海报编辑器开发
目标:通过拖拽的形式或自动生成宣传页
最小化实现: 使用无头浏览器截图
海报编辑器需求
市场中已经存在 “易企秀” 和“泥石流海报” 所以只需要原样照抄即可。 所以这里只剩下技术问题
需求分析和架构设计
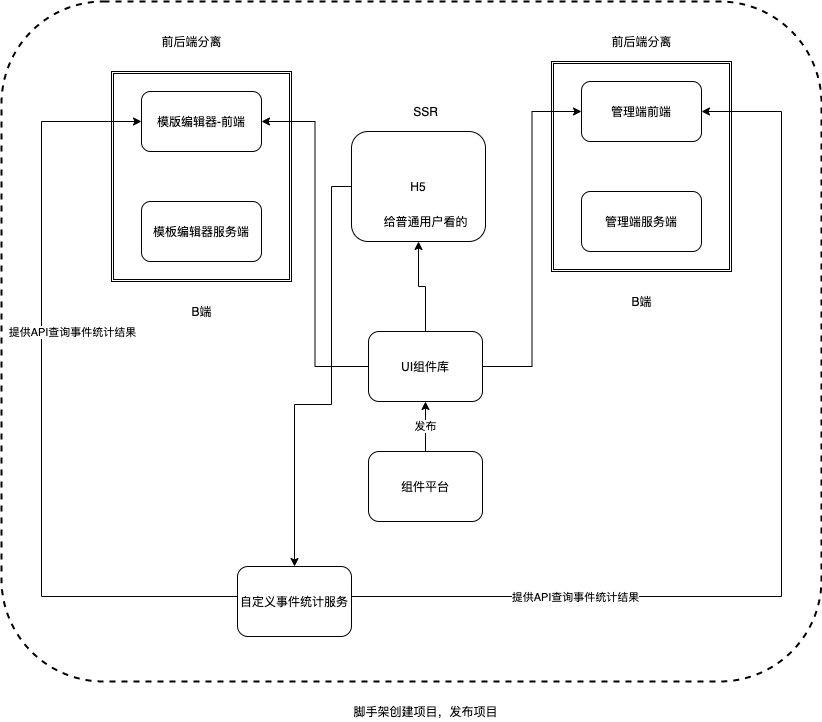
项目构成
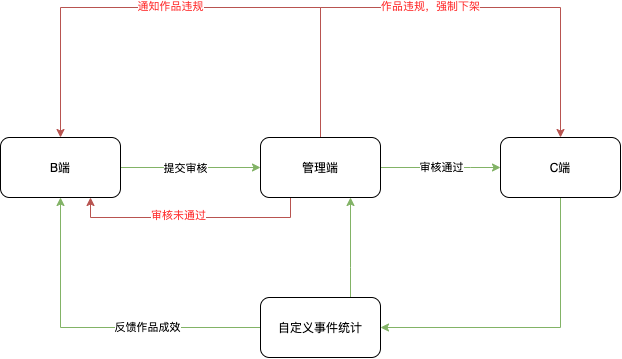
分成B端(内容制作端)、C端(消费端,玩家端)、管理端(管理B端和C端),以上每个都有对应的服务端,整个项目由脚手架创建并管理,发布等,如下图所示
项目的浅层需求
表面需求
- 登录
- 创建一个作品, 编辑,发布
- 访问作品H5
- 用户信息
- 登录
- 注册
- 获取用户信息
- 作品
- 创建
- 保存
- 发布
- 获取作品信息
- 获取作品列表
- 模板
- 模板列表
- 使用模板创建
项目的深层需求
不容易一眼看到,但很重要的需求。
作品的管理
- 删除和恢复
- 转赠(员工离职交接工作)
- 复制
作品统计
需求闭环, 有输入有输出,创建发布了作品,当然要看一看统计结果。
- 统计
- 分渠道统计,渠道对于运营人员非常重要。
