国产化达梦dm数据库 sq执行计划 (sql plan)-part01
执行计划是什么呢?
所谓执行计划,顾名思义,就是对一个查询任务,做出一份怎样去完成任务的详细方案。举个生活中的例子,我从珠海要去英国,我可以选择先去香港然后转机,也可以先去北京转机,或者去广州也可以。但是到底怎样去英国划算,也就是我的费用最少,这是一件值得考究的事情。同样对于查询而言,我们提交的SQL仅仅是描述出了我们的目的地是英国,但至于怎么去,通常我们的SQL中是没有给出提示信息的,是由数据库来决定的,查询优化器会为这条sql语句设计执行方式,交给执行器去执行,查询优化器设计的执行方式就是执行计划。
达梦执行计划涉及到的一些主要操作符有:
CSCN :基础全表扫描(a),从头到尾,全部扫描
SSCN :二级索引扫描(b), 从头到尾,全部扫描
SSEK :二级索引范围扫描(b) ,通过键值精准定位到范围或者单值
CSEK :聚簇索引范围扫描© ,通过键值精准定位到范围或者单值
BLKUP :根据二级索引的ROWID 回原表中取出全部数据(b + a)
一、执行计划解读
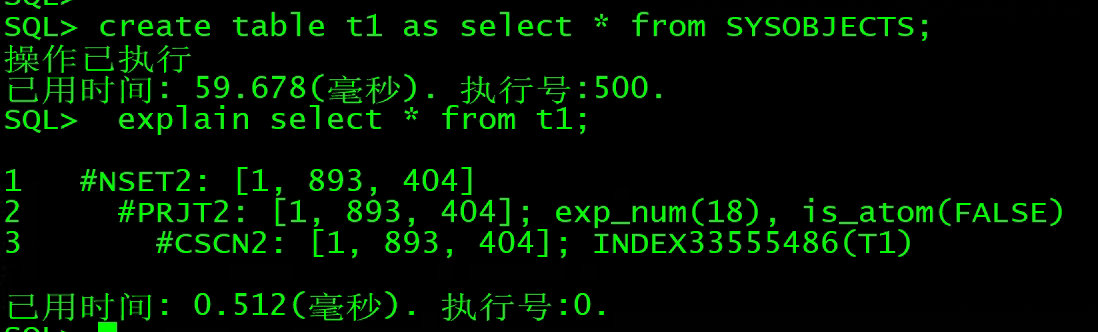
从上面的执行计划中我们可以看到哪些信息呢?
首先,一个执行计划由若干个计划节点组成,如上面的1、2、3。
然后我们看到,每个计划节点中包含操作符(CSCN2)和它的代价([0, 1711, 396])等信息。
代价由一个三元组组成[代价,记录行数,字节数]。
代价的单位是毫秒,记录行数表示该计划节点输出的行数,字节数表示该计划节点输出的字节数。
拿上面第三个计划节点举例:操作符是CSCN2即全表扫描,代价估算是0ms,扫描的记录行数是1711行,输出字节数是396个。
二、举例说明操作符
1、准备测试表和数据

