笔记整理--C语言
C语言指针5分钟教程
指针、引用和取值
什么是指针?什么是内存地址?什么叫做指针的取值?指针是一个存储计算机内存地址的变量。在这份教程里“引用”表示计算机内存地址。从指针指向的内存读取数据称作指针的取值。指针可以指向某些具体类型的变量地址,例如int、long和double。指针也可以是void类型、NULL指针和未初始化指针。本文会对上述所有指针类型进行探讨。
根据出现的位置不同,操作符 * 既可以用来声明一个指针变量,也可以用作指针的取值。当用在声明一个变量时,*表示这里声明了一个指针。其它情况用到*表示指针的取值。
&是地址操作符,用来引用一个内存地址。通过在变量名字前使用&操作符,我们可以得到该变量的内存地址。
// 声明一个int指针
int *ptr;
// 声明一个int值
int val = 1;
// 为指针分配一个int值的引用
ptr = &val;
// 对指针进行取值,打印存储在指针地址中的内容
int deref = *ptr;
printf("%d\n", deref);
第2行,我们通过*操作符声明了一个int指针。接着我们声明了一个int变量并赋值为1。然后我们用int变量的地址初始化我们的int指针。接下来对int指针取值,用变量的内存地址初始化int指针。最终,我们打印输出变量值,内容为1。
第6行的&val是一个引用。在val变量声明并初始化内存之后,通过在变量名之前使用地址操作符&我们可以直接引用变量的内存地址。
第8行,我们再一次使用*操作符来对该指针取值,可直接获得指针指向的内存地址中的数据。由于指针声明的类型是int,所以取到的值是指针指向的内存地址存储的int值。
这里可以把指针、引用和值的关系类比为信封、邮箱地址和房子。一个指针就好像是一个信封,我们可以在上面填写邮寄地址。一个引用(地址)就像是一个邮件地址,它是实际的地址。取值就像是地址对应的房子。我们可以把信封上的地址擦掉,写上另外一个我们想要的地址,但这个行为对房子没有任何影响。