作品发布
- URL不能变
- 支持多渠道
H5
- 分享--- 对业务增长负责,这里就能体现
后台管理
全局把控,让一切尽在掌握之中。
- 数据统计
- 作品管理,能快速下线作品,防止有违规内容
- 用户管理,能快速冻结用户,防止有违规用户
- 模板管理,能控制哪些模块展示,哪些不展示
需求总结
对象
制作人,管理员 作品(成果物), 创作工具
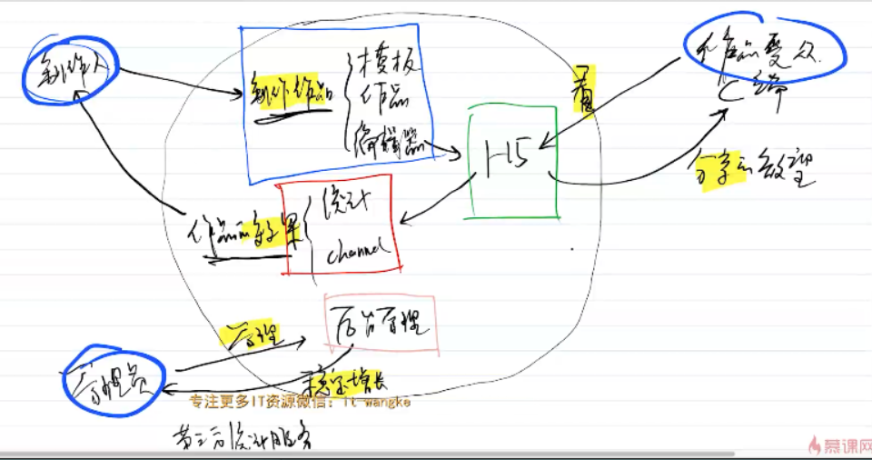
子项目关系
- 这里子项目是指B端、C端这些项目
B端是任务发起者,或者说内容制作者使用的客户端,B端完成内容创建后供C端使用,C端是消费端,B端和C端同样是客户端,需要用同样的前端组件库以保证两端的页面渲染是一样的,C端产生效益,需要另外的服务用于统计产品被访问次数以及分享次数,此服务还需向B端和管理端提供查询接口,方便运营统计以及作为未来业务发展的导向
- 特殊模块说明:自定义事件统一,在三个模块之外,组件库要独立出
核心数据结构
数据结构要求
- 每个组件尽量符合 vnode 规范
- 尽量使用引用关系,不要冗余
{
work: {
title: '作品标题',
