国产化达梦dm数据库 sq执行计划 (sql plan)-part02
上一篇学习了 达梦基本的执行计划
https://www.cnblogs.com/stone469/articles/16656894.html
下面接着学习 复杂连接查询

CREATE TABLE TEST5(ID INT);
CREATE TABLE TEST6(ID INT);
CREATE TABLE TEST7(ID INT);
CREATE TABLE TEST8(ID INT);
insert into test5 values(3);
insert into test6 values(4);
insert into test7 select level %100 from dual connect by level < 10000;
insert into test8 select level %100 from dual connect by level < 10000;
explain select /*+no_use_cvt_var*/* from
(select test5.id from test5,test6 where test5.id = test6.id)a,
(select id from
(select test7.id from test7,test8 where test7.id = test8.id) group by id
) b
where a.id = b.id;
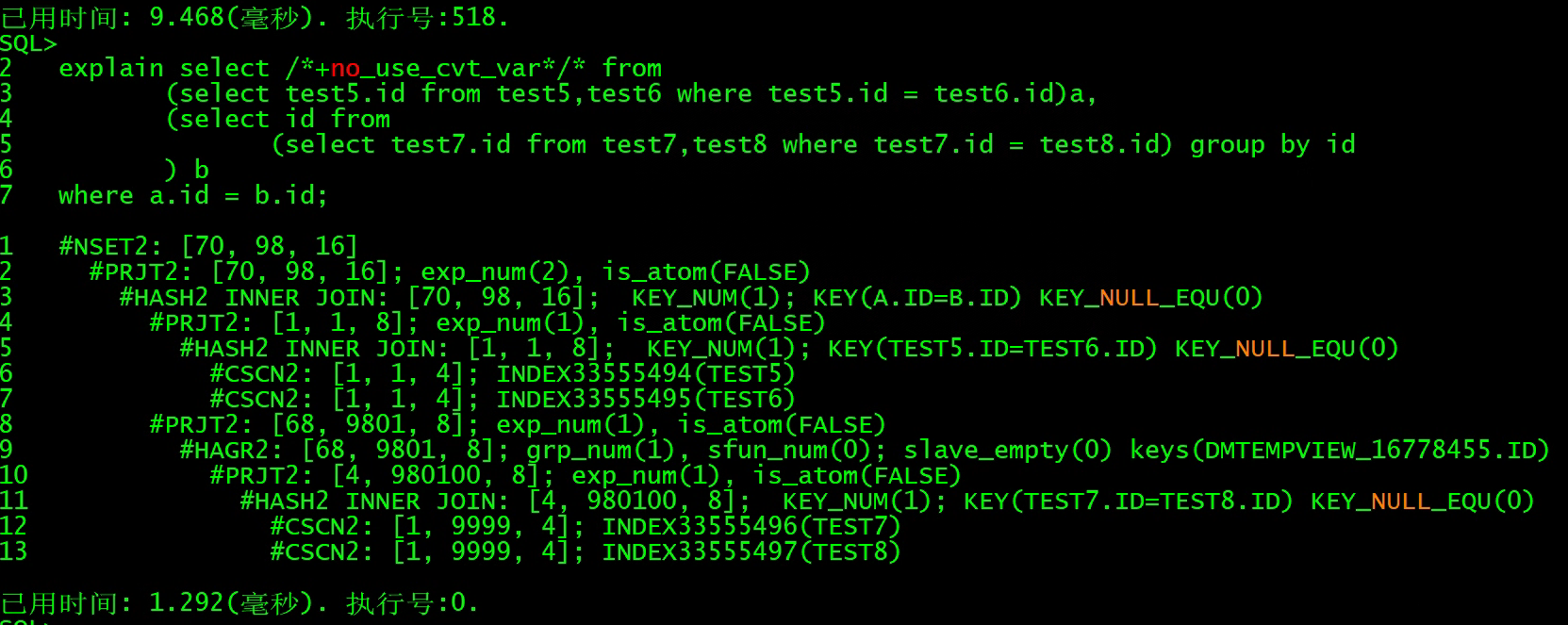
用到的操作符说明:
NSET2 结果集(result set)收集,一般是查询计划的顶层节点
PRJT2 关系的―投影‖(project)运算,用于选择表达式项的计算
HASH2 INNER JOIN HASH 内连接
PRJT2 关系的―投影‖(project)运算,用于选择表达式项的计算
HASH2 INNER JOIN HASH 内连接
PRJT2 关系的―投影‖(project)运算,用于选择表达式项的计算
HASH2 INNER JOIN HASH 内连接
CSCN2 聚集索引扫描
CSCN2 聚集索引扫描
PRJT2 关系的―投影‖(project)运算,用于选择表达式项的计算