void指针、NULL指针和未初始化指针
一个指针可以被声明为void类型,比如void *x。一个指针可以被赋值为NULL。一个指针变量声明之后但没有被赋值,叫做未初始化指针。
int *uninit; // int指针未初始化
int *nullptr = NULL; // 初始化为NULL
void *vptr; // void指针未初始化
int val = 1;
int *iptr;
int *castptr;
// void类型可以存储任意类型的指针或引用
iptr = &val;
vptr = iptr;
printf("iptr=%p, vptr=%p\n", iptr, vptr);
// 通过显示转换,我们可以把一个void指针转成
// int指针并进行取值
castptr = (int *)vptr;
printf("*castptr=%d\n", *castptr);
// 打印null和未初始化指针
printf("uninit=%p, nullptr=%p\n", uninit, nullptr);
// 不知道你会得到怎样的返回值,会是随机的垃圾地址吗?
// printf("*nullptr=%d\n", nullptr);
// 这里会产生一个段错误
// printf("*nullptr=%d\n", nullptr);
执行上面的代码,你会得到类似下面对应不同内存地址的输出。
iptr=0x7fff94b89c6c, vptr=0x7fff94b89c6c
*castptr=1
uninit=0x7fff94b89d50, nullptr=(nil)
第1行我们声明了一个未初始化int指针。所有的指针在赋值为NULL、一个引用(地址)或者另一个指针之前都是未被初始化的。第2行我们声明了一个NULL指针。第3行声明了一个void指针。第4行到第6行声明了一个int值和几个int指针。
第9行到11行,我们为int指针赋值为一个引用并把int指针赋值为void指针。void指针可以保存各种其它指针类型。大多数时候它们被用来存储数据结构。可以注意到,第11行我们打印了int和void指针的地址。它们现在指向了同样的内存地址。所有的指针都存储了内存地址。它们的类型只在取值时起作用。
第15到16行,我们把void指针转换为int指针castptr。请注意这里需要显示转换。虽然C语言并不要求显示地转换,但这样会增加代码的可读性。接着我们对castptr指针取值,值为1。
第19行非常有意思,在这里打印未初始化指针和NULL指针。值得注意的是,未初始化指针是有内存地址的,而且是一个垃圾地址。不知道这个内存地址指向的值是什么。这就是为什么不要对未初始化指针取值的原因。最好的情况是你取到的是垃圾地址接下来你需要对程序进行调试,最坏的情况则会导致程序崩溃。
NULL指针被初始化为o。NULL是一个特殊的地址,用NULL赋值的指针指向的地址为0而不是随机的地址。只有当你准备使用这个地址时有效。不要对NULL地址取值,否则会产生段错误。
指针和数组
C语言的数组表示一段连续的内存空间,用来存储多个特定类型的对象。与之相反,指针用来存储单个内存地址。数组和指针不是同一种结构因此不可以互相转换。而数组变量指向了数组的第一个元素的内存地址。
一个数组变量是一个常量。即使指针变量指向同样的地址或者一个不同的数组,也不能把指针赋值给数组变量。也不可以将一个数组变量赋值给另一个数组。然而,可以把一个数组变量赋值给指针,这一点似乎让人感到费解。把数组变量赋值给指针时,实际上是把指向数组第一个元素的地址赋给指针。
int myarray[4] = {1,2,3,0};
int *ptr = myarray;
printf("*ptr=%d\n", *ptr);
// 数组变量是常量,不能做下面的赋值
// myarray = ptr
// myarray = myarray2
// myarray = &myarray2[0]
第1行初始化了一个int数组,第2行用数组变量初始化了一个int指针。由于数组变量实际上是第一个元素的地址,因此我们可以把这个地址赋值给指针。这个赋值与*ptr = &myarray[0]效果相同,显示地把数组的第一个元素地址赋值到了ptr引用。这里需要注意的是,这里指针需要和数组的元素类型保持一致,除非指针类型为void。
指针与结构体
就像数组一样,指向结构体的指针存储了结构体第一个元素的内存地址。与数组指针一样,结构体的指针必须声明和结构体类型保持一致,或者声明为void类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 | struct person { int age; char *name; }; struct person first; struct person *ptr; first.age = 21; char *fullname = "full name"; first.name = fullname; ptr = &first; printf("age=%d, name=%s\n", first.age, ptr->name); |
第1至6行声明了一个person结构体,一个变量指向了一个person结构体和指向person结构体的指针。第8行为age成员赋了一个int值。第9至10行我们声明了一个char指针并赋值给一个char数组并赋值给结构体name成员。第11行我们把一个person结构体引用赋值给结构体变量。
第13行我们打印了结构体实例的age和name。这里需要注意两个不同的符号,’.’ 和 ‘->’ 。结构体实例可以通过使用 ‘.’ 符号访问age变量。对于结构体实例的指针,我们可以通过 ‘->’ 符号访问name变量。也可以同样通过(*ptr).name来访问name变量。
总结
希望这份简短的概述能够有助于了解不同的指针类型。在后续的博文中我们会探讨其它类型的指针和高级用法,比如函数指针。
欢迎提出提问并给出评论。
英文原文: Dennis Kubes 编译:伯乐在线 – 唐尤华
【如需转载,请标注并保留原文链接、译文链接和译者等信息,谢谢合作!】
C语言深度剖析 (2013/2/27 9:36:09)
定义声明最重要的区别:定义创建了对象并为这个对象分配了内存,声明没有分配内存。
register:寄存器变量,请求编译器将变量尽可能的将变量存放在CPU内部寄存器中而提高访问效率。
寄存器其实就是一块一块小的存储空间,只不过其存取速度比内存快。
register 变量必须是能被 CPU 寄存器所接受的类型。意味着 register 变量必须是一个单个的值,并且其长度应小于或等于整型的长度。 而且
register 变量可能不存放在内存中,所以不能用取址运算符“&”来获取 register 变量的地址。
static
的作用:第一修饰变量,变量分为局部变量和全局变量,它们都在内存的静态区。
静态全局变量,作用域仅限于变量被定义的文件中,其他文件即使用 extern 声明也没法使用他。准确地说作用域是从定义之处开始,到文件结尾处结束,在定义之处前面的那些代码行也不能使用它。想要使用就得在前面再加
extern ***。恶心吧?要想不恶心,很简单,直接在文件顶端定义不就得了。
静态局部变量,在函数体里面定义的,就只能在这个函数里用了,同一个文档中的其他
函数也用不了。由于被 static
修饰的变量总是存在内存的静态区,所以即使这个函数运行结束,这个静态变量的值还是不会被销毁,函数下次使用时仍然能用到这个值。
第二修饰函数,函数前加 static使得函数成为静态函数。但此处“static”的含义不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函数)。使用内部函数的好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
sizeof在计算变量所占空间大小时,括号可以省略,而计算类型大小时不能省略。
#include <stdio.h>include <string.h>
int main(int argc, char const argv[])
{
char a[1000];
int i;
for(i = 0; i < 1000; i++){
a[i] = -1-i;