setting: {}, // 一些可能的配置项 扩展性保证
props: {}, // 页面的一些设置 扩展性保证
components: [
{
id: '1',
name: '文本1',
tag: 'text',
attrs: {
fontSize: '20px'
},
children: ['文本1']
},
{
id: '2',
name: '图片1',
tag: 'image',
attrs: {
src: 'xxx.png',
width: '120px'
},
children: null
}
]
}
}
server 端架构设计
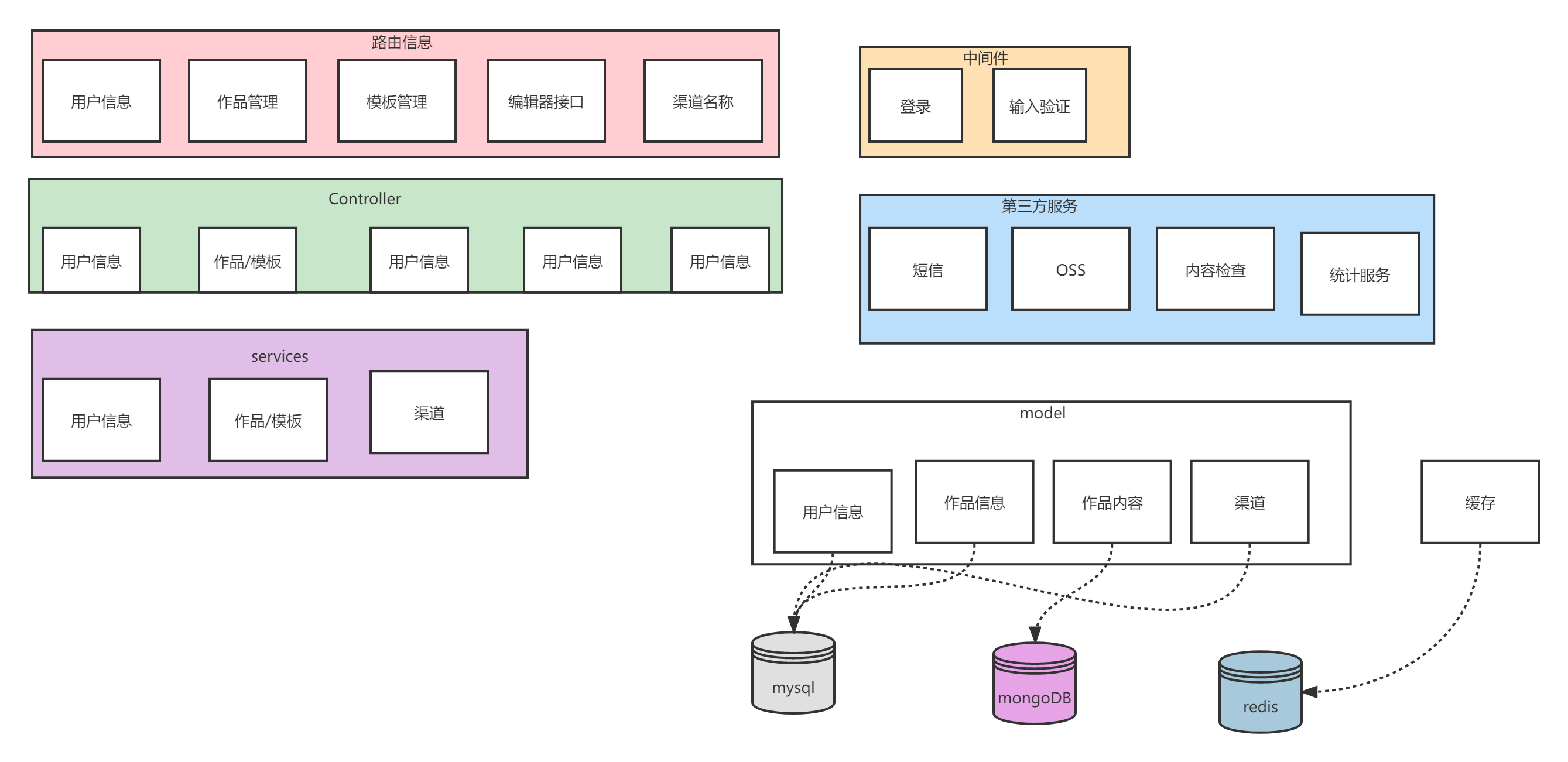
数据流转
如何以架构师思维分析需求
脱离业务的架构就是刷流氓,架构师必须要深入理解,参与需求,看透需求背后的本质。
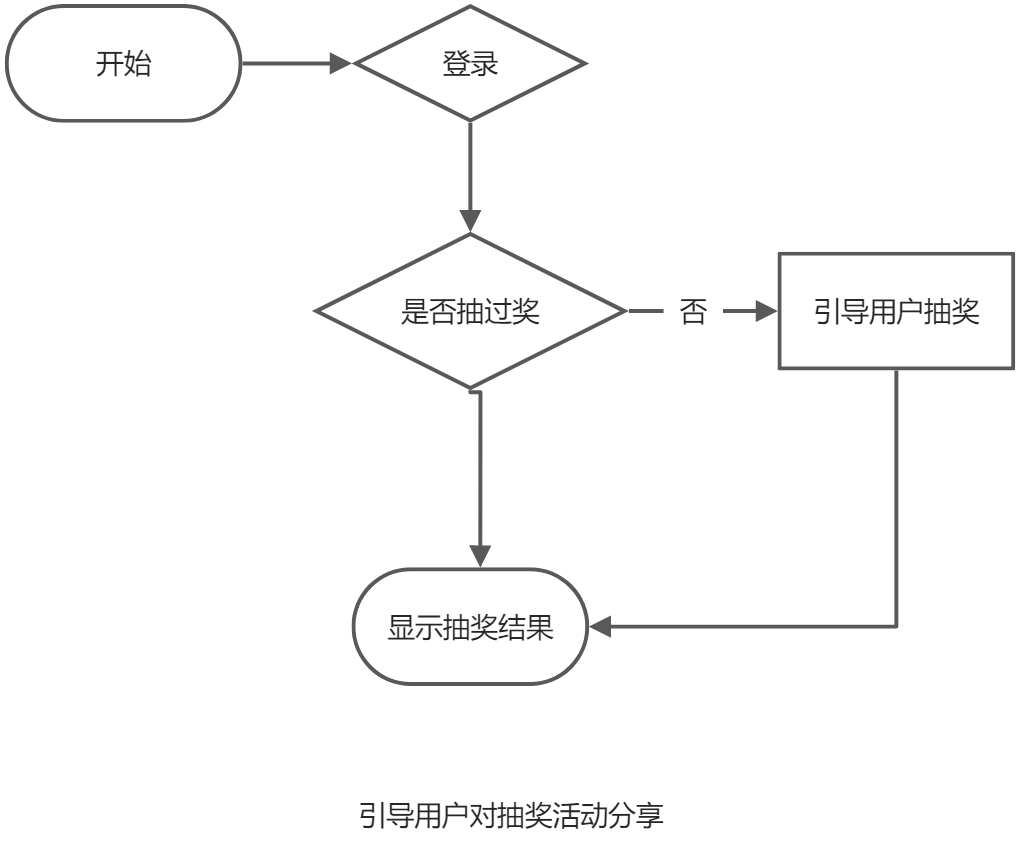
面试题: 作为前端复负责人,来开发一个h5 页,某个抽奖活动的运营活动,假设PM和RD都是实习生,技术和业务都不熟练, 你要从0开发这个页面,你会要求server端给你提供哪些接口和能力?