HAGR2 HASH 分组,并计算聚集函数
PRJT2 关系的―投影‖(project)运算,用于选择表达式项的计算
HASH2 INNER JOIN HASH 内连接
CSCN2 聚集索引扫描
CSCN2 聚集索引扫描
no_use_cvt_var 不考虑变量改写方式实现连接,仅 OPTIMIZER_MODE=1 有效。
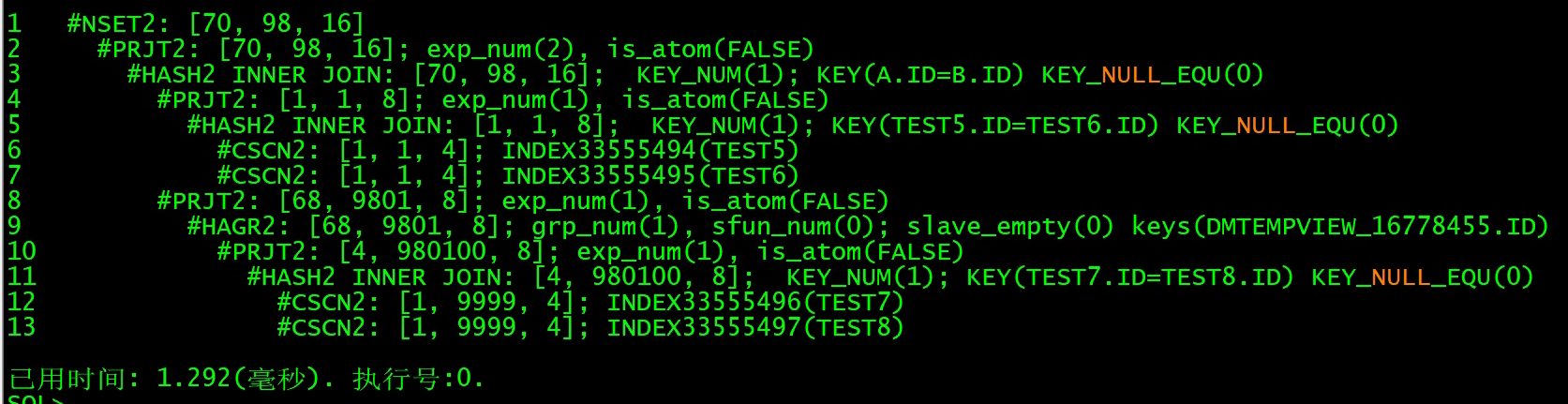
执行顺序 6->7->5->12->13->11->9->3
首先执行TEST5和TEST6的HASH连接,然后执行TEST7,TEST8的HASH连接并将连接结果进行HASH分组,再将两个结果再次进行HASH连接得到最终结果集。
六、多表连接的三种方式
一般来说:
等值连接条件一般会选择哈希连接;
非等值连接条件会采用嵌套连接;
连接列均为索引列时,会采用归并连接。
创建测试环境:
create table tab1(c1 int,c2 int ,c3 int);
create table tab2(c1 int,c2 int ,c3 int);
insert into tab1 select level,level,level from DUAL CONNECT by level <100000;
insert into tab2 select level,level,level from DUAL CONNECT by level <100000;
create index ind_tab1 on tab1(c1);
create index ind_tab2 on tab2(c1);
select * from user_indexes where table_name in ('TAB1','TAB2') ;
1、HASH JOIN(哈希连接)
Hash join的工作方式是将一个表(通常是小一点的那个表)做hash运算,将列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做匹配。
1)HASH2 INNER JOIN(HASH内连接)
explain select tab1.c1,tab2.c2 from tab1 , tab2 where tab1.c1=tab2.c1;

