算法常见概念
一个算法应该具有以下五个重要的特征:
1、有穷性: 一个算法必须保证执行有限步之后结束;
2、确切性: 算法的每一步骤必须有确切的定义;
3、输入:一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定除了初始条件;
4、输出:一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
5、可行性: 算法原则上能够精确地运行,而且人们用笔和纸做有限次运算后即可完成。
常见的算法
1.分治法
字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序、归并排序)、傅立叶变换(快速傅立叶变换)。另一方面,理解及设计分治法算法的能力需要一定时间去掌握。正如以归纳法去证明一个理论,为了使递归能够推行,很多时候需要用一个较为概括或复杂的问题去取代原有问题。而且并没有一个系统性的方法去适当地概括问题。
2.动态规划法
动态规划在查找有很多重叠子问题的情况的最优解时有效。它将问题重新组合成子问题。为了避免多次解决这些子问题,它们的结果都逐渐被计算并被保存,从简单的问题直到整个问题都被解决。因此,动态规划保存递归时的结果,因而不会在解决同样的问题时花费时间。
动态规划只能应用于有最优子结构的问题。最优子结构的意思是局部最优解能决定全局最优解(对有些问题这个要求并不能完全满足,故有时需要引入一定的近似)。简单地说,问题能够分解成子问题来解决。
- 最优子结构性质。如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。最优子结构性质为动态规划算法解决问题提供了重要线索。
- 子问题重叠性质。子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是在表格中简单地查看一下结果,从而获得较高的效率。
3.贪心算法
贪心法( Greedy algorithm),又称贪心算法,是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。[1]比如在旅行推销员问题中,如果旅行员每次都选择最近的城市,那这就是一种贪心算法。
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是局部最优解能决定全局最优解。简单地说,问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。
贪心算法与动态规划的不同在于它每对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
4.回溯法
5.分支限界法
比较
分治法,动态规划法,贪心算法这三者之间有类似之处,比如都需要将问题划分为一个个子问题,然后通过解决这些子问题来解决最终问题。但其实这三者之间的区别还是蛮大的。
1.分治法
分治法(divide-and-conquer):将原问题划分成n个规模较小而结构与原问题相似的子问题;递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
分治模式在每一层递归上都有三个步骤:
- 分解(Divide):将原问题分解成一系列子问题;
- 解决(conquer):递归地解各个子问题。若子问题足够小,则直接求解;
- 合并(Combine):将子问题的结果合并成原问题的解。
合并排序(merge sort)是一个典型分治法的例子。其对应的直观的操作如下:
- 分解:将n个元素分成各含n/2个元素的子序列;
- 解决:用合并排序法对两个子序列递归地排序;
- 合并:合并两个已排序的子序列以得到排序结果。
2. 动态规划法
动态规划算法的设计可以分为如下4个步骤:
- 描述最优解的结构
- 递归定义最优解的值
- 按自底向上的方式计算最优解的值
- 由计算出的结果构造一个最优解