扩展性保障
- 组件库扩展
- 编辑器扩展
- 数据结构扩展
其他
开发提效: 使用脚手架工具
运维保障
- 线上服务和运维服务
- 安全
- 服务扩展:流量大时怎么办
需求分析:
技术方案设计文档
技术方案设计
核心数据结构设计
关键词
- 流程图---分析需求的工具
- 全局思维,整体思维, 闭环思维---架构师思维来分析需求
- 业务组件库--独立拆分出来,复用
- 自定义事件统计-- 业务的重要性,如何实现
学习方法
- 有耐心,不要一心想着写代码,觉得需求和设计不重要
- 抛开你固有的程序员思维,开始准备接受架构师思维
- 要坚信:技术永远都是为业务服务的,技术是实现业务增长的工具。
注意事项
- 不要关注细节,要看整体,看范围
- 设计时要判断可行性,不确定的就要调研一下
- 设计时压迫考虑复杂度,越简单越好不要过度设计,不要为了设计而设计
整体架构设计
技术永远都是为了业务而服务的
熟悉需求后,就要考虑如何把它做出来。
如何写技术方案设计
主要内容
需要哪些项目,各项目之间的关系
独立的业务组件库
为何要自研自定义事件统计服务
作品的数据结构设计
写《技术方案设计》文档
注意事项
- 不要关注细节,要看整体,看范围
- 考虑扩展性(这就需要深入理解业务,否则你也不知道未来将如何扩展)
- 考虑可行性,不确定的就调研一下
- 考虑实现成本, 不要为了设计而设计,技术要永远服务与业务。---永远选择最简单的实现方案。
分析需求,确定要创建的项目
先不看细节,看整体,这一步就是确定项目的范围。确定范围就是做任何事情的第一步。
范围确定好了,剩下的事情,即便有问题,也属于“人民内部矛盾”。
需要哪些项目
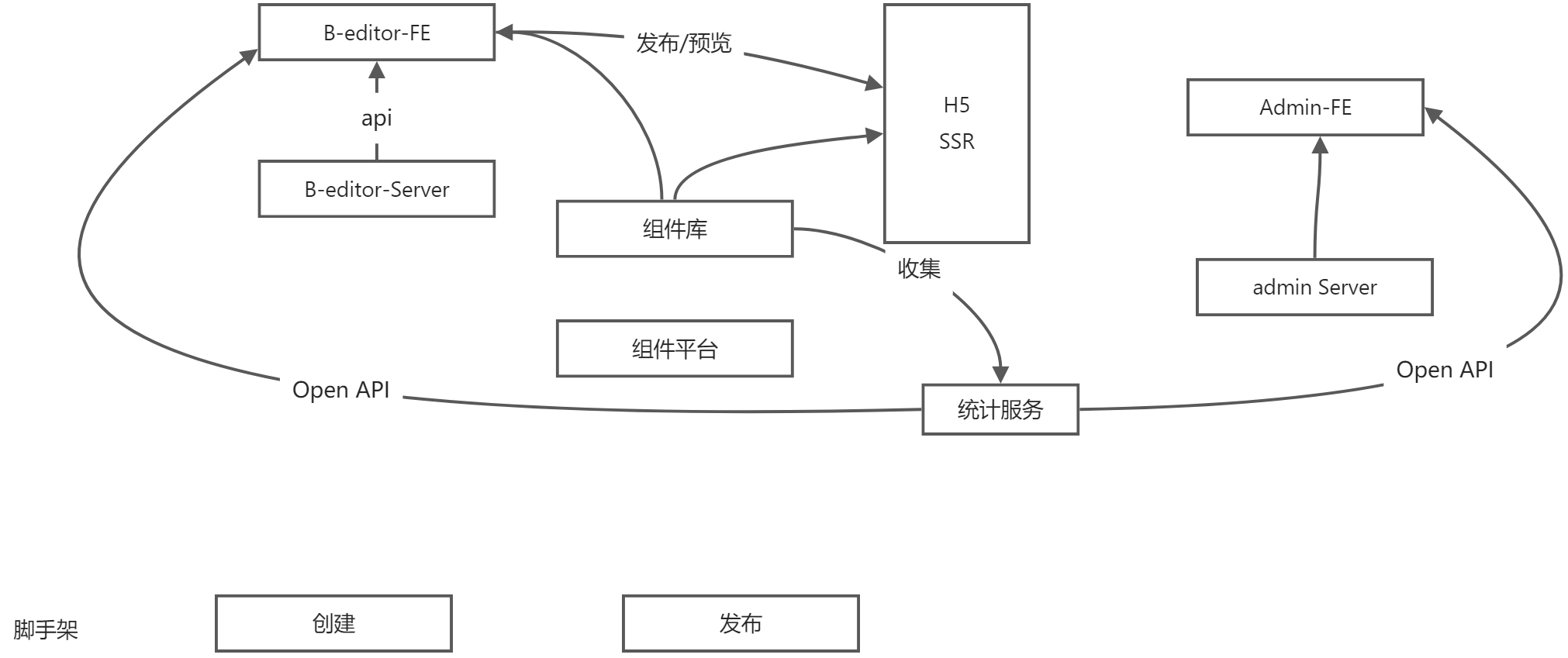
从需求来看,比较重要的几个方面:B端和编辑器, H5, 管理后台
B端和编辑器,做前后端分离
- biz-editor-fe
- biz-editor-server
H5 适合做SSR,因为要考虑性能
- H5-server
管理后台,做前端分析
- admin-fe
- admin-server
统计服务
熟悉需求
回顾一下作品的渠道,以及分渠道统计,这个需求。
而且,我们非常明确,这个需求是我们业务环节中非常重要的一部分,没有它,业务就无法闭环,就跑不通
如何自研
要实现这个功能,我们就需要自定义事件统计。普通的PV统计,是无法满足的。
- 支持自定义事件统计
- 支持OpenAPI---重要
一 开始我们以为有一些第三方的统计服务: 如友盟,百度统计,arms 可以支持。但是后来调查发现,他们要么支持,要么收费很贵(统计一年好几万)
所以需求有不能砍掉,综合对比只能选择自研一个。包括功能
- 日志收集
- 日志分析
- OpenAPI
各个项目的关系
作品的数据结构设计
需求描述了什么问题
一个可以简单拖拽或输入特定信息就可以生成Web页面,web页面经过审核后可以在线被分享浏览的系统
需要可视化的编辑器, 审核功能, 组件库; 作品统计
用户分析
- 模板作品创作者
- 模板使用者
- 平台管理员
技术需求
前端工程化
统一数据格式
{
// 作品
work: {
title: '作品标题',
setting: { /* 一些可能的配置项,用不到就先预留 */ },
props: { /* 页面 body 的一些设置,如背景色 */ },
