
【转载】爬虫流程总结
爬虫是一个比较容易上手的技术,也许花5分钟看一篇文档就能爬取单个网页上的数据。但对于大规模爬虫,完全就是另一回事,并不是1*n这么简单,还会衍生出许多别的问题。
系统的大规模爬虫流程如图所示。

先检查是否有API
API是网站官方提供的数据接口,如果通过调用API采集数据,则相当于在网站允许的范围内采集,这样既不会有道德法律风险,也没有网站故意设置的障碍;不过调用API接口的访问则处于网站的控制中,网站可以用来收费,可以用来限制访问上限等。整体来看,如果数据采集的需求并不是很独特,那么有API则应优先采用调用API的方式。
数据结构分析和数据存储
- 爬虫需求要十分清晰,具体表现为需要哪些字段,这些字段可以是网页上现有的,也可以是根据网页上现有的字段进一步计算的,这些字段如何构建表,多张表如何连接等。值得一提的是,确定字段环节,不要只看少量的网页,因为单个网页可以缺少别的同类网页的字段,这既有可能是由于网站的问题,也可能是用户行为的差异,只有多观察一些网页才能综合抽象出具有普适性的关键字段——这并不是几分钟看几个网页就可以决定的简单事情,如果遇上了那种臃肿、混乱的网站,可能坑非常多。
- 对于大规模爬虫,除了本身要采集的数据外,其他重要的中间数据(比如页面Id或者url)也建议存储下来,这样可以不必每次重新爬取id。
- 数据库并没有固定的选择,本质仍是将Python里的数据写到库里,可以选择关系型数据库MySQL等,也可以选择非关系型数据库MongoDB等;对于普通的结构化数据一般存在关系型数据库即可。
sqlalchemy是一个成熟好用的数据库连接框架,其引擎可与Pandas配套使用,把数据处理和数据存储连接起来,一气呵成。
数据流分析
- 对于要批量爬取的网页,往上一层,看它的入口在哪里;这个是根据采集范围来确定入口,比如若只想爬一个地区的数据,那从该地区的主页切入即可;但若想爬全国数据,则应更往上一层,从全国的入口切入。一般的网站网页都以树状结构为主,找到切入点作为根节点一层层往里进入即可。
- 值得注意的一点是,一般网站都不会直接把全量的数据做成列表给你一页页往下翻直到遍历完数据,比如链家上面很清楚地写着有24587套二手房,但是它只给100页,每页30个,如果直接这么切入只能访问3000个,远远低于真实数据量;因此先切片,再整合的数据思维可以获得更大的数据量。显然100页是系统设定,只要超过300个就只显示100页,因此可以通过其他的筛选条件不断细分,只到筛选结果小于等于300页就表示该条件下没有缺漏;最后把各种条件下的筛选结果集合在一起,就能够尽可能地还原真实数据量。
- 明确了大规模爬虫的数据流动机制,下一步就是针对单个网页进行解析,然后把这个模式复制到整体。对于单个网页,采用抓包工具可以查看它的请求方式,是get还是post,有没有提交表单,欲采集的数据是写入源代码里还是通过AJAX调用JSON数据。
- 同样的道理,不能只看一个页面,要观察多个页面,因为批量爬虫要弄清这些大量页面url以及参数的规律,以便可以自动构造;有的网站的url以及关键参数是加密的,这样就悲剧了,不能靠着明显的逻辑直接构造,这种情况下要批量爬虫,要么找到它加密的js代码,在爬虫代码上加入从明文到密码的加密过程;要么采用下文所述的模拟浏览器的方式。
数据采集
- 之前用R做爬虫,不要笑,R的确可以做爬虫工作;但在爬虫方面,Python显然优势更明显,受众更广,这得益于其成熟的爬虫框架,以及其他的在计算机系统上更好的性能。