分治法是指将问题划分成一些独立地子问题,递归地求解各子问题,然后合并子问题的解而得到原问题的解。与此不同,动态规划适用于子问题独立且重叠的情况,也就是各子问题包含公共的子子问题。在这种情况下,若用分治法则会做许多不必要的工作,即重复地求解公共的子问题。动态规划算法对每个子子问题只求解一次,将其结果保存在一张表中,从而避免每次遇到各个子问题时重新计算答案。
适合采用动态规划方法的最优化问题中的两个要素:最优子结构和重叠子问题。
最优子结构:如果问题的一个最优解中包含了子问题的最优解,则该问题具有最优子结构。
重叠子问题:适用于动态规划求解的最优化问题必须具有的第二个要素是子问题的空间要很小,也就是用来求解原问题的递归算法课反复地解同样的子问题,而不是总在产生新的子问题。对两个子问题来说,如果它们确实是相同的子问题,只是作为不同问题的子问题出现的话,则它们是重叠的。
“分治法:各子问题独立 动态规划:各子问题重叠”
算法导论: 动态规划要求其子问题既要独立又要重叠,这看上去似乎有些奇怪。虽然这两点要求听起来可能矛盾的,但它们描述了两种不同的概念,而不是同一个问题的两个方面。如果同一个问题的两个子问题不共享资源,则它们就是独立的。对两个子问题俩说,如果它们确实是相同的子问题,只是作为不同问题的子问题出现的话,是重叠的,则它们是重叠的。
3. 贪心算法
对许多最优化问题来说,采用动态规划方法来决定最佳选择有点“杀鸡用牛刀”了,只要采用另一些更简单有效的算法就行了。贪心算法是使所做的选择看起来都是当前最佳的,期望通过所做的局部最优选择来产生出一个全局最优解。贪心算法对大多数优化问题来说能产生最优解,但也不一定总是这样的。
贪心算法只需考虑一个选择(亦即,贪心的选择);在做贪心选择时,子问题之一必须是空的,因此只留下一个非空子问题。
贪心算法与动态规划与很多相似之处。特别地,贪心算法适用的问题也是最优子结构。贪心算法与动态规划有一个显著的区别,就是贪心算法中,是以自顶向下的方式使用最优子结构的。贪心算法会先做选择,在当时看起来是最优的选择,然后再求解一个结果子问题,而不是先寻找子问题的最优解,然后再做选择。
贪心算法是通过做一系列的选择来给出某一问题的最优解。对算法中的每一个决策点,做一个当时看起来是最佳的选择。这一点是贪心算法不同于动态规划之处。在动态规划中,每一步都要做出选择,但是这些选择依赖于子问题的解。因此,解动态规划问题一般是自底向上,从小子问题处理至大子问题。贪心算法所做的当前选择可能要依赖于已经做出的所有选择,但不依赖于有待于做出的选择或子问题的解。因此,贪心算法通常是自顶向下地做出贪心选择,不断地将给定的问题实例归约为更小的问题。贪心算法划分子问题的结果,通常是仅存在一个非空的子问题。
容斥原理
在计数时,必须注意无一重复,无一遗漏。为了使重叠部分不被重复计算,人们研究出一种新的计数方法,这种方法的基本思想是:先不考虑重叠的情况,把包含于某内容中的所有对象的数目先计算出来,然后再把计数时重复计算的数目排斥出去,使得计算的结果既无遗漏又无重复,这种计数的方法称为容斥原理。
典型的题目有:uva 10209
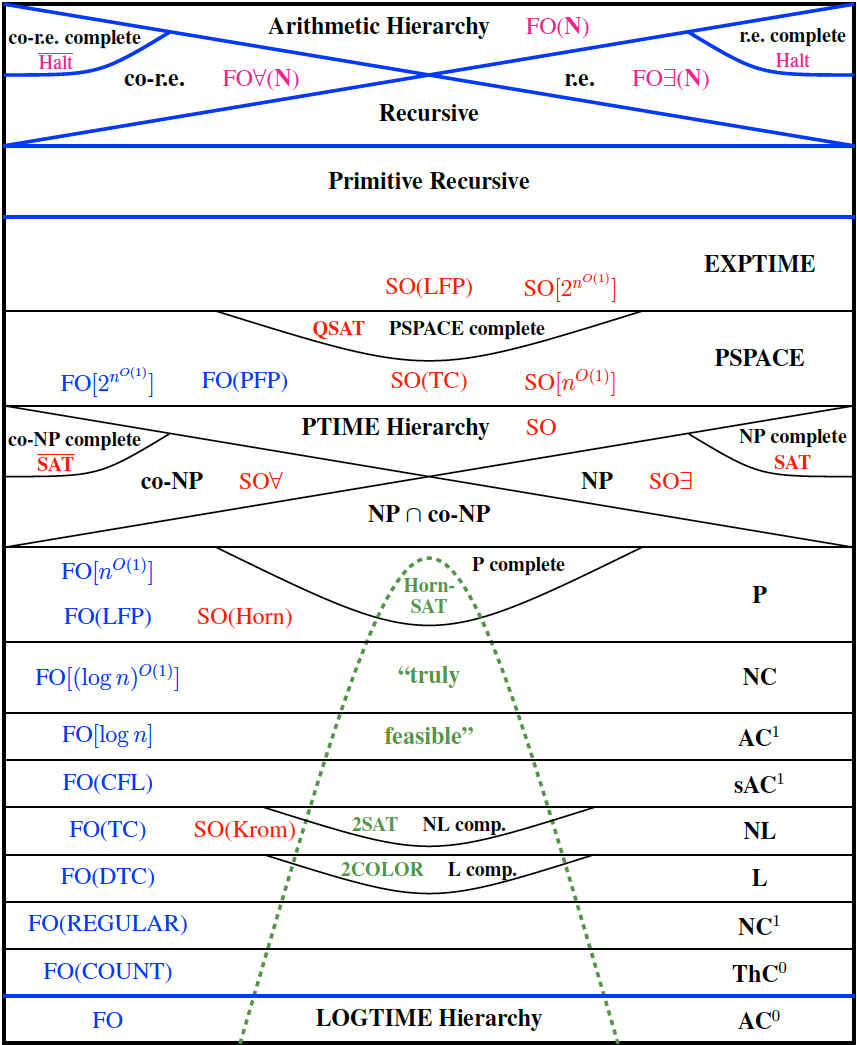
P与NP问题
例如一个问题如果在确定性图灵机上所需时间不会超过一个确定的多项式(以输入的长度为多项式的不定元),那么我们称这类问题的集合为P(polynomial time Turing machine)。而将前述定义中的“确定性图灵机”改为“不确定性图灵机”,那么所得到的问题集合为NP(non-deteministic polynomial time Turing machine)。NP完备(NP完全)是最不可能被化简为P(多项式时间可决定)的决定性问题的集合。若任何NPC问题得到多项式时间的解法,那此解法就可应用在所有NP问题上。
下图为计算复杂度理论图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号