components: [
// components 要用数组,有序结构
// 单个 node 要符合常见的 vnode 格式
{
id: 'xxx', // 每个组件都有 id ,不重复
name: '文本1',
tag: 'text',
attrs: { fontSize: '20px' },
children: [
'文本1' // 文本内容,有时候放在 children ,有时候放在 attrs 或者 props ,没有标准,看实际情况来确定
]
},
{
id: 'yyy',
name: '图片1',
tag: 'image',
attrs: { src: 'xxx.png', width: '100px' },
children: null
},
]
},
// 画布当前选中的组件
activeComponentId: 'xxx'
}
数据传递
模块划分
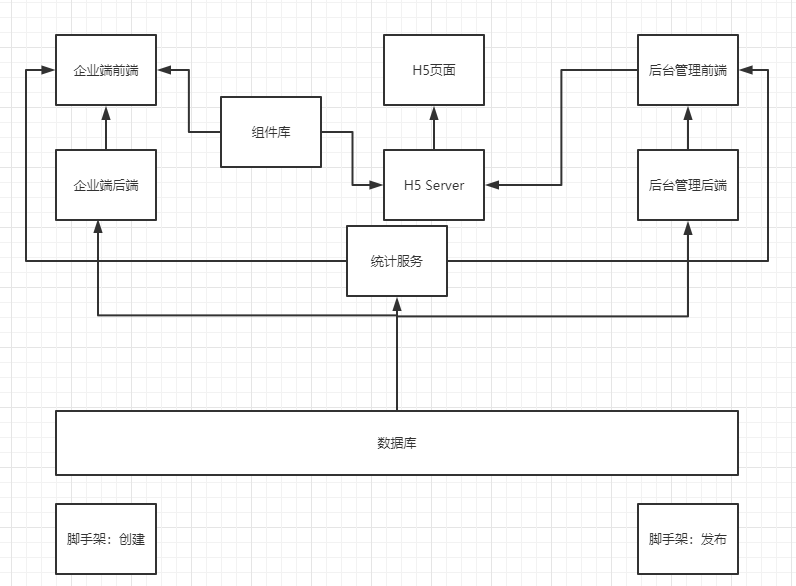
B端 h5-SSR
编辑器 biz-editor-server; biz-editor-fe
编辑器端制作发布作品、保存模板,并能查看作品的浏览、分享等数据,管理账户作品及模板等
H5 web
H5端用于显示成品作品,使用服务端渲染提高性能与用户体验,收集浏览及分享数据,发送到统计服务端
管理系统 admin-fe;admin-server
管理端管理作品,紧急下架,编辑器端用户管理,查看网站所有数据(用户数、浏览量、作品数量等)
架构图
扩展性保证
- 扩展组件
- 扩展编辑器功能
- 扩展页面信息
- 其他扩展功能
开发提效
- 组件平台
- 脚手架
运维保障
技术方案设计文档
技术方案设计
核心数据结构设计
关键词
- 流程图---分析需求的工具
- 全局思维,整体思维, 闭环思维---架构师思维来分析需求
- 业务组件库--独立拆分出来,复用
- 自定义事件统计-- 业务的重要性,如何实现
学习方法
- 有耐心,不要一心想着写代码,觉得需求和设计不重要
- 抛开你固有的程序员思维,开始准备接受架构师思维
- 要坚信:技术永远都是为业务服务的,技术是实现业务增长的工具。
注意事项
- 不要关注细节,要看整体,看范围
- 设计时要判断可行性,不确定的就要调研一下
- 设计时压迫考虑复杂度,越简单越好不要过度设计,不要为了设计而设计
需求分析
如何以架构师思维分析需求
脱离业务的架构就是刷流氓,架构师必须要深入理解,参与需求,看透需求背后的本质。
面试题: 作为前端复负责人,来开发一个h5 页,某个抽奖活动的运营活动,假设PM和RD都是实习生,技术和业务都不熟练, 你要从0开发这个页面,你会要求server端给你提供哪些接口和能力?
项目的浅层需求
表面需求
- 登录
- 创建一个作品, 编辑,发布
- 访问作品H5
- 用户信息
- 登录
- 注册
- 获取用户信息
- 作品
- 创建
- 保存
- 发布
- 获取作品信息
- 获取作品列表
- 末班
- 模板列表
- 使用模板创建
项目的深层需求
不容易一眼看到,但很重要的需求。
作品的管理
- 删除和恢复
- 转赠(员工离职交接工作)
- 复制
作品统计
需求闭环, 有输入有输出,创建发布了作品,当然要看一看统计结果。
- 统计
- 分渠道统计,渠道对于运营人员非常重要。
作品发布
- URL不能变
- 支持多渠道
H5
