
索引、分片以及副本的数量和大小原则:
在整理操作流程之前,先了解如何分配索引以及副本个数~
集群(cluster):由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node):单个ElasticSearch实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index):在ES中, 索引是一组文档的集合
分片(shard):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿.
副本(replica):ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.
对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求, 它们的唯一区别在于只有主分片才能处理索引请求.
谨慎分配你的分片
当在ElasticSearch集群中配置好你的索引后, 你要明白在集群运行中你无法调整分片设置. 既便以后你发现需要调整分片数量, 你也只能新建创建并对数据进行重新索引(reindex)(虽然reindex会比较耗时, 但至少能保证你不会停机).
主分片的配置与硬盘分区很类似, 在对一块空的硬盘空间进行分区时, 会要求用户先进行数据备份, 然后配置新的分区, 最后把数据写到新的分区上.
分配分片时主要考虑的你的数据集的增长趋势.
我们也经常会看到一些不必要的过度分片场景. 从ES社区用户对这个热门主题(分片配置)的分享数据来看, 用户可能认为过度分配是个绝对安全的策略(这里讲的过度分配是指对特定数据集, 为每个索引分配了超出当前数据量(文档数)所需要的分片数).
稍有富余是好的, 但过度分配分片却是大错特错. 具体定义多少分片很难有定论, 取决于用户的数据量和使用方式. 100个分片, 即便很少使用也可能是好的;而2个分片, 即便使用非常频繁, 也可能是多余的.
要知道, 你分配的每个分片都是有额外的成本的:
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降
ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
堆内存配置建议:
-
将最小堆大小(Xms)和最大堆大小(Xmx)设置为彼此相等。
-
Elasticsearch可用的堆越多,可用于缓存的内存就越多。但请注意,太多的堆内存可能会使您长时间垃圾收集暂停。
-
将Xmx设置为不超过物理内存的50%,以确保有足够的物理内存留给内核文件系统缓存。
-
不要将Xmx设置为JVM超过32GB。
分片大小建议:
● 宿主机内存大小的一半和31GB,取最小值。
大规模以及日益增长的数据场景
对大数据集, 我们非常鼓励你为索引多分配些分片--当然也要在合理范围内. 上面讲到的每个分片最好不超过30GB的原则依然使用.
不过, 你最好还是能描述出每个节点上只放一个索引分片的必要性. 在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个.
随着数据量的增加,如果你通过集群状态API发现了问题,或者遭遇了性能退化,则只需要增加额外的节点即可. ES会自动帮你完成分片在不同节点上的分布平衡.
再强调一次, 虽然这里我们暂未涉及副本节点的介绍, 但上面的指导原则依然使用: 是否有必要在每个节点上只分配一个索引的分片. 另外, 如果给每个分片分配1个副本, 你所需的节点数将加倍. 如果需要为每个分片分配2个副本, 则需要3倍的节点数。
再次声明, 数据分片也是要有相应资源消耗,并且需要持续投入:
当索引拥有较多分片时, 为了组装查询结果, ES必须单独查询每个分片(当然并行的方式)并对结果进行合并. 所以高性能IO设备(SSDs)和多核处理器无疑对分片性能会有巨大帮助. 尽管如此, 你还是要多关心数据本身的大小,更新频率以及未来的状态.
好了,理论知识晓得了,下面看看实际怎么操作,在创建索引的时候指定分片以及副本的个数:
[root@VM-75-64 conf.d]# curl -XPUT 'http://192.168.75.64:9200/75-64-zabbix' -d '
> {
> "settings" : { #这里的内容是以交互式界面编辑的
> "index" : {
> "number_of_shards" : 6,
> "number_of_replicas" : 0
> }
> }
> }'
{"acknowledged":true,"shards_acknowledged":true,"index":"75-64-zabbix"}[root@VM-75-64 conf.d]#
上面是创建75-64-zabbix索引的指令,设置的分片数为6,副本数为0 ,并且在交互式界面直接就返回了创建结果:true!也就是成功的!
[root@VM-75-64 conf.d]# curl -XGET 'http://192.168.75.64:9200/75-64-zabbix/_settings,_mappings?pretty'
{
"75-64-zabbix" : {
"settings" : {
"index" : {
"creation_date" : "1554175133035",
"number_of_shards" : "6",
"number_of_replicas" : "0",
"uuid" : "_B7JAlnFSwCD694BHxA-zQ",
"version" : {
"created" : "5061699"
},
"provided_name" : "75-64-zabbix"
}
},
"mappings" : { }
}
}
上面就是查看某个索引的指令,其中
_settings:表示基本设置
_mappings:mappings信息
?pretty:以友好的格式展现
索引创建好了,就能在head界面看到配置结果了:

可以看到,分片被均匀的分配在了两个节点中!
那么如何接入logstash呢?
下面跟之前一样,修改logstash的配置文件:

这里分别在input和output中,添加了两段该索引的配置,注意,这里索引的名称一定要严格对应!
重启zabbix服务,让系统产生日志,在区head界面看看有没有收集到!
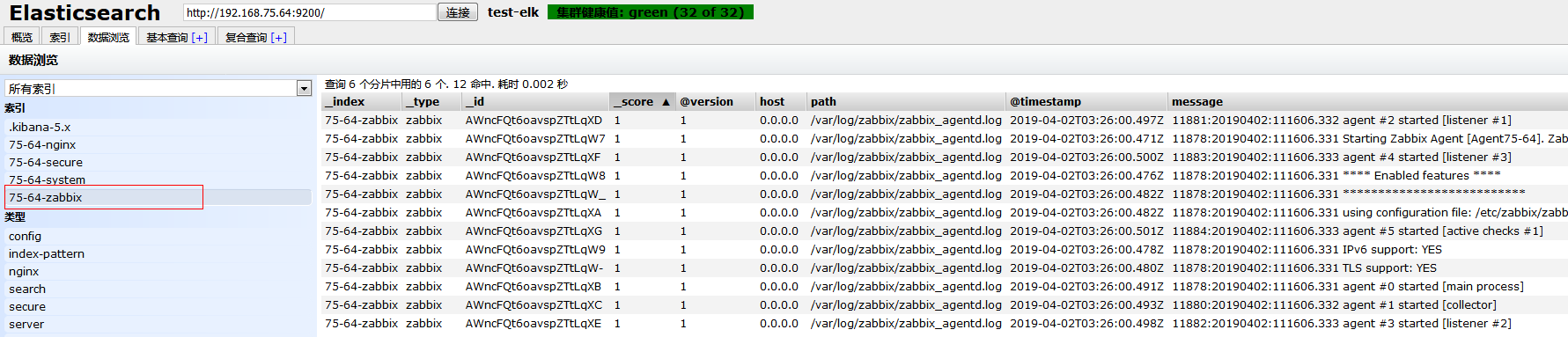
OK,这里看日志拿到了!
同时这里要说明下,一个index创建了之后,分片数时不可修改的,但是副本数是可以随时修改的,那么在哪里修改?
Kibana里!

在kibana的管理界面,有个Dev tools的入口,其中就是执行console语句的框:
PUT:相当于在命令行的-XPUT
75-64-nginx:index名称
_settings:上面提到过了,相关的配置选项
number_of_replicas:副本数量的指定字段
refresh_interval:副本与分片之间的数据延迟时间!这里已经设置成了0,延迟已经没意义了!
回到head界面看下:
还记得在上篇中,nginx标签的分片配置如下图:

此时我们修改了副本数为0,也就是说,上面一排灰色的副本现在没有了,那么,系统会自动重新分配现有的分片数到当前的集群中,效果如下:

可以看到nginx索引副本数已经没有了,分片被重新分配到其他节点上了,之前默认的五个分片是在同一个节点上的!
自动化,科技化,人性化!
以上,共勉!