2)HASH LEFT JOIN2(HASH左外连接)
explain select tab1.c1 from tab1 left join tab2 on tab1.c1=tab2.c1;

3) HASH FULL JOIN2(HASH 全外连接)
explain select tab2.c1 from tab1 full outer join tab2 on tab2.c1=tab1.c1 ;

全连接的查询结果是左外连接和右外连接查询结果的并集,即使一些记录关联不上,也能够把部分信息查询出来。
4)HASH LEFT SEMI MULTIPLE JOIN(多列not in)
explain select * from tab1 where (c1,c2) not in (select c1,c2 from tab2) ;

5)HASH LEFT SEMI JOIN2(HASH 左半连接)
子查询和非等值连接出现
explain select * from tab1 where c1 not in (select c1 from tab2)
and c2 not in (select c2 from tab2);

6)HASH RIGHT JOIN2(HASH右外连接)
explain select t.c1 ,tab1.c3 from tab1 left join (select * from tab2 where c1=10)t on t.c1=tab1.c2 ;

2、MERGE JOIN(归并连接,也叫排序归并连接)
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多
1) 模拟:(归并内连接)
连接列有索引且只需要返回索引列归并更合适
explain select tab1.c1 from tab1 , tab2 where tab1.c1=tab2.c1;

3、NESTED LOOP(嵌套循环连接)
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是当一个关联表比较小的时候,效率会更高。
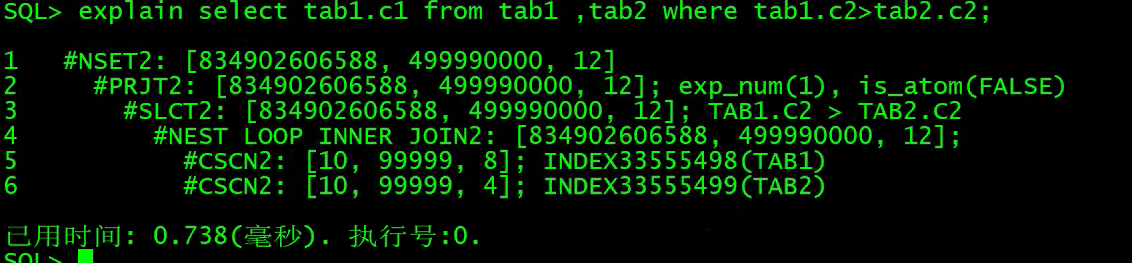
1)NEST LOOP INNER JOIN2(嵌套循环内连接)
explain select tab1.c1 from tab1 ,tab2 where tab1.c2>tab2.c2;
2)NEST LOOP LEFT JOIN2(嵌套循环左连接)
explain select tab1.c1 from tab1 left join tab2 on tab1.c2>tab2.c2;

七、补充下索引的知识点
聚集(clustered)索引,也叫聚簇索引。聚簇索引的索引和数据是存储在一起的。
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
说实话,看着有点拗口,用大白话说就是,我们的sql数据库是行数据库,数据是一行一行存储的,而聚集索引是个特殊的索引,相当于这一行行记录的物理编号,描述这一行行数据的物理存储顺序。所以,一张表只会有一个聚集索引。
除了聚集索引外的其他索引类型都属于二级索引。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据
更多资讯请上达梦技术社区了解: https://eco.dameng.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号