}
printf("%d\n",strlen(a));
return 0;
}
1 2 3 4 5 6 7 8 9 10 11 12 | 按照我们上面的解释,那-0 和+0在内存里面分别怎么存储?int i = unsigned j = 10;i+j的值为多少?为什么?下面的代码有什么问题?unsigned i ;for (i=9;i>=0;i--){ printf("%u\n",i);} |
bool变量与“零值”进行比较
bool bTestFlag = FALSE;
if(bTestFlag);
if(!bTestFlag);
float变量与“零值”进行比较
float fTestVal = 0.0;
if((fTestVal >= -EPSINON) && (fTestVal <= EPSINON)); //EPSINON
为定义好的
精度。
指针变量与“零值”进行比较
intp=NULL;
if(NULL == p);
if(NULL != p);
if、else一般表示两个分支或是嵌套表示少量的分支,但如果分支很多的话……还是用switch、case组合吧。
每个case 语句的结尾绝对不要忘了加 break,否则将导致多个分支重叠(除非有意使多个分支重叠)。
最后必须使用default 分支。即使程序真的不需要 default 处理,也应该保留语句:
default :
break;
这样做并非画蛇添足,可以避免让人误以为你忘了 default处理。
case 后面只能是整型或字符型的常量或常量表达式(想想字符型数据在内存里是怎么存的)
。
case语句的排列顺序:
按字母或数字顺序排列各条case语句。
把正常情况放在前面,而把异常情况放在后面。
按执行频率排列case语句。
把default子句只用于检查真正的默认情况。
在 switch case 语句中能否使用
continue关键字?为什么?
循环语句的注意点
在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少 CPU 跨切循环层的次数。
建议for 语句的循环控制变量的取值采用“半开半闭区间”写法。
不能在for循环体内修改循环变量,防止循环失控。
循环要尽可能的短,要使代码清晰,一目了然。
把循环嵌套控制在3 层以内。
void真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
任何类型的指针都可以直接赋值给它,无需进行强制类型转换。
void修饰函数返回值和参数
如果函数没有返回值,那么应声明为 void类型。
如果函数无参数,那么应声明其参数为void。
无论在 C
还是C++中,若函数不接受任何参数,一定要指明参数为 void。
void指针
不能对
void指针进行算法操作。是因为它坚持:进行算法操作的指针必须是确定知道其指向数据类型大小的。也就是说必须知道内存目的地址的确切值。但是大名鼎鼎的
GNU(GNU's Not Unix的递归缩写)则不这么认定,它指定 void 的算法操作与 char 一致。
如果函数的参数可以是任意类型指针,那么应声明其参数为void 。
void不能代表一个真实的变量。
void体现了一种抽象,这个世界上的变量都是“有类型”的。
return用来终止一个函数并返回其后面跟着的值。
return 语句不可返回指向“栈内存”的“指针” ,因为该内存在函数体结束时被自动销毁。
定义 const只读变量,具有不可变性。
const修饰的只读变量必须在定义的同时初始化。
编译器通常不为普通
const只读变量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的值,没有了存储与读内存的操作,使得它的效率也很高。
const定义的只读变量在程序运行过程中只有一份拷贝(因为它是全局的只读变量,存放在静态区)
,而#define定义的宏常量在内存中有若干个拷贝。#define宏是在预编译阶段进行替换,而
const修饰的只读变量是在编译的时候确定其值。#define宏没有类型,而 const修饰的只读变量具有特定的类型。
const修饰的只读变量不能用来作为定义数组的维数,也不能放在 case关键字后面。
修饰一般变量
这种只读变量在定义时,修饰符 const可以用在类型说明符前,也可以用在类型说明符后。例如:int const i=2; 或 const int
i=2;修饰数组
定义或说明一个只读数组可采用如下格式:int const a[5]={1, 2, 3, 4, 5};或const int a[5]={1, 2, 3,
4, 5};修饰指针
const int p; // p 可变,p指向的对象不可变
int const p; // p可变,p指向的对象不可变
intconstp; //p不可变,p指向的对象可变
const int const p; //指针 p和 p指向的对象都不可变
先忽略类型名,看
const离哪个近,离谁近就修饰谁。
const int p;
//const修饰p,p是指针,p是指针指向的对象,不可变
int const
p;//const修饰p,p是指针,p是指针指向的对象,不可变
int const p;//const修饰
p,p不可变,p 指向的对象可变
const int const p; //前一个
const修饰p,后一个 const修饰p,指针 p和 p 指向的对象都不可变
修饰函数的参数
const修饰符也可以修饰函数的参数,当不希望这个参数值被函数体内意外改变时使用。例如:void Fun(const int
i);告诉编译器i在函数体中的不能改变, 从而防止了使用者的一些无意的或错误的修改。修饰函数的返回值
const修饰符也可以修饰函数的返回值,返回值不可被改变。例如:const int Fun (void);
最易变的关键字----volatile
用它修饰的变量表示可以被某些编译器,未知的因素更改,比如操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
最会带帽子的关键字----extern
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中。
struct 关键字
结构体所占的内存大小是其成员所占内存之和,空结构体的大小就定位 1 个byte。
struct与 class的区别
在 C++里 struct关键字与 class关键字一般可以通用,只有一个很小的区别。struct的成员默认情况下属性是
public的,而class成员却是 private的。
在union中所有的数据成员共用一个空间,同一时间只能储存其中一个数据成员,所有的数据成员具有相同的起始地址。
一个 union只配置一个足够大的空间以来容纳最大长度的数据成员。
大端模式和小端模式。
大端模式(Big_endian) :字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端模式(Little_endian) :字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中。
union型数据所占的空间等于其最大的成员所占的空间。
对 union型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始, 也就是联合体的访问不论对哪个变量的存取都是从
union的首地址位置开始。
请写一个 C 函数,若处理器是Big_endian的,则返回 0;若是Little_endian的,则返回 1。
利用 union类型数据的特点:所有成员的起始地址一致。
枚举与#define宏的区别
#define宏常量是在预编译阶段进行简单替换。枚举常量则是在编译的时候确定其值。
一般在编译器里,可以调试枚举常量,但是不能调试宏常量。
枚举可以一次定义大量相关的常量,而#define宏一次只能定义一个。
注释的使用规则
y=x/p 表示把x赋值给y,同时注释开始
y=x/(p) 表示把x除以 p 指向的内存里的值,把结果赋值为 y
0。
1,最高位是补0 或是补1 取决于编译系统的规定。TurboC和很多系统规定为补 1。