- 分享--- 对业务增长负责,这里就能体现
后台管理
全局把控,让一切尽在掌握之中。
- 数据统计
- 作品管理,能快速下线作品,防止有违规内容
- 用户管理,能快速冻结用户,防止有违规用户
- 模板管理,能控制哪些模块展示,哪些不展示
需求总结
对象
制作人,管理员 作品(成果物), 创作工具
整体架构设计
技术永远都是为了业务而服务的
熟悉需求后,就要考虑如何把它做出来。
如何写技术方案设计
主要内容
需要哪些项目,各项目之间的关系
独立的业务组件库
为何要自研自定义事件统计服务
作品的数据结构设计
写《技术方案设计》文档
注意事项
- 不要关注细节,要看整体,看范围
- 考虑扩展性(这就需要深入理解业务,否则你也不知道未来将如何扩展)
- 考虑可行性,不确定的就调研一下
- 考虑实现成本, 不要为了设计而设计,技术要永远服务与业务。---永远选择最简单的实现方案。
分析需求,确定要创建的项目
先不看细节,看整体,这一步就是确定项目的范围。确定范围就是做任何事情的第一步。
范围确定好了,剩下的事情,即便有问题,也属于“人民内部矛盾”。
需要哪些项目
从需求来看,比较重要的几个方面:B端和编辑器, H5, 管理后台
B端和编辑器,做前后端分离
- biz-editor-fe
- biz-editor-server
H5 适合做SSR,因为要考虑性能
- H5-server
管理后台,做前端分析
- admin-fe
- admin-server
统计服务
熟悉需求
回顾一下作品的渠道,以及分渠道统计,这个需求。
而且,我们非常明确,这个需求是我们业务环节中非常重要的一部分,没有它,业务就无法闭环,就跑不通
如何自研
要实现这个功能,我们就需要自定义事件统计。普通的PV统计,是无法满足的。
- 支持自定义事件统计
- 支持OpenAPI---重要
一 开始我们以为有一些第三方的统计服务: 如友盟,百度统计,arms 可以支持。但是后来调查发现,他们要么支持,要么收费很贵(统计一年好几万)
所以需求有不能砍掉,综合对比只能选择自研一个。包括功能
- 日志收集
- 日志分析
- OpenAPI
各个项目的关系
作品的数据结构设计
前端
后端
需求分析
功能描述
- 作品总数/分月总数: 通过数据库查询
- 发布的作品PV: 通过之前的数据统计系统OPENAPI来实现
- 模板总数/使用次数:查询数据库做统计
- 用户总数/活跃数量:查询数据库做统计
实时统计
从业务角度,信息不需要特别精确。实时统计技术实现较为简单...。
用户管理 - 显示列表,搜索:从数据库中读取
- 冻结/解冻:修改数据状态,再登录时做状态判断
作品管理 - 显示列表、搜索:从数据库读取
- 强制下线/恢复:修改数据状态
模板管理
前端开发
使用技术: umjs 和React hooks
主要产出:后台的前端代码(后台数据先用mock)
主要内容
用umijs初始化项目环境
开发功能
发布到测试机
注意事项
React是高级前端工程师的必备技能,必须要刻意练习(不能只会Vue)
React 不会从0 基础开始讲解
umijs可能会更新,要学会看文档,以现在的文档为主
创建项目
初始化项目 yarn create @umijs/umi-app
安装依赖 yarn install
启动yarn start 浏览器打开http://localhost:8000/