scrapy是一个成熟的爬虫框架,直接往里套用就好,比较适合新手学习;requests是一个比原生的urllib包更简洁强大的包,适合作定制化的爬虫功能。requests主要提供一个基本访问功能,把网页的源代码给download下来。一般而言,只要加上跟浏览器同样的Requests Headers参数,就可以正常访问,status_code为200,并成功得到网页源代码;但是也有某些反爬虫较为严格的网站,这么直接访问会被禁止;或者说status为200也不会返回正常的网页源码,而是要求写验证码的js脚本等。 - 下载到了源码之后,如果数据就在源码中,这种情况是最简单的,这就表示已经成功获取到了数据,剩下的无非就是数据提取、清洗、入库。但若网页上有,然而源代码里没有的,就表示数据写在其他地方,一般而言是通过AJAX异步加载JSON数据,从XHR中找即可找到;如果这样还找不到,那就需要去解析js脚本了。
解析工具
源码下载后,就是解析数据了,常用的有两种方法,一种是用BeautifulSoup对树状HTML进行解析,另一种是通过正则表达式从文本中抽取数据。
- BeautifulSoup比较简单,支持
Xpath和CSSSelector两种途径,而且像Chrome这类浏览器一般都已经把各个结点的Xpath或者CSSSelector标记好了,直接复制即可。以CSSSelector为例,可以选择tag、id、class等多种方式进行定位选择,如果有id建议选id,因为根据HTML语法,一个id只能绑定一个标签。 - 正则表达式很强大,但构造起来有点复杂,需要专门去学习。因为下载下来的源码格式就是字符串,所以正则表达式可以大显身手,而且处理速度很快。
对于HTML结构固定,即同样的字段处tag、id和class名称都相同,采用BeautifulSoup解析是一种简单高效的方案,但有的网站混乱,同样的数据在不同页面间HTML结构不同,这种情况下BeautifulSoup就不太好使;如果数据本身格式固定,则用正则表达式更方便。比如以下的例子,这两个都是深圳地区某个地方的经度,但一个页面的class是long,一个页面的class是longitude,根据class来选择就没办法同时满足2个,但只要注意到深圳地区的经度都是介于113到114之间的浮点数,就可以通过正则表达式"11[3-4].\d+"来使两个都满足。
数据整理
一般而言,爬下来的原始数据都不是清洁的,所以在入库前要先整理;由于大部分都是字符串,所以主要也就是字符串的处理方式了。
- 字符串自带的方法可以满足大部分简单的处理需求,比如
strip()可以去掉首尾不需要的字符或者换行符等,replace()可以将指定部分替换成需要的部分,split()可以在指定部分分割然后截取一部分。 - 如果字符串处理的需求太复杂以致常规的字符串处理方法不好解决,那就要请出正则表达式这个大杀器。
Pandas是Python中常用的数据处理模块,虽然作为一个从R转过来的人一直觉得这个模仿R的包实在是太难用了。Pandas不仅可以进行向量化处理、筛选、分组、计算,还能够整合成DataFrame,将采集的数据整合成一张表,呈现最终的存储效果。
写入数据库
如果只是中小规模的爬虫,可以把最后的爬虫结果汇合成一张表,最后导出成一张表格以便后续使用;但对于表数量多、单张表容量大的大规模爬虫,再导出成一堆零散的表就不合适了,肯定还是要放在数据库中,既方便存储,也方便进一步整理。
- 写入数据库有两种方法,一种是通过Pandas的DataFrame自带的