4字节对齐,这时就按4 字节对齐,所以sizeof(TestStruct4)应该为 8;
个字节,它按什么对齐呢?对于结构来说,它的默认对齐方式就是它的所有成员使用的对齐参数中最大的一个,TestStruct4的就是4.所以,成员d就是按4字节对齐.成员e是8个字节,它是默认按8字节对齐,和指定的一样,所以它对到8字节的边界上,这时,已经使用了12个字节了,所以又添加了
4 个字节的空,从第 16个字节开始放置成员 e.这时,长度为24,已经可以被 8(成员 e按 8字节对齐)整除.这样,一共使用了 24个字节.内存布局如下
(表示空闲内存, 1表示使用内存。单位为 1byete) :
a b
c TestStruct4.a TestStruct4.b
d
1111,, 11111111


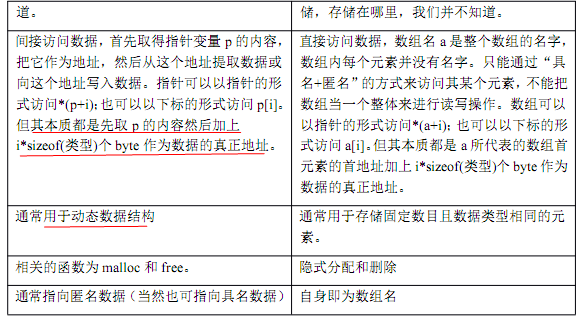
指针和数组
byte,其值为某一个内存的地址。指针可以指向任何地方,但是不是任何地方你都能通过这个指针变量访问到。
byte,这块内存也没有名字。对这块内存的访问完全是匿名的访问。比如现在需要读取字符‘e’ ,我们有两种方式:
0x0000FF04。然后取出 0x0000FF04地址上的值。
p里存储的地址值,然后加上中括号中
4个元素的偏移量,计算出新的地址,然后从新的地址中取出值。也就是说以下标的形式访问在本质上与以指针的形式访问没有区别,只是写法上不同罢了。
a找到数组首元素的首地址,然后根据偏移量找到相应的值。这是一种典型的“具名+匿名”访问。比如现在需要读取字符‘5’ ,我们有两种方式:
0x0000FF04。然后取出 0x0000FF04地址上的值。
4个元素的偏移量,计算出新的地址,然后从新的地址中取出值。
XXX的形式的访问”这种表达方式。另外一个需要强调的是:上面所说的偏移量 4 代表的是4 个元素,而不是 4 个byte。只不过这里刚好是 char类型数据
1个字符的大小就为 1个 byte。记住这个偏移量的单位是元素的个数而不是
byte数,在计算新地址时千万别弄错了。

