基于toyix的进程和轻权进程的学习
我们在平时的计算机课上学习过进程,知道程序的执行的背后其实就是进程在进行一些操作。大家都知道打开windows的任务管理器可以看到正在运行的进程,当程序卡死时,可以在任务管理器里强制关闭相关程序的进程,这样就可以关闭卡死的程序,所以我们知道进程就是程序执行所产生的,但是我们对进程没有很清楚的认识。什么是进程?进程在程序的执行过程中到底起了什么样的作用?我们在toyix平台上来对进程进行研究学习。
一、什么是toyix?
Toyix是王爽老师为了进行操作系统基础理论教学而开发的一个系统。它的特点是既能提供良好的编程体验,又不太复杂。Toyix小巧简单,安装包只有几百kb,解压即可使用;兼容Dos的大多数命令,使用的是tc的编译器。系统部分与UNIX、标准c库函数兼容,具有很好兼容性的编程接口。
二、什么是进程?
进程是程序在计算机上的一次执行活动,当运行一个程序,就启动了一个进程。程序运行活动可以用一个进程模型来描述。就是说进程是我们对程序执行过程的描述,举个例子,程序就像是一台音响,进程就是播放音乐这个动作过程。程序是储存在存储空间中的二进制文件,就像音响一样,是看得见、摸得着的,而进程是一个动作、一个过程,是我们只能想象、只能感受和想象的。我们在任务管理器里停止了进程,只是停止了程序的执行,程序本身并没有被删除,这是因为程序是静态的,进程是动态的,停止进程并不会删除它所使用的数据,就像停止播放音乐并不会损坏音响一样。
我们在电脑上所能看到的所有文件都是存储在电脑中的,就比如下面这个程序:

执行过程如下:
在命令行输入do 1运行程序,发现这里需要输入一个字符才能继续执行,toyix的进程监视器显示ready的进程是1.

按回车程序继续执行,输出一行字符a,这时进程监视器里的running显示的是1.

最后输出完毕,程序执行完毕,进程监视器里的running显示的是0.

在这个程序的执行过程中,我们可以看到在屏幕上输出a时,进程监视器的running显示的是1,它表示这个程序正在执行中,因为程序里有延时函数delay,所以我们可以很清楚地看到输出a的过程,这就是进程处于执行态。我们可以看到,这个过程是动态的,而且它的状态和结果与程序的代码没有关系,不管它是ready、running,不管程序执行成功还是失败,程序的代码还是在那里,不会有任何改变,因为它是静态的。即进程的状态和结果与程序本身无关。
再输入do 1 1执行两次程序:

这时ready显示1和2两个进程号,它表示现在有两个进程等待执行。
按回车让程序继续执行,发现输出了160个a,在输出a的过程中有时running是1,ready是2,有时running是2,ready是1,这表示这两个进程在交替执行。如果没有延时函数,也就是如果程序执行的很快,我们会感觉到这两个程序是同时执行的,这就是为什么我们用计算机可以一边听歌一边用文档打字,在计算机上可以同时使用不同的程序,因为程序是通过进程来执行的,而进程的执行有并发性。
三、进程的三态模型
为什么进程的执行有并发性?因为进程可以交替执行。为什么进程可以交替执行?因为进程有不同的状态,它可以在不同的状态之间转换达到暂停的效果。那么进程有哪几种状态呢?上图中的进程监视器有running、ready、blocked三个字段,它们表示进程的三种执行状态:执行态、就绪态、阻塞态,这三种状态之间的转换关系可以用下图表示:
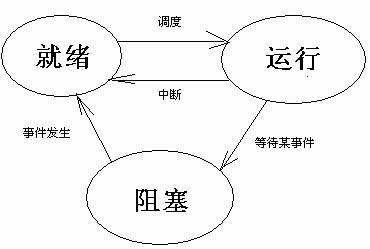
我们在上一个程序执行的过程中发现,我们在执行程序后程序的内容还没有开始执行,这时进程监视器显示进程处于ready就绪态,在我们输入一个字符后进程就进入了运行态,运行完毕后退出,也就是说进程在程序开始是就绪态,之后进入运行态,运行完毕后从运行态退出,即进程的起点是就绪态,终点是运行态,我们来看看这三种状态的具体含义:
1、就绪态:进程分配到除CPU以外的所有资源,只要能获得cpu就能执行。
2、执行态:进程获得cpu正在执行。
3、阻塞态:进程因等待某事件而暂停执行。
所以,我们调用一个程序,就创建了一个进程,这时进程分配了所要的内存空间等资源,但是这时还有没执行,因为没有cpu来计算进程的数据得到结果。如果进程分配到了cpu资源就开始执行,进入运行态,如果这时进程执行过程中要等待某事件才能继续执行,比如要用户进行输入,就会进入阻塞态,即处于暂停的状态,直到事件发生,但是这时cpu还在执行其它进程的计算任务,所以这个进程进入到就绪态,直到分配到cpu的资源再进入执行态继续执行。也就是说,就绪态和阻塞态都是缺少一些东西,就绪态是缺少cpu资源,阻塞态是缺少某件事情的发生,只有运行态是具备一切条件,可以顺利执行程序的,所以在正常情况下运行态是进程的出口。
那么为什么进程要从就绪态开始进入,而不是阻塞态进入呢?因为我们在执行程序后,创建进程并分配好所需的一切资源,这时候是不可能缺少外部的事件的,只有当程序开始执行后,才会需要某些事件的发生。也就是说,就绪态需要的是内部资源,即cpu资源,而阻塞态需要的是外部资源,即某些事件的发生。所以在正常情况下就绪态是进程的入口。
所以我们在执行do 1 1时会发现进程1、2在运行态和就绪态之间相互转化,这说明两个进程在交替使用cpu资源。如果一个处于执行态在使用cpu资源,那么另一个就处于就绪态在等待cpu资源。
我们在程序中加入一个getch函数:

执行结果如下:

当程序执行到getch()时等待键盘输入,我们看到这时进程的状态还是运行态,这是为什么呢?为什么这时是等待外部事件发生,但是进程没有转到阻塞态?查询函数手册可知,getch函数是调用进程循环等待,不会使进程进入阻塞态,而get_char会使进程进入阻塞态来等待输入,我们把程序里的getch换成get_char函数执行来看看结果:

可以看到此时的进程处于阻塞态来等待输入。
所以我们在使用相关函数时要注意它是否是一个阻塞函数,要注意阻塞和循环等待的区别。类似的函数还有gets和get_str、wait和sleep等。要注意我们使用get_str时在进行键盘输入就会唤醒进程,即让进程从阻塞态进入运行态,那么对于阻塞的进程,除了进程需要的事件发生,可以用其他的方式将进程唤醒吗?查询函数手册可知wakeup函数为唤醒原语,那么可以用wakeup函数唤醒阻塞的进程吗?我在上面程序的getch()改成get_char后调用wakeup函数,结果发现没有起作用,这是因为进程在执行get_char函数后就进入了阻塞态,这时程序不往下执行,所以不会执行wakeup语句。但是因为wakeup是唤醒原语,所以要唤醒一个进程一定会使用它,但是可能是在get_char函数中调用,这涉及到进程的三态模型是通过什么来控制的,进程是操作系统执行程序的一种方式和过程,所以是操作系统控制进程在三种状态之间转换。
我们可以体会一下三态模型的思想:进程执行需要一些外部的操作和内部的资源,就绪态是缺少内部的资源(cpu),这是内因,阻塞态是缺少外部的资源(事件的发生),这是外因,当内因和外因都具备时就可以转到运行态执行了。在这里,cpu资源是最宝贵的,它直接决定了计算机和程序的运行速度,所以进程思想和三态模型的出现都是为了最大程度地分配和利用cpu资源。
四、进程的创建
进程的创建也是操作系统所要做的工作,当我们执行一个程序时,操作系统就会创建与这个程序完成相关的进程,不需要我们手动创建。我们可以用get_pid函数得到调用进程的进程号:
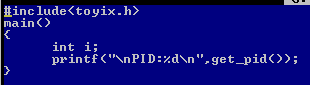
用do 1执行程序,结果如下:

发现结果进程的序列号为1,在进程就绪状态进程监视器显示的进程号也为1。
我们再用do 1 1 1执行三个进程:
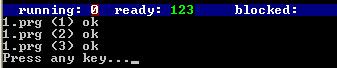
可以看到程序创建了三个进程,它们的进程号分别为1、2、3.
也就是说,这里进程号是从1开始连续分配的,每执行一次程序就创建一个进程,那么一个程序可以创建开启多个进程吗?我们可以使用fork函数和frk函数来创建多个进程。
Fork函数的作用是创建一个与父进程相同的子进程:

执行结果为:
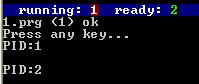
Fork创建了一个子进程,所以打印出了2个进程号。我们把创建新进程前的进程叫做父进程,把创建新进程后的进程叫做子进程,那么这两个进程哪个是父进程,哪个是子进程呢?我们是无法通过它们的进程号来区分的,但是我们知道fork函数在创建进程成功后,在父进程中会返回子进程的进程号,在子进程中会返回0,也就是说,在父进程中fork()的值是一个非0值,而在子进程中,fork()的值为0.那么我们可以通过判断fork()的值是否为0来判断这个进程是父进程还是子进程:
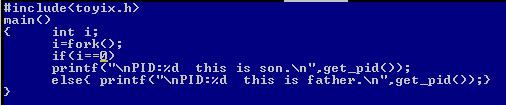
执行结果如下:

有程序的执行结果可知,进程1是父进程,进程2是子进程。
Fork函数有两个特点:1、父子进程不共享数据段。2、父进程结束后不撤销子进程。
什么是数据段呢?进程是程序的执行过程,它的执行需要调用程序里设置的数据来给cpu进行计算得到需要的结果,这些程序里设置的数据就存储在一段存储空间里,这个空间就叫做这个进程的数据段,它是进程所需资源的一种,是在创建进程时由操作系统分配给进程的。
进程一般由控制信息和本体信息组成,进程号就属于进程的控制信息,本体信息一般是由代码段、数据段、栈段所组成。栈段是用来保存如cpu现场等进程的特有信息,我们知道局部变量就是用栈段存储的,比如上面的变量i,它在父子进程中的值是不同的,所以我们可以知道栈段是不可能被父子进程共享的。我们知道全局变量是存放在数据段里的,要验证数据段是否共享,我们可以对全局变量进行操作和打印:
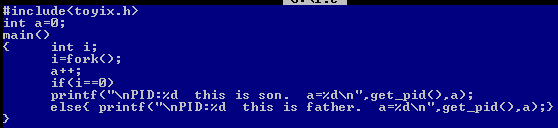
执行结果为:

所以这里打印的a的值都为1,而如果两个进程共享一个数据段,那么a会自加2次,输出的结果应该为2。所以这里的两个进程没有共享数据段。
要判断两个进程的代码段是否共享,只需要看看它们代码段的地址是否相同即可,我们打印这两个进程的地址:

执行结果如下:

我们可以看到这两个进程的代码段并不一样,所以它们的代码段不是共享的。所以fork函数创建的两个进程的代码段、数据段、栈段都是不共享的。而且我们注意到父进程是先打印的,也就是说父进程是先执行的,在父进程执行后子进程并没有被撤销。
那么frk函数和fork函数有什么区别呢?由函数手册可知,frk函数也是创建一个与父进程相同的子进程,而它的不同之处是这两个进程是共享数据段的,而且如果父进程结束了,子进程也会被撤销。
我们将上面的函数里的fork函数改成frk函数来执行:
第一个程序修改如下,这里在a++后面调用delay函数是为了在父进程a++执行完后,子进程有足够的时间去完成a++操作,如果父进程的a++执行后就执行下面的打印语句,子进程可能还没有执行a++,那么可能的结果就是父进程打印出来的a的值为1,子进程打印出来的值为2:
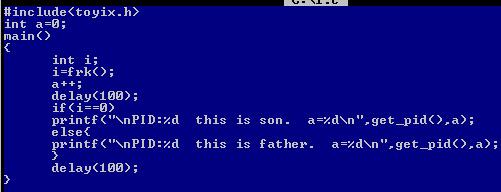
执行结果如下:

这里打印出来a的值都为2,说明了这两个进程是共享数据段的。
我们把第二个程序修改为如下:

这里程序最后的delay(100)的作用也是让父进程暂停等待子进程执行,否则父进程结束后会撤销子进程,那么子进程的打印语句就无法执行。
执行结果如下:

这里的打印出来的两个函数的代码段地址不同,所以frk创建的子进程也不与父进程共享代码段。我们注意到子进程打印出来的地址是一个错误的地址,因为我们是用十六进制打印的地址,而r是不属于十六进制的数的,如果用十进制打印,结果如下:

这个地址应该是正确地地址,那么为什么用十六进制打印会出现错误的地址呢?按理说%x不应该输出大于f的值,那么我觉得可能是这里printf里对%x的实现有问题。
如果上面的程序最后不加delay(100),执行结果如下:

因为父进程在执行完后撤销了子进程,所以只有父进程执行了printf函数。
所以我们得到的结论是frk函数创建的子进程与父进程共享数据段,不共享代码段和栈段。
我们之前在讨论进程的三态模型时发现在正常情况下,进程是从运行态退出的,但是frk函数创建的子进程可能没有执行完就因为父进程的结束而被撤销了,这是为什么呢?查询资料发现,实际上还存在从就绪态或者阻塞态到结束状态的释放转换。进程的退出可以分为正常退出和异常退出,异常退出的原因包括进程执行超时、内存不足、非法指令或地址访问、I/O操作失败、被其他进程所终止等,比如父进程可以在任何时间终止子进程,只是fork中设置的是父进程退出不撤销子进程,而frk中设置的是父进程结束时撤销子进程,我们也可以写一个函数创建子进程,并在父进程执行时就撤销它。
那么为什么fork函数和frk函数的功能差不多,但是一个共享数据段、一个不共享数据段呢?我们知道进程包含数据段,而fork创建的子进程不与父进程共享数据段,所以在创建时系统要把父进程数据段的内容复制到子进程的数据段中,这会造成一定的开销,而且也不利于父子进程间交换数据,所以fork和frk创建的进程各有特点。为了区别fork创建的进程,我们把frk创建的进程叫做轻权进程。
虽然frk和fork创建的子进程都不与父进程共享代码段,但是父子进程代码段的内容都是一样的,怎么让子进程的代码段的内容与父进程不一样呢?我们可以用exec函数,它的功能是执行一个可执行文件,创建一个进程覆盖当前的进程,这样我们就可以在生成的子进程中创建一个新的进程,而这个新的进程可以执行与父进程完全不同的功能。如下,编写程序1为:

程序2为:
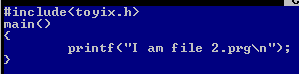
执行结果为:
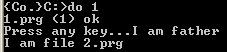
程序中子进程在执行exec函数后被新建的2.prg的进程所覆盖,从而执行2.prg的内容,这样就可以使进程1的子进程运行时启动2.prg的进程了。
如果把exec放到父进程里面会怎么样呢?

执行结果如下:
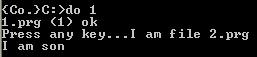
父进程被覆盖了,那么再把fork换成frk试试看:

执行结果如下:

只执行了主进程的内容,这是因为frk的父进程在结束时会撤销轻权进程,这是因为主进程和轻权进程共享一个数据段,主进程结束后会释放数据段,如果这时轻权进程还存在的话,就会继续使用数据段,但是这时数据段已经被释放了,可能内存空间已经被别的程序使用,如果继续使用会出错,所以必须要撤销轻权进程。但是如果我们在主进程里添加延时函数或者输入函数,等到轻权进程执行,就可以达到之前程序的结果。
那么如果exec是在轻权进程中执行,它所创建的进程还是轻权进程吗?Exec函数是执行一个完全不同的程序,那么这个程序的数据段肯定与当前程序不同,即新的进程不与主进程共享数据段,那么它就不是一个轻权进程。所以我们在轻权进程中用exec创建的进程是一个普通进程而不是轻权进程。我们可以实现程序来证明:
程序1为:

程序2为:

执行结果为:

结果发现在执行2.prg的过程中,也就是输出a的过程中我们按回车结束主进程,但是此时还是在继续输出a,这说明当主进程结束后,exec创建的进程并没有被撤销,而是继续执行。这说明exec创建的不是轻权进程。
那么如果exec函数在主进程中,能够用新创建的进程覆盖主进程吗?我们将程序1修改为如下:

执行结果为:
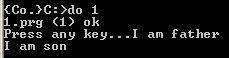
可见exec并没有创建执行新的进程,主进程也没有被覆盖。查看函数手册发现exec如果执行失败了exec会返回-1.用printf函数打印exec的值,发现果然是-1:

那么就说明exec执行失败了,为什么它会执行失败呢?因为现在主进程如果被覆盖,那么它的数据段就会释放,但是此时轻权进程还要继续使用这个数据段,会发生错误,所以主进程无法被覆盖。要使exec能够执行成功,第一可以使轻权进程在主进程被覆盖前就执行完毕,第二可以使轻权进程通过exec升级成为一个普通进程,第三可以使用fork来创建子进程。我们修改程序,用getch()使主进程等待直到轻权进程执行完毕。

执行结果如下:

果然,轻权进程结束后,主进程执行exec成功创建新进程覆盖了主进程。
用do 1 1将上面的程序执行两个进程,结果过如下:

发现在这个过程中当打印第一行a的时候进程监视器显示进程1在执行,进程2是就绪态,但是当第一行a输出完了显示的还是进程1在执行,进程2没有了。那么难道第一行a是进程2创建的新进程输出的?,但是这个过程中进程1才是处在执行态。我们来分析一下过程:首先进程1和2的轻权进程都执行完,进程1的getch()收到了输入的消息,执行exec创建一个新的进程覆盖原来的进程1,这个新的进程的进程号就是1,然后它执行输出,执行完毕后结束,这时就只有处于就绪态的进程2了,进程2执行exec创建一个新的进程,因为之前的进程1不存在了,所以这一个新的进程的进程号就是1,所以我们才会看到进程1一直处于执行态。
五、进程间的通信
我们可以用fork、frk、cobegin函数创建多个进程并使它们并发执行,进程的执行需要一些资源,那么当多个进程并发执行时要使用相同的资源怎么办?我们把一个全局变量当作资源,设计两个进程都对这个全局变量进行操作:
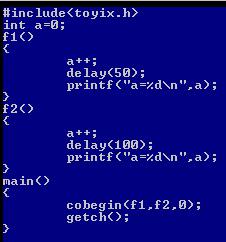
执行结果如下:

如果这两个进程并发执行的话,第一个进程先使用资源,对a加1并输出,那么先输出的应该是a=1,第二个进程输出的是a=2。为什么这两个进程输出的都是a=2呢?因为f1中有延时函数delay(50),在f1延时时f2的进程对a加了1,所以f1输出a的时候a的值已经变成了2.也就是说f1和f2的进程并发执行有可能导致f1和f2的公共资源使用出错。那么怎么解决这个问题呢?要得到正确的结果,就要让一个进程的执行过程中不会被其他进程所干扰,形成进程互斥。即让一个进程的执行内容像一个原子操作,具有原子性。
我们可以使用PV原语来保证进程的原子性,PV原语是对于信号量的操作,信号量的值代表有几个资源,P操作是将信号量减1,如果执行后信号量大于等于0,就继续执行,否则将该进程堵塞并置于该信号量的阻塞队列中。V操作是对信号量加1,如果执行后信号量的值大于0,那么就将继续执行,否则从该信号量的等待队列中唤醒一个等待的进程。也就是说,P操作是将当前进程由运行态转为阻塞态,而V操作是将一个阻塞态的进程转成就绪态。而他们对进程的阻塞和唤醒是根据当前信号量的值来判断的,因为信号量的值就代表了当前资源的数目。
我们使用PV操作来对上面的程序进行修改:


执行结果为:

执行结果是正确的。我们先将信号量的值设置为1,然后将f1、f2并发执行,这时如果f1先执行,执行p操作,s=0,进程继续执行,此时如果执行进程2,执行p操作,s=-1<0,进程就会被阻塞放入等待队列中,f1的进程就会继续执行,当执行到v操作,s=0,不符合执行条件,则唤醒等待队列中的f2的进程,当f2的v操作执行完,这时s=1可以通过,则进程执行完成。所以在f1进程执行过过程中,不管有多少进程执行了,都会被转到阻塞态,s可能会很小,但是在当前进程执行v操作时会不停唤醒等待队列中的进程直到s大于0,所以在当前进程执行时不会有其他的进程来执行,这样就实现了进程的互斥性。
这里我们所说的进程间的通信,指的就是进程能够一个一个来执行,不会“抢”,通过信号量还有PV操作,我们实现了进程的互斥性,就是进程间像是能够通信一样,当一个进程运行时,其他进程全部阻塞。
六、生产者、消费者问题
生产者-消费者问题也称有限缓冲问题,是一个多线程同步的经典案例。该问题描述了两个共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
生产者、消费者问题有几种形式,我们来分别讨论:
(1)一个生产者、一个消费者,公用一个缓冲区
这里我们设置三个信号量s、empty、full,s表示缓冲区的个数,初值为1;empty表示缓冲区的大小,初值为20,即我们假设缓冲区最多能放20个产品;full表示缓冲区是否为空,初值为0。实现的程序如下:


程序中,我们用producer()来表示生产者,用consumer()来表示消费者,生产者生产一件产品要占用要判断缓冲区是否未满,即剩余空间empty减一之后是否还大于等于0,所以先对empty进行p操作,之后用p(&s)判断缓冲区是否被占用,再进行生产(product加一并输出)后用v操作释放缓冲区,再执行v操作对full加1判断是否大于0,即缓冲区是否为空,如果为不为空则继续执行,因为full的初值为0,而生产者进程执行的时间片完后轮到消费者进程,对full进行p操作是-1,消费者进程被堵塞再执行生产者进程,执行到v(&full)时,full加1变成0,所以唤醒消费者进程,p(&full),full变成-1,再被堵塞,执行生产者进程,所以生产者进程和消费者进程会不断交替执行。为了使产品累加起来便于观察,我用延时函数delay使生产者生产产品的周期比消费者消费产品的周期要短。我们来观察程序的执行过程:



观察结果:首先生产者不停生产产品到10个,然后生产者一边生产、消费者一边消费,因为生产者的生产的速度比消费者消费的速度要快,所以产品还是在逐渐地累加一直到20,之后就是生产者生产一件产品、消费者消费一件产品,达到一个比较平衡的状态。
(2)一个生产者、一个消费者、公用n个环形缓冲区
这里比较特别的是缓冲池被分为多个环形缓冲区,也就是说,如果第一个缓冲区满了,那么生产者生产的产品只能放在第二个缓冲区中,如果第n个缓冲区满了,那么生产者就要再从第一个缓冲区开始放,消费者也是一样,如果第一个缓冲区里有产品而第二个里面没有,那么消费者就只能从第一个缓冲区中拿产品。因为缓冲区是环形的,要确定当前缓冲区是哪一个,我们可以用模运算求得。程序如下:
1 #include<toyix.h> 2 semaphore s,empty,full; 3 int product[10]={0}; 4 producer() 5 { 6 int in=0; 7 while(1) 8 { 9 delay(20); 10 p(&empty); 11 p(&s); 12 printf("Producer: There are %d products in NO.%d buffer\n",++product[in],in); 13 in=(in+1)%10; 14 v(&s); 15 v(&full); 16 } 17 } 18 consumer() 19 { 20 int out=0; 21 while(1) 22 { 23 delay(400); 24 p(&full); 25 p(&s); 26 printf("Consumer: There are %d products in NO.%d buffer\n",--product[out],out); 27 out=(out+1)%10; 28 v(&s); 29 v(&empty); 30 } 31 } 32 main() 33 { 34 set(&s,1); 35 set(&empty,20); 36 set(&full,0); 37 cobegin(producer,consumer,0); 38 getch(); 39 }
(3)一组生产者、一组消费者,公用n个环形缓冲区
因为有多个生产者和多个消费者,生产者之间存在互斥关系,消费者之间也存在互斥关系。所以我们要用信号量来控制一个时间只能有一个生产者在生产,一个消费者在消费。所以我们设mutex1为生产者之间的互斥信号量,初值为1,mutex2为消费者之间的互斥信号量,初值为2.,程序如下:
#include<toyix.h> semaphore s,empty,full,mutex1,mutex2; int product[10]={0}; producer() { int in=0; while(1) { delay(20); p(&empty); p(&mutex1); p(&s); printf("Producer: There are %d products in NO.%d buffer\n",++product[in],in); in=(in+1)%10; v(&s); v(&mutex1); v(&full); } } consumer() { int out=0; while(1) { delay(400); p(&full); p(&mutex2); p(&s); printf("Consumer: There are %d products in NO.%d buffer\n",--product[out],out); out=(out+1)%10; v(&s); v(&mutex2); v(&empty); } } main() { set(&s,1); set(&empty,20); set(&full,0); set(&mutex1,1); set(&mutex2,1); cobegin(producer,consumer,0); getch(); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号