to_sql()方法,好处是自动建表,对于对表结构没有严格要求的情况下可以采用这种方式,不过值得一提的是,如果是多行的DataFrame可以直接插入不加索引,但若只有一行就要加索引否则报错,虽然这个认为不太合理;另一种是利用数据库引擎来执行SQL语句,这种情况下要先自己建表,虽然多了一步,但是表结构完全是自己控制之下。Pandas与SQL都可以用来建表、整理数据,结合起来使用效率更高。 - 写入数据库有两种思路,一种是等所有的数据都爬完,集中一次向量化清洗,一次性入库;另一种是爬一次数据清洗一次就入库。表面上看前者效率更高,但是对于大规模爬虫,稳定性也是要考虑的重要因素,因为在长久的爬虫过程中,总不可避免会出现一些网络错误,甚至如果出现断网断电的情况,第一种情况下就全白费了,第二种情况下至少已入库的不会受影响,并且单次的清洗和入库是很快的,基本不怎么费时间,所以整体来看推荐第二种思路。
爬虫效率提升
对于大规模爬虫,效率是一个核心问题。单个网页爬取可能很大,一旦网页数量级大增之后,任务量也会大增,同时方式下的耗时也会大增。没有公司或人个愿意爬个几十万上百万的页面还要等几个月,因此优化流程、提高效率是非常必要的。
- 尽量减少访问次数。单次爬虫的主要耗时在于网络请求等待响应,所以能减少访问就少访问,既减少自己的工作量,也减轻网站的压力,还降低被封的风险。首先要做的就是流程优化,尽可能精简流程,一些数据如果可以在一个页面内获取而不必非要在多个页面下获取,那就只在一个页面内获取。然后去重也是非常重要的手段——网站并不是严格意义的互不交叉的树状结构,而是多重交叉的网状结构,所以从多个入口深入的网页会有很多重复,一般根据url或者id进行唯一性判别,爬过的就不再继续爬了。最后,值得深思的一点就是,是不是所有的数据都需要爬?对于那些响应慢,反爬机制很严格的网站,爬少量的都困难,爬大量的时间成本就会高到难以接受,这种情况下怎么办?举一个例子,对于气象数据,已知的一点是时间、空间越接近的地方数据就越接近,那么你爬了一个点的气象数据之后,100米以内的另一个点就可以不用再爬,因为可预期一定是跟之前的点差不多;这个时候就可以采用机器学习的方法,爬取一部分数据作为训练数据,其他的进行预测,当对数据的准确性要求不是特别高,当模型的性能比较好,采用机器学习模型预测就可以省下大部分爬虫的工作。虽然专业的爬虫工程师懂机器学习的可能不多,但这正是复合型人才的优势。
- 大量爬虫是一个IO阻塞的任务,因此采用多进程、多线程或者协程的并发方式可以有效地提高整理速度。个人推荐用协程,速度比较快,稳定性也比较好。
- 即使把各种法子都用尽了,单机单位时间内能爬的网页数仍是有限的,面对大量的页面队列,可计算的时间仍是很长,这种时候就必须要用机器换时间了,这就是分布式爬虫。首先,分布式不是爬虫的本质,也不是必须的,对于互相独立、不存在通信的任务就可手动对任务分割,然后在多台机器上分别执行,减少每台机器的工作量,耗时就会成倍减少。比如有100W个页面待爬,可以用5台机器分别爬互不重复的20W个页面,相对单机耗时就缩短了5倍。但是如果存在着需要通信的状况,比如一个变动的待爬队列,每爬一次这个队列就会发生变化,即使分割任务也就有交叉重复,因为各个机器在程序运行时的待爬队列都不一样了——这种情况下只能用分布式,一个Master存储队列,其他多个Slave各自来取,这样共享一个队列,取的时候互斥也不会重复爬取。
scrapy-redis是一款用得比较多的分布式爬虫框架。
数据质量管理
