【CSP-S 2019】【洛谷P5665】划分
1|0前言
时发现自己做过类似这道题的题目 : P4954 [USACO09Open] Tower of Hay 干草塔
然后回忆了差不多才想出来。。。
然后就敲了的部分分。当时的内存是左右,写一个高精就炸内存了。
2|0题目
2048 年,第三十届 CSP 认证的考场上,作为选手的小明打开了第一题。这个题的样例有 组数据,数据从 编号, 号数据的规模为 。
小明对该题设计出了一个暴力程序,对于一组规模为 的数据,该程序的运行时间为 。然而这个程序运行完一组规模为 的数据之后,它将在任何一组规模小于 的数据上运行错误。样例中的 不一定递增,但小明又想在不修改程序的情况下正确运行样例,于是小明决定使用一种非常原始的解决方案:将所有数据划分成若干个数据段,段内数据编号连续,接着将同一段内的数据合并成新数据,其规模等于段内原数据的规模之和,小明将让新数据的规模能够递增。
也就是说,小明需要找到一些分界点 ,使得
注意 可以为 且此时 ,也就是小明可以将所有数据合并在一起运行。
小明希望他的程序在正确运行样例情况下,运行时间也能尽量小,也就是最小化
小明觉得这个问题非常有趣,并向你请教:给定 和 ,请你求出最优划分方案下,小明的程序的最小运行时间。
3|0思路:
假设我们现在已经划分为三个部分满足,那么显然是有
所以我们肯定要做到能分就分。
但是贪心选取肯定是错误的。样例一明显就指出了错误。
考虑。设表示我们划分的所有数,以为最后一个区块的情况下,最后一个区块的最小长度。
那么枚举一个,明显有
由于满足单调性,所以肯定选择尽量大的来转移。
如果可以转移到,那么转移的同时可以求出划分的费用
这样我们就得到了一个的算法,可以得到的高分。
我们发现,转移的条件其实就是,移项就得到了
我们发现,在做了前缀和之后,上式等号左边只与有关,等号右边只与有关。同时我们又要满足选择尽量大的来转移,所以就可以维护一个单调队列装进行转移。
但是我们每次要选择的是满足的尽量大进行转移,而不是单纯的最小的转移。所以我们每次要不断弹出队头,知道队头不再满足。此时将最后一次弹出的元素再从头部插入进行转移。这样就保证了每次选择最大的满足条件的元素进行转移。容易证明,弹出的元素不会对后面的转移产生影响。
这样每个元素最多进入队列1次,时间复杂度。
这样我们就得到了的高分。
对于的数据点需要使用高精,但是由于的算法我们的内存已经使用了,所以几乎没有空间来敲高精。
所以此时就只能用csp不允许使用的__int128了
我们将改为类型,是可以存下最终答案的。
然后我就愉快的T了。
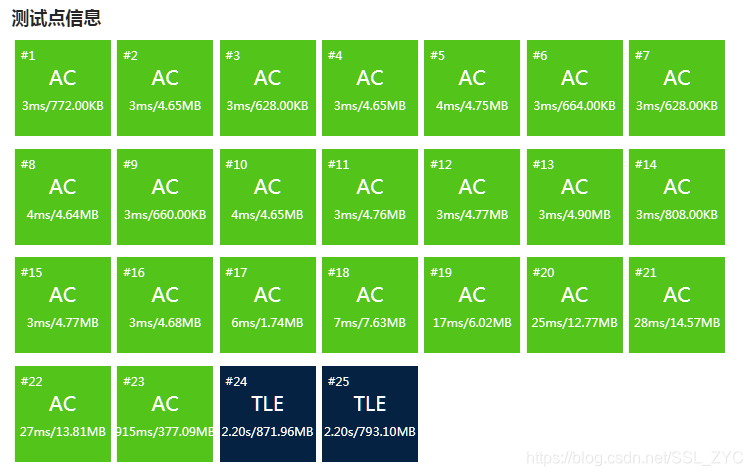
在尝试过所有我知道的化学性卡常后,样例三依然需要才可以跑过。
所以此时就只能用csp不允许使用的Ofast了
物理性卡常!样例最终可以在左右跑过。
然后我就愉快的MLE了。
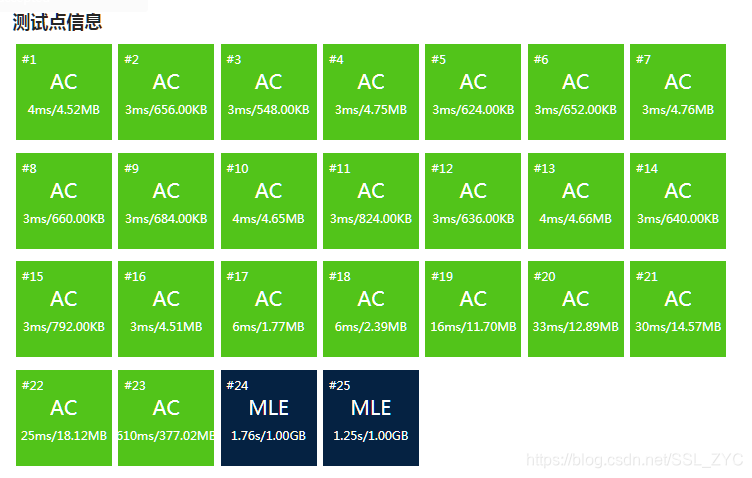
经过输出后,三个数组加起来是。将近的差距,只能考虑删除一个数组了。
和是肯定无法删除的,而我们发现,在转移时是等于的,其中直可以转移的最大的。
所以我们考虑直接用数组来表示出数组。这样我们往单调队列插入时就要插入两维,因为后者在去掉数组后是没办法算出来的。
最终还是以过了这道题。但是在时是不允许用和的,所以其实这份代码无论是时间还是空间都是过不去的
4|0代码:
__EOF__

本文链接:https://www.cnblogs.com/stoorz/p/12076749.html
关于博主:菜死了 /fad
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构