聊聊Mysql索引和redis跳表
摘要
面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别。这种一看就知道是死记硬背,没有理解索引的本质。本文旨在剖析这背后的原理,欢迎留言探讨
问题
如果对以下问题感到困惑或一知半解,请继续看下去,相信本文一定会对你有帮助
- mysql 索引如何实现
- mysql 索引结构B+树与hash有何区别。分别适用于什么场景
- 数据库的索引还能有其他实现吗
- redis跳表是如何实现的
- 跳表和B+树,LSM树有和区别呢
解析
首先为什么要把mysql索引和redis跳表放在一起讨论呢,因为他们解决的都是同一种问题,用于解决数据集合的查找问题,即根据指定的key,快速查到它所在的位置(或者对应的value)
当你站在这个角度去思考问题时,还会不知道B+树索引和hash索引的区别吗
数据集合的查找问题
现在我们将问题领域边界划分清楚了,就是为了解决数据集合的查找问题。这一块需要考虑哪些问题呢
- 需要支持哪些查找方式,单key/多key/范围查找,
- 插入/删除效率
- 查找效率(即时间复杂度)
- 存储大小(空间复杂度)
我们看下几种常用的查找结构
hash 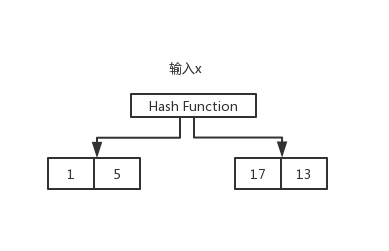
hash是key,value形式,通过一个散列函数,能够根据key快速找到value
B+树 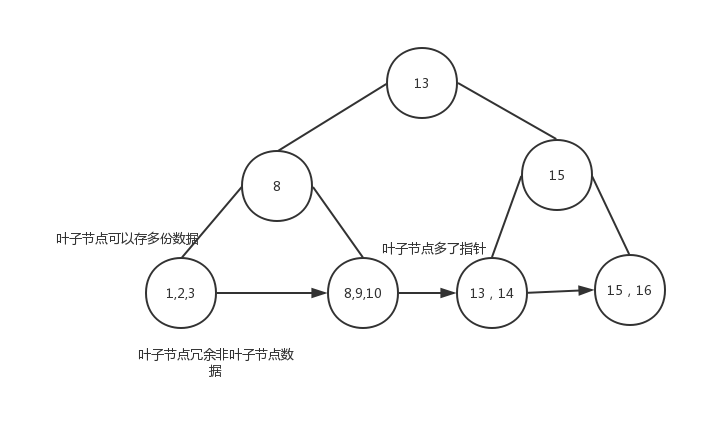
B+树是在平衡二叉树基础上演变过来,为什么我们在算法课上没学到B+树和跳表这种结构呢。因为他们都是从工程实践中得到,在理论的基础上进行了妥协。
B+树首先是有序结构,为了不至于树的高度太高,影响查找效率,在叶子节点上存储的不是单个数据,而是一页数据,提高了查找效率,而为了更好的支持范围查询,B+树在叶子节点冗余了非叶子节点数据,为了支持翻页,叶子节点之间通过指针连接。
跳表 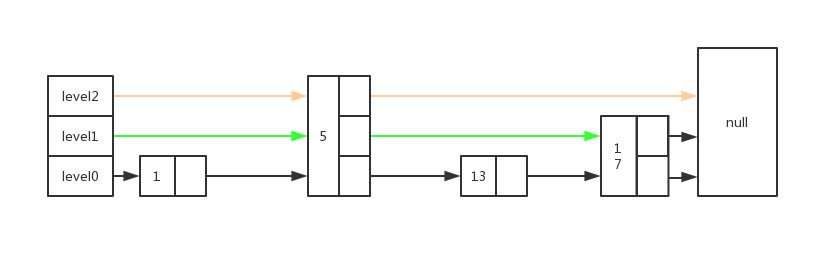
跳表是在链表的基础上进行扩展的,为的是实现redis的sorted set数据结构。 level0: 是存储原始数据的,是一个有序链表,每个节点都在链上 level0+: 通过指针串联起节点,是原始数据的一个子集,level等级越高,串联的数据越少,这样可以显著提高查找效率,
总结
| 数据结构 | 实现原理 | key查询方式 | 查找效率 | 存储大小 | 插入、删除效率 |
|---|---|---|---|---|---|
| Hash | 哈希表 | 支持单key | 接近O(1) | 小,除了数据没有额外的存储 | O(1) |
| B+树 | 平衡二叉树扩展而来 | 单key,范围,分页 | O(Log(n) | 除了数据,还多了左右指针,以及叶子节点指针 | O(Log(n),需要调整树的结构,算法比较复杂 |
| 跳表 | 有序链表扩展而来 | 单key,分页 | O(Log(n) | 除了数据,还多了指针,但是每个节点的指针小于<2,所以比B+树占用空间小 | O(Log(n),只用处理链表,算法比较简单 |
对LSM结构感兴趣的可以看下cassandra vs mongo (1)存储引擎
有用点个赞,谢谢 
参考
https://www.cnblogs.com/Elliott-Su-Faith-change-our-life/p/7545940.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号