4个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
p1,int修饰的是数组的内容,即数组的每个元素。那现在我们清楚,这是一个数组,其包含 10个指向 int类型数据的指针,即指针数组。至于
p2就更好理解了,在这里“ () ”的优先级比“[]”高, “”号和 p2构成一个指针的定义,指针变量名为
p2,int修饰的是数组的内容,即数组的每个元素。数组在这里并没有名字,是个匿名数组。那现在我们清楚 p2是一个指针,它指向一个包含 10个
int类型数据的数组,即数组指针。
数组指针(也称行指针)
定义
int (p)[n];
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
如要将二维数组赋给一指针,应这样赋值:
int
a[3][4];
int
(p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a;
//将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++;
//该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
定义
int p[n];
[]优先级高,先与p结合成为一个数组,再由int说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样
p=a; 这里p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int
p[3];
int
a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];
这里int
p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。
这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
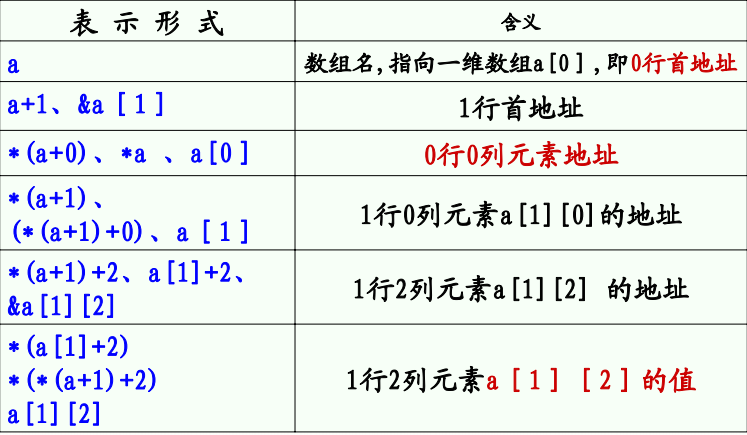
还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
比如要表示数组中i行j列一个元素:
(p[i]+j)、((p+i)+j)、((p+i))[j]、p[i][j]
优先级:()>[]>
。
int类型数据的指针。
(int)Function;表示将函数的入口地址赋值给指针变量 p。
静态区:保存自动全局变量和 static变量(包括 static全局和局部变量)
。静态区的内容在总个程序的生命周期内都存在,由编译器在编译的时候分配。栈:保存局部变量。栈上的内容只在函数的范围内存在,当函数运行结束,这些内容也会自动被销毁。其特点是效率高,但空间大小有限。
堆:由 malloc系列函数或 new操作符分配的内存。其生命周期由 free或
delete决定。在没有释放之前一直存在,直到程序结束。其特点是使用灵活,空间比较大,但容易出错。
语句不可返回指向“栈内存”的“指针”,因为该内存在函数体结束时被自动销毁。
assert(NULL!=strDest);
return('\0'!=strDest)?(1+my_strlen(strDest+1)):0;
文件操作 (2013/2/26 15:07:24)