DROP TABLE T1; DROP TABLE T2; CREATE TABLE T1(C1 INT ,C2 CHAR(1),C3 VARCHAR(10) ,C4 VARCHAR(10) ); CREATE TABLE T2(C1 INT ,C2 CHAR(1),C3 VARCHAR(10) ,C4 VARCHAR(10) ); INSERT INTO T1 SELECT LEVEL C1,CHR(65+MOD(LEVEL,57)) C2,'TEST',NULL FROM DUAL CONNECT BY LEVEL<=10000; INSERT INTO T2 SELECT LEVEL C1,CHR(65+MOD(LEVEL,57)) C2,'TEST',NULL FROM DUAL CONNECT BY LEVEL<=10000; CREATE INDEX IDX_C1_T1 ON T1(C1); SP_INDEX_STAT_INIT(USER,'IDX_C1_T1');-- 收集指定的索引的统计信息
这里说明一下SP_INDEX_STAT_INIT的两个参数分别是模式名和索引名。我这里指定的是USER,会默认查找当前登录用户同名的模式,如果这个用户下有多个模式,查不到其他模式。
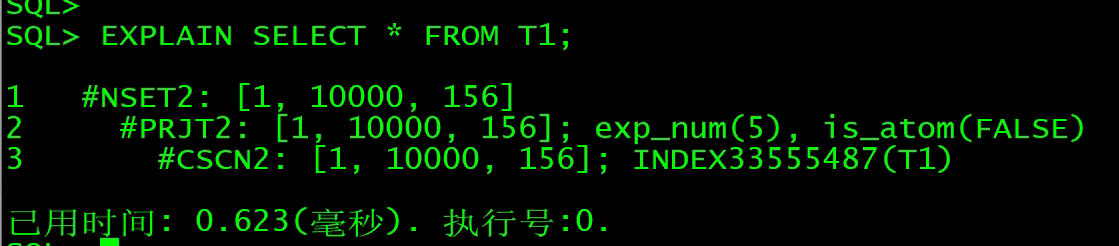
2、NSET:收集结果集
说明:用于结果集收集的操作符, 一般是查询计划的顶层节点。
EXPLAIN SELECT * FROM T1;
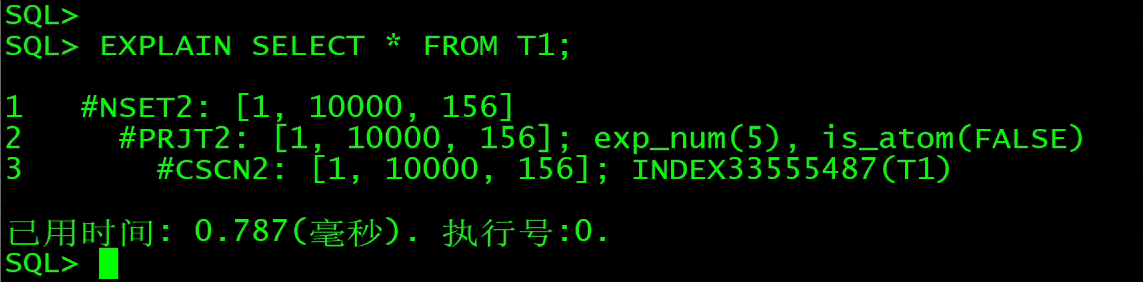
3、PRJT:投影
说明:关系的“投影”(project)运算,用于选择表达式项的计算;广泛用于查询,排序,函数索引创建等。
