yield 的理解(2) 顺便 探索下for 循环 ,以及递归
代码目的:
利用递归,获得一个List中所有的元素
同时说明一下for ,以及 yield的特点。
代码:
net = [[[1,2],3],4,[5,6]]
def flatten(nested = net ,level = 0):
level +=1
count = 0
try:
for sublist in nested:
count += 1
print ('level {} sublist {} is {} '.format(level,count ,sublist) )
for element in flatten(sublist,level):
print('back to level:{}'.format(level))
yield element
except TypeError:
print('fined node:{}'.format(nested))
yield nested
解释一下代码:
net
是要被分解的列表。
flatten(nested ,level ) :
递归调用的函数,用于一层一层的进入嵌套列表,直到找到数据元素
当flatten 的参数nested ,被赋值为数据元素(而不是列表时) ,for sublist in nested 会触发 错误: “TypeError”
此时进入except TypeError ,Yield nested 会暂停该函数,返回到上一级函数去继续执行。
注意:Yield并不代表整个程序暂停,而仅是Yield所在函数暂停,并返回值。
上一个函数此时正在 for element in flatten(sublist,level) ,于是element = 找到的节点,并借由yield element ,一层一层往外退。
当退到shell 层,代码暂停。用户需要继续输入 next(g) ,来调用下一次查找.
注意,next(g)后,程序是从递归最内层的 yield开始继续执行的。
第一次执行next(g),以及第二次执行next(g)的入口,流程如下图(为了节约空间,去掉了print()):

这个图说明了两点:
1. yield是向上一层返回值,和return的路径一样。
2. next(g),是从最早的一次yield处回复的。
可以理解为,当多个yield依次调用时,yield的现场被放入一个“栈”。 使用next恢复时,从栈的最底端保存的yield现场,恢复执行.
疑问:栈中的其他yield ,是否就丢弃了,暂时没有答案.
实验:
在python中执行之前的代码:
net = [[[1,2],3],4,[5,6]]
def flatten(nested = net ,level = 0):
level +=1
count = 0
try:
for sublist in nested:
count += 1
print ('level {} sublist {} is {} '.format(level,count ,sublist) )
for element in flatten(sublist,level):
print('back to level:{}'.format(level))
yield element
except TypeError:
print('fined node:{}'.format(nested))
yield nested
执行过程,和结果如下:
>>> g= flatten()
>>> next(g)
level 1 sublist 1 is [[1, 2], 3]
level 2 sublist 1 is [1, 2]
level 3 sublist 1 is 1
fined node:1
back to level:3
back to level:2
back to level:1
1
>>> next(g)
level 3 sublist 2 is 2
fined node:2
back to level:3
back to level:2
back to level:1
2
>>> next(g)
level 2 sublist 2 is 3
fined node:3
back to level:2
back to level:1
3
>>> next(g)
level 1 sublist 2 is 4
fined node:4
back to level:1
4
>>> next(g)
level 1 sublist 3 is [5, 6]
level 2 sublist 1 is 5
fined node:5
back to level:2
back to level:1
5
>>> next(g)
level 2 sublist 2 is 6
fined node:6
back to level:2
back to level:1
6
>>> next(g)
Traceback (most recent call last):
File "<pyshell#21>", line 1, in <module>
next(g)
StopIteration
>>>
可见,列表分层如下:
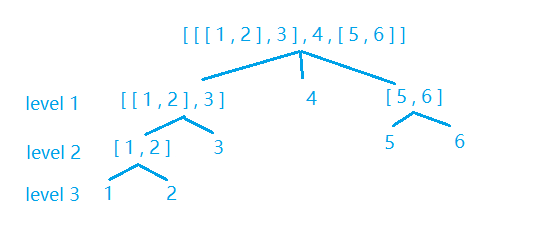
然后,还要提到对 python的 for 语句的理解。
首先,在C语言中, 简单的一句 for( i =0 ; i < 10 ; i ++ ) { do something} 是这样执行的:
1.更具语句1“ i= 0 ” 获得初值
2. 判断语句2" i<10 " 是否为真,不为真,则退出for 循环,执行下一个程序块。
3. 如果第二条判断为真,那么首先执行了循环体,其后执行 第三条 "i++"
4. 回到2.
然后, python 中 for语句是不同的。
我理解的(for x in y )中,y是一个可迭代的对象,而不是一个条件判断语句或者范围值。
即是说,可以多次访问y ,每次访问后,y都会迭代,发生变化,并可输出空(迭代结束)。
比如 ,当y 是一个 list对象时,循环处理如下:
1. y产生一次迭代,如为空,则跳出循环。 如值有效,则把值赋给x
2. 执行循环体
3. 回到1.
那么,回到递归这句话:
for element in flatten(sublist,level)
由于flatten 函数中具有yield, 这让他成为一个生成器 ,而生成器的特点是,当他第一次被调用时,将返回一个迭代器。
所以,此时for 语句中,flatten就是一个迭代器,每次调用的后,函数的返回值,就是要赋给x的值。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号