数据链表与内存分配 (2013/2/26 14:50:13)





链表




结构体,共用体 (2013/2/26 12:24:47)








位运算



字符与字符串 (2013/2/25 21:49:09)





指针 (2013/2/25 21:13:44)








数组名是数组的首地址是一个常量











C基础 (2013/2/25 20:37:39)



auto: 花括号内的都是auto型变量,局部变量,现在很少使用,都是缺省了<o:p></o:p>
extern:具有外部变量链接;如果在别的文件中定义了变量如:int ER; 在其他的文件中要使用它,可以用extern int ER;此时的ER变量和前面保持一致;如果在其他文件中去掉extern,如:int ER;此ER为局部变量和前面完全不同。 <o:p></o:p>
register: 寄存器变量,寄存器变量比内存变读取速度更快,但是寄存器变量资源有限,不能存放太多变量和太大变量比如:double型.<o:p></o:p>
static:静态变量,从第一次调用的时候初始化一次,然后在域没消失前,数据不会初始化;数据会常驻内存,一直到程序结束。<o:p></o:p>
<o:p></o:p>
const:把变量声明转换成常量的声明;所谓转换成常量并不是真的变成了常量,只是把变量设置成只读变量;<o:p></o:p>
例如:const int num;//把num转换成只读变量<o:p></o:p>
num=12;//不允许写入,只能读;即会错误提示<o:p></o:p>
const int num=12;//允许在定义阶段初始化。<o:p></o:p>
<o:p></o:p>
sizeof:返回一个类型或变量的字节数;例如:char a[]="asdfs";sizeof(a)=5;注意这里的/0不会计算在内;<o:p></o:p>
volatile:告诉编译器定义的变量是一个常改变的值;使得在编译器优化的时候把变量读入缓存的问题;<o:p></o:p>
volatile的作用: 作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值.<o:p></o:p>






















附件列表
本文来自博客园,作者:suntl,转载请注明原文链接:https://www.cnblogs.com/stlong/p/6290442.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号