大量的页面往往不会是结构完全一样,而且大量的访问也总会出现该访问成功却访问不成功的情况,这些都是非常常见的状况,因此单一的逻辑无法应对各种不可预知的问题,反映在结果上就是爬取的数据往往会有错漏的情况。
-
try...except是Python中常用的异常诊断语句,在爬虫中也可充分应用。一方面,同样的字段可能在有的网页上有,另外的网页上就是没有,这样爬取该字段的语句就会出错,然而这并不是自己逻辑或代码的错,用诊断语句就可以绕过这些网站的坑;另一方面,大规模爬虫是一个耗时较长的过程,就像是千军万马冲锋,不能因为中间挂了几个而停止整体进程,所以采用这个语句可以跳过中间出现的各种自己产生或者网站产生的错误,保证爬虫整体的持续进行。 -
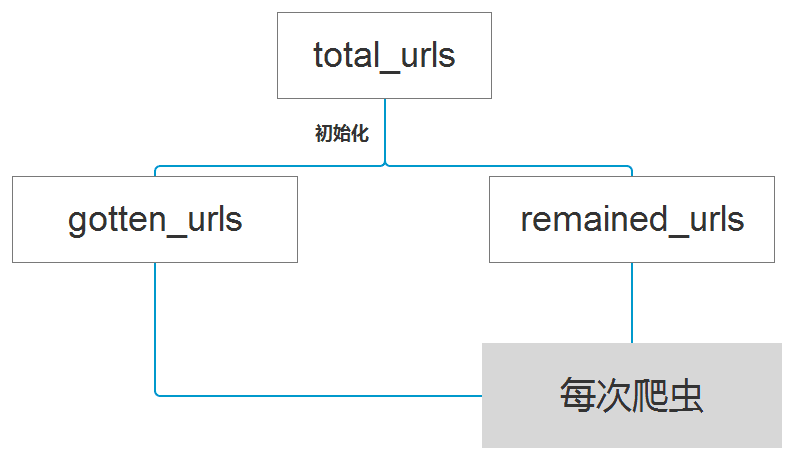
断点续传也是流程设计是重要的一块。一个一旦启动就必须要等它跑完,如果中途中断就前功尽弃的爬虫系统是非常不健壮的,因为谁也无法预料中间会因各种原因中断,而且估计也没有谁会喜欢这种类似于被绑架的感觉。健壮的爬虫系统应该是随时都可以启动,而且每次启动都是爬剩下的而不是从头开始重复爬,其实这个流程设计也比较简单,如下图所示:所有待爬的网页total_urls分为两部分,一部分是已爬过的gotten_urls(初始化之前为空),total_urls与gotten_urls的差集remained_urls就是剩余要爬的网页。total_urls是固定的,每执行一次爬虫,gotten_urls就会增加,下一次启动爬虫程序计算的remained_urls就减少了,当remained_urls为空表示完成全部爬虫任务。这样的断点续传流程设计可使爬虫程序可以随时停下,随时启动,并且每次启动都不会做重复劳动。
- 错漏校验可以入库之后进行,这一步就是把爬虫过程中产生错漏的记录筛选出来清掉重新爬,这一步也很重要,保证数据质量才能继续后续的流程。错漏校验就要结合业务自己来写一套数据清洗流程。对于字段为空的情况,有两种产生原因:一是该网页本来就没有这个字段,这不是错误;另一种是由于网络出错没有获取到该字段,这是错误,要筛选出来清除——一般情况下可以通过status_code是否为200来判断网络访问是否出错来判断空字段是否是由于网络出错的原因造成的,对于特殊的status_code为200仍不返回正常数据的就需特殊分析了。此外,可以通过某些字段固定的属性来作为筛选条件,比如名称不能为空(或者为空就舍弃)、深圳地区的经度介于113和114之间等条件来过滤掉缺漏或者是网站反爬恶意传回的错误数据。清洗逻辑越全面复杂,数据质量越高,后续使用数据时产生的问题就越少;这也是一块需要深入思考的部分。
反反爬虫
爬虫的固定套路也就那么多,各种网站爬取策略的不同就在于网站的反爬虫机制不同,因此多作试验,摸清网站的反爬机制,是大规模爬虫的先行工作。爬虫与反爬虫是无休止的斗争,也是一个见招拆招的过程,但总体来说,以下方法可以绕过常见的反爬虫。
- 加上headers。这是最基础的手段。加上了请求头就可以伪装成浏览器,混过反爬的第一道关卡;反之,连请求头都不加,网站可以直接看出是程序在访问而直接拒绝。一般的网站加上User-Agent就可以,反爬严格的网站则要加上cookie甚至各种参数都要加上。
- 随机延时。这是最简单有效的一种手段。稳定性是大规模爬虫的另一个核心问题,虽然与效率冲突。许多网站都会统计同一个IP一段时间内的访问频率,如果采集过快,会直接封禁IP。不要为了一时爽而不加延时导致几分钟后IP就被封24小时,还不如老老实实地加延时慢慢爬一夜爬完。至于延时加多少因各个网站而异,但一般情况下延时个3~5秒就足够了。