EXPLAIN SELECT * FROM T1;
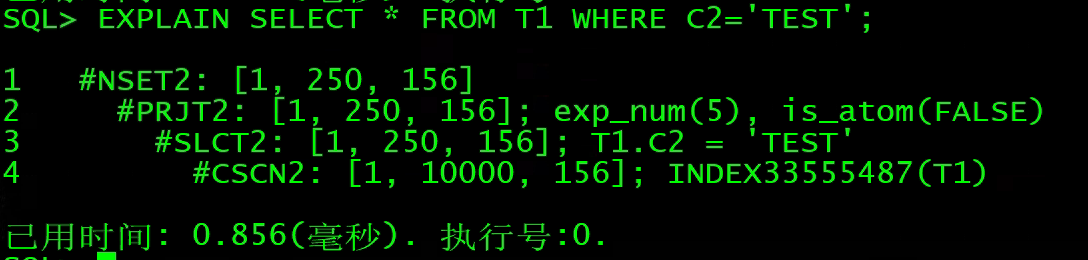
4、SLCT:选择
说明:关系的“选择” 运算,用于查询条件的过滤。
EXPLAIN SELECT * FROM T1 WHERE C2='TEST';
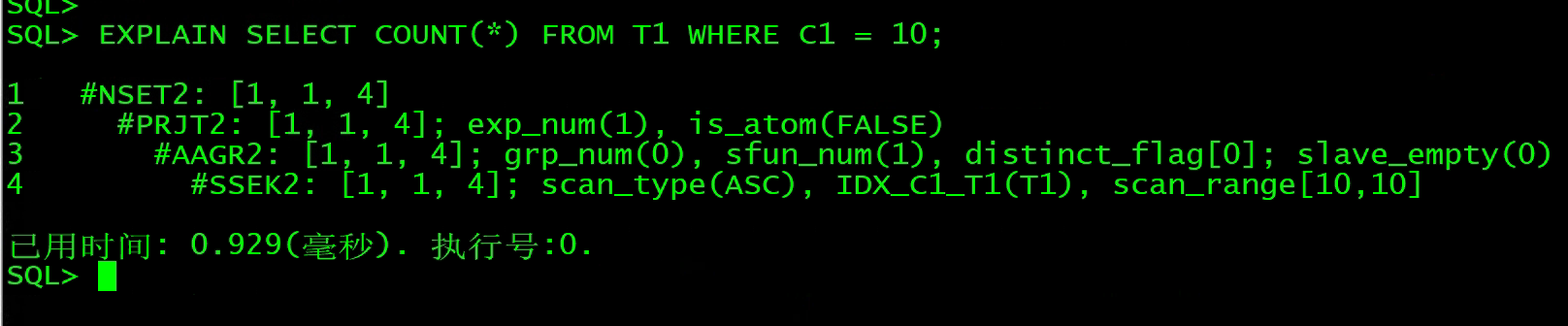
5、AAGR:简单聚集
说明:用于没有group by的count,sum,age,max,min等聚集函数的计算。
EXPLAIN SELECT COUNT(*) FROM T1 WHERE C1 = 10;
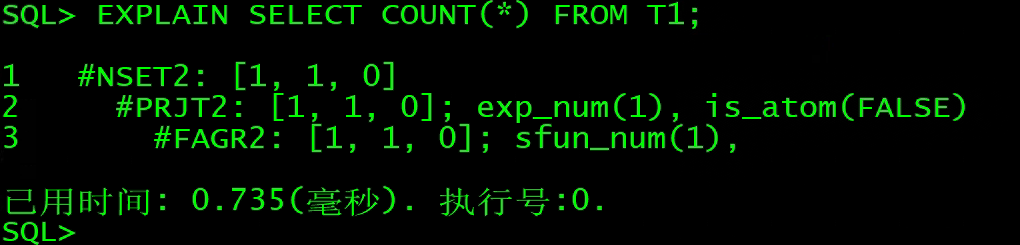
6、FAGR:快速聚集
说明:用于没有过滤条件时从表或索引快速获取 MAX/MIN/COUNT值,DM数据库是世界上单表不带过滤条件下取COUNT值最快的数据库。
EXPLAIN SELECT COUNT(*) FROM T1;
7、HAGR:HASH分组聚集
说明:用于分组列没有索引只能走全表扫描的分组聚集,C2列没有创建索引。
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C2;

8、SAGR:流分组聚集
说明:用于分组列是有序的情况下可以使用流分组聚集,C1上已经创建了索引,SAGR2性能优于HAGR2。
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C1;

官方解释是:如果输入流是有序的,则使用流分组,并计算聚集函数。
9、BLKUP:二次扫描
说明:先使用2级别索引定位,再根据表的主键、聚集索引、 rowid等信息定位数据行。
