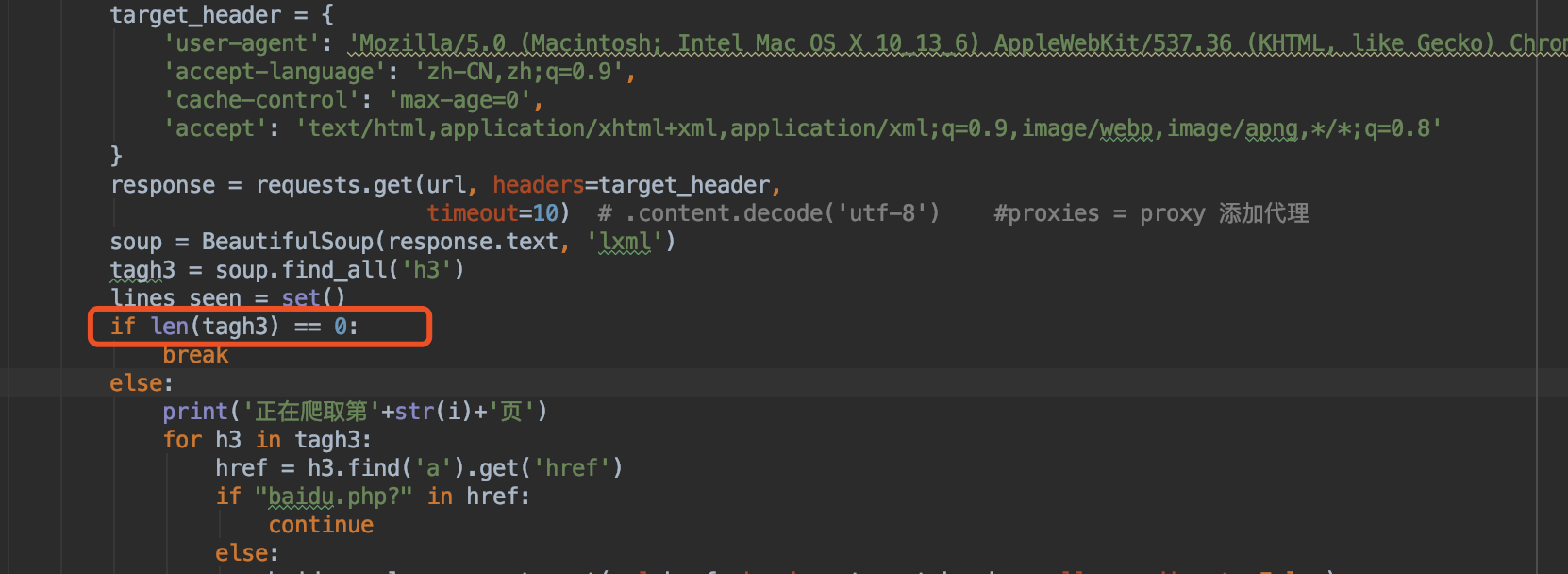
5.链接根域名的去重问题
设置set集合 lines_seen = set()
每次写入url前判断
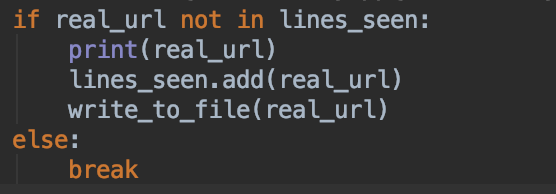
附代码:
tips:url_all.txt为自定义的google hacking语法
import re
import json
from bs4 import BeautifulSoup
import requests
def main(word):
with open('url_all.txt', 'r') as f:
hacking = f.read()
f.close()
url_list = hacking.split('\n') # 生成列表
url_list = filter(None, url_list) # 去除空白单词
for siteurl in url_list:
i = 0
lines_seen = set()
while i < 20:#遍历前20页获取到的链接
url = 'http://www.baidu.com/s?wd=site:' + str(word) +'%20'+ siteurl + '&pn='+str(10*i)+'&ie=utf-8&bs='+str(word) +'%20'+ siteurl+'&rsv_jmp=fail'
i = i+1
print(url)
target_header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
}
response = requests.get(url, headers=target_header,
timeout=10) # .content.decode('utf-8') #proxies = proxy 添加代理
soup = BeautifulSoup(response.text, 'lxml')
tagh3 = soup.find_all('h3')
if len(tagh3) == 0:
break
else:
print('正在爬取第'+str(i)+'页')
for h3 in tagh3:
href = h3.find('a').get('href')
if "baidu.php?" in href:
continue
else:
baidus_url = requests.get(url=href, headers=target_header, allow_redirects=False)
real_url = baidus_url.headers['Location'] # 得到网页原始地址
if real_url not in lines_seen:
print(real_url)
lines_seen.add(real_url)
write_to_file(real_url)
else:
break
if __name__ == '__main__':
word = input("关键词:")
main(word)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号