- 如果页面量实在太大,每次访问设置的随时延时也会成为额外大量的时间成本。单个IP快速访问会有被封的风险,这是就要用代理池,有两点好处:一是降低某个IP单位时间内的访问频率,降低被封风险;二是即使IP被封,也有别的IP可以继续访问。代理池有免费和收费的,免费代理可以从许多网站上获取(这也是一个爬虫项目),但大部分都没用,有用的小部分也会很快挂掉;收费代理好一点,但也好不了多少。高质量的代理成本就高了不少,这个要结合项目实际需求来考虑成本。所以,如果网站不封IP就可以不用代理,以免减慢访问速度,增大被拒的概率。
- 有的网站必须要登录才能访问,才能爬虫。以知乎为例,知乎的模拟登录必较简单,甚至现在都没有对帐号和密码加密,直接明文post就可以。请求头的cookie含有登录信息,而知乎的cookie寿命较长,所以可以直接在网站上人工登录然后把cookie复制到代码中;知乎目前的反爬机制是如果判断是机器人就封帐号但不封IP——封IP是同样的机器无法访问,但却可以用同样的帐号在其他机器上访问;封号是同样的帐号在各种终端上都无法访问,但同一台机器上却可以换号访问。基于这种机制,爬知乎就不需要IP代理池而需要的是帐号池。举另一个例子,腾讯有一个子网站,它也要求必须QQ登录,而且cookie只有6分钟的寿命,而且一个帐号一天只能访问130次超过就封号,无论爬得再慢——这种情况下只能搞大量的QQ号进行自动登录并不断切换。
- 如果有的网站的反爬机制实在太过丧心病狂,各种JS代码逻辑十分复杂艰深,那只能模拟浏览器了。模拟浏览器其实就是一种自动的浏览器访问,与正常的用户访问很类似,所以可以跳过大部分的反爬机制,因为你装得实在太像正常用户;不过缺点也很明显,就是慢。所以可以用requests搞定的优先用requests,实在没有办法了再考虑模拟浏览器。
- 验证码。验证码一出就蛋疼了……Python有自动识别图像的包,不过对于大部分网站的验证码都无能为力。写一个自动识别验证码的程序理论上不是不行,但是这种复杂的机器学习项目一点都不比爬虫系统本身难度低,从成本的角度考虑实在是得不偿失——何况对于有些网站如谷歌,验证码识别是非常困难的。所以对于验证码问题,首先是躲过去尽量不要触发验证码,实在触发了只能乖乖人工去填验证码。
各种各样的反爬机制也算是因垂斯听,只有身经百战,爬得多了,才能谈笑风生,爬虫水平不知道高到哪去了。有哪些有趣的反爬虫手段?
爬虫的道德节操和法律问题
- 一些大型的网站都会有robot.txt,这算是与爬虫者的一个协议。只要在robot.txt允许的范围内爬虫就不存在道德和法律风险,只不过实际上的爬虫者一般都不看这个。
- 控制采集速度。过快的采集会对网站服务器造成不小的压力,如果是性能差的小站可能就会被这么搞垮了。因此放慢采集速度相当于各退一步,既给网站减轻压力,也降低自己被封禁的风险。
- 爬虫目前在法律上尚属灰色地段,但爬别的网站用于自己的商业化用途也可能存在着法律风险。非法抓取使用“新浪微博”用户信息 “脉脉”被判赔200万元,这是国内的一条因爬虫被判败诉的新闻。所以各商业公司还是悠着点,特别是爬较为隐私的数据。
本文来自博客园,作者:suntl,转载请注明原文链接:https://www.cnblogs.com/stlong/p/11223551.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号