
002爬虫之requests模块
我们的第一个爬虫用的是urllib来抓取页面源代码,这个是python内置的一个模块。但是它并不是我们常用的爬虫工具,常用的抓取页面的模块通常使用一个第三方模块requests,这个模块的优势就是比urllib还要简单, 并且处理各种请求都比较方便。
我们直接上第一个程序,还是爬取百度:
import requests
# 爬取百度的页面源代码
url = "http://www.baidu.com"
resp = requests.get(url)
# 设置字符集utf-8
resp.encoding = "utf-8"
print(resp.text) # 拿到页面源代码
我也把urllib写的拿过来,大家可以自行对比下:
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
# print(resp.read().decode("utf-8"))
with open("baidu.html", mode="w", encoding="utf-8") as f:
f.write(resp.read().decode("utf-8"))
接下来我们说说requests模块的两种请求方式:get, post
先说get:get请求一般会将请求参数直接放到请求体的后面,比如下面的这种写法。
# GET请求
import requests
content = input("请输入你要检索的内容:")
url = f"https://www.sogou.com/web?query={content}"
headers = {
# 添加一个请求头信息。UA
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
# 处理一个小小的反爬
resp = requests.get(url, headers=headers)
print(resp.text)
再说post,post请求会将请求信息放到form data里面,这里我们在post请求时,加入data=data就可以。
# post请求
import requests
url = "https://fanyi.baidu.com/sug"
data = {
"kw": input("请输入一个单词:")
}
resp = requests.post(url, data=data)
print(resp.text) # 拿到的是文本字符串
print(resp.json()['data']) # 此时拿到的直接是json数据
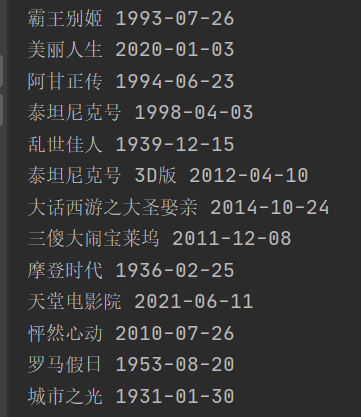
以上是最简单的get和post请求的区别,请大家自行比对。最后我们看一个例子,用get请求获取豆瓣电影的名称和上映时间。下面的代码有几个点大家可以细品下:第一,get请求的数据参数单独放到外面,用params进行传参;第二,获取数据的格式是json格式,然后通过遍历的方式获取想要爬取的信息。
# get请求参数
import requests
url = "https://movie.douban.com/j/chart/top_list"
data = {
"type":"13",
"interval_id":"100:90",
"action":"",
"start":"0",
"limit":"20" # 修改这个值可以控制获取多少部电影信息
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
# get请求可以通过params将参数传递,post请求通过data传递
resp = requests.get(url, params=data, headers=headers)
# print(resp.text) # 获取文本
# print(resp.json()) # 获取json数据
# print(resp.request.url) # 获取访问的url
# 循环遍历获取的json数据
for item in resp.json():
# 获取电影名称
movie_name = item['title']
# 获取电影放映日期
release_date = item['release_date']
print(movie_name, release_date)
以下是爬取出来的结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号