EXPLAIN SELECT * FROM T1 WHERE C1=10;

bookmark lookup 翻译成中文是书签查找
BLKUP2 官方文档说明是:定位查找
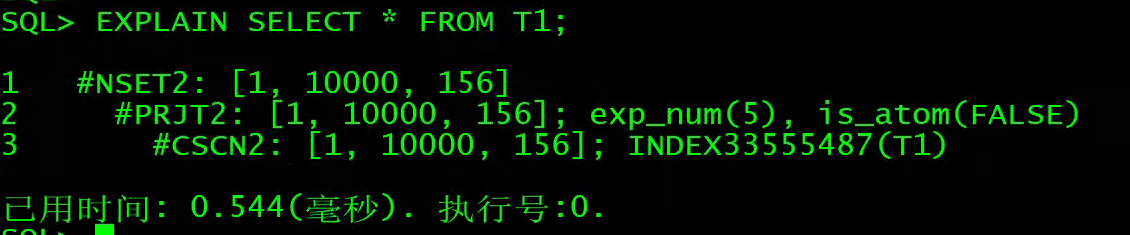
10、CSCN:全表扫描
说明:CSCN2是CLUSTER INDEX SCAN的缩写即通过聚集索引扫描全表,全表扫描是最简单的查询,如果没有选择谓词,或者没有索引可以利用,则系统一般只能做全表扫描。在一个高并发的系统中应尽量避免全表扫描。
EXPLAIN SELECT * FROM T1;
11、SSEK、CSEK、SSCN:索引扫描
1) SSEK
说明:SSEK2是二级索引扫描即先扫描索引,再通过主键、聚集索引、ROWID等信息去扫描表;
EXPLAIN SELECT * FROM T1 WHERE C1=10;

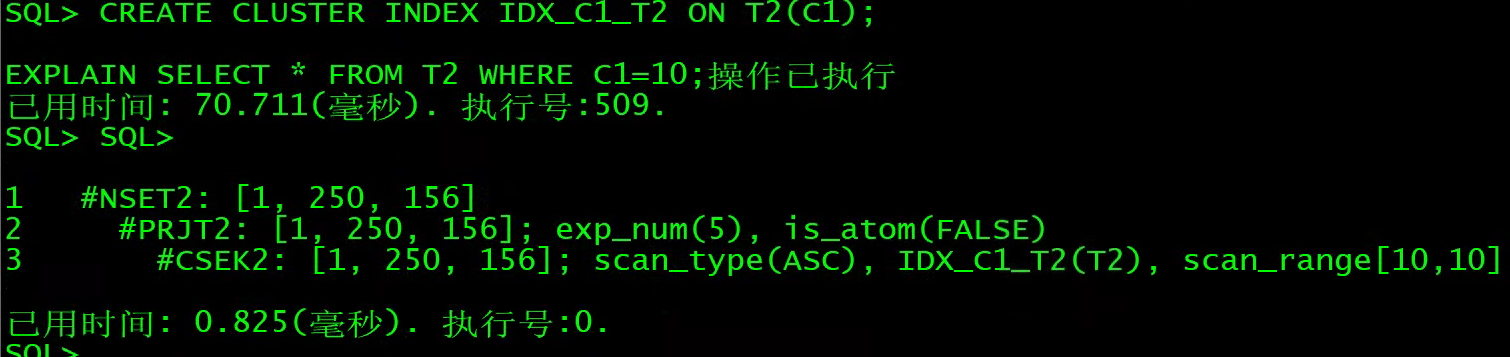
2)CSEK
说明:CSEK2是聚集索引扫描只需要扫描索引,不需要扫描表;
CREATE CLUSTER INDEX IDX_C1_T2 ON T2(C1);
EXPLAIN SELECT * FROM T2 WHERE C1=10;
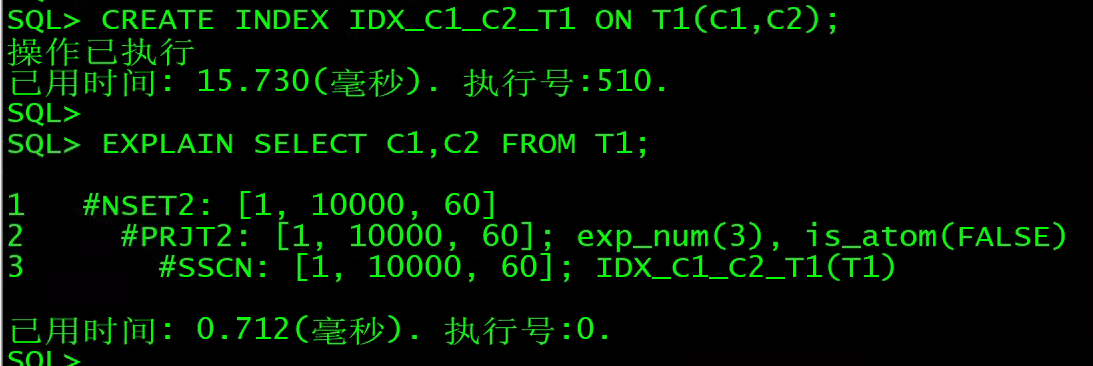
3)SSCN
说明:SSCN是索引全扫描,不需要扫描表。
官方解释是:直接使用二级索引进行扫描。
CREATE INDEX IDX_C1_C2_T1 ON T1(C1,C2);
EXPLAIN SELECT C1,C2 FROM T1;
达梦社区地址:https://eco.dameng.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号