查看配置文件 .umirc.ts
配置
刚创建项目时,有配置文件.umirc.ts根据文档,配置可以放在config/config.ts,两者二选一。注意如果要使用config/config.ts一定要把.umirc.ts删除,否则运行报错
删除umirc.ts
- 新建
config/config.ts(还可以根据环境变量,扩展其他配置文件,参考文档)
将路由拆分到config/route.ts
解决warning
yarn start可能出现以下warning *******'SelectLang' was not found in 'umi'
'SelectLang' was not found in 'umi'
解决方案 config/config.ts中增加locale:{}- 新建文件
sec/localeszh-CN.ts,文件中写export default {} - 重启服务
mock接口 - 新增
mock/demo.tsmock一个接口 - 在
src/pages/index.ts中获取mock接口数据
关闭mock - package.json script 增加
"dev-no-mock":cross-env UMI_ENV = dev-no-mock umi dev", - 增加配置文件
config/config.dev-no-mock.ts
总结 - 初始化
- mock
服务端
主要产出
- 管理后台服务端代码和接口
主要内容 - 浏览代码结构
- 主要功能实现
注意事项 - 代码,技术方案,和之前哪些服务端基本一致,不会再分节点详细讲解
koa2 项目环境
src/
bin/
package.json
//发布到测试机- Dockerfile
- docker-compose.yml
- github actions
按月统计SQL语句
配置路由
- 修改路由
config/router.ts - 新增页面
src/pages/
登录验证
获取用户信息 - axios封装
src/utils - host配置
src/config/host.ts - 获取数据
src/service/admin.ts
检验并显示用户信息 - 校验用户
src/app.tsx - 显示用户信息
src/components/userInfo.tsc
登录页的css样式,要覆盖住左侧的菜单栏
框架会一直迭代,项目开发时使用z-index:10;正常,备课时就得改为z-index:100了
各个功能
登录 - mock接口
mock.admin.ts - 页面
src/pages/login/index/tsx
用户管理 - mock接口
mock/users.ts - 获取数据
src/service/user.ts - 页面
src/users/index.ts(及其附加组件)
首页dashboard - 获取统计数据
src/service/stat.ts - 页面
src/pages/dashboard/index.ts(及其附加的组件) - 页面
src/pages/dashboard/sub-pages(及其附加的组件)
404 - 页面
src/pages/404/index.tsx
总结 - 配置路由
- 登录检验
发布到测试机
前端代码发布到测试机,和server 端不一样,注意区分
打包
- 增加package.json scripts
"build-dev":"cross-env" UMI_ENV= prd-dev umi build - 增加配置文件
config/config.prd-dev.ts,取消mock,设置环境变量 - 查看host配置,
src/config/host.ts
运行yarn run build-dev, 打包到dist/目录
Docker容器
前端代码,打包
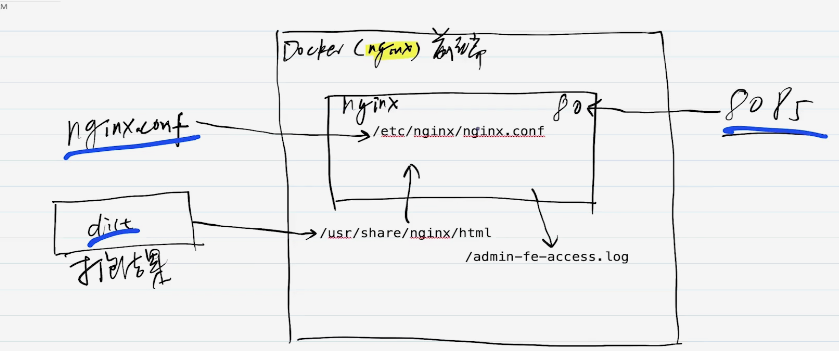
echarts
首页
整合B端页面的各种功能
完成作品发布的流程
- 对编辑区域进行截图
- 截图完成重新上传文件
- 上传完成保存作品并且创建渠道
发布后渠道窗口的功能 - 管理渠道---> 创建和删除渠道
- 使用钩子函数整合发布流程 -usePublishWork
- 将渠道链接生二维码
拷贝文本到剪贴板的功能
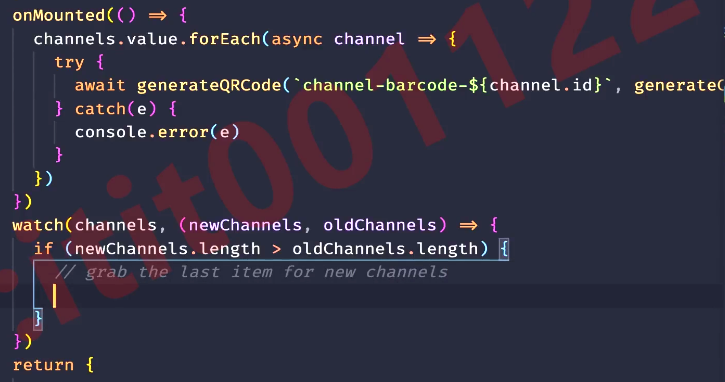
一个钩子函数的进化过程 - 首页加载更多
- 作品实现翻页
下载文件的原理以及编码过程
功能点 - html2canvas
- 基本使用
- 踩坑之旅
- qrcode---> 生成二维码
-Clipboard.js ---> 复制文本到剪切板- 基本使用
- 原理
- useLoadMore ---钩子函数的进化之旅
- 支持点击加载更多
- 支持无线滚动
- 支持分页
前端下载文件的原理
- 同域文件的下载
- 跨域文件的下载
- FileSaver.js的使用和原理
发布
发布作品,发布为模板
二维码
http://182.92.168.192:8082/p/232-elb4?
channel = 102
http://182.92.168.192:8082/ --->base_url
232--->page.id
elb4 --->page.uuid
102---> channel.id
qrcodejs https://github.com/davidshimjs/qrcodejs
node-qrcorde https://github.com/soldair/node-qrcode
watch...
dom 节点生成后在生成二维码
server
假设要抄“泥石流海报” 前端已经写完了,他的后端该如何写
泥石流海报: https://graph.readhub.cn/
后端需求分析
技术选型
nodejs框架: koa2
数据库: MySQL, mongodb, redis
登录校验:JWT
单元测试和接口测试:jest
线上服务: PM25 +nginx
原因
koa2 号称下一代的express, koa2 的体积也较小巧,代码结构是想用koa2 来封装一个类似于egg.js 的东西。
MySQL:主要用来存储一些规则的信息(标题,作者,创建时间, “内容(链接)”,...)
mongoDB: 存储内容(JSON)
Redis 存储一些缓存(有搜索内容的需求,使用缓存体验会更好些)
因为直接写SQL语句容易造成SQL注入的漏洞,使用了插件 Sequelize, Mongoose, redis-server, redis